【技术综述】如何Finetune一个小网络到移动端(时空性能分析篇)
本文首发于龙鹏的知乎专栏《有三AI学院》
https://zhuanlan.zhihu.com/p/34455109
00 引言
现在很多的图像算法都是离线计算的,而学术界刷榜单那些模型,什么vgg16,resnet152是不能直接拿来用的,所以,对于一个深度学习算法工程师来说,如果在这些模型的基础上,设计出一个又小又快的满足业务需求的模型,是必备技能,今天就来简单讨论一下这个问题。
首先,祭出一个baseline,来自Google的mobilenet,算是学术界祭出的真正有意义的移动端模型。
当然,这里我们要稍微修改一下,毕竟原始的mobilenet是分类模型过于简单无法展开更多,我们以更加复杂通用的一个任务开始,分割,同时修改一下初始输入尺度,毕竟224这个尺度在移动端不一定被采用,我们以更小的一个尺度开始,以MacBookPro为计算平台。
在原有mobilenet的基础上添加反卷积,输入网络尺度160*160,网络结构参考mobilenet,只是在最后加上反卷积如下
如果谁有可以可视化caffe网络结构图并保存成高清图片的方法,请告诉我一下,netscope不能保存图,graphviz的图又效果很差,所以这里没有放完整结构图。
不过,大家可以去参考mobilenet,然后我们在mac上跑一遍,看看时间代价如下:
其中黄色高亮是统计的每一个module的时间和。

准备工作完毕,接下来开始干活。
01 分析网络的性能瓶颈
1.1 运行时间和计算代价分析
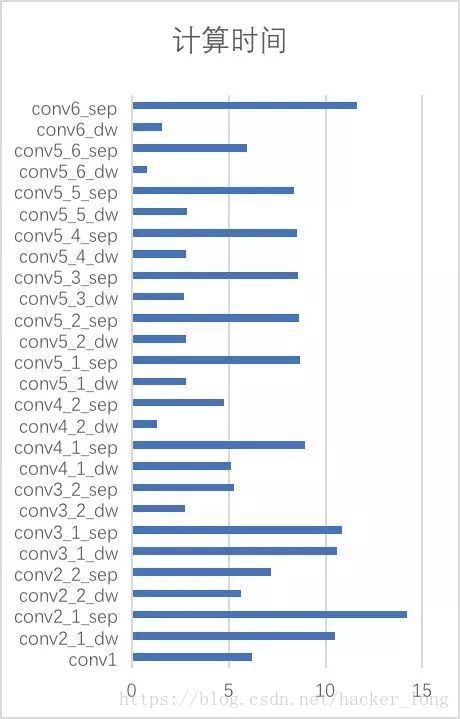

