Kafka技术知识总结之二——Kafka事务
接上篇《Kafka技术知识总结之一——Kafka 的元素,组成,架构》
二. Kafka 事务
参考地址:
《【干货】Kafka 事务特性分析》
2.1 Kafka 事务简述
Kafka 事务与数据库的事务定义基本类似,主要是一个原子性:多个操作要么全部成功,要么全部失败。Kafka 中的事务可以使应用程序将消费消息、生产消息、提交消费位移当作原子操作来处理。
为了实现事务,Producer 应用程序必须做到:
- 提供唯一的 transactionalId
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, “transacetionId”);- Kafka 可以通过相同的 transactionalId 确定唯一的生产者。对于相同 transactionalId 的新生 Producer 实例被创建且工作时,旧的 Producer 实例将不再工作。即消息跨生产者的的幂等性。
- 要求 Producer 开启幂等特性
- 将 enable.idempotence 设置为 true;
注:
- transactionalId 与 PID 一一对应,为了保证新的 Producer 启动之后,具有相同的 transactionalId 的旧生产者立即失效,每个 Producer 通过 transactionalId 获取 PID 的时候,还会获取一个单调递增的 producer epoch。
- Kafka 的事务主要是针对 Producer 而言的。对于 Consumer,考虑到日志压缩(相同 Key 的日志被新消息覆盖)、可追溯的 seek() 等原因,Consumer 关于事务语义较弱。
- 对于 Kafka Consumer,在实现事务配置时,一定要关闭自动提交的选项,即 props.put(“ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false”);
2.2 消费-转换-生产模式
消费-转换-生产模式是一种常见的,又比较复杂的情况,由于同时存在消费与生产,所以整个过程通常需要事务化。
通常在实现该模式时,需要同时构建一个用于拉取原消息的 Consumer,一个将原消息处理后,将处理后消息投递出去的 Producer。在代码上主要有五个步骤:
// 初始化事务
producer.initTransactions();
// 开启事务
producer.beginTransaction();
// 消费 - 生产模型
producer.send(producerRecord);
// 提交消费位移
producer.sendOffsetsToTransaction(offsets, "groupId");
// 提交事务
producer.commitTransaction();
上述过程全部被 try… catch…,如果中间出现错误,需要在 catch 块中执行:
// 中止事务
producer.abortTransaction();
2.3 Kafka 事务的实现
实现 Kafka 事务,主要使用到 Broker 端的事务协调器 (TransactionCoordinator)。每个 Producer 都会被指定一个特定的 TransactionalCoordinator,用来负责处理其事务,与消费者 Rebalance 时的 GroupCoordinator 作用类似。实现事务的流程如下图所示:
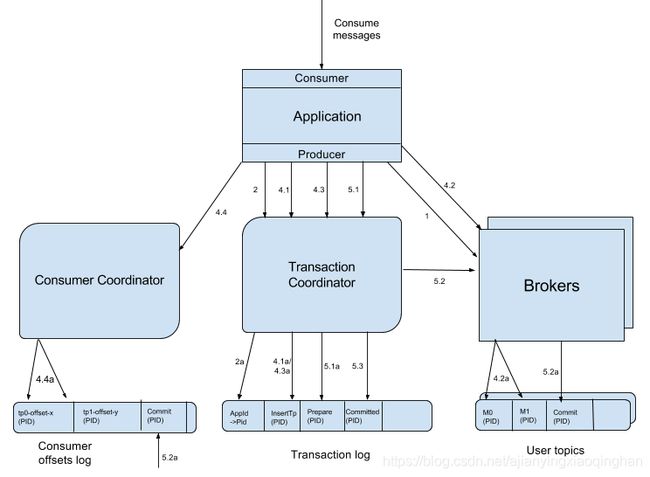
基本步骤如下:
2.3.1 查找事务协调者
