JAVA Apache POI解析docx格式的word文件并提取带样式文本
关于JAVA Apache POI读取word文档,网上资料很多,但是大多数还是仅仅提取文档中的纯文本,好一点的,也就提取所有图片,但是,word文档本身是具有样式的,这样简单粗暴的提取就会丢失字体、字号、颜色、粗体、斜体等一系列样式,也没有办法还原图片在文档流中的位置,没有办法提取出表格。
docx格式的word文件实际上是一个压缩包,通过修改后缀名为rar后可用winrar打开,里面实际上是xml文件
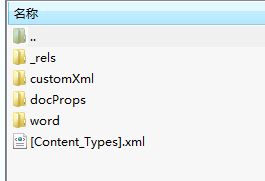
这是因为docx文件遵循了OfficeOpenXML规范,该规范内容很多,有兴趣的同学可以自行下载翻阅。打开上图的word文件夹

这里我们需要关注的是document.xml和numbering.xml
其中document.xml包含了文档的主要结构与主要文本内容,其形式有点像HTML语言

而numbering.xml与自动序号有关,由于非常复杂,文本暂不讨论,主要原因是自动序号实际上是在渲染时进行实时计算的,并且需要有不同的层次。
在开始使用Apache POI解析之前,我们需要了解一些关于docx文件结构的基本概念

整个文档是一个document,document的子元素为Paragraph(段落)和Table(表格)这和我们日常使用word的经验基本相符,Paragraph的子元素为Run,代表一段连续的相同样式的文本,一般来说,没有改过样式的一段纯中文或者纯英文就在一个Run内,而一旦对其中一个字改变了字号、颜色、粗细等样式,那么其本身及前后必然会被不同的Run分割。
在实际使用Apache POI中,又分为High Level和Low Level两种API,一般以XWPF作为前缀的是High Level API,以CT为前缀的是Low Level,High Level API使用更简单,比较容易理解,但是目前只有比较常见的元素有,例如XWPFParagraph、XWPFRun。Low Level API实际上是对xml文件中标签的简单封装,需要你对OfficeOpenXML规范有足够的了解,例如CTP(Paragraph)、CTR(Run)。当然,Low Level API也不一定能满足你的全部需求,这个时候你只能对着OfficeOpenXML文档自行解析XML了。High Level API可以获取到对应的Low Level API,例如,XWPFParagraph.getCTP()。
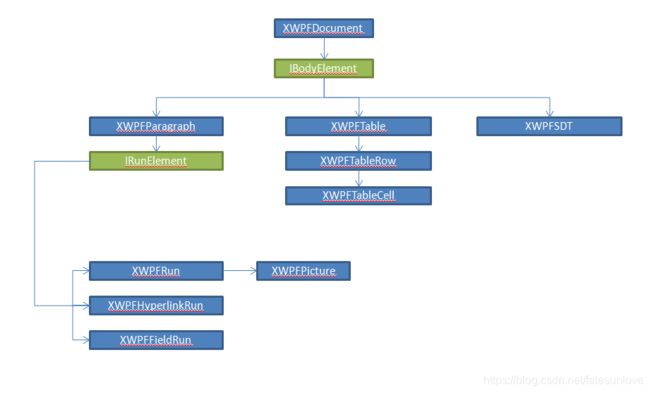
上图是High Level API的类的主要关系图,其中蓝色的是class,绿色的是interface
List paragraphs = document.getParagraphs();
for(XWPFParagraph paragraph:paragraphs){
List runs= paragraph.getRuns();
for(XWPFRun run:runs){
List pictures=run.getEmbeddedPictures();
String text=run.text();
}
} 一般来说,我们使用XWPFParagraph、XWPFRun、XWPFPicture就能满足绝大多数情况。由于图片的情况较为复杂,这里能抽取的图片是嵌入型的图片,而衬于文字上/下方的图片抽取较为复杂,本文暂不讨论。
下面就主要讲讲XWPFParagraph与XWPFRun的样式相关API
1.对齐方式
xwpfParagraph.getAlignment().getValue()下表仅列出常用对齐方式
| 返回值 | 含义 |
| 1 | 左对齐 |
| 2 | 居中 |
| 3 | 右对齐 |
2.字体
run.getFontFamily()3.字号
run.getFontSize()4.粗体
run.isBold()5.斜体
run.isItalic()6.下划线
run.getUnderline().getValue()下表仅列出常用下划线
| 返回值 | 含义 |
| 1 | 单下划线 |
| 3 | 双下划线 |
7.下标
run.getVerticalAlignment().equals(STVerticalAlignRun.Enum.forInt(3))8.上标
run.getVerticalAlignment().equals(STVerticalAlignRun.Enum.forInt(2))9.颜色
run.getColor()表格抽取相对较简单,最终又回到XWPFParagraph
List xwpfTableRows = xwpfTable.getRows();
for (XWPFTableRow xwpfTableRow : xwpfTableRows) {
List xwpfTableCells = xwpfTableRow.getTableCells();
for (XWPFTableCell xwpfTableCell : xwpfTableCells) {
List xwpfParagraphs = xwpfTableCell.getParagraphs();
}
} 最后补充一些特殊情况,这些情况需要用到Low level API
1.oMath公式
office中公式的版本很乱,因为涉及到历史兼容原因,老版本的公式只能抽取为图片,最新版本的公式可以抽取为xml
List ctoMaths = xwpfParagraph.getCTP().getOMathList(); 顺带说一句,oMath可以转换为mml再转换为Latex语言
2.特殊符号
有些特殊符号是用的某种字体中的某个字符,一般使用&#x unicode进行显示
List ctSyms = run.getCTR().getSymList();
if (ctSyms.size() > 0) {
String symHtml = "";
for (CTSym ctSym : ctSyms) {
String font = ctSym.getFont();
byte[] chars = ctSym.getChar();
String unicode = "";
for (byte aChar : chars) {
int realInt = aChar & 0xff;
String hex = Integer.toHexString(realInt);
if (hex.length() == 1) {
hex = "0" + hex;
}
}
unicode += hex;
}
} 3.着重号

run.getCTR().getRPr() != null && run.getCTR().getRPr().getEm() != null && run.getCTR().getRPr().getEm().getVal().toString().equals("dot")