Hadoop入门(五)IO操作
一、HadoopIO操作意义
Hadoop自带一套用于I/O的原子性的操作
(不会被线程调度机制打断,一直到结束,中间不会有任何context switch)
特点
基于保障海量数据集的完整性和压缩性
Hadoop提供了一些用于开发分布式系统的API(一些序列化操作+基于磁盘的底层数据结构)
二、HDFS数据完整性
用户希望储存和处理数据的时候,不会有任何损失或者损坏。
Hadoop提供两种校验
1校验和(常用循环冗余校验CRC-32)
2运行后台进程来检测数据块
(1)校验和
- 写入数据节点验证
- 读取数据节点验证
- 恢复数据
- Localfilesystem类
- ChecksumfileSystem类
(2)写入数据节点验证
Hdfs会对写入的所有数据计算校验和,并在读取数据时验证校验和。
元数据节点负责在验证收到的数据后,储存数据及其校验和。在收到客户端数据或复制其他datanode的数据时执行。
正在写数据的客户端将数据及其校验和发送到一系列数据节点组成的管线,管线的最后一个数据节点负责验证校验和
(3)读取数据节点验证
客户端读取数据节点数据也会验证校验和,将它们与数据节点中储存的校验和进行比较。
每个数据节点都持久化一个用于验证的校验和日志。
客户端成功验证一个数据块后,会告诉这个数据节点,数据节点由此更新日志。
(4)恢复数据
由于hdfs储存着每个数据块的备份,它可以通过复制完好的数据备份来修复损坏的数据块来恢复数据。
(5)Localfilesystem类
Hadoop的LocalFileSystem类是用来执行客户端的校验和验证。当写入一个名为filename的文件时文件系统客户端会在包含文件块校验和的同一目录内建立一个名为Filename.crc的隐藏文件。
(6)ChecksumfileSystem类
LocalFileSystem类通过ChecksumFileSystem类来完成自己的任务
FileSystem rawFs;
FileSystem checksummedFs=new ChecksumFileSystem(rawFS);
可以通过CheckFileSystem的getRawFileSystem()方法获取源文件系统。
当检测到错误,CheckFileSystem类会调用reportCheckSumFailure()方法报告错误,然后LocalFileSystem将这个出错的文件和校验和移到名为bad_files的文件夹内,管理员可以定期检查这个文件夹。
(7)DatablockScanner
数据节点后台有一个进程DataBlockScanner,定期验证储存在这个数据节点上的所有数据项,该项措施是为解决物理储存媒介上的损坏。DataBlockScanner是作为数据节点的一个后台线程工作的,跟着数据节点同时启动
它的工作流程如图
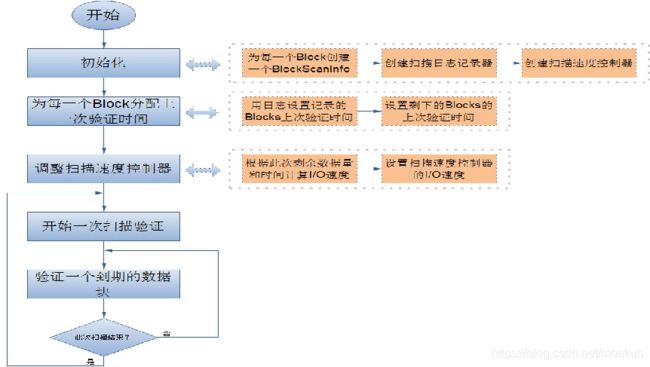
由于对数据节点上的每一个数据块扫描一遍要消耗较多系统资源,因此扫描周期的值一般比较大,
这就带来另一个问题,就是在一个扫描周期内可能出现数据节点重启的情况,所以为了提高系统性能,避免数据节点在启动后对还没有过期的数据块又扫描一遍,
DataBlockScanner在其内部使用了日志记录器来持久化保存每一个数据块上一次扫描的时间
这样的话,数据节点可以在启动之后通过日志文件来恢复之前所有的数据块的有效时间。
三、基于文件的数据结构
HDFS和MR主要针对大数据文件来设计,在小文件处理上效率低.解决方法是选择一个容器,将这些小文件包装起来,将整个文件作为一条记录,可以获取更高效率的储存和处理,避免多次打开关闭流耗费计算资源.hdfs提供了两种类型的容器 SequenceFile和MapFile
小文件问题解决方案
在原有HDFS基础上添加一个小文件处理模块,具体操作流程如下:
- 当用户上传文件时,判断该文件是否属于小文件,如果是,则交给小文件处理模块处理,否则,交给通用文件处理模块处理。在小文件模块中开启一定时任务,其主要功能是当模块中文件总size大于HDFS上block大小的文件时,则通过SequenceFile组件以文件名做key,相应的文件内容为value将这些小文件一次性写入hdfs模块。
- 同时删除已处理的文件,并将结果写入数据库。
- 当用户进行读取操作时,可根据数据库中的结果标志来读取文件。
四、Sequence file
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。Hadoop-0.21.0版本开始中提供了SequenceFile,包括Writer,Reader和SequenceFileSorter类进行写,读和排序操作。该方案对于小文件的存取都比较自由,不限制用户和文件的多少,支持Append追加写入,支持三级文档压缩(不压缩、文件级、块级别)。其存储结构如下图所示:

(1)SequenceFile储存
文件中每条记录是可序列化,可持久化的键值对,提供相应的读写器和排序器,写操作根据压缩的类型分为3种
- Write 无压缩写数据
- RecordCompressWriter记录级压缩文件,只压缩值
- BlockCompressWrite块级压缩文件,键值采用独立压缩方式
在储存结构上,sequenceFile主要由一个Header后跟多条Record组成,如图
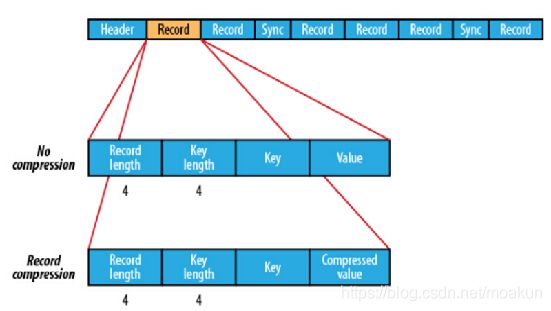
