pandas与numpy数据结构
Pandas是python的一个数据分析包,最初由AQR Capital Management于2008年4月开发,并于2009年底开源出来,目前由专注于Python数据包开发的PyData开发team继续开发和维护,属于PyData项目的一部分。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型。(下面的表格只能截图了,mweb编辑的文章不能直接发布到简书)
pandas数据结构
①Series:一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很相近,其区别是:_List中的元素可以是不同的数据类型,而Array和Series中则只允许存储相同的数据类型,这样可以更有效的使用内存,提高运算效率。_
②Time- Series:以时间为索引的Series。
③DataFrame:二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
④Panel :三维的数组,可以理解为DataFrame的容器。
python本身的数据结构
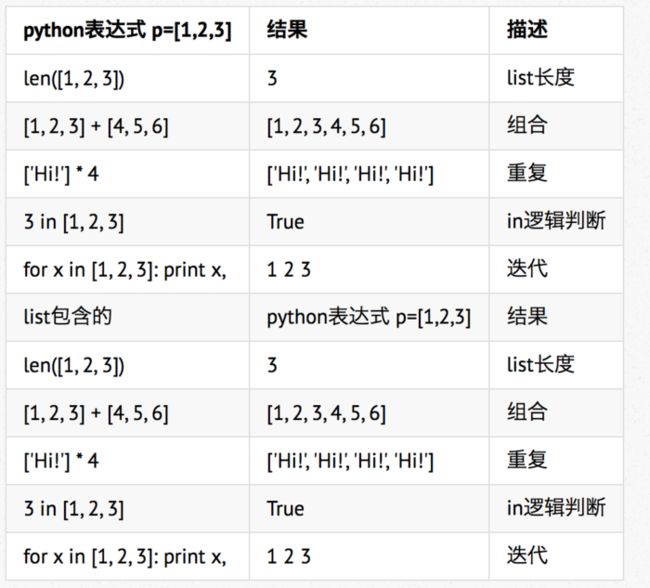
1. list
Python中最基本的数据结构。序列中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。可以使用append()方法来添加列表项。可以使用 del 语句来删除列表的的元素。


2.元组
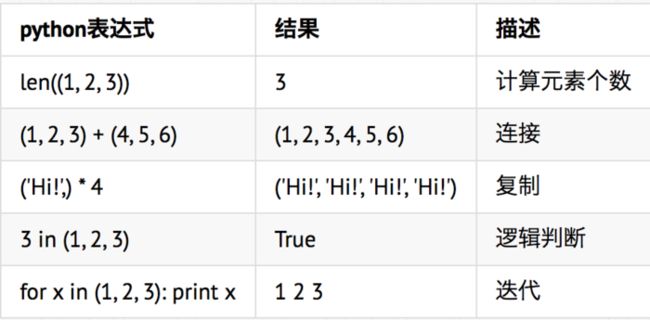
元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
元组中只包含一个元素时,需要在元素后面添加逗号;
元组可以使用下标索引来访问元组中的值:
tup2[1:5]: (2, 3, 4, 5)
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组
元组运算
3.字典
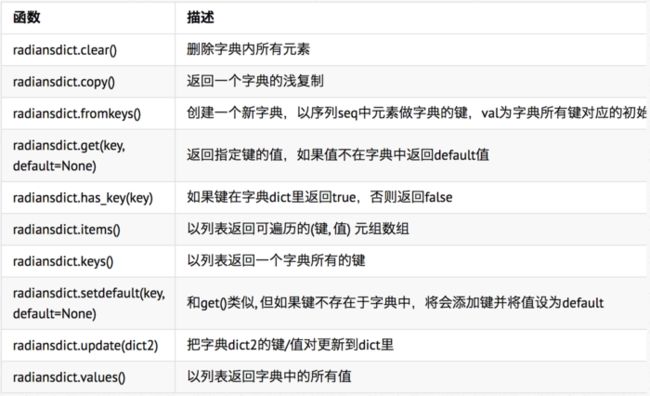
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中
d = {key1 : value1, key2 : value2 }
键必须是唯一的,但值则不必。
访问字典里的值:把相应的键放入熟悉的方括弧
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对如下实例:
dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'};
dict['Age'] = 8; # update existing entry
dict['School'] = "DPS School"; # Add new entry
能删单一的元素也能清空字典,清空只需一项操作。

Numpy数据结构
1. ndarray 数组
* ndarray是一个通用的同构数据多维容器,即所有元素必须是相同类型
* 每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(说明数组数据类型) NumPy数组的维数称为秩(rank),一维数组的秩为1,二维数组的秩为2 data=array([[1, 9, 6], [2, 8, 5], [3, 7, 4]])

基本的索引和切片
arr=np.arange(10)
arr[5:8]切片第6个到第8个元素
视图上的任何修改都会直接反映到源数组上。如arr[5:8]=12,则源数组的第6到第8个元素都会赋值为12.
