python数据分析案例2:Python爬虫框架Scrapy入门与实践:
转载自:https://www.jianshu.com/p/169b62a8a269
本文建立在学习完大壮老师视频Python最火爬虫框架Scrapy入门与实践,自己一步一步操作后做一个记录(建议跟我一样的新手都一步一步进行操作).
主要介绍:
1、scrapy框架简介、数据在框架内如何进行流动
2、scrapy框架安装、mongodb数据库安装
3、scrapy抓取项目如何创建
4、scrapy抓取项目如何进行数据解析
5、scrapy抓取项目如何绕过反爬机制抓取数据
6、scrapy抓取项目如何存储数据到不同的格式
=
抓取目标:
本文通过网页豆瓣电影排行数据的抓取和清洗,介绍Python使用

豆瓣电影排行
大壮老师介绍:
目前任职于某大型互联网公司人工智能中心。Python开发工程师,主要负责汽车简历数据抓取、商业推广平台数据抓取及接口开发、竞品信息数据抓取等工作。 开发语言:python、autoit。项目中主要使用工具requests 多线程抓取网页系统数据,使用autoit抓取软件系统数据,使用appium抓取app系统数据等。使用scrapy进行大数据量信息抓取。
准备工作:
1、具有一定的Python基础
2、具有一定的linux系统管理基础,编译安装软件,yum包管理工具等
3、具有一定数据库管理基础,增删改查
4、了解xpath语法和插件的使用方法
代码下载地址:Python爬虫框架Scrapy入门与实践
注意:
文件middlewares.py 中下面信息需要改为有效信息:
request.meta['proxy'] = 'http-cla.abuyun.com:9030'
proxy_name_pass = b'H622272STYB666BW:F78990HJSS7'
如果么有购买,测试功能需要取消该方法:
修改settings.py文件:注释douban.middlewares.my_proxy:
DOWNLOADER_MIDDLEWARES = { #'douban.middlewares.my_proxy': 543,}
操作 1 : 通过Pycharm CE 创建一个项目scrapy_douban
创建前需要安装好相应的环境和软件:
环境配置,安装
A : 安装Anaconda (包含Python环境,Conda,numpy,pandas 等大量依赖包) :
下载地址1:Anaconda 下载1
下载地址2(国内推荐): 清华大学开源镜像 Anaconda 下载
选择包 : 分别对应有Mac , windows, linux 包, 根据设备选择,
比如我的是Mac : Anaconda3-5.2.0-MacOSX-x86_64-1.pkg

Anaconda5.2
下载开发工具->PyCharm
logo如下:

