基本Java语言特性
Java是一种面向对象的编程语言,但是Java比使用对象编程更多。本文开始一个分为三部分的小系列,介绍一些基于Java语言的非面向对象特性和语法。了解为什么Unicode将ASCII替换为Java的通用编码标准,然后了解如何在Java程序中使用注释,标识符,类型,文字和变量。
请注意,本文中的示例是使用Java 8编写的。
Unicode和字符编码
当您保存程序的源代码(通常在文本文件中)时,字符将进行编码以进行存储。历史上,ASCII(美国信息交换标准代码)用于对这些字符进行编码。因为ASCII只限于英语,所以Unicode是作为替换开发的。
Unicode是一种计算行业标准,用于一致地编码,表示和处理在世界上大多数写作系统中表达的文本。Unicode使用字符编码来对字符进行编码以进行存储。两种常用的编码是UTF-8和UTF-16。您将在本文后面了解Java对Unicode的支持如何影响您的源代码和编译。
从头开始学习Java
你刚刚开始使用Java?请参见Jeff的第一篇Java 101系列教程:“ 从头开始学习Java。
注释:三种方式记录您的Java代码
假设你在一家大公司的IT部门工作。你的老板指示你写一个由几千行源代码组成的程序。几个星期后,您完成该程序并部署它。几个月后,用户开始注意到程序偶尔崩溃。他们抱怨你的老板,他命令你修复它。在搜索项目存档后,您会遇到一个文件夹文件夹列出程序的源代码。不幸的是,你发现源代码没有什么意义。自从创建这个项目以来,你一直在处理其他项目,你不能记得为什么你写的代码。可能需要几个小时甚至几天的时间来解密你的代码,但你的老板想要一个解决方案昨天。谈论主要压力!你是做什么?
你可以通过用有意义的描述记录源代码来避免这种压力。虽然经常被忽略,在编写程序的逻辑时记录源代码是开发人员最重要的任务之一。正如我的例子所示,离开代码有一段时间,即使原来的程序员可能不了解某些决定背后的推理。
在Java中,您可以使用注释功能将文档嵌入到源代码中。一个注释是文本分隔块这是对人类有意义而不是编译器。当编译源代码时,Java编译器忽略所有注释; 它不会为它们生成字节码。Java支持单行,多行和Javadoc注释。让我们看看每个例子。
单行注释
一个单行注释跨越一行。它从//当前行开始并继续到当前行的结尾。编译器忽略从//该行末端开始的所有字符。以下示例介绍单行注释:
System.out.println((98.6 - 32) * 5 / 9);
// Output Celsius equivalent of 98.6 degrees Fahrenheit.单行注释对于指定给定代码行后面的意图的简短有意义的描述是有用的。
多行注释
一个多行注释跨越多行。它开始于/*和结束于*/。来自/*through的所有字符*/被编译器忽略。以下示例提供了一个多行注释:
/*
An amount of $2,200.00 is deposited in a bank paying an annual
interest rate of 2%, which is compounded quarterly. What is
the balance after 10 years?
Compound Interest Formula:
A = P(1+r/n)nt
A = amount of money accumulated after n years, including interest
P = principal amount (the initial amount you deposit)
r = annual rate of interest (expressed as a decimal fraction)
n = number of times the interest is compounded per year
t = number of years for which the principal has been deposited
*/
double principal = 2200;
double rate = 2 / 100.0;
double t = 10;
double n = 4;
System.out.println(principal * Math.pow(1 + rate / n, n * t));如您所见,多行注释对于记录多行代码非常有用。或者,您可以为此目的使用多个单行注释,如下所示:
// Create a ColorVSTextComponent object that represents a component
// capable of displaying lines of text in different colors and which
// provides a vertical scrolling capability. The width and height of
// the displayed component are set to 180 pixels and 100 pixels,
// respectively.
