机器学习(二):基础概念
这是一篇机器学习的介绍,本文不会涉及公式推导,主要是一些算法思想的随笔记录。
适用人群:机器学习初学者,转AI的开发人员。
编程语言:Python
参考书籍:《Python机器学习实践指南》《机器学习实战》
参考视频:吴恩达老师的机器学习系列视频
吴恩达老师机器学习笔记整理
笔记下载:机器学习个人笔记完整版
什么是机器学习
机器学习是人工智能的一个分支,实际上,即使是在机器学习的专业人士中,也不存在一个被广泛认可的定义来准确定义机器学习是什么或不是什么。
年代近一点的定义,由Tom Mitchell提出,来自卡内基梅隆大学,Tom定义的机器学习是,假设用P来评估计算机程序在某任务类T上的性能,若一个程序通过利用经验E在T中任务上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习。
我认为大家不必纠结于机器学习的定义,更普遍的理解如下图所示:
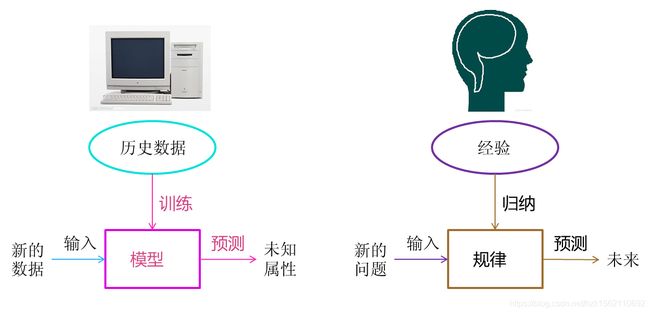
即从大量历史数据中训练出一个模型,基于此模型,能够对新数据进行一种预测。个人理解,机器学习就是对数据的一种探索与挖掘,提取有用的信息进行预测。
机器学习三要素
数据(Data)、算法(Algorithm)、模型(Model)是机器学习三要素,机器学习的输入是数据(Data),学到的结果叫模型(Model)。从数据中学得模型这个过程通过执行某个算法(Algorithm)来完成。
关键术语
- 关键术语
训练(train):可以理解为机器的学习过程。
训练集(training set):用于训练及其学习算法的数据集合。
训练集中有特征和目标变量。
特征(feature)或者属性通常是训练样本集的列,他是独立测量的结果,多个特征联系在一起共同组成的一个训练样本。
目标变量(label):机器学习算法的预测结果。
测试集(testing set):评断模型效果的数据集合。
归一化(normalization):要把你需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保正程序运行时收敛加快。
- 监督学习(supervised learning)与无监督学习(unsupervised learning)
监督学习需要用户知道目标值(label),简单地说就是知道在数据中寻找什么。
无监督学习则无需用户知道搜寻的目标,只需要从算法中得到这些数据的共同特征。如K-均值聚类算法、用于关联分析的Apriori算法及使用FP-growth算法改进关联分析。
监督学习相对比较简单,机器只需从输入数据中预测合适的模型,并从中计算出目标变量的结果。一般使用两种类型的目标变量:标称型(离散型)与数值型。标称型目标变量的结果只在有限目标集中取值(如真与假、动物分类集合{ 爬行类、鱼类、哺乳类、两栖类、植物、真 菌 })——用于分类(Classification);数值型:数值型目标变量则可以从无限的数值集合中取值(如 0.100、42.001、000.743等 )—–用于回归(Regression)。
分类与回归是监督学习的两大任务。
非监督学习的任务有聚类(Clustering)、关联分析(Association Analysis)、降维(Dimension Reduction)等。
除此监督学习和无监督学习这两个主要分类之外,还有半监督学习(Semi-Supervised Learning,SSL):是模式识别和机器学习领域研究的重点问题,是监督学习与无监督学习相结合的一种学习方法。半监督学习使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。
另外,强化学习(Reinforcement Learning,又称再励学习、评价学习)也是使用未标记的数据,但是可以通过某种方法知道你是离正确答案越来越近还是越来越远(即奖惩函数)。可以把奖惩函数想象成正确答案的一个延迟的、稀疏的形式。在监督学习中,能直接得到每个输入的对应的输出。强化学习中,训练一段时间后,你才能得到一个延迟的反馈,并且只有一点提示说明你是离答案越来越远还是越来越近。
算法
- 算法分类
 注意:决策树(Decision Trees)、随机森林(Random Forests) 、支持向量机(SVM)等既可以做分类,也可以做回归。
注意:决策树(Decision Trees)、随机森林(Random Forests) 、支持向量机(SVM)等既可以做分类,也可以做回归。 - 如何初步选择合适的算法

开发机器学习应用程序的步骤
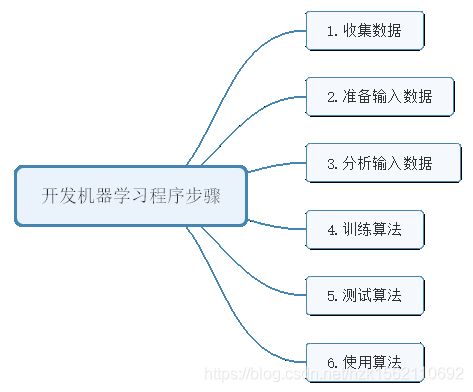
1、收集数据
收集我们关心的数据,方法如:网络爬虫,一些设备发送过来的数据,如从物联网设备获取来的数据。
2、准备输入数据
得到数据之后,我们要确保得到的数据格式符合要求。如某些算法要求特征值需要使用特定的格式。
3、分析输入的数据
查看是否有明显的异常值,如某些数据点和数据集中的其他值存在明显的差异。通过一维,二维或者三维图形化展示数据是个不错的方法,但是我们得到的数据的特征值都不会低于三个,无法一次图形化展示所有特征。我们可以通过数据的提炼,压缩多维特征到二维或者一维。确定数据集中没有垃圾数据。
4、训练算法
机器学习算法从这一步,才真正的开始。考虑算法是属于监督学习算法还是无监督学习算法。
如果使用无监督学习算法,由于不存在目标变量值,故而也不需要训练算法,所有与算法相关的内容都在第5步。
5、测试算法
这一步将实际使用第4步机器学习得到的知识信息。为了评估算法,必须测试算法工作的效果。对于监督学习,必须已知用于评估算法的目标变量值;对于无监督学习,也必须通过其他的评测手段来检测算法的成功率。如果不满意预测结果,返回第四步。
6、使用算法
这一步是将机器学习算法转化为应用程序,执行实际任务。