PyCharm
创建项目: 下面选择Python方式是创建一个新的目录管理第三方源, 后面可能需要手动导入需要的包
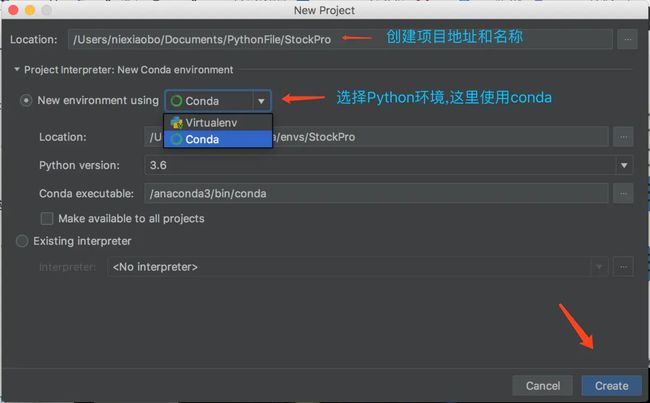
图片.png
创建后就会自动生成项目,并导入初始化环境, 然后就可以创建代码了:
图片.png
操作 2 : 进入你的项目路径, 并初始化
(下面调试是在Mac OS 系统进行,其他系统可能有点小区别)
进入你的项目路径:
cd /Users/niexiaobo/Documents/PythonFile/scrapy_douban
并初始化一个项目douban:
scrapy startproject douban
终端效果如下:
niexiaobodeMacBook-Pro:~ niexiaobo$ cd /Users/niexiaobo/Documents/PythonFile/scrapy_douban
niexiaobodeMacBook-Pro:scrapy_douban niexiaobo$ scrapy startproject douban
New Scrapy project 'douban', using template directory '/anaconda3/lib/python3.6/site-packages/scrapy/templates/project', created in:
/Users/niexiaobo/Documents/PythonFile/scrapy_douban/douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
niexiaobodeMacBook-Pro:scrapy_douban niexiaobo$
图片.png
操作 3 : 修改settings.py设置文件:
ROBOTSTXT_OBEY = False
# 下载延时
DOWNLOAD_DELAY = 0.5
操作 4 : 生成初始化文件:
niexiaobodeMacBook-Pro:scrapy_douban niexiaobo$ cd douban/
niexiaobodeMacBook-Pro:douban niexiaobo$ ls
douban scrapy.cfg
niexiaobodeMacBook-Pro:douban niexiaobo$ cd douban/
niexiaobodeMacBook-Pro:douban niexiaobo$ cd spiders/
niexiaobodeMacBook-Pro:spiders niexiaobo$ scrapy genspider douban_spider movie.douban.com
Created spider 'douban_spider' using template 'basic' in module:
douban.spiders.douban_spider
niexiaobodeMacBook-Pro:spiders niexiaobo$ ls
__init__.py __pycache__ douban_spider.py
niexiaobodeMacBook-Pro:spiders niexiaobo$
图片.png
抓取目标链接:https://movie.douban.com/top250