前三个字节是一个Bytes SEQ代表着版本号,同时header也包括key的名称,value class , 压缩细节,metadata,以及Sync markers。Sync markers的作用在于可以读取任意位置的数据。
在recourds中,又分为是否压缩格式。当没有被压缩时,key与value使用Serialization序列化写入SequenceFile。当选择压缩格式时,record的压缩格式与没有压缩其实不尽相同,除了value的bytes被压缩,key是不被压缩的。
当保存的记录很多时候,可以把一串记录组织到一起同一压缩成一块。
在Block中,它使所有的信息进行压缩,压缩的最小大小由配置文件中,io.seqfile.compress.blocksize配置项决定。
(2)SequenceFile写操作
通过createWrite创建SequenceFile对象,返回Write实例,指定待写入的数据流如FSDataOutputStream或FileSystem对象和Path对象。还需指定Configuration对象和键值类型(都需要能序列化)。
SequenceFile通过API来完成新记录的添加操作 fileWriter.append(key,value);
private static void writeTest(FileSystem fs, int count, int seed, Path file,
CompressionType compressionType, CompressionCodec codec)
throws IOException {
fs.delete(file, true);
LOG.info("creating " + count + " records with " + compressionType +
" compression");
//指明压缩方式
SequenceFile.Writer writer = SequenceFile.createWriter(fs, conf, file,
RandomDatum.class, RandomDatum.class, compressionType, codec);
RandomDatum.Generator generator = new RandomDatum.Generator(seed);
for (int i = 0; i < count; i++) {
generator.next();
//keyh
RandomDatum key = generator.getKey();
//value
RandomDatum value = generator.getValue();
//追加写入
writer.append(key, value);
}
writer.close();
}
public class SequenceFileWriteDemo {
private static final String[] DATA = {"One, two, buckle my shoe", "Three, four, shut the door", "Five, six, pick up sticks", "Seven, eight, lay them straight", "Nine, ten, a big fat hen"};
public static void main(String[] args) throws IOException {
String uri = =“hdfs:
//master:8020/number.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
IntWritable key = new IntWritable();
Text value = new Text();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path, key.getClass(), value.getClass());
for (int i = 0; i < 100; i++) {
key.set(100 - i);
value.set(DATA[i % DATA.length]);
System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
}
(3)读取SequenceFile
public class SequenceFileReadDemo {
public static void main(String[] args) throws IOException {
String uri = =“hdfs://master:8020/number.seq";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path path = new Path(uri);
SequenceFile.Reader reader = null;
try {
reader = new SequenceFile.Reader(fs, path, conf);
Writable key = (Writable)
ReflectionUtils.newInstance(reader.getKeyClass(), conf);
Writable value = (Writable)
