Python爬虫实战之爬取QQ音乐数据
目录
- 准备工作
- 安装方法
- 步骤
- 新建py文件
- 复制网页链接
- 获取源代码
- 获取数据
- 源代码
这里用QQ音乐作为一个例子。不同的链接,按照此方法都可做到。
本次程序编写原则上按照模块化进行划分,一个步骤一个函数。
分别:main()、open_url(url)、find_attribute()。
准备工作
准备如下几个工具。BeautifulSoup包、IDLE
对前端的知识有一定的理解
安装方法
1.IDLE下载链接
2.BeautifulSoup包在拥有IDLE的前提下输入win+r
3.输入cmd 进入命令提示符
4.输入命令 pip install BeautifulSoup4
步骤
- 新建py文件
- 复制网页链接
- 获取网页源代码
- 获取数据
- 自定义保存
新建py文件
建立函数结构
import urllib.request
from bs4 import BeautifulSoup
def open_url(url):
pass
def find_attribute(url):
pass
def main():
pass
复制网页链接
复制网页链接将链接用列表进行保存下来。如果想要同一时间获取多个网页里面的数据,自行书写for循环遍历列表即可。以下只以一个网页进行讲解。

def main():
# 用列表进行存储网页链接
url = "https://y.qq.com/n/yqq/playlist/7174020835.html#stat=y_new.index.playlist.name"
# 将url传到该函数进行获取数据该功能
find_attribute(url)
获取源代码
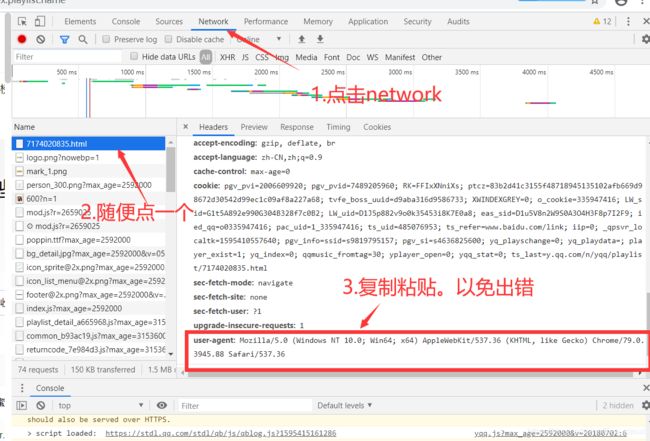
def open_url(url):
req = urllib.request.Request(url)
# 模拟电脑访问
# 按F12按照图片所示操作即可获取添加
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36")
# 给网页发送请求。网页就会返回一个响应给我们
response = urllib.request.urlopen(req)
# 获取源代码
html = response.read()
# 将源码以utf-8 的形式进行解码
return html.decode("utf-8")
获取数据
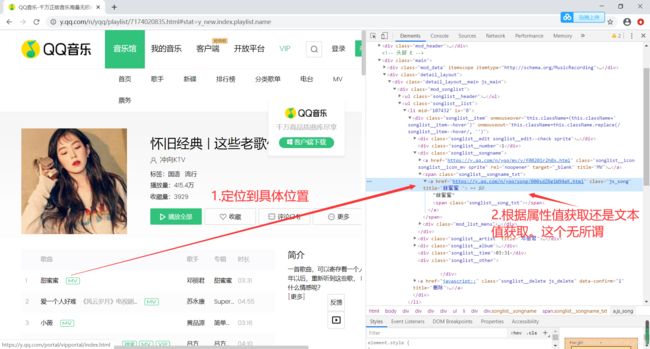
使用select定位的方法。有可能存在以下问题:
1.定位不准确,会导出网页其他的内容
2.找不到内容,原因:定位深度有限。解决方案:父子关系多写几层用>符号进行建立父子关系
3.对于类选择题,ID选择器有不同的方法进行搜索。
自行上网进行查阅。关键字:beautifulsoup.select方法的使用
每一次书写select定位的方法可以使用print进行打印。
获取的数据是用列表进行存储的。
def find_attribute(url):
# 此处返回的html就是网页的源代码
# 可以用print(html) 打印观看一下效果
html = open_url(url)
# 利用BeautifulSoup将源代码进行解析
soup = BeautifulSoup(html,"lxml")
# 通过标签进行选择数据即可
# 定位的方法具体如图片所示
# 30
# 排名
ranks = soup.select("div.songlist__number")
# 歌曲
musics = soup.select("span.songlist__songname_txt > a")
# 歌手
singers = soup.select("div.songlist__artist > a")
# 专辑
albums = soup.select("div.songlist__album > a")
# 时长
times = soup.select("div.songlist__time")
list1 = []
# 连接列表。用循环打印
# 再存放到字典当中
for rank,music,singer,album,time in zip(ranks,musics,singers,albums,times):
data = {
# 获取文本用 get_text()
# 获取属性值用['属性']
"排名":rank.get_text(),
"歌曲":music["title"],
"歌手":singer["title"],
"专辑":album["title"],
"时长":time.get_text()
}
# 追加到列表当中
list1.append(data)
print(list1)
源代码
import urllib.request
from bs4 import BeautifulSoup
def open_url(url):
req = urllib.request.Request(url)
# 模拟电脑访问
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36")
response = urllib.request.urlopen(req)
html = response.read()
# 将源码以utf-8 的形式进行解码
return html.decode("utf-8")
def find_attribute(url):
html = open_url(url)
soup = BeautifulSoup(html,"lxml")
# 通过标签进行选择数据即可
# 30
# 排名
ranks = soup.select("div.songlist__number")
# 歌曲
musics = soup.select("span.songlist__songname_txt > a")
# 歌手
singers = soup.select("div.songlist__artist > a")
# 专辑
albums = soup.select("div.songlist__album > a")
# 时长
times = soup.select("div.songlist__time")
list1 = []
for rank,music,singer,album,time in zip(ranks,musics,singers,albums,times):
data = {
"排名":rank.get_text(),
"歌曲":music["title"],
"歌手":singer["title"],
"专辑":album["title"],
"时长":time.get_text()
}
list1.append(data)
print(list1)
def main():
# 第一步:将url传过去利用一定手段返回网页的源码
# 第二步:源码获取了之后
# 第三步:通过标签的父子关系进行定位
# 第四步:将获取的数据,进行一个保存
# 如果有多个url添加for循环修改地址即可
# 这里只演示单个网页
url = "https://y.qq.com/n/yqq/playlist/7174020835.html#stat=y_new.index.playlist.name"
# 为了更加好看。设计模块化罢了
find_attribute(url)
if __name__ == "__main__":
main()