京东2020校招数据分析工程师 —— 选择题盲点整理(2019.8.24)
- 套题
京东2020校招数据分析工程师笔试题 - 题型
选择 * 30 + 编程 * 2 - 完成时间
120分钟
完整题目不可能记得啦,针对盲点,补一补。
❤️ 「更多数据分析真题」
《数据分析真题日刷 | 目录索引》
❤️ 「更多我的秋招经验贴」
《2020我的秋招总结帖 [数据分析岗] | 目录索引》
1. 哈夫曼树5个叶子结点,一共多少个结点?
Huffman 树是所谓的正则二叉树,只有度为0和度为2的结点。
根据二叉树的性质,n0 = n2 + 1,因此该树中度为2的结点数量为n-1
于是一共有 2n-1个结点。
2. 选择DDL语句
DML(data manipulation language)数据操纵语言:
就是我们最经常用到的 SELECT、UPDATE、INSERT、DELETE。 主要用来对数据库的数据进行一些操作。DDL(data definition language)数据库定义语言:
比如说:CREATE、ALTER、DROP等。DDL主要是用在定义或改变表的结构,数据类型,表之间的链接和约束等初始化工作上。DCL(Data Control Language)数据库控制语言:
是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。这个比较少用到。
来源:https://www.cnblogs.com/feng0815/p/8510236.html
3. apriori改进
不记得备选项给了哪些改进方法了。不过这篇博文,对apriori算法总结得很好。
《关联规则挖掘——Apriori算法的基本原理以及改进》
4. 神经网络参数
印象中选项涉及以下参数:
Batch_Size(批尺寸)
该参数主要用于批梯度下降算法(Batch Gradient Descent)中,批梯度下降算法是每次迭代都遍历批中的所有样本,由批中的样本共同决定最优的方向,Batch_Size 正是批中的样本数量。
冲量-momentum
梯度下降法中一种常用的加速技术
权值衰减-weight decay
使用的目的是防止过拟合,当网络逐渐过拟合时网络权值往往会变大,因此,为了避免过拟合,在每次迭代过程中以某个小因子降低每个权值,也等效于给误差函数添加一个惩罚项,常用的惩罚项是所有权重的平方乘以一个衰减常量之和。权值衰减惩罚项使得权值收敛到较小的绝对值。
学习率-learning rate
学习率决定了参数移动到最优值的速度快慢,如果学习率过大,很可能会越过最优值导致函数无法收敛,甚至发散;反之,如果学习率过小,优化的效率可能过低,算法长时间无法收敛,也易使算法陷入局部最优(非凸函数不能保证达到全局最优)。合适的学习率应该是在保证收敛的前提下,能尽快收敛。
版权声明:本文为CSDN博主「IceMiao433」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yudiemiaomiao/article/details/72391316
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数。 相反,其他参数的值通过训练得出。
神经网络中的超级参数
- 学习率 η,
- 正则化参数 λ,
- 神经网络的层数 L,
- 每一个隐层中神经元的个数 j,
- 学习的回合数Epoch,
- 小批量数据 minibatch 的大小,
- 输出神经元的编码方式,
- 代价函数的选择,
- 权重初始化的方法,
- 神经元激活函数的种类,
- 参加训练模型数据的规模
版权声明:本文为CSDN博主「SherryGo」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xueruixuan/article/details/78772110
5. 选择用串行训练的模型(备选项有:xgboost, gbdt, adaboost, rf)
- Boosting:串行训练,例如xgboost, gbdt, adaboost;
- Bagging:并行训练,例如rf。
6. 过滤类型的特征选择
从给定的特征集合中选择出相关特征子集的过程,称为“特征选择”。特征选择是一个重要的数据预处理过程,进行特征选择的原因如下:
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合;
- 去除不相关特征,降低学习难度。
常见的特征选择方法大致可以分为三类:过滤式、包裹式和嵌入式。
一、 过滤式方法
先对数据集进行特征选择,然后再训练学习器。特征选择过程与后续学习器无关,这相当于先对初始特征进行“过滤”,再用过滤后的特征训练模型。
- 过滤式选择的方法有:
- 移除低方差的特征;
- 相关系数排序,分别计算每个特征与输出值之间的相关系数,设定一个阈值,选择相关系数大于阈值的部分特征;
- 利用假设检验得到特征与输出值之间的相关性,方法有比如卡方检验、t检验、F检验等。
- 互信息,利用互信息从信息熵的角度分析相关性。
二、包裹式
从初始特征集合中不断的选择特征子集,训练学习器,根据学习器的性能来对子集进行评价,直到选择出最佳的子集。