arr[5:8].copy() 切片副本
arr2d[:2,1:] 切片第0,1行向量与第1,2列向量交组成的数组
names = np.array(['Bob','Joe'])
arr[names == 'Bob'] 布尔型索引
花式索引
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
整数列索引 arr[[4,3,0,6]], arr[[-3,-5,-7]]
多个索引组
arr = np.arange(32).reshape((8,4))
arr[[1,5,7,2],[0,3,1,2]] 得到 array([4, 23, 29, 10])
arr[[1,5,7,2]][:,[0,3,1,2]]
得到
array([[4,7,5,6],
[20,23,21,22],
[28,31,29,30],
[8,11,9,10]])
np.ix_同样可以得到以上结果
arr[np.ix_([1,5,7,2],[0,3,1,2])]
花式索引总是将数据复制到新数组中
其他方法和属性
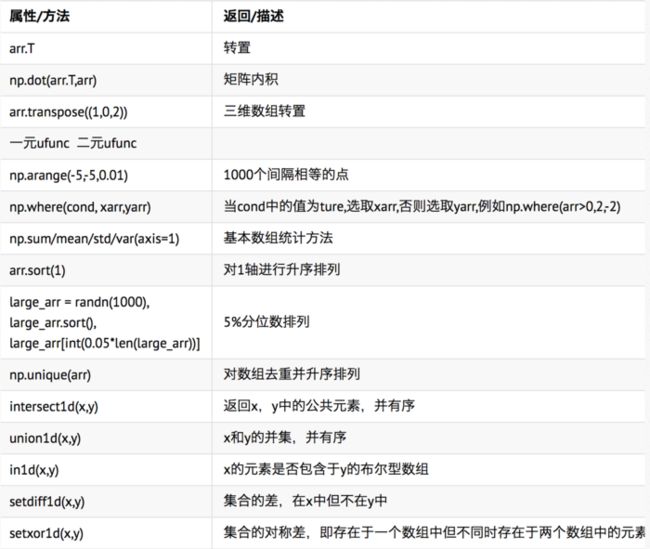
布尔值在计算过程中可以被当做0或1处理
例如,result = 1* (cond1 -cond2) + 2*(cond2 & -cond1) + 3 * -(cond1 | cond2)
数组文件的输入输出
arr=np.arange(10)
np.save('some_array', arr) 将数组以二进制格式,some_array.npy名称保存在磁盘上。
np.load('some_array.npy')加载
np.savez('array_archive.npz', a=arr, b=arr) 将多个数组保存在压缩文件中
存取文本文件
arr = np.loadtxt('array_ex.txt',delimiter=',')将文件中数据加载到二维数组中
np.savetxt执行相反操作
线性代数计算
x.dot(y) 相当于np.dot(x,y)
inv(mat) 对可逆矩阵求逆
……
随机数生成
* numpy.random模块
* np.random.normal(size=(4,4))生成标准正态分布的4*4样本数组
* seed 确定随机数生成器的种子
* permutation 返回一个序列的随机排列或返回一个随机排列的范围
* shuffle 对一个序列就地随机排列
* rand 产生均匀分布的样本值
* randint 从给定的上下限范围随机取整数
pandas数据结构
1.Series结构 类似于一维数组的对象,索引在左边,值在右边,若不指定索引,会自动创建一个0~N-1的整数型索引 In: obj2 = Series([4,7,-5,3], index=['d','b','a','c']) Out: d 4 b 7 a -5 c 3

2.Pandas DataFrame结构 DataFrame是一个表格型数据结构,每列可以是不同的值类型(数值、字符串、布尔值等),它可以被看成由Series组成的字典,它既有行索引也有列索引。以一个或多个二维块存放(而不是列表、字典或别的一维数据结构) 构建DataFrame的方法:
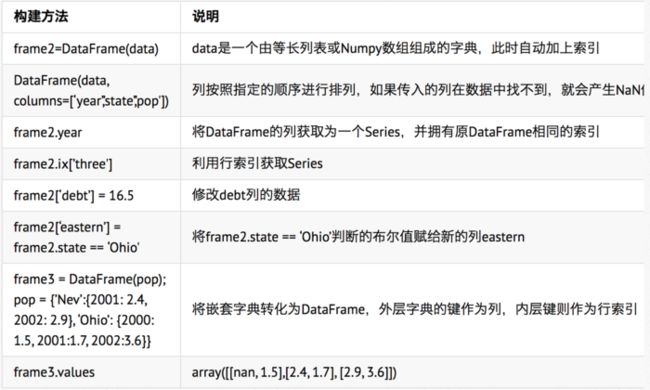
索引对象
1.pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。index对象是不可以修改的,这样才能使index对象在多个数据结构之间安全共享。