ColorVSTextComponent cvstc = new ColorVSTextComponent(180, 100);多行注释的另一个用途是注释掉你不想编译的代码块,但仍然希望保留,因为将来可能需要它们。以下源代码演示了此场景:
/*
if (!version.startsWith("1.3") && !version.startsWith("1.4"))
{
System.out.println("JRE " + version + " not supported.");
return;
}
*/ 不要嵌套多行注释,因为编译器将报告错误。例如,编译器在遇到错误消息时会输出错误消息/* This /* nested multiline comment (on a single line) */ is illegal */。
Javadoc评论
一个Javadoc注释是一个特殊的多行注释。它开始于/**和结束于*/。来自/**through的所有字符*/被编译器忽略。以下示例介绍Javadoc注释:
/**
* Application entry point
*
* @param args array of command-line arguments passed to this method
*/
public static void main(String[] args)
{
// TODO code application logic here
} 此示例的Javadoc注释描述了该main()方法。夹在之间/**,*/是对方法和@paramJavadoc标记(@对javadoc工具的一个 - 前缀指令)的描述。
考虑这些常用的Javadoc标签:
-
@author标识源代码的作者。 -
@deprecated标识不应再使用的源代码实体(例如,方法)。 -
@param标识方法的参数之一。 -
@see提供了一个see-also参考。 -
@since标识实体最初创建的软件版本。 -
@return标识该方法返回的值的类型。 -
@throws记录从方法抛出的异常。
虽然由编译器忽略,Javadoc注释由处理javadoc,它们将它们编译为基于HTML的文档。例如,以下命令生成假设Checkers类的文档:
javadoc Checkers 生成的文档包括描述文档起始页的索引文件(index.html)。例如,图1显示了来自Java SE 8更新45运行时库API文档的起始页。
图1. Java SE 8u45运行时库API文档由javadoc生成。
标识符:在Java代码中的命名类,方法等
必须命名各种源代码实体(如类和方法),以便可以在代码中引用它们。Java为此提供了标识符特征,其中标识符只是源代码实体的名称。
标识符由字母(AZ,az或其他人字母表中的等效大写/小写字母),数字(0-9或其他人字母表中的等效数字),连接标点符号(如下划线)和货币符号如美元符号)。此名称必须以字母,货币符号或连接标点符号开头。此外,它不能从一行换行到下一行。
以下是一些有效标识符的示例:
-
i -
count2 -
loanAmount$ -
last_name -
$balance -
π(希腊字母Pi - 3.14159)
许多字符序列不是有效的标识符。考虑以下示例:
-
5points,因为它以数字开头 -
your@email_address,因为它包含一个@符号 -
last name,因为它包括一个空格
Java在Java中很重要
Java是一种区分大小写的语言,这意味着仅在情况下不同的标识符被认为是单独的标识符。例如,age并且Age是单独的标识符。
几乎可以选择任何有效的标识符来命名类,方法或其他源代码实体。但是,Java为特殊目的保留了一些标识符; 它们被称为保留字。Java保留以下标识符:
表1. Java中的保留字
| 抽象 | 断言 | 布尔 | 打破 | 字节 |
| 案件 | 抓住 | char | 类 | const |
| 继续 | 默认 | 做 | 双 | 其他 |
| 枚举 | 延伸 | 假 | 最后 | 最后 |
| 浮动 | 对于 | 去 | 如果 | 实现 |
| 进口 | instanceof | int | 接口 | 长 |
| 本机 | 新 | 空值 | 包 | 私人的 |