- 包裹法中,特征子集的搜索问题,最容易想到的办法是穷举法,还可以在拉斯维加斯方法框架下使用随机策略进行子集搜索(Las Vegas Wrapper,LVW)。
- 因此,我们通常使用的是贪心算法:如前向搜索(在最优的子集上逐步增加特征,直到增加特征并不能使模型性能提升为止)、后向搜索、双向搜索(将前向搜索和后向搜索相结合)。
三、嵌入式选择
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别。而嵌入式特征选择在学习器训练过程中自动地进行特征选择。
- 嵌入式选择最常用的是L1 正则化和L2 正则化。正则化项越大,模型越简单,系数越小,当正则化项增大到一定程度时,所有的特征系数都会趋于0,在这个过程中,会有一部分特征的系数先变成0。也就实现了特征选择过程。
- 逻辑回归、线性回归、决策树都可以当作正则化选择特征的基学习器,只有可以得到特征系数或者可以得到特征重要度的算法才可以作为嵌入式选择的基学习器。
————————————————
版权声明:本文为CSDN博主「齐在」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/pxhdky/article/details/86305538
- 强烈参考
《【机器学习】特征选择(过滤式、包裹式、嵌入式)》
7. 红黑树
为什么要红黑树?
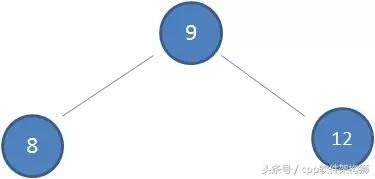
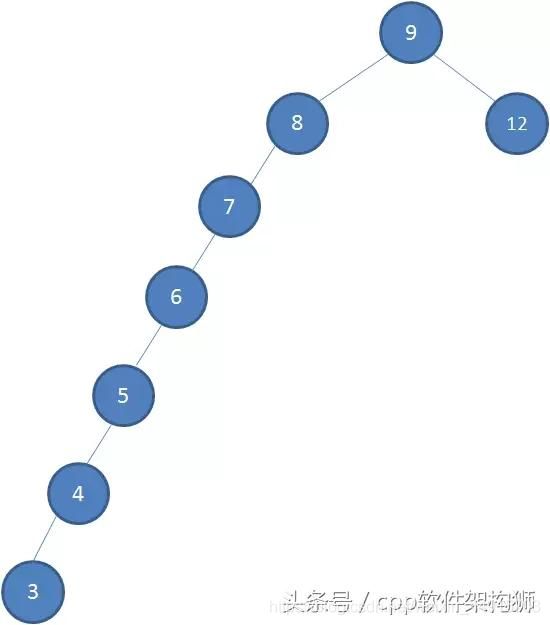
- 这是初始的二叉查找树:
我们依次插入5个结点:7,6,5,4,3:
- 可见,这棵树变得相当不均衡,“左腿”很长。此时,查找的性能大打折扣,几乎为线性的了。
- 这个时候,就需要「红黑树」了。
来源:http://www.360doc.com/content/18/0904/19/25944647_783893127.shtml
红黑树是什么?
红黑树是一种平衡的二叉查找树,平衡的意思是说,它不会变成“瘸腿”,某一分支特别长。除了符合二叉查找树的性质,还具有以下特性:
- 每个节点或者是黑色,或者是红色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
插入和删除时,旋转和变色的技巧方法详细参考博文。
强烈参考:http://www.360doc.com/content/18/0904/19/25944647_783893127.shtml

8. SQL优化 having和where
不记得比较having 和where的什么了。
不过这篇博文《sql优化部分总结》写得不错,摘录部分如下。
- 1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
可以在num上设置默认值0,确保表中num列没有null值。- 3.应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
- 4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描。
- 5.in 和 not in 也要慎用,否则会导致全表扫描,对于连续的数值,能用 between 就不要用 in 了。很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:select num from a where exists(select 1 from b where num=a.num)- 6.模糊查询也将导致全表扫描。
- 7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
select id from t where num/2 = 100,应改为select id from t where num = 100*2- 9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。
- 15.select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是一定要杜绝的。
- 16.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
来源:https://blog.csdn.net/chenglc1612/article/details/70860996
9. union all ? union
UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
- 1.对重复结果的处理:
UNION在进行表链接后会筛选掉重复的记录,Union All不会去除重复记录。- 2.对排序的处理:
Union将会按照字段的顺序进行排序;UNION ALL只是简单的将两个结果合并后就返回。- 从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复数据且不需要排序时的话,那么就使用UNION ALL。
来源:https://www.cnblogs.com/areyouready/p/7827779.html
10. new ? init
在面向对象编程中,实例化基本遵循以下过程?
