阿里云centos7.3配置hadoop2.7伪分布式环境
一、防火墙设置
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
二、修改主机名
vim /etc/hostname
我将主机名修改为master

reboot重启服务器生效
三、修改hosts配置文件
vim /etc/hosts
添加内网ip 主机名

四、安装SSH客户端
(1)安装ssh,询问时输入y
yum install openssh-clients openssh-server
(2)测试ssh是否安装完成
ssh master

(3)配置SSH免key登陆(必须要配置)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
(4)用ssh连接本机,此时不需要密码

五、配置java环境(如果已安装的跳过)
(1)下载解压安装包
由于1.8版本适用范围最广,这里安装jdk1.8版本,先下载安装包。
附百度云下载链接
链接:https://pan.baidu.com/s/1_A1pCLXvCMs5SxmpHPPYfg
提取码:4e9h
在/usr/local/目录下创建一名为java的文件夹,将安装包移入该文件夹。
先转到需要解压的目录下
cd /usr/local/java
解压安装包
tar -zxvf jdk-8u231-linux-x64.tar.gz
(2)添加环境变量
打开配置文件
vim /etc/profile
输入i进行编辑
在末尾加入
export JAVA_HOME=/usr/local/java/jdk1.8.0_231
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}编辑完毕后ctrl+c,输入:wq!回车退出
使配置文件生效
source /etc/profile
(3)查看是否配置成功
分别输入java -version和$JAVA_HOME/bin/java -version查看输出结果是否正确且一致。
六、安装hadoop
(1)下载解压安装包
由于hadoop2.7是最新的稳定版本,这里安装该版本。
在/usr/local/下创建hadoop文件夹,进入该目录下
cd /usr/local/hadoop/
在线下载hadoop安装包
wget http://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/hadoop-2.7.5.tar.gz
在线下载可能会很慢,在此附上百度云下载链接
链接:https://pan.baidu.com/s/1S9kEMpDFSvN9JcH8J0uskA
提取码:2295
解压安装包
tar -zxvf hadoop-2.7.5.tar.gz
查看是否安装成功
/usr/local/hadoop/hadoop-2.7.5/bin/hadoop version

七、修改配置文件
(1)设置环境变量
1.vim ~/.bashrc
结尾添加
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.5
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin使配置文件生效
source ~/.bashrc
2.vim /etc/profile
结尾添加
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
使配置文件生效
source /etc/profile
(2)修改hadoop-env.sh
vim /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
修改内容
export JAVA_HOME=/usr/local/java/jdk1.8.0_231
结尾添加
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.5
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"(2)修改core-site.xml
vim /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/core-site.xml
修改为如下内容
hadoop.tmp.dir
file:/usr/local/hadoop/hadoop-2.7.5/tmp
location to store temporary files
fs.defaultFS
hdfs://master:9000
(3)修改hdfs-site.xml
vim /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
修改为以下内容
//设置HDFS文件副本数
dfs.replication
1
dfs.client.use.datanode.hostname
true
dfs.datanode.use.datanode.hostname
true
//设置HDFS元数据文件存放路径
dfs.namenode.name.dir
file:/usr/local/hadoop/hadoop-2.7.5/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/hadoop-2.7.5/tmp/dfs/data
//设置其他用户执行操作是会提醒没有权限的问题
dfs.permissions
false
(4)修改mapred-site.xml
将/usr/local/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml.template的后缀.template去掉
vim /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
修改为以下内容
mapreduce.framework
yarn
(5)修改yarn-site.xml
vim /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/yarn-site.xml
修改为以下内容
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
(6)修改slaves文件
vim /usr/local/hadoop/hadoop-2.7.5/etc/hadoop/slaves
将localhost直接改成主机名(这里为master),如果有多个结点就每行一个。
八、格式化NameNode
注意:只能格式化一次,如果之后想格式化就必须先清除/usr/local/hadoop/hadoop-2.7.5/tmp
格式化
/usr/local/hadoop/hadoop-2.7.5/bin/hdfs namenode -format

返回0说明格式化成功
九、启动hadoop
/usr/local/hadoop/hadoop-2.7.5/sbin/start-all.sh
第一次启动时会有错误

直接输入yes,之后再启动就不会有错了(不知道为什么,知道的仁兄可以解答一下)。

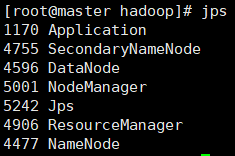
输入jps可以查看进程状态
九、开放端口
需要开放:
50070:为查看hdfs状态
50010:如果不打开这个端口,在browse directory里就查看不了文件
50075:如果不打开这个端口,可能不能在50070里下载文件
我们可以打开ip:50070对hdfs进行操作

9000:配置中把默认端口改为9000了
8088:查看yarn状态
也可以打开ip:8088查看yarn状态

十、基本操作
(1)shell操作(以wordcount为例)
1.在hdfs中建立目录
bin/hdfs dfs -mkdir -p /user/root/input
2.上传文件
bin/hdfs dfs -put wc(源路径) /user/root/input(目标路径)
3.计算
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /user/root/input /user/root/output
4.查看结果
hdfs dfs -cat /user/root/output/p*
5.查看文件/目录
bin/hdfs dfs -ls -R /(目标路径)
6.删除文件/目录
bin/hdfs dfs -rm -r /user/root/output
(2)50070页面操作
点击文件名是可以download的,但是需要先配置本机上的C:\Windows\System32\drivers\etc\hosts文件
在尾部追加/etc/hosts中的内容即可(值得一提的是其中ip地址都必须是公网ip地址)。
在网上看到很多人的50070界面还可以上传、删除,可能是版本问题(我有点想试试高版本了)。
(3)javaAPI操作
在window上调试需要配置hadoop环境,步骤简单多了。
首先下载工具包,附百度云下载链接:
链接:https://pan.baidu.com/s/1h8PIpREHCNlILp9_cDqd6g
提取码:mlhk
将安装包解压至合适路径下,配置环境变量。


hadoop环境就此配好了,另外在项目中还需要添加log4j.properties配置文件(在云服务器hadoop-2.7.5/etc/hadoop/目录下)和jar包,还有如果要上传文件,需要进行configuration.set("dfs.client.use.datanode.hostname", "true");操作,原因我不是很清楚,可以看看这个网站https://segmentfault.com/a/1190000019632252?utm_source=tag-newest