ReflectionUtils.newInstance(reader.getValueClass(), conf);
long position = reader.getPosition();
while (reader.next(key, value)) {
//同步记录的边界
String syncSeen = reader.syncSeen() ? "*" : "";
System.out.printf("[%s%s]\t%s\t%s\n", position, syncSeen, key, value);
position = reader.getPosition(); // beginning of next record
}
} finally {
IOUtils.closeStream(reader);
}
}
}
示例2
写入了100条(key,value)的信息,其中以LongWriable为key,以Text作为value
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(conf);
int i = 0; Path path = new Path("/home/lake/hello.xml"); SequenceFile.Writer writer = null;
SequenceFile.Writer.Option optPath = SequenceFile.Writer.file(path);
//定义key
SequenceFile.Writer.Option optKey = SequenceFile.Writer.keyClass(LongWritable.class);
//定义value
SequenceFile.Writer.Option optVal = SequenceFile.Writer.valueClass(Text.class); writer = SequenceFile.createWriter(conf, optPath, optKey, optVal);
//写入的数据测试
String value = "hello world";
while(i < 100){
writer.append(new LongWritable(i),new Text(value)); i ++;
}
writer.close();
读取的代码
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path("/home/lake/hello.xml"); SequenceFile.Reader reader = new SequenceFile.Reader(fs.getConf(), SequenceFile.Reader.file(path));
List
五、MapFile
一个MapFile可以通过SequenceFile的地址,进行分类查找的格式。使用这个格式的优点在于,首先会将SequenceFile中的地址都加载入内存,并且进行了key值排序,从而提供更快的数据查找。
与SequenceFile只生成一个文件不同,MapFile生成一个文件夹。
索引模型按128个键建立的,可以通过io.map.index.interval来修改
缺点
1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的
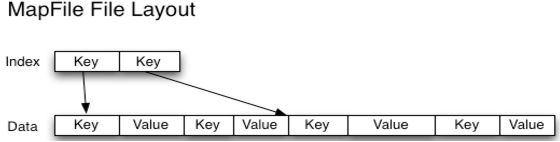
排序后的SequeneceFile,并且它会额外生成一个索引文件提供按键的查找.读写mapFile与读写SequenceFile非常类似,只需要换成MapFile.Reader和MapFile.Writer就可以了。
在命令行显示mapFile的文件内容同样要用 -text
(1)MapFile写操作
public class MapFileWriteFile {
private static final String[] myValue = {"hello world", "bye world", "hello hadoop", "bye hadoop"};
public static void main(String[] args) {
String uri = "hdfs://master:8020/number.map";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
IntWritable key = new IntWritable();
Text value = new Text();
MapFile.Writer writer = null;
try {
writer = new MapFile.Writer(conf, fs, uri, key.getClass(), value.getClass());
for (int i = 0; i < 500; i) {
key.set(i);
value.set(myValue[i % myValue.length]);
writer.append(key, value);
}
}finally{
IOUtils.closeStream(writer);
}
}
}
}
MapFile会生成2个文件 1个名data,1个名index 查看前10条data+index $ hdfs –fs –text /number.map/data | head