2.重新索引 reindex
obj2 = obj.reindex(['a','b','c','d','e'])
按照reindex新索引进行重排,如果某个索引值不存在,就引入缺失值,
obj.reindex(['a','b','c','d','e'], fill_value=0), 将缺失值赋值为0
使用ffill可以实现前向值填充:
obj3 = Series(['blue','pureple','yellow'], index=[0,2,4])
obj3.reindex(range(6),method='ffill')
fill/pad 前向填充(或搬运)值
bfill/backfill 后向填充值
如果只传入一个序列则会重新索引行
使用columns关键字即可重新索引列:
frame.reindex(columns=states)
同时重新索引:frame.reindex(index=['a','b','c','d'], method='ffill', columns=states)
limit 前向或后向填充时的最大填充量
ix使重新索引更加简洁:frame.ix[['a','b','c','d'],states]
1.其他功能
2.汇总和计算描述统计
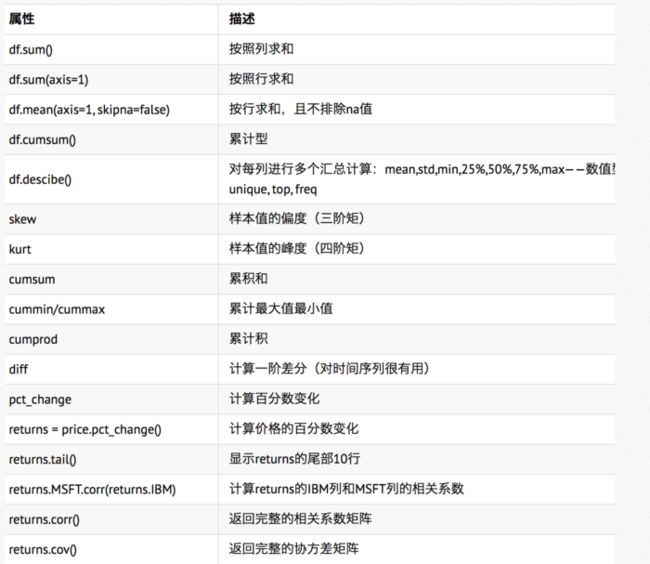
缺失值处理

层次化索引
data=Series(np.random.randn(10),index=[['a','a','a','b','b','b','c','c','d','d'],[1,2,3,1,2,3,1,2,2,3]] In: data.index Out: Multiindex[('a',1),('a',2)....] 层次化索引在数据重塑和基于分组的操作(如透视表生成)中扮演着重要角色, data.unstack()转化为一个DataFrame,其逆运算是stack data.unstack().stack()
对于DataFrame每条轴都可以有分层索引
frame = DataFrame(np.arange(12).reshape((4,3)), index=[['a','a','b','b'],[1,2,1,2]],columns=[['Ohio','Ohio','Colorado'],['Green','Red','Green']])
数据加载、存储与文件格式
1. 读写文本格式数据

2.逐块读取文本文件
在处理很大的文件时,可能只想读取文件的一小部分或逐块对文件进行迭代 pd.read_csv(‘ch06/ex6.csv’, nrow=5) 只读取几行 chunker=pd.read_csv(‘ch06/ex6.csv’,chunksize=1000) #设置每次处理行数
tot = Series([])
for piece in chunker:
tot = tot.add(piece['key'].value_counts(), fill_value=0)
tot =tot.ordr(ascending=False)
3.将数据写出到文本格式
data.to_csv('ch06/out.csv') data.to_csv(sys.stout, sep='|') #指定分隔符
data.to_csv(sys.stout, na_rep='NULL')
4.手工处理分隔符格式
直接使用Python内置的csv模块
import csv