图片.png
操作 5 : 根据需要抓取的对象编辑数据模型文件 items.py ,创建对象(序号,名称,描述,评价等等).
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#序号
serial_number = scrapy.Field()
#电影名称
movie_name = scrapy.Field()
# 介绍
introduce = scrapy.Field()
# 星级
star = scrapy.Field()
# 评价
evaluate = scrapy.Field()
# 描述
describle = scrapy.Field()
操作 6 : 编辑爬虫文件douban_spider.py :
修改前:
# -*- coding: utf-8 -*-
import scrapy
class DoubanSpiderSpider(scrapy.Spider):
name = 'douban_spider'
allowed_domains = ['movie.douban.com']
start_urls = ['http://movie.douban.com/']
def parse(self, response):
pass
修改后:
# -*- coding: utf-8 -*-
import scrapy
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫的名称
name = 'douban_spider'
# 爬虫允许抓取的域名
allowed_domains = ['movie.douban.com']
# 爬虫抓取数据地址,给调度器
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
# 打印返回结果
print(response.text)
操作 7 : 开启scrapy项目:
打开终端, 在spiders文件路径下执行命令:scrapy crawl douban_spider
niexiaobodeMacBook-Pro:spiders niexiaobo$ scrapy crawl douban_spider
执行返回:
2018-07-10 10:36:18 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: douban)
2018-07-10 10:36:18 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.5.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.6.5 |Anaconda, Inc.| (default, Apr 26 2018, 08:42:37) - [GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)], pyOpenSSL 18.0.0 (OpenSSL 1.0.2o 27 Mar 2018), cryptography 2.2.2, Platform Darwin-16.7.0-x86_64-i386-64bit
2018-07-10 10:36:18 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'douban', 'DOWNLOAD_DELAY': 0.5, 'NEWSPIDER_MODULE': 'douban.spiders', 'SPIDER_MODULES': ['douban.spiders']}
2018-07-10 10:36:18 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.logstats.LogStats']
2018-07-10 10:36:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.Do
.
.
2018-07-10 10:36:18 [scrapy.core.engine] DEBUG: Crawled (403) (referer: None)
2018-07-10 10:36:18 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://movie.douban.com/top250>: HTTP status code is not handled or not allowed
.
.
'log_count/DEBUG': 2,
'log_count/INFO': 8,
'memusage/max': 51515392,
'memusage/startup': 51515392,
'response_received_count': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2018, 7, 10, 2, 36, 18, 577140)}
2018-07-10 10:36:18 [scrapy.core.engine] INFO: Spider closed (finished)
上面返回发现有报错:
2018-07-10 10:36:18 [scrapy.core.engine] DEBUG: Crawled (403) (referer: None)
2018-07-10 10:36:18 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://movie.douban.com/top250>: HTTP status code is not handled or not allowed
我们还需要回到项目settings.py 里 设置USER_AGENT,不然请求无法通过
设置什么内容?
操作 8 : 设置请求头信息 USER_AGENT
我们需要打开网页,F12打开页面调试窗口,在网络(network)下,刷新页面,找到"top250",并点击它:
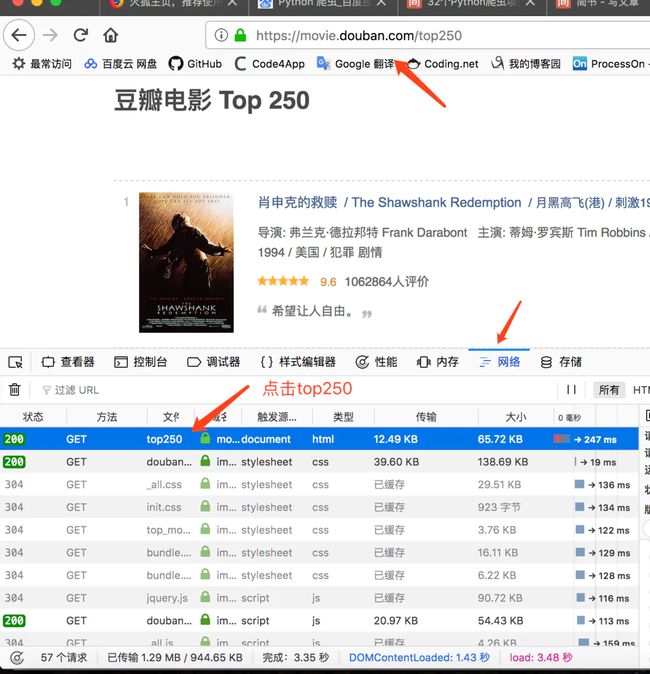
图片.png
找到请求信息的消息头,里面有User-Agent信息: (复制它)
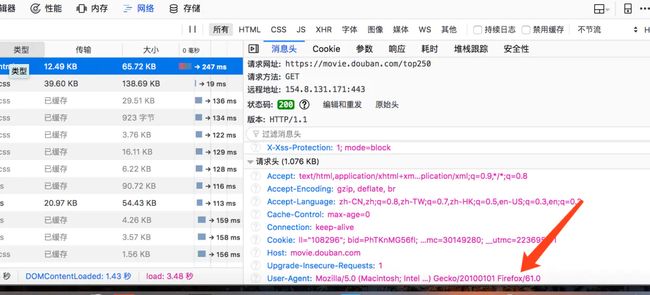
图片.png
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:61.0) Gecko/20100101 Firefox/61.0
打开Pycharm CE的 settings.py 里 设置USER_AGENT:
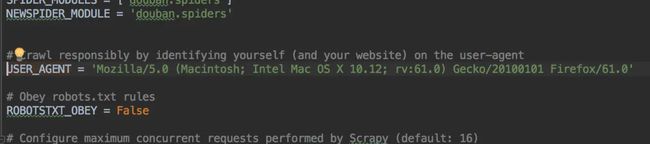
图片.png
打开终端, 在spiders文件路径下重新执行命令:scrapy crawl douban_spider
niexiaobodeMacBook-Pro:spiders niexiaobo$ scrapy crawl douban_spider
如果返回日志里有一堆html信息,说明执行成功:
...
1

导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
1994 / 美国 / 犯罪 剧情
1062864人评价
希望让人自由。
...
另外,本人安装Python是通过Anaconda管理,会安装大部分常用的模块,如果编译安装Python缺少模块,就可能执行失败

