Windows10搭建zookeeper集群及Java客户端测试
大部分分布式应用需要一个主控、协调器或者控制器来管理物理分布的子进程。目前,大多数都要开发私有的协调程序,缺乏一个通用机制,协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器,zookeeper提供通用的分布式锁服务,用以协调分布式应用。所以说zookeeper是分布式应用的协作服务。
zookeeper作为注册中心,服务器和客户端都要访问,如果有大量的并发,肯定会有等待。所以可以通过zookeeper集群解决。
下面是zookeeper集群部署结构图:
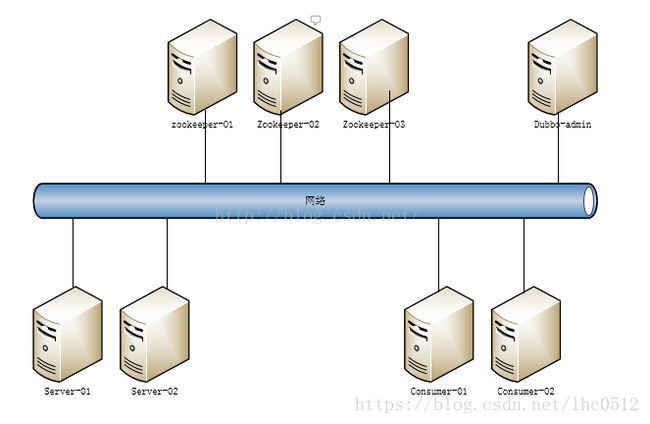
首先到官网下载
http://www-eu.apache.org/dist/zookeeper/zookeeper-3.4.13/
我就解压到D:\server\zookeeper-cluster
第一个节点重名为zookeeper-1
在D:\server\zookeeper-cluster\zookeeper-1\conf目录下
把zoo_sample.cfg 重名为zoo.cfg
打开zoo.cfg
第一个客户端默认为2181,不变,其他两个位2182和2183
clientPort=2181创建文件夹并配置目录,其他两个为 zookeeper-2 和zookeeper-3
dataDir=D:\\server\\zookeeper-cluster\\zookeeper-1\\data
dataLogDir=D:\\server\\zookeeper-cluster\\zookeeper-1\\log配置集群节点
2881为集群节点的通行端口,3881为集群节点的投票端口,下面类似
server.1=localhost:2881:3881
server.2=localhost:2882:3882
server.3=localhost:2883:3883在dataDir=D:\server\zookeeper-cluster\zookeeper-1\data目录下创建myid文件 写1
其他节点类似
节点二
myid为2
clientPort=2182
dataDir=D:\\server\\zookeeper-cluster\\zookeeper-2\\data
dataLogDir=D:\\server\\-cluster\\zookeeper-2\\log节点三
myid为3
clientPort=2183dataDir=D:\\server\\zookeeper-cluster\\zookeeper-3\\data
dataLogDir=D:\\server\\-cluster\\zookeeper-3\\log到D:\soft-ware\zookeeper-3.4.13\bin
通过cmd启动三个节点的zookeeper,由于三个节点,由于zookeeper的选举机制可知,至少需要2个节点的启动才能运行,leader为节点2,其他为flower
zkServer.cmd 启动服务器
zkCli.cmd 启动客户端
zookeeper的所有shell命令
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port接下使用java客户端测试zookeeper集群
引入依赖
<dependency>
<groupId>org.apache.zookeepergroupId>
<artifactId>zookeeperartifactId>
<version>3.4.11version>
dependency>
代码很简单,注释写的很清楚了
public class Test {
// 会话超时时间,设置为与系统默认时间一致
private static final int SESSION_TIMEOUT = 30 * 1000;
// 创建 ZooKeeper 实例
private ZooKeeper zk;
// 创建 Watcher 实例
private Watcher wh = new Watcher() {
/**
* Watched事件
*/
public void process(WatchedEvent event) {
System.out.println("WatchedEvent >>> " + event.toString());
}
};
// 初始化 ZooKeeper 实例
private void createZKInstance() throws IOException {
// 连接到ZK服务,多个可以用逗号分割写
zk = new ZooKeeper("localhost:2181,localhost:2182,localhost:2183", Test.SESSION_TIMEOUT, this.wh);
}
private void ZKOperations() throws IOException, InterruptedException, KeeperException {
//权限: OPEN_ACL_UNSAFE ,节点类型: Persistent
zk.create("/test", "lhc0512".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
//查看
System.out.println(new String(zk.getData("/test", this.wh, null)));//lhc0512
// 修改
zk.setData("/test", "llhhcc".getBytes(), -1);//WatchedEvent >>> WatchedEvent state:SyncConnected type:NodeDataChanged path:/test
// 这里再次进行修改,则不会触发Watch事件,这就是我们验证ZK的一个特性“一次性触发”
zk.setData("/test", "llhhcc0512".getBytes(), -1);
//查看
System.out.println(new String(zk.getData("/test", false, null)));//llhhcc0512
//删除
zk.delete("/test", -1);
//查看是否删除
System.out.println(" 节点状态: [" + zk.exists("/test", false) + "]");// 节点状态: [null]
}
//关闭
private void ZKClose() throws InterruptedException {
zk.close();
}
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
Test dm = new Test();
dm.createZKInstance();
dm.ZKOperations();
dm.ZKClose();
}
}