生产者首先会发起一个查找事务协调者 (TransactionalCoordinator) 的请求 (FindCoordinatorRequest),Broker 集群根据 Request 中包含的 transactionalId 查找对应的 TransactionalCoordinator 节点并返回给 Producer。
2.3.2 获取 Producer ID
生产者获得协调者信息后,向刚刚找到的 TransactionalCoordinator 发送 InitProducerIdRequest 请求,为当前 Producer 分配一个 Producer ID。分两种情况:
- 不包含 transactionId:直接生成一个新的 Producer ID,返回给生产者客户端;
- 包含 transactionId:根据 transactionId 获取 PID,这个对应关系保存在事务日志中(上图中的 2a 步骤);
注:如果 TransactionalCoordinator 第一次收到包含该 transactionalId 的消息,则将相关消息存入主题 __transaction_state 中。
2.3.3 开启事务
生产者通过方法 producer.beginTransaction() 启动事务,此时只是生产者内部状态记录为事务开始。对于事务协调者,直到生产者发送第一条消息,才认为已经发起了事务。
2.3.4 消费-转换-生产
前面的阶段都是开始阶段,该阶段包含了整个事务的处理过程,消费者和生产者互相配合,共同完成事务。需要做如下工作:
- 存储对应关系,通过请求增加分区
- Producer 在向新分区发送数据之前,首先向 TransactionalCoordinator 发送请求,使 TransactionalCoordinator 存储对应关系 (transactionalId, TopicPartition) 到主题 __transaction_state 中。
- 生产者发送消息
- 基本与普通的发送消息相同,生产者调用
producer.send()方法,发送数据到分区; - 发送的请求中,包含 pid, epoch, sequence number 字段;
- 基本与普通的发送消息相同,生产者调用
- 增加消费 offset 到事务
- 生产者通过
producer.senOffsetsToTransaction()接口,发送分区的 Offset 信息到事务协调者,协调者将分区信息增加到事务中;
- 生产者通过
- 事务提交位移
- 在前面生产者调用事务提交 offset 接口后,会发送一个 TxnOffsetCommitRequest 请求到消费组协调者,消费组协调者会把 offset 存储到 Kafka 内部主题 __consumer_offsets 中。协调者会根据请求的 pid 与 epoch 验证生产者是否允许发起这个请求。
- epoch:生产者用于标识同一个事务 ID 在一次事务中的轮数,每次初始化事务的时候,都会递增,从而让服务端知道生产者请求是否为旧的请求。
- 只有当事务提交之后,offset 才会对外可见。
- 提交或回滚事务
- 用户调用
producer.commitTransaction()或abortTransaction()方法,提交或回滚事务; - EndTxnRequest:生产者完成事务之后,客户端需要显式调用结束事务,或者回滚事务。前者使消息对消费者可见,后者使消息标记为 abort 状态,对消费者不可见。无论提交或者回滚,都会发送一个 EndTxnRequest 请求到事务协调者,同时写入 PREPARE_COMMIT 或者 PREPARE_ABORT 信息到事务记录日志中。