f = open('cho6/ex7.csv')
reader = csv.reader(f)
for line in reader:
print line
这样得到一系列列表
为时数据格式合乎要求,做如下操作
lines = list(csv.reader(open('cho6/ex7.csv')))
header, values = lines[0],lines[1:]
data_dict = {h: v for h, v in zip(header, zip(*values))}
定义子类处理各种分隔符:
class my_dialect(csv.Dialect):
lineterminator = '\n'
delimiter = ';'
quotechar = '"'
reader = csv.reader(f, diaect=my_dialect)
JSON数据
JSON= JavaScript Object Notation
1.加载json数据
result=json.loads(obj)
2.将Python对象转为json格式
asjson=json.dumps(result)
3.转换为DataFrame结构
siblings = DataFrame(result['siblings'],columns=['name','age'])
4.web信息收集
from lxml.html import parse
from urllib2 import urlopen
parsed =parse(urlopen('http://www.baidu.com'))
doc = parsed.getroot()
获取该页面的所有URL
urls = [lnk.get('href') for lnk in doc.findall('.//a')]
a.pop() # 把最后一个值4从列表中移除并作为pop的返回值
a.append(5) # 末尾插入值,[1, 2, 3, 5]
a.index(2) # 找到第一个2所在的位置,也就是1
a[2] # 取下标,也就是位置在2的值,也就是第三个值3
a += [4, 3, 2] # 拼接,[1, 2, 3, 5, 4, 3, 2]
a.insert(1, 0) # 在下标为1处插入元素0,[1, 0, 2, 3, 5, 4, 3, 2]
a.remove(2) # 移除第一个2,[1, 0, 3, 5, 4, 3, 2]
a.reverse() # 倒序,a变为[2, 3, 4, 5, 3, 0, 1]
a[3] = 9 # 指定下标处赋值,[2, 3, 4, 9, 3, 0, 1]
b = a[2:5] # 取下标2开始到5之前的子序列,[4, 9, 3]
c = a[2:-2] # 下标也可以倒着数,方便算不过来的人,[4, 9, 3]
d = a[2:] # 取下标2开始到结尾的子序列,[4, 9, 3, 0, 1]
e = a[:5] # 取开始到下标5之前的子序列,[2, 3, 4, 9, 3]
f = a[:] # 取从开头到最后的整个子序列,相当于值拷贝,[2, 3, 4, 9, 3, 0, 1]
a[2:-2] = [1, 2, 3] # 赋值也可以按照一段来,[2, 3, 1, 2, 3, 0, 1]
g = a[::-1] # 也是倒序,通过slicing实现并赋值,效率略低于reverse()
a.sort()
print(a) # 列表内排序,a变为[0, 1, 1, 2, 2, 3, 3]