(2)读取MapFile
public class MapFileReadFile {
public static void main(String[] args) {
String uri ="hdfs://master:8020/number.map";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
MapFile.Reader reader = null;
try {
reader = new MapFile.Reader(fs, uri, conf);
WritableComparable key = (WritableComparable) ReflectionUtils.newInstance(reader.getValueClass(), conf);
while (reader.next(key, value)) {
System.out.printf("%s\t%s\n", key, value);
}
reader.get(new IntWritable(7), value);
System.out.printf("%s\n", value);
} finally {
IOUtils.closeStream(reader);
}
}
}SequenceFile文件是用来存储key-value数据的,但它并不保证这些存储的key-value是有序的, 而MapFile文件则可以看做是存储有序key-value的SequenceFile文件。 MapFile文件保证key-value的有序(基于key)是通过每一次写入key-value时的检查机制,这种检查机制其实很简单,就是保证当前正要写入的key-value与上一个刚写入的key-value符合设定的顺序, 但是,这种有序是由用户来保证的,一旦写入的key-value不符合key的非递减顺序,则会直接报错而不是自动的去对输入的key-value排序
(3)SequenceFile转换为MapFile
mapFile既然是排序和索引后的SequenceFile那么自然可以把SequenceFile转换为MapFile使用mapFile.fix()方法把一个SequenceFile文件转换成MapFile
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
URI uri = new URI(“hdfs://master:8020/number.map”);//uri下必须有要转换的sq文件
FileSystem fs = FileSystem.get(uri, conf);
Path map = new Path(uri.toString());
Path mapData = new Path(map, MapFile.DATA_FILE_NAME);
SequenceFile.Reader read = new SequenceFile.Reader(fs, mapData, conf);
Class keyClass = read.getKeyClass();
Class valueClass = reader.getValueClass();
read.close();
longentries = MapFile.fix(fs, map, keyClass, valueClass, false, conf);
System.out.printf(“create MapFile % s with % d entries\n”, map, entries);
}
六、压缩
减少储存文件所需空间,还可以降低其在网络上传输的时间。 压缩算法对比

Bzip2支持切分 splitting.hdfs上文件1GB,如按照默认块64MB,那么这个文件被分为16个块。如果把这个块放入MR任务 ,将有16个map任务输入。如果算法不支持切分,后果是MR把这个文件作为一个Map输入。这样任务减少了,降低了数据的本地性。
(1)CodeC
实现了一种压缩解压算法。Hadoop中压缩解压类实现CompressionCodec接口createOutputStream来创建一个CompressionOutputStream,将其压缩格式写入底层的流
演示HDFS上一个1.bzip2算法压缩的文件解压,然后把解压的文件压缩成2.gz
(2)本地库
Hadoop使用java开发,但是有些需求和操作并不适合java,所以引入了本地库 native。可以高效执行某些操作。如使用gzip压缩解压时,使用本地库比使用java时间要缩短大约10%,解压达到50%。在hadoop_home/lib/native下
在hadoop配置文件core-site.xml可以设置是否使用native
Hadoop.native.lib
true
默认是启用本地库,如果频繁使用原生库做压解压任务,可以使用codecpool,通过CodecPool的getCompressor方法获得Compressor对象,需要传入Codec 。这样可以节省创建Codec对象开销 ,允许反复使用。
(3)如何选择压缩格式
- Gzip 优点是压缩率高,速度快。Hadoop支持与直接处理文本一样。缺点不支持split,当文件压缩在128m内,都可以用gzip
