初学ARM感觉写个裸板程序还真的不容易,可能是没有用到ADS,keil之类的开发平台的缘故吧。编译,链接过程在linux平台上完成,这样学起来更有实感,还能顺便熟悉linux环境,以及命令,何乐而不为呢?
为此得准备一些必要的基础知识,前几篇博客总结一些汇编的指令,以及makefile的总结。有兴趣的同学可以去看看。
汇编引导程序:
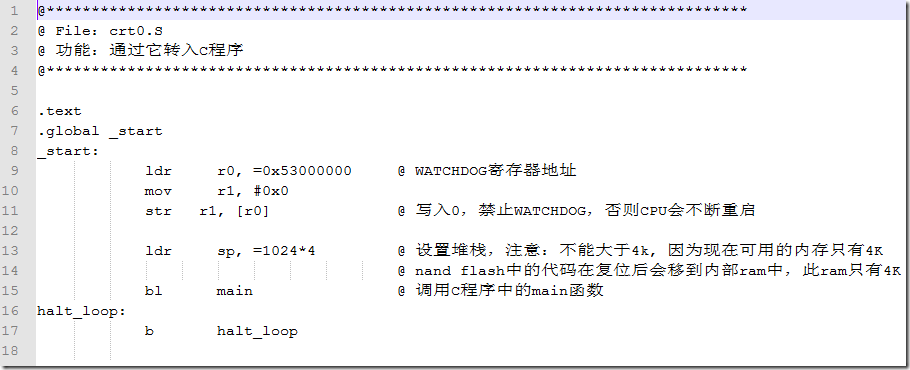
这段汇编代码做了3件事情:
1、关看门狗。
2、设置栈。
3、调用main函数。
这里想说明的就是,设置站。写C函数必须先设置栈,因为需要用栈来存放函数的参数值,局部变量的值等。
我用的2440的内部ram是4K,这里sp就指向了ram地址最大的地方,这是因为ARM-Thumb过程调用标准和ARM、Thumb C/C++ 编译器总是使用Full descending 类型堆栈。即栈首部是高地址,堆栈向低地址增长。
每次压栈(向栈里写数据),sp会先递减,再向地址中写数据,每次弹栈(把栈里数据读出),会先读出sp所指地址的数据,然后再将sp递增:用一张图来加强记忆:
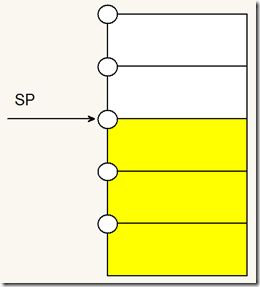
想象每个内存都是一个装水的鱼缸,鱼缸的左上方有一个注水口,SP就是一个可以注水,也可以抽水的的水管。那么注水就是压栈过程,抽水就是弹栈过程。每次想注水时,先将sp向上一格到注水口处,再注水。每次抽水时,将水抽空之后,sp就向下移动一格。
感觉这样对比之后,整个过程就很容易理解和记忆了。
//---------------------拓展阅读---------------------
栈的增长方式有两种:向上 和 向下
为什么栈会有两种增长方式?
一般程序的变量都是从RAM的低地址开始分配的,变量从低地址开始分配的原因是很明显的,它可以在RAM容量增大时不用从新编译程序。早期的计算机系统的内存容量有限,将堆栈设计成从高地址向低地址增长,可以有限地利用所有的内存容量;同时在变量数目改变的时候,可以保持堆栈的起始地址不变。
现今内存容量变得越来越大,上述的安排就变得逐渐失去了意义;今天即使可以使用从低地址向高地址增长的堆栈,但应该很少会有人用,人们已经习惯成自然了。
Makefile:
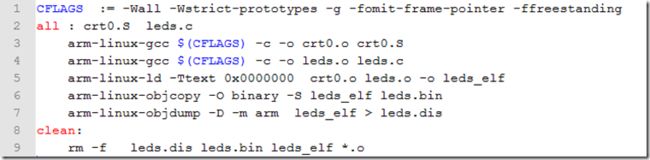
又见这段makefile了,之前再上一篇博客《makefile学习总结》已经见到过了。
今天从第5行开始分析:arm-linux-ld 中的-Ttest选项,用来指定代码段的起始地址,在汇编引导程序的第6行的”.text”就表示该处是代码段的其实位置。-Ttest 0x0000,就是把该位置地址设置为0x00000。并且将编译后的文件链接起来,输出led_elf文件。到此就完成了编译,和链接工作。
但是事情并没有结束。对于ARM芯片来说,它不认识led_elf文件因为格式不对,我们需要生成arm认识的bin文件。
于是就用到第六行这条命令arm-linux-objcopy (被用来复制一个目标文件的内容到另一个文件中,可用于不同源文件的之间的格式转换),选项-O(大写)表示指定某个格式输出,-O binary,就表示已二进制格式输出。-S表示: 不从源文件中复制重定位信息和符号信息到目标文件中。这条命令执行玩了之后,就生成了bin文件,可以下载到arm中执行了。
如果还想看看反汇编文件,就可以用接下来这个命令:arm-linux-objdump(常用来显示二进制文件信息,常用来查看反汇编代码)-D表示反汇编所有段(-d表示反汇编可执行段); -m arm表示指定目标文件使用arm架构进行反汇编。 ‘>’表示把命令结果输出到文本文件中去。
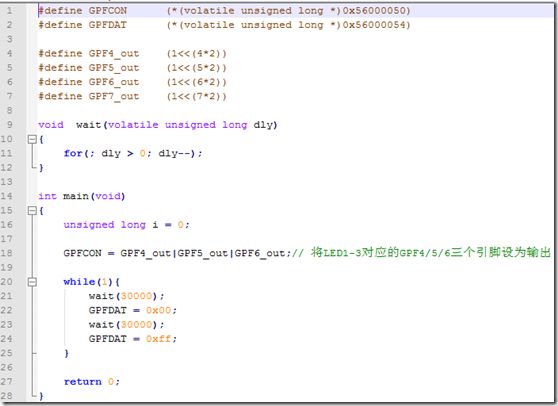
C程序,如下就没什么好说的了~~
总结:一个裸板程序,我们用到了3个文件。
汇编引导程序:主要作用是设置栈,以及调用main函数。
C源程序:实现具体功能。
makefile:编译,链接以上文件,生成arm可执行的bin文件。
以上程序是运行在2440的内部ram上的,下节同样是一个裸板程序,将讲到如何将程序运行在2440外接的SDRAM上。
2014-11-26
宋桓公