图片.png
如果执行失败,比如下面情况,像教程里老师缺少sqlite3:

图片.png
那么需要安装sqlite:
管理员执行命令: sudo yum -y install sqlite*
再输入电脑密码回车

图片.png
安装成功后,需要重新编译一下Python,并开启sqlite
进入你的Python安装目录编译:
./configure --prefix='你的安装路径' --with-ssl

图片.png
操作 9 : 上面我们是在终端执行的,为了方便,现在设置在Pycharm CE开发工具中执行.
首先我们需要创建一个启动文件,比如main.py:
创建完成后编写如下main.py:
from scrapy import cmdline
# 输出未过滤的页面信息
cmdline.execute('scrapy crawl douban_spider'.split())
右键运行,返回信息和终端一样.
操作 10 : 下面进入爬虫文件douban_spider.py 进行进一步设置:
# -*- coding: utf-8 -*-
import scrapy
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫的名称
name = 'douban_spider'
# 爬虫允许抓取的域名
allowed_domains = ['movie.douban.com']
# 爬虫抓取数据地址,给调度器
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
print(i_item)
其中:response.xpath("//div[@class='article']//ol[@class='grid_view']/li")是xml的解析方法xpath, 括号内是xpath语法:
(根据抓取网页的目录结构,等到上面结果, 意思是选取class为article的div下,class为grid_view的ol下的所有li标签)

图片.png
示例:

图片.png
回到上面,在douban_spider.py 编辑完成后,进入main.py运行:
2018-07-10 14:31:51 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to from
2018-07-10 14:31:52 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
<200 https://movie.douban.com/top250>
...
操作 11 : 返回我们选择的Selector对象
接下来进一步细分,获取详细的信息:
继续修改 信息:
1: 导入模型文件from douban.items import DoubanItem
意思是从目录文件douban下的items.py里,导入DoubanItem模型
2: 修改遍历:
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
print(douban_item)
解释:
1 DoubanItem() 模型初始化
2 douban_item['serial_number'] 设置模型变量serial_number值,
3 i_item.xpath(".//div[@class='item']//em/text()")对返回结果进一步筛选,并且以"."开头表示拼接,以text()结束表示获取其信息
4 extract_first() 筛选结果的第一个值
修改后的douban_spider.py文件:
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫的名称
name = 'douban_spider'
# 爬虫允许抓取的域名
allowed_domains = ['movie.douban.com']
# 爬虫抓取数据地址,给调度器
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
print(douban_item)
运行main.py:( 如下,序号获取成功)
2018-07-10 15:06:13 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to from
2018-07-10 15:06:14 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
{'serial_number': '1'}
{'serial_number': '2'}
{'serial_number': '3'}
{'serial_number': '4'}
{'serial_number': '5'}
{'serial_number': '6'}
{'serial_number': '7'}
...
操作 12 : 完善douban_spider.py文件(解析详细属性):
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫的名称
name = 'douban_spider'
# 爬虫允许抓取的域名
allowed_domains = ['movie.douban.com']
# 爬虫抓取数据地址,给调度器
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first()
descs = i_item.xpath(".//div[@class='info']//div[@class='hd']/p[1]/text()").extract()
for i_desc in descs:
i_desc_str = "".join(i_desc.split())
douban_item['introduce'] = i_desc_str
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describle'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
print(douban_item)
再次运行main.py,返回信息:
2018-07-10 15:29:21 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
{'describle': '希望让人自由。',
'evaluate': '1062864人评价',
'movie_name': '肖申克的救赎',
'serial_number': '1',
'star': '9.6'}
{'describle': '风华绝代。',
'evaluate': '774612人评价',
'movie_name': '霸王别姬',
'serial_number': '2',
'star': '9.5'}
{'describle': '怪蜀黍和小萝莉不得不说的故事。',
'evaluate': '991246人评价',
'movie_name': '这个杀手不太冷',
'serial_number': '3',
'star': '9.4'}
...
操作 13 : yield命令和Scrapy框架
接着把刚才最后一行代码
print(douban_item)
替换成
yield douban_item
意思是将返回结果压入 item Pipline进行处理:(如下图介绍scrapy原理)