- Izo 优点压缩速度快 合理的压缩率;支持split,是最流行的压缩格式。支持native库;缺点 比gzip压缩率低,hadoop本身不支持,需要安装;在应用中对lzo格式文件需要处理如 指定inputformat为lzo格式
- Snappy压缩 高速压缩率合理支持本地库。不支持split,hadoop不支持 要安装linux没有对应命令;当MR输出数据较大,作为到reduce数据压缩格式
- Bzip2 支持split,很高的压缩率,比gzip高,hadoop支持但不支持native,linux自带命令使用方便。缺点压缩解压速度慢
使用哪种压缩和具体应用有关,对于巨大,没有储存边界的文件如日志 可以考虑
- 储存不压缩的文件
- 使用支持切分的储存格式 bzip2
- 在应用中切分,然后压缩,需要选择合理数据块的大小,以确定压缩后的块大小
- 使用顺序文件SF,支持压缩和切分
- 使用Avro数据文件,支持压缩切分并增加了编程语言可读写的优势对于大文件,不应该使用不支持切分的压缩格式,否则失去本地性,造成MR应用效率低下。
七、序列化
为什么Hadoop基本类型还要定义序列化?
- Hadoop在集群之间通信或者RPC调用时需要序列化,而且要求序列化要快,且体积要小,占用带宽小。
- java的序列化机制占用大量计算开销,且序列化结果体积过大;它的引用机制也导致大文件不能被切分,浪费空间;此外,很难对其他语言进行扩展使用;
- java的反序列化过程每次都会构造新的对象,不能复用对象。
Hadoop定义了两个序列化相关接口
Writable和Comparable
WritableComparable接口相当于继承了上述两个接口的新接口
Public interface WritableComparable
extends Writable,Comparable
(1)Writable接口
基于DataInput与DatOutput的简单高效可序列化接口,就是org.apache.hadoop.io.Writable接口
几乎所有的hadoop可序列化对象都必须实现这个接口有2个方法
Write,readFiles
以IntWritable为例,它把java的int类型封装成了Writable序列化格式
可以通过set()设置它的值
new IntWritable().set(100);
new IntWritable(100);
(2)WritableComparable接口
类似java的Comparable接口,用于类型的比较。MR其中一个阶段叫排序,默认使用Key来排序。Hadoop提供了一个优化接口RawComparator
Public interface RawComparator
Public int compare(byte[] b1,int s1,int l1,byte[] b2,int s2,int l2);
}
可以比较b1和b2,允许执行者直接比较数据流记录,而无须先把数据流反序列化成对象,这样可以避免新建对象的开销 。
八、Writable类
ArrayWritable
TwoDArrayWritable
MapWritable
SortedMapWritable
BooleanWritable
ByteWritable
IntWritable
VIntWritable
FloatWritable
LongWritable
VLongWritable
DoubleWritable
NullWritable
Text
BytesWritable
MD5Hash
ObjectWrtiable
GenericWritable
| Java primitive |
Writable Implementation |
Serialized size(bytes) |
| boolean |
BooleanWritable |
1 |
| byte |
ByteWritable |
1 |
| short |
ShortWritable |
2 |
| int |
IntWritable |
4 |
|
|
VIntWritable |
1-5 |
| float |
FloatWritable |
4 |
| long |
LongWritable |
8 |
| VLongWritable |
1-9 |
|
| double |
DoubleWritable |
8 |
(1)Text
存储的数据按照UTF-8,类似String,它提供了序列化,反序列化和字节级别比较的方法。Text类替换了UTF8类。
1.unicode编码是一个很大的集合,可以容纳100多万个符号。具体的符号对应表可以查询unicode.org 它只规定了符号的二进制代码,没有规定如何存储,而utf-8就是unicode的实现还有utf16等。对于单个字符字节第一位为0,后面7位为这个符号的unicode码。因此对于英语字母,utf-8编码和ASCII码是相同的。所有\u0001~\u007f会以单字节储存。\u0080~\u07ff的unicode会以双字节储存,\u0800~\uFFFF的会以3字节存储。
2.例子 Text的几个方法 一旦使用多字节编码Text和String区别就明显了
public void testText() throws UnsupportedEncodingException {
Text T = new Text("你好天地");
String S ="你好天地";
assertEquals(t.getLength(), 12);