- WriteTxnMarkerRequest:事务协调者收到 EndTxnRequest 之后,其中包含消息是否对消费者可见的信息,然后就需要向事务中各分区的 Leader 发送消息,告知消费者当前消息时哪个事务,该消息应该接受还是丢弃。每个 Broker 收到请求之后,会把该消息应该 commit 或 abort 的信息写到数据日志中。
- 用户调用
2.4 消息事务
参考地址:《利用事务消息实现分布式事务》
很多场景下,我们发消息的过程,目的往往是通知另外一个系统或者模块去更新数据。消息队列中的事务,主要**解决消息生产者和消息消费者的数据一致性问题**。
举一个例子:用户在电商 APP 上购物时,先把商品加到购物车里,然后几件商品一起下单,最后支付,完成购物流程。
这个过程中有一个需要用到消息队列的步骤:订单系统创建订单后,发消息给购物车系统,将已下单的商品从购物车中删除。因为从购物车删除已下单商品这个步骤,并不是用户下单支付这个主要流程中必要的步骤,使用消息队列来异步清理购物车是更加合理。
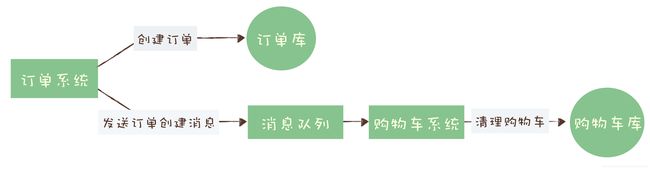
对于订单系统,它创建订单的过程实际执行了 2 个步骤的操作:
- 在订单库中插入一条订单数据,创建订单;
- 发消息给消息队列,消息的内容就是刚刚创建的订单;
对于购物车系统:订阅相应的主题,接收订单创建的消息,然后清理购物车,在购物车中删除订单的商品。
在分布式系统中,上面提到的步骤,任何一个都有可能失败,如果不做任何处理,那就有可能出现订单数据与购物车数据不一致的情况,比如:
- 创建了订单,没有清理购物车;
- 订单没创建成功,购物车里面的商品却被清掉了。
所以我们需要解决的问题为:在上述任意步骤都有可能失败的情况下,还要保证订单库和购物车库这两个库的数据一致性。所以在这种跨库的事务操作中,需要使用到分布式事务。分布式事务见数据库篇,在多种适用于不同场景下的分布式事务方法中,其中一种方式是消息事务。
事务消息需要消息队列提供相应的功能才能实现,kafka 和 RocketMQ 都提供了事务相关功能。依旧以上面的订单系统为例,有两个操作:在本地数据库中插入订单数据,以及向消息队列中发送订单信息,订单系统如何才能保证这两个操作同时成功,同时失败呢?
- 开启消息队列的生产者事务;
- Kafka 的
producer.beginTransaction();
- Kafka 的
- 向消息队列发送半消息;
- 半消息,即向发送一个完整的消息给消息队列,但消费者不可见;也就是说,生产者不将消息提交出去,而是等待某些状态确认后才执行提交 commit 操作;
- Kafka 的
producer.send();方法;
- 开启本地数据库事务,执行插入操作;
- 插入操作的结果,决定是否把消息提交;
- 如果本地数据库事务执行成功,则提交 (commit) 事务;
- 如果事务执行失败,则回滚 (abort) 事务;
- 如果发送提交 / 回滚消息事务的请求出现异常(如超时等),不同的消息队列有不同的解决方式;
- Kafka:提交时错误会抛出异常,此时由业务自行决定如何处理。可以尝试重复执行提交,直到重试成功;或者也可以进行一个补偿操作,将已经存入数据库中的订单删除;
- RocketMQ:提供事务反查机制;RocketMQ 的 Broker 没有收到提交或回滚请求,Broker 会定期去 Producer 上反查该事务的本地数据库事务状态,根据反查结果决定提交/回滚该事务。同时也需要业务代码自行实现本地事务状态的反查接口。
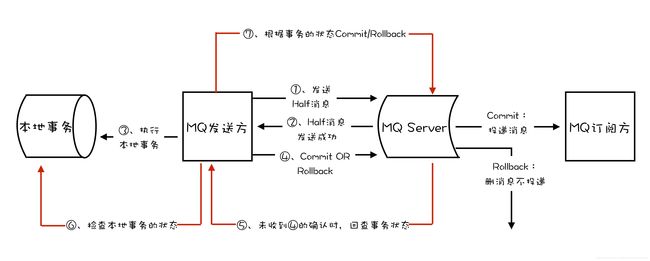
注:此外,该流程也可以用于支付流水的业务场景:保证存入一条支付流水,以及发送支付流水消息,两者之间的原子性。(来自于笔者阿里二面面试题)