图片.png
操作 14 : 继续编辑我们的爬虫douban_spider.py文件

图片.png
操作 15 : 遍历 "下一页" , 获取所有数据
再次编辑douban_spider.py文件:
# -*- coding: utf-8 -*-
import scrapy
from douban.items import DoubanItem
class DoubanSpiderSpider(scrapy.Spider):
# 爬虫的名称
name = 'douban_spider'
# 爬虫允许抓取的域名
allowed_domains = ['movie.douban.com']
# 爬虫抓取数据地址,给调度器
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath("//div[@class='article']//ol[@class='grid_view']/li")
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']/div[@class='hd']/a/span[1]/text()").extract_first()
descs = i_item.xpath(".//div[@class='info']//div[@class='hd']/p[1]/text()").extract()
for i_desc in descs:
i_desc_str = "".join(i_desc.split())
douban_item['introduce'] = i_desc_str
douban_item['star'] = i_item.xpath(".//span[@class='rating_num']/text()").extract_first()
douban_item['evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
douban_item['describle'] = i_item.xpath(".//p[@class='quote']/span/text()").extract_first()
yield douban_item
# 解析下一页
next_link = response.xpath("//span[@class='next']/link/@href").extract()
if next_link:
next_link = next_link[0]
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
解释:
1 每次for循环结束后,需要获取next页面链接:next_link
2 如果到最后一页时没有下一页,需要判断一下
3 下一页地址拼接: 点击第二页时页面地址是https://movie.douban.com/top250?start=25&filter= 恰好就是https://movie.douban.com/top250 和 中href的拼接
4 callback=self.parse : 请求回调
运行main.py结果:(可以看到我们把最后一个序号250的数据加载到)

图片.png
操作 16 : 保存数据到json文件 或者 csv文件
在douban路径执行:scrapy crawl douban_spider -o movielist.json
或者
在douban路径执行:scrapy crawl douban_spider -o movielist.csv
niexiaobodeMacBook-Pro:douban niexiaobo$ scrapy crawl douban_spider -o movielist.json
niexiaobodeMacBook-Pro:douban niexiaobo$ scrapy crawl douban_spider -o movielist.csv
保存成功:
...
{'describle': '一部能引人思考的科幻励志片。',
'evaluate': '92482人评价',
'movie_name': '千钧一发',
'serial_number': '249',
'star': '8.7'}
2018-07-10 17:29:47 [scrapy.core.scraper] DEBUG: Scraped from <200 https://movie.douban.com/top250?start=225&filter=>
{'describle': '献给所有外婆的电影。',
'evaluate': '50187人评价',
'movie_name': '爱·回家',
'serial_number': '250',
'star': '9.0'}
2018-07-10 17:29:47 [scrapy.core.engine] INFO: Closing spider (finished)
2018-07-10 17:29:47 [scrapy.extensions.feedexport] INFO: Stored json feed (250 items) in: movielist.json
2018-07-10 17:29:47 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 3862,
'downloader/request_count': 11,
'downloader/request_method_count/GET': 11,
'downloader/response_bytes': 128522,
'downloader/response_count': 11,
'downloader/response_status_count/200': 10,
'downloader/response_status_count/301': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2018, 7, 10, 9, 29, 47, 88010),
'item_scraped_count': 250,
'log_count/DEBUG': 262,
'log_count/INFO': 8,
'memusage/max': 51916800,
'memusage/startup': 51916800,
'request_depth_max': 9,
'response_received_count': 10,
'scheduler/dequeued': 11,
'scheduler/dequeued/memory': 11,
'scheduler/enqueued': 11,
'scheduler/enqueued/memory': 11,
'start_time': datetime.datetime(2018, 7, 10, 9, 29, 40, 675082)}
2018-07-10 17:29:47 [scrapy.core.engine] INFO: Spider closed (finished)
ls查看:里面有movielist.json 和 movielist.csv
niexiaobodeMacBook-Pro:douban niexiaobo$ ls
__init__.py items.py middlewares.py movielist.json settings.py
__pycache__ main.py movielist.csv pipelines.py spiders
查看保存结果:
Mac可以使用Numbers正常打开(如果使用Excel打开显示乱码,需要先设置编码格式Utf8-bom后打开)