| 保护 | 上市 | 返回 | 短 | 静态的 |
| strictfp | 超 | 开关 | 同步 | 这个 |
| 扔 | 抛出 | 短暂的 | 真正 | 尝试 |
| void | 挥发性 | 而 |
当编译器检测到在其使用上下文之外使用这些保留字中的任何一个时,输出错误消息; 例如,作为类或方法的名称。Java也保留但不使用const和goto。
保留字,关键字和文字
大多数Java的保留字也称为关键字。三个例外是false,null和true,这是文字的例子。我会在稍后讨论这些。
类型:在Java代码中分类值
Java应用程序处理字符,整数,浮点数,字符串和其他类型的值。所有相同类型的值具有某些特性。例如,整数没有分数,字符串是具有长度概念的字符序列。
Java提供了用于对值进行分类的类型功能。一个类型是一组值,其在存储器中的表示,以及用于操纵这些值,通常它们转化成其它值的一组操作。例如,整数类型描述一组不带小数部分的数字,二进制补码表示(我将在后面解释二进制补码),以及产生新整数的加法和减法等操作。
Java是一种强类型语言
在强类型语言(如Java)中,每个变量,表达式等都具有编译器已知的类型。此功能帮助编译器在编译时检测与类型相关的错误,而不是在原点难以找到的运行时出现这些错误。我将在本文后面讨论变量,并将表达式的覆盖延迟到本系列的下一篇文章。
Java支持基本类型,引用类型和数组类型。
原始类型
一个基本类型是可以被语言和其值不是对象定义的类型。Java支持一些原始类型:
- 布尔值
- 字符
- 字节整数
- 短整数
- 整数
- 长整数
- 浮点
- 双精度浮点
在继续讨论引用和数组类型之前,我们将考虑这些。
原语的问题
许多开发人员希望Java不支持原始类型,因为他们喜欢对象无处不在,而其他人则认为原语具有独特和必要的用途。
布尔值
布尔类型描述true / false值。的JVM规范指示存储在一个阵列(后面将讨论)的布尔值被表示为在存储器8位(二进制位)的整数值。此外,当它们出现在表达式中时,这些值表示为32位整数。Java提供AND,OR和NOT操作来操作布尔值。此外,其boolean保留字标识源代码中的布尔类型。
请注意,JVM对布尔值提供的支持非常少。Java编译器将它们转换为32位值,1表示真,0表示假。
字符
字符类型根据分配的Unicode编号描述字符值(例如,大写字母A,数字7和星号[*]符号)。(例如,65是大写字母A的Unicode编号。)字符值在内存中表示为16位无符号整数值。对字符执行的操作包括分类,例如分类给定字符是否是数字。
将Unicode标准从16位扩展到32位(以适应更多的书写系统,例如埃及象形文字)有些复杂了字符类型。它现在描述基本多语言平面(BMP)代码点,包括代理代码点或UTF-16编码的代码单元。如果您想了解BMP,代码点和代码单元,请学习Character该类的Java API文档。然而,在大多数情况下,您可以简单地将字符类型视为适应字符值。
整数类型
由于空间和精度原因,Java支持四种整数类型:字节整数,短整数,整数和长整数。基于较短整数的数组不消耗太多空间。涉及更长整数的计算给您更高的精度。与无符号字符类型不同,整数类型是有符号的。
字节整数
字节整数类型描述以8位表示的整数; 它可以容纳范围从-128到127的整数值。与其他整数类型一样,字节整数存储为二进制补码值。在二进制补码中,所有的比特被翻转,从一个到零,从零到一,然后将数字1加到结果。最左边的位称为符号位,所有其他位指的是数字的幅度。该表示在图2中示出。
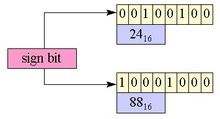
图2.正和负8位整数的内部表示由符号和幅度组成。
字节整数对于在数组中存储小值最有用。编译器生成字节码以在执行诸如加法的数学运算之前将字节整数值转换为整数值。Java的byte保留字标识源代码中的字节整数类型。
短整数
短整数类型描述以16位表示的整数; 它可以容纳范围从-32,768到32,767的整数值。它具有与字节整数相同的内部表示,但具有更多的位以适应其较大的量值。编译器生成字节码以在执行数学运算之前将短整数值转换为整数值。Java的short保留字标识源代码中的短整数类型。
整数类型