assertEquals(s.getBytes("utf-8").length, 12);
assertEquals(s.length(), 4);
assertEquals(t.find("天"), 6);
assertEquals(s.indexOf("天"), 3);
}Text.find()方法返回的是字节偏移量,String.indexOf返回单个编码字符的索引位置,
String.codeprintAt()和Text.charAt类似,前者通过字节偏移量来索引
Text对字符串没有String方法丰富 大多数情况下通过toString转换成String来操作
(2)BytesWritable
相当于二进制数据数组的包装。以字节数组{1,2,3,4}它的序列化格式是4字节表示字节数 ,每2个字节表示一个数据即 “0000 0004 0102 0304” 和Text一样BytesWritable也是可变的 ,可以通过set来修改
(3)NullWritable
NullWritable是writable类型的特殊类型,序列化长度为0,它充当占位符但不真在数据流中读写。NullWritable是单实例类型,通过NullWriable.get()方法获取
(4)ObjectWritable和GenericWritable
ObjectWritable是对java基本类型的和这些类型的数组类型的通用封装 ,使用RPC来封送
(5)自定义Writable类型
Hadoop基本满足大部分需求,但有些情况下可以根据业务需要构造新的实现,为了提高MR作业的性能,因为Writable是MR的核心。 例子:假如 要处理一组姓名字段,不能单独处理名和姓。 下面表示一对字符串TextPair的基本实现
public class TextPair implements WritableComparable {
private Text first, second;
public TextPair() {
set(new Text(), new Text());
}
public TextPair(String first, String second) {
set(new Text(first), new Text(second));
}
public TextPair(Text first, Text second) {
set(first, second);
}
public void set(Text first, Text second) {
this.first = first;
this.second = second;
}
public Text getFirst() {
return first;
}
public Text getSecond() {
return second;
}
public void readFields(DataInput in) {
First.readFields(in);
Second.readFields(in);
}
public void write(DataOutput out) {
first.write(out);
second.write(out);
}
public int compareTo(TextPair tp) {
int cmp = first.compareTo(tp.first);
if (cmp != 0) return cmp;
return second.compareTo(tp.second);
}
public int hashCode() {
return first.hashCode() * 163 + second.hashCode();
}
public Boolean equals(Object o) {
if (o instanceof TextPair) {
TextPair tp = (TextPair) o;
return first.equals(tp.first) && second.equals(tp.second);
}
return false;
}
public String toString() {
return first +"\t"+second;
}
}
示例说明:
TextPair类的write()方法将first和 second两个字段序列化到输出流中,
反之 readFields方法对来自输入流的字节进行反序列化处理。
DataOutput和DataInput接口提供了底层的序列化和反 序列化方法。
所以可以完全控制Writable对象的数据传输格式。
与java值对象一样,必须重写object的hashCode,equals和toString()方法。hashCode给后面的MR进行 reduce分区使用
最后 这个类 继承了WritableComparable接口,所以必须提供CompareTo方法的实现,该 方法 按first排序 ,如相同按second排序。
九、小结
HDFS以CRC校验来检测数据是否为完整的,并在默认设置下,会读取数据时验证校验和,保证其数据的完整性,其所有序列化数据结构都是针对大数据处理的。
Hadoop对大数据的压缩和解压机制,可以减少储存 空间和加速数据在网络上的传输。
在hadoop中通过序列化将消息编码为二进制流发送到远程节点,此后在接收端接收的二进制流被反序列化为消息。Hadoop没有采用java的序列化,实现了自己的writable接口。