图片.png
操作 17 : 存储到数据库MongoDB(pymongo)
首先检查是否安装pymongo:
打开终端
输入
python
回车
输入:
import pymongo
回车
如果没有安装就会报错:
...
No module named 'pymongo'
安装pymongo:
输入命令:
pip install pymongo
回车安装.
安装成功以后,接下来需要编写存储代码.
进入项目
设置settings.py文件
(1)将settings.py被注释的下面代码开启:
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
(2)settings.py文件最后添加数据库信息:
启动数据库服务
host:你的ip地址;
port : pymongo默认端口
db_name: 数据库名
db_collection: 表名
# 定义MongoDB信息
mongo_host = '172.16.0.0'
mongo_port = 27017
mongo_db_name = 'douban'
mongo_db_collection = 'douban_movie'
修改你的pipelines.py文件如下:
# -*- coding: utf-8 -*-
import pymongo
from douban.settings import mongo_host ,mongo_port,mongo_db_name,mongo_db_collection
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class DoubanPipeline(object):
def __init__(self):
host = mongo_host
port = mongo_port
dbname = mongo_db_name
sheetname = mongo_db_collection
client = pymongo.MongoClient(host=host,port=port)
mydb = client[dbname]
self.post = mydb[sheetname]
def process_item(self, item, spider):
data = dict(item)
self.post.insert(data)
return item
进入main.py运行.即可存储数据到数据库.
操作 17 : ip代理中间价编写(爬虫ip地址伪装)
修改中间价文件:middlewares.py文件:
(1)文件开头导入base64文件:
import base64
(2)文件结尾添加方法:
class my_proxy(object):
def process_request(self,request,spider):
request.meta['proxy'] = 'http-cla.abuyun.com:9030'
proxy_name_pass = b'H622272STYB666BW:F78990HJSS7'
enconde_pass_name = base64.b64encode(proxy_name_pass)
request.headers['Proxy-Authorization'] = 'Basic ' + enconde_pass_name.decode()
解释:根据阿布云注册购买http隧道列表信息
request.meta['proxy'] : '服务器地址:端口号'
proxy_name_pass: b'证书号:密钥' ,b开头是字符串base64处理
base64.b64encode() : 变量做base64处理
'Basic ' : basic后一定要有空格
大壮老师购买阿布云http隧道页:

图片.png
修改settings.py文件:
(3)取消注释,并修改如下:
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.my_proxy': 543,
}
(4)进入main.py运行:
下面截图表示成功隐藏ip地址

图片.png
操作 18 : 头信息User-Agent伪装
其实在上面'操作 8' 步骤里已经设置过一次User-Agent信息,不过信息是写死的,
接下里我们通过随机给出一个User-Agent信息的方式来实现简单伪装:
同样是修改中间价文件:middlewares.py文件:
(1)文件开头导入random文件(随机函数):
import random
(2)文件结尾添加方法:
添加新方法:
class my_useragent(object):
def process_request(self, request, spider):
UserAgentList = [
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)",
"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)",
"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5",
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
]
agent = random.choice(UserAgentList)
request.headers['User_Agent'] = agent
(3)修改settings.py文件:并修改如下:
增加一条设置: 'douban.middlewares.my_useragent': 544
DOWNLOADER_MIDDLEWARES = {
'douban.middlewares.my_proxy': 543,
'douban.middlewares.my_useragent': 544,
}
(4)进入main.py运行:
user agent设置成功

图片.png
操作 19 : 最后
学习爬虫可用于个人学习和研究数据,不可涉及违法使用.