整数类型描述以32位表示的整数; 它可以适应范围从-2,147,483,648到2,147,483,647的整数值。它具有与字节整数和短整数相同的内部表示,但具有更多的位以适应其较大的量值。Java的int保留字标识源代码中的整数类型。
长整数
长整数类型描述以64位表示的整数; 它可以容纳范围从-2 63到2 63 -1的整数值。它具有与字节整数,短整数和整数相同的内部表示,但具有更多的位以适应其较大的量值。Java的long保留字标识源代码中的长整数类型。
浮点类型
由于空间和精度原因,Java支持两种浮点类型。较小的类型在数组上下文中很有用,但不能容纳大范围的值。虽然它在数组上下文中占用更多的空间,但是更大的类型可以容纳更大的范围。
浮点类型描述以32位表示的浮点值; 它可容纳范围从大约+/- 1.18x10浮点值-38到大约+/- 3.4×10 38。它以IEEE 754格式表示,其中最左边的位是符号位(0表示正,1表示负),接下来的8位保存指数,最后的23位保存尾数,导致大约6-9个十进制精度数字。Java的float保留字标识源代码中的浮点类型。
双精度浮点类型描述以64位表示的浮点值; 它可以容纳浮点值范围从大约+/- 2.23x10 -308至大约+/- 1.8× 308。它以IEEE 754格式表示,其中最左边的位是符号位(0表示正,1表示负),接下来的11位保存指数,最后52位保存尾数,导致约15-17的十进制精度数字。Java的double保留字标识源代码中的双精度浮点类型。
参考类型
一个引用类型是从中创建或参考的对象类型,其中一个参考是某种指针的对象。(引用可以是实际内存地址,内存地址表中的索引,或其他内容。)引用类型也称为用户定义类型,因为它们通常由语言用户创建。
Java开发人员使用类功能来创建引用类型。一类是无论是对一个应用程序的一个占位符main()的方法(参见HelloWorld在“应用从地了解的Java向上 ”为一个例子main())或各种static方法,或者它的用于制造物体,这是我下面演示模板:
class Cat
{
String name; // String is a special reference type for describing strings
Cat(String catName)
{
name = catName;
}
String name()
{
return name;
}
} 这个类声明引入了一个描述feline的Cat类。它的name字段将cat的名称存储为字符串,其构造函数将此数据成员初始化为cat名称,并且其name()方法返回cat的名称。以下代码片段(可能位于main()方法中)显示了如何制造cat并获取其名称:
Cat cat = new Cat("Garfield");
System.out.println(cat.name()); // Output: Garfield 该接口的功能可以让你引用一个对象,而该对象的类类型的关注。只要对象的类实现了接口,该对象也被认为是接口类型的成员。考虑下面的例子,它声明一个Shape接口Circle和Rectangle类:
interface Shape
{
void draw();
}
class Circle implements Shape
{
void draw()
{
System.out.println("I am a circle.");
}
}
class Rectangle implements Shape
{
void draw()
{
System.out.println("I am a rectangle.");
}
}无法编译?检查可见性。
如果你试图编译上面的代码,你会得到一个错误信息。问题是,Shape的draw()方法有公众知名度,而每个Circle年代和Rectangle的draw()方法有包的知名度。您可以通过预先解决这个问题public,以Circle年代和Rectangle的draw()方法头,如public void draw()。我将在后续的Java 101文章中详细解释可见性。
下一个代码片段实例Circle化Rectangle,并将它们的引用分配给Shape变量,并要求他们绘制自己:
Shape shape = new Circle();
shape.draw(); // Output: I am a circle.