上面两图分别是网络的计算时间和计算量,从上面我们总结几条规律:
(1) 耗时前5,conv2_1_sep,conv6_sep,conv3_1_sep,conv3_1_dw,conv2_1_dw。
我们看看为什么,
conv2_1_dw计算量,32*80*80*3*3*1=1843200
conv2_1_sep计算量,32*80*80*1*1*64=13107200
conv3_1_dw计算量,128*40*40*3*3*1=1843200
conv3_1_sep计算量,128*40*40*1*1*128=26214400
conv6_sep计算量,1024*5*5*1*1*1024=26214400
上面可以看出,计算量最大的是conv6_sep,conv2_1_sep,理论上conv2_1_dw计算量与conv2_1_sep不在一个量级,但是实际上相当,这是库实现的问题。
(2) 从conv5_1到conv5_5,由于尺度不发生变化,通道数不发生变化,所以耗时都是接近的,且dw模块/sep模块耗时比例约为1:3。
前者计算量:512*10*10*3*3
后者计算量:512*10*10*1*1*512
这一段网络结构是利用网络深度增加了非线性,所以对于复杂程度不同的问题,我们可以缩减这一段的深度。
1.2 网络参数量分析
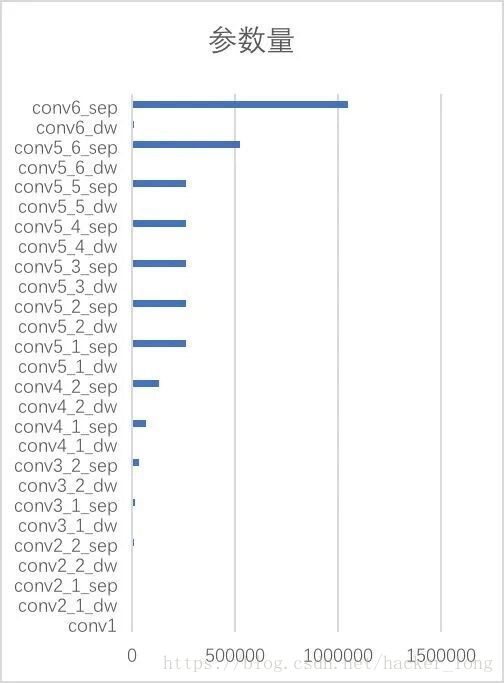
从上面我们可以看出,参数量集中在conv6_sep,conv5_6_sep,conv5_1~5_5,所以要压缩模型,应该从这里地方入手。
当我们想设计更小的mobilenet网络时,有3招是基本的,一定要用。
(1) 降低输入分辨率,根据实际问题来设定。
(2) 调整网络宽度,也就是channel数量。
(3) 调整网络深度,比如从conv4_2到conv5_6这一段,都可以先去试一试。
02开始调整网络
在做这件事之前,我们先看看经典网络结构的一些东西,更具体可以参考之前的文章。
https://zhuanlan.zhihu.com/p/25797790
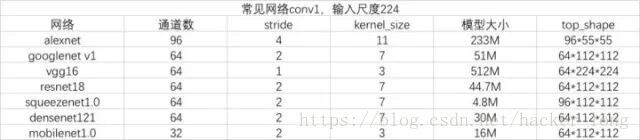
从上面的表看,主流网络第一个卷积,kernel=3,stride=2,featuremap=64,mobilenet系列已经降到了32。
第1层是提取边缘等信息的,当然是featuremap数量越大越好,但是其实边缘检测方向是有限的,很多信息是冗余的, 由于mobilenet优异的性能,事实证明,最底层的卷积featuremap channel=32已经够用。
实际的任务中,大家可以看conv1占据的时间来调整,不过大部分情况下只需要选择好输入尺度大小做训练,然后套用上面的参数即可,毕竟这一层占据的时间和参数,都不算多,32已经足够好足够优异,不太需要去调整的。
自从任意的卷积可以采用3*3替代且计算量更小后,网络结构中现在只剩下3*3和1*1的卷积,其他的尺寸可以先不考虑。
采用80*80输入,砍掉conv5_6和conv6,得到的模型各层花费时间如下
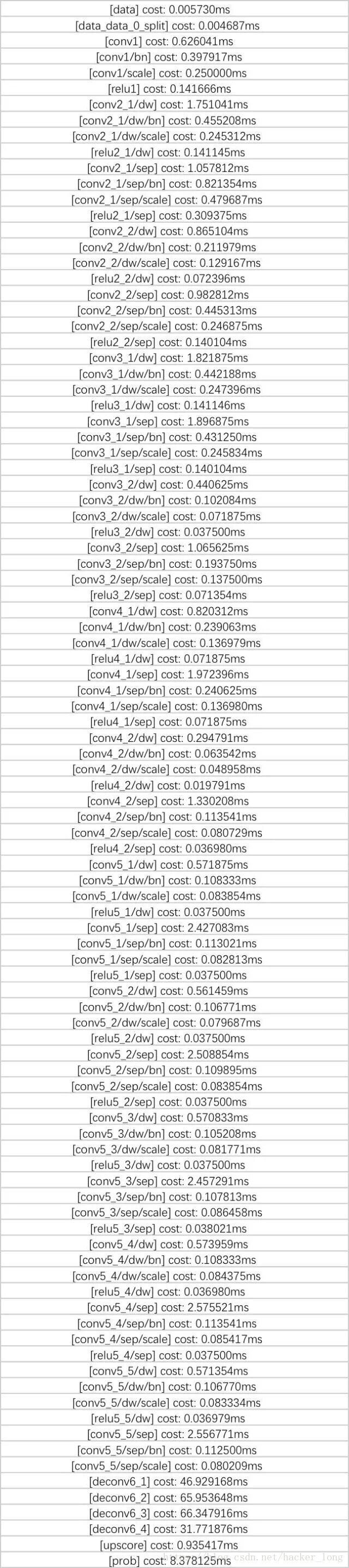
总共274ms,我们称这个模型为mobilenet_v0。
2.1 如何决定输入尺度
输入尺度绝对是任务驱动的,不同的任务需要不同的输入尺度,分割比分类需要尺度一般更大,检测又比分割所需要的尺度更大,在这里,我们限定一个比较简单的分割任务,然后将输入尺度定为80*80,就将该任务称为A吧。
2.2 如何调整网络宽度与深度
通道数决定网络的宽度,对时间和网络大小的贡献是一个乘因子,这是优化模型首先要做的,下面开始做。
2.2.1 反卷积
看上面的模型我们可以看出,反卷积所占用时间远远大于前面提取特征的卷积,这是因为我们没有去优化过这个参数。那么,到底选择多少才合适呢?
在这里经验就比较有用了。卷积提取特征的过程,是featuremap尺度变小,channel变大,反卷积正好相反,featuremap不断变大,通道数不断变小。这里有4次放大2倍的卷积,考虑到每次缩放一倍,所以第一次的channel数量不能小于2^4=16,一不做二不休,我们干脆就干为16。
我们称这个模型为mobilenet_v1
我们看下时间对比