创建实例对象->初始化实例对象->最后返回实例对象。
- Python 中的 new 方法负责创建一个实例对象;
- init 方法负责将该实例对象进行初始化
所以你可以猜到, __new__在__init__之前被调用。
关于两者的性质和比较,强烈推荐《浅析__new__()和__init__()使用》。结合代码的运行结果,比较理解。
11. 哪种情况用栈(题目备选:表达式求值,递归,子程序等)
表达式求值
- 中缀表达式:
格式:"操作数1 操作符 操作数2"
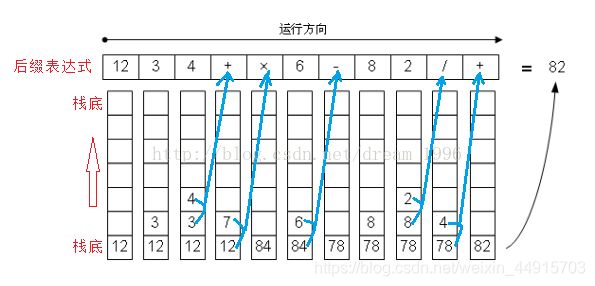
12 * (3 + 4) - 6 + 8 / 2; // 中缀表达式- 后缀表达式
格式:"操作数 操作符"
12 3 4 + * 6 - 8 2 / +; //后缀表达式那后缀表达式是如何计算的呢?
这里栈就派上用场了,从左到右一个个遍历表达式,遇到操作数就入栈,遇到操作符就依次取出栈顶的两个操作数进行计算,并把计算结果入栈,供后面计算,直到栈为空,说明表达式计算完毕,否则说明表达式有问题。
来源:https://blog.csdn.net/dream_1996/article/details/78126839
递归
- 我们会惊奇的发现这个过程和栈的工作原理一致对,递归调用就是通过栈这种数据结构完成的。整个过程实际上就是一个栈的入栈和出栈问题。然而我们并不需要关心这个栈的实现,这个过程是由系统来完成的。
- 那么递归中的“递”就是入栈,递进;“归”就是出栈,回归。
来源:https://www.jianshu.com/p/a4d635ca19cc?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
子程序
任何程序在运行过程中都需要使用堆栈,操作系统为每一个程序(进程及线程)设置一个堆栈。在使用高级语言编程时,源程序中使用的函数调用、局部变量都要用到堆栈,由编译器来负责生成有关的机器指令。我的理解,堆栈就是维护当前线程中运行状态的一个数据结构,这种状态包括:需要传递的变量,函数的返回地址,局部变量等等。
————————————————
版权声明:本文为CSDN博主「lyyyuna」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lyyyuna/article/details/41211737
栈的其他应用场景
逆序输出
- 栈最大的特点是先进后出,所以逆序输出是栈经常用到的一个应用场景。首先把所有元素依次入栈,然后把所有元素出栈并输出,这样就实现了逆序输出。
语法检查,符号成对出现
- 在我们日常编程中,括号都是成对出现的,比如“()”“[]”“{}”“<>”这些成对出现的符号。
- 那么具体处理的方法就是:凡是遇到括号的前半部分,即把这个元素入栈,凡是遇到括号的后半部分就比对栈顶元素是否该元素相匹配,如果匹配,则前半部分出栈,否则就是匹配出错。
数制转换
- 将十进制的数转换为2-9的任意进制的数。我们都知道,通过求余法,可以将十进制数转换为其他进制,比如要转为八进制,将十进制数除以8,记录余数,然后继续将商除以8,一直到商等于0为止,最后将余数倒着写数来就可以了。
- 比如100的八进制,100首先除以8商12余4,4首先进栈,然后12除以8商1余4,第二个余数4进栈,接着1除以8,商0余1,第三个余数1进栈,最后将三个余数出栈,就得到了100的八进制数144,。
版权声明:本文为CSDN博主「kingdoooom」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kuangsonghan/article/details/79499380
- 参考资料
- 《【经典算法】-算术表达式求值》
- 《以此类推——深入理解递归算法以及应用场景》
- 《汇编学习-堆栈与子程序》
- 《栈的使用场景》
如果不查漏补缺,这题就白做了呢。
可是,我编程的两道题都没写出来,摊手?♀️