shape = new Rectangle();
shape.draw(); // Output: I am a rectangle. 你可以使用接口从一组不同的类中抽象出通用性。作为一个例子,一个Inventory接口将提取的共同性Goldfish,Car以及Hammer类,因为这些物品可以被清点。当与数组和循环结合使用时,接口提供了相当大的能力,您将在本系列的后面部分中了解。
字符串中的语法糖
该String类型描述一个字符串,独立的作为Java的唯一类型,包括特殊的语言支持。例如,考虑如何创建包含字符串的String对象Java,然后将其引用分配给变量language。如果String像其他类型,你需要指定String language = new String("Java");; 但是因为String是特殊的,你可以指定以下代替:String language = "Java";。
这是一个语法糖的例子- 一种“甜化”语言的结构规则。字符串连接也受益于语法糖。例如,您可以指定,甚至更短:而不是指定language = language.concat(" rules!");生成。Java rules!language = language + " rules!";language += " rules!";
String在本系列的后面部分,您将了解更多关于引用类型的内容。
数组类型
Array是我们的三种类型中的最后一种。一个数组类型是表示一个特殊引用类型的数组,这是一个内存区域,在该大小相等,并且(通常)的连续时隙存储值。这些值通常被称为元素。数组类型由元素类型(基本类型或引用类型)和一个或多个方括号对组成,这些方括号表示数组占用的维数(范围)数。单对括号表示一维数组(向量); 两对括号表示二维数组(表); 三对括号表示一维二维数组(表的向量); 等等。例如,int[]表示一维数组(具有int作为元素类型),并且String[][]表示二维数组(具有String作为元素类型)。
void类型
除了基本类型,引用类型和数组类型之外,Java还支持void类型,由保留字表示void。void类型在方法头上下文中使用,表示方法不返回值。例如,public static void main(String[] args)头指定void为其返回类型,因为该main()方法从不向其调用者返回值(尽管您可以通过方法调用返回一个整数退出代码)。System.exit(integer);
文字:在Java代码中指定值
Java提供了用于在源代码中嵌入值的文字语言特性。一个文字是一个值的字符表示。每个基本类型与其自己的字面值集相关联:
布尔基元类型与文字true或相关联false。
字符基本类型与字符文字相关联,字符文字通常由单引号之间的单个值组成,如大写字母A('A')。或者,您可以指定转义序列或Unicode转义序列。考虑每个选项:
- 一个转义序列是不能在字符字面字面表达字符或字符串表示。转义序列用一个反斜杠字符开头(
\),后面跟着一个\,',",b,f,n,r,或t。您必须始终转义要反映的字符,以通知编译器它没有引入转义序列。您必须始终转义在字符文字中表达的单引号,以通知编译器该单引号不结束字符文字。类似地,您必须始终转义在字符串文字中表达的双引号,以通知编译器双引号不结束字符串文字。其他转义序列用于没有符号表示的字符:\b表示退格,\f表示换页,\n表示新行,\r表示回车,并且\t表示水平制表符。换码序列出现在字符文字上下文中的单引号之间(例如,'\n')。 - 一个Unicode转义序列是任意的Unicode字符的表示。它由一个
\u前缀紧跟着四个十六进制数字组成。例如,\u0041表示大写字母A,并且\u3043表示平假名字母。Unicode转义序列出现在字符文字上下文中的单引号之间(例如,'\u3043')。
整数类型与由数字序列组成的文字相关联,可选择嵌入下划线字符。默认情况下,整数字面值被赋予integer(int)类型。您必须使用大写字母L(或小写字母l,可能与数字混淆1)后缀字母表示一个长整数值。整数文字可以用二进制,十进制,十六进制和八进制格式指定:
- 二进制包含数字0和1,前缀为
0b或0B。示例:0b01111010。 - 小数由0到9的数字组成,没有前缀。示例:
2200。 - 十六进制由数字0到9,小写字母a到f和大写字母A到F组成。此文本带有
0x或的前缀0X。示例:0xAF。 - 八进制由数字0到7组成并带有前缀
0。示例:077。
为了提高可读性,可以在数字之间插入下划线字符; 例如,1234_5678_9012_3456L。您不能像前面那样指定前导下划线,_1234因为编译器会假定正在指定标识符。您也不能指定尾随下划线。
浮点类型与由非小数部分,小数点,小数部分,可选指数的文字有关,或者是可选的双精度浮点型字母D或d,或者浮点类型字母F或f。浮点文字的例子包括2.7818,0.8D,-57.2E+31,和3.14159f。如果没有D,d,F,也不f存在,类型默认为双精度浮点。如果D或d存在,类型也是双精度浮点。但是,如果F或f指定,类型是浮点型。