再看下性能对比。

这样,一举将模型压缩5倍,时间压缩5倍,而且现在反卷积的时间代价几乎已经可以忽略。
2.2.2 粗暴地减少网络宽度
接下来我们再返回第1部分,conv5_1到conv5_5的计算量和时间代价都是不小的,且这一部分featuremap大小不再发生变化。这意味着什么?这意味着这一部分,纯粹是为了增加网络的非线性性。
下面我们直接将conv5_1到conv5_5的featuremap从512全部干到256,称其为mobilenet2.1.1,再看精度和时间代价。

时间代价和网络大小又有了明显下降,不过精度也有下降。
2.2.3 粗暴地减少网络深度
网络层数决定网络的深度,在一定的范围内,深度越深,网络的性能就越优异。但是从第一张图我们可看出来了,网络越深,featureamap越小,channel数越多,这个时候的计算量也是不小的。
所以,针对特定的任务去优化模型的时候,我们有必要去优化网络的深度,当然是在满足精度的前提下,越小越好。
我们从一个比较好的起点开始,从mobilenet_v1开始吧,直接砍掉conv5_5这个block,将其称为mobilenet_v2.1.2。
下面来看看比较。

从结果来看,精度下降尚且不算很明显,不过时间的优化很有限,模型大小压缩也有限。
下面在集中看一下同时粗暴地减少网络深度和宽度的结果,称其为mobilenet_v2.1.3

以损失将近1%的代价,将模型压缩到2.7m,40ms以内,这样的结果,得看实际应用能不能满足要求了。
总之,粗暴地直接减小深度和宽度,都会造成性能的下降。
2.2.4 怎么弥补通道的损失
从上面我们可以看出,减少深度和宽度,虽然减小了模型,但是都带来了精度的损失,很多时候这种精度损失导致模型无法上线。所以,我们需要一些其他方法来解决这个问题。
2.2.4.1 crelu通道补偿
从上面可以看出,网络宽度对结果的影响非常严重,如果我们可以想办法维持原来的网络宽度,且不显著增加计算量,那就完美了。正好有这样的方法,来源于这篇文章《Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units》,它指出网络的参数有互补的现象,如果将减半后的通道补上它的反,会基本上相当于原有的模型,虽然原文针对的是网络浅层有这样的现象,不过深层我们不妨一试,将其用于参数量和计算代价都比较大的conv5_1到conv5_4,我们直接从mobilenet_v2.1.3开始,增加conv5_1到conv5_4的网络宽度,称之为mobilenet_v2.1.4。

2.2.4.2 skip connect,融合不同层的信息
这是说的不能再多,用的不能再多了的技术。从FCN开始,为了恢复分割细节,从底层添加branch到高层几乎就是必用的技巧了,它不一定能在精度指标上有多少提升,但是对于分割的细节一般是正向的。
我们直接从mobilenet_v2.1.3开始,添加3个尺度的skip connection。由于底层的channel数量较大,deconv后的channel数量较小,因此我们添加1*1卷积改变通道,剩下来就有了两种方案,1,concat。2,eltwise。
针对这两种方案,我们分别进行试验。

从上表可以看出,两个方案都不错,时间代价和模型大小增加都很小,而精度提升较大。
现在反过头回去看刚开始的模型v0,在精确度没有下降的情况下,我们已经把速度优化了5倍以上,模型大小压缩到原来的1/10,已经满足一个通用的线上模型了。
当然,我们不可能道尽所有的技术,而接着上面的思路,也还有很多可以做的事情,本篇的重点,是让大家学会分析性能网络的性能瓶颈,从而针对性的去优化网络。更多类似技巧和实验,作为技术人员,自己尝试去吧。
同时,在我的知乎专栏也会开始同步更新这个模块,欢迎来交流
https://zhuanlan.zhihu.com/c_151876233
注:部分图片来自网络
—END—
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!