对于浮点类型,您可以在数字之间插入下划线字符; 例如,1.234_567e+56。您不能指定前导下划线(例如,_1.234),因为编译器会假定正在指定标识符。您还不能指定尾随下划线(例如,1.5_),小数点任一侧的下划线(例如,2_.3或2._3),当指数存在时(或)的e或E字符之前或之后的下划线,随后的任何一个或字符的任何一侧或(例如,或)。1.2_e31.2E_3+-eE2.8e_+23.1E-_5
引用类型文字
每个引用类型与特定null文字相关联,以指示无引用。该String引用类型与一组字符串相关的。这些从双引号开始; 继续使用文字字符,转义序列和Unicode转义序列; 并以双引号结束。这里有一个例子:"Hello, \"Java\""。
变量:在Java代码中存储值
应用程序操作存储在内存中的值。Java的变量特性象征性地表示源代码中的内存。一个变量是存储某些类型的值的命名的存储单元。对于基本类型,值直接存储在变量中。对于引用类型的变量,引用存储在变量中,引用引用的对象存储在其他地方。存储引用的变量通常称为引用变量。
您必须在使用变量之前声明该变量。变量声明最少由一个类型名称,可选地后跟一系列方括号对,后跟一个名称,可选地后跟一系列方括号对,并以分号字符(;)结尾。考虑以下示例:
int age; // Declare integer variable age.
float interest_rate; // Declare floating-point variable interest_rate.
String name; // Declare String variable name.
Car car; // Declare Car variable car.
char[] text; // Declare one-dimensional character array variable text.
double[][] temps; // Declare two-dimensional floating-point array variable temps.上述变量需要在使用前进行初始化。您可以将变量初始化为其声明的一部分:
int age = 25;
float interest_rate = 4.0F;
String name = "Java";
Car car = new Car();
char[] text = { 'J', 'a', 'v', 'a' };
double[][] temps = { { 25.0, 96.2, -32.5 }, { 0.0, 212.0, -41.0 }}; 每个初始化要求=后跟一个文字,一个以new或者开头的对象创建表达式,或者一个数组初始化器(仅适用于数组类型)。数组初始化器由一个括号分隔和逗号分隔的文字列表和(对于多维数组)嵌套数组初始化器组成。
注意,该text示例创建一个由四个元素组成的一维字符数组。该temps示例创建一个双行一列三列的双精度浮点值二维数组。数组初始值设定器指定两个行数组,每个行数组包含三个列值。
或者,您可以通过省略类型在声明后初始化变量,如下所示:
age = 25;
interest_rate = 4.0F;
name = "Java";
car = new Car();
text = { 'J', 'a', 'v', 'a' };
temps = { { 25.0, 96.2, -32.5 }, { 0.0, 212.0, -41.0 }};访问变量的值
要访问变量的值,请指定变量的名称(对于基本类型和String),取消引用对象并访问成员,或使用array-index表示法来标识要访问其值的元素:
System.out.println(age); // Output: 25
System.out.println(interest_rate); // Output: 4.0
System.out.println(name); // Output: Java
System.out.println(cat.name()); // Output: Garfield
System.out.println(text[0]); // Output: J
System.out.println(temps[0][1]); // Output: 96.2 为了取消引用一个对象,你必须在引用变量(cat)和member(name())之间放置一个句点字符。在这种情况下,将name()调用该方法并输出其返回值。
数组访问需要为每个维指定基于零的整数索引。对于text,只需要一个索引:0标识此一维数组中的第一个元素。对于temps,需要两个索引:0标识第一行,1标识此二维数组中第一行中的第二列。
您可以在一个声明中声明多个变量,通过用逗号分隔每个变量与其前缀,如以下示例所示:
int a, b[], c; 这个例子声明了一个名为三个变量a,b和c。每个变量共享相同的类型,这恰好是整数。不同于a和c,每个存储一个整数值,b[]表示一维数组,其中每个元素存储整数。尚未关联任何数组b。
注意,当数组在与其他变量相同的声明中声明时,方括号必须出现在变量名之后。如果将方括号放在变量名称之前int a, []b, c;,编译器将报告错误。如果将方括号放在类型名称后面,如int[] a, b, c;,所有三个变量表示整数的一维数组。
方括号在哪里?
方括号可以出现在类型名称后面或变量名称后面,但通常不会出现在这两个位置。例如,您可以指定int[] x;或int x[];。但是,通常的做法是将方括号放在元素类型名称后面(例如,int)。如果你要指定int[] x[];,你必须声明一个二维数组变量,就像你指定的一样int[][] x;。
早些时候,我提到Java支持Unicode。在下一节中,我们将了解这种支持如何影响源代码和编译。
实验Java的Unicode支持
Java程序列表通常存储在根据本地平台的字符编码对其进行编码的文件中。例如,我的Windows 7平台使用Cp1252作为其字符编码。当JVM开始运行时,例如当您通过该javac工具启动基于Java的Java编译器时,它尝试获取此编码。如果JVM无法获取它,JVM将选择UTF-8作为默认字符编码。
Cp1252不支持超出传统ASCII字符集的许多字符,这可能会导致问题。例如,如果您尝试使用Windows notepad编辑器保存清单1,编辑器将抱怨Unicode格式的字符将丢失。你能找出为什么吗?
清单1.以符号名称标识符(版本1)
class PrintPi
{
public static void main(String[] args)
{
double π = 3.14159;
System.out.println(π);
}
} 问题是,上面的源包括希腊字母Pi(π)作为变量的名称,这导致编辑器balk。幸运的是,我们可以解决这个问题。
首先,尝试将清单1保存到名为的文件PrintPi.java:从notepad“ 另存为 ”对话框中,输入PrintPi.java作为文件名称,并从“ 编码”编码下拉列表中选择与UTF-16(小端顺序)对应的Unicode 选项。然后按保存按钮。
接下来,尝试编译PrintPi.java,如下:
javac PrintPi.java 作为响应,您会收到许多错误消息,因为文本文件的内容编码为UTF-16,但javac假设(在我的平台上)内容编码为Cp1252。要解决这个问题,我们必须告诉javac内容编码为UTF-16。我们通过将-encoding Unicode选项传递给此程序,如下所示:
javac -encoding Unicode PrintPi.java 这一次,代码编译没有错误。当您执行PrintPi.classvia java PrintPi时,您将观察到以下输出:
3.14159 您还可以通过指定其Unicode转义序列而不使用周围的引号来嵌入其他字母表中的符号。这样,您不必在保存列表或编译保存的文本时指定编码,因为文本是根据本机平台的编码(例如,Cp1252)进行编码的。例如,清单2用此符号π的\u03c0Unicode转义序列替换。
清单2.以符号名称标识符(版本2)
class PrintPi
{
public static void main(String[] args)
{
double \u03c0 = 3.14159;
System.out.println(\u03c0);
}
} 编译没有-encoding unicodeoption(javac PrintPi.java)的源代码- 生成相同的类文件 - 并像before(java PrintPi)一样运行应用程序。您将观察到相同的输出。
结论是
Java有许多基本的语言特性,你应该在掌握语言的真正有趣的部分之前掌握。在本文中,您了解了Unicode,注释,标识符,类型,文字和变量在Java程序中的工作方式。下一次我们将处理Java表达式及其运算符。