李宏毅学习笔记5.逻辑斯蒂回归
文章目录
- logistics与linear 回归的比较
- logistics回归的三板斧
- 步骤一 找function set
- 步骤二: Goodness of a function(决定函数的好坏)
- 步骤三:find the best function
- 填坑:为什么Logistics回归的损失函数不用square error
- Discriminative vs Generative
- 那个模型比较强?
- 最后结论
- 多分类问题Multi-class Classification
- 问题描述
- 解决问题.
- 逻辑斯蒂回归的限制 Limitation of Logistic Regression
- 不能解决与非门。
- 解决方案
- 解决方案Cont. 逻辑斯蒂回归的级联(cascading)
logistics与linear 回归的比较

虽然这个比较放最前面,其实老师是在讲解logistics回归的三个步骤的过程中每一个步骤都比较一下的。
logistics回归的三板斧
老师的套路就是概述中提到的,机器学习很简单就是三个步骤,现在学习logistics regression,也是按三个步骤来进行。
顺便熟悉Latex公式输入,可以这个网站进行速查
在线Latex公式
步骤一 找function set

其中w是n维向量,它的每个维度dimension用下标i进行标记
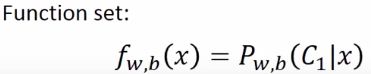
选择不同的w和b就得到不同的function,所有的w和b不同的组合,就形成了function set,每个function其实就是特定的w和b,给定x,属于c1类的概率,用图像的方式来表示function set,其中xi是输入,wi是权重weight,常数b是bias,输出值是概率probability。
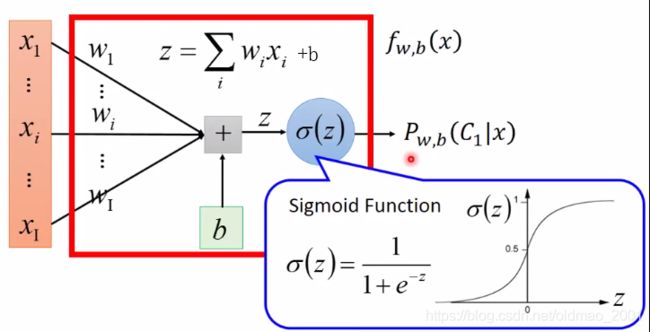
步骤二: Goodness of a function(决定函数的好坏)

L ( w , b ) L(w,b) L(w,b)的含义是给定w和b,得到 x 1 , x 2 , x 3 . . . . . . x N x^1,x^2,x^3......x^N x1,x2,x3......xN的概率,而 w ∗ 和 b ∗ w^*和b^* w∗和b∗是使得这个概率最大的两个参数。
w ∗ , b ∗ = a r g m a x w , b L ( w , b ) w^*,b^*=arg\underset{w,b}{max}L(w,b) w∗,b∗=argw,bmaxL(w,b)等价于求最小 w ∗ , b ∗ = a r g m i n w , b [ − l n L ( w , b ) ] w^*,b^*=arg\underset{w,b}{min}[-lnL(w,b)] w∗,b∗=argw,bmin[−lnL(w,b)]

下面那里是 − l n L ( w , b ) -lnL(w,b) −lnL(w,b)的展开,这个展开的每一项为什么可以变成箭头右边的东西?因为:

PS:老师ppt里面有点错,手动改了一下。
上图中当输入的xi属于C1时 y ∧ \overset{\wedge}{y} y∧为1,反之为 0 = 1 − y ∧ 0=1-\overset{\wedge}{y} 0=1−y∧(因为是二分类问题)。所以把上图带入箭头后面的公式就会发现,这样的写法是等价的:

把上面的内容整理一下,得到:

蓝色字是很大一个坑,第一次接触会有点听不懂,先记下来,大概意思是说这个式子代表两个伯努利分布的交叉熵。

交叉熵的公式是:
H ( p , q ) = − ∑ x p ( x ) l n ( q ( x ) ) H(p,q)=-\underset{x}{\sum}p(x)ln(q(x)) H(p,q)=−x∑p(x)ln(q(x))
交叉熵的含义老师给出解释是:两个分布接近的程度。如果两个分布一模一样,则 H ( p , q ) = 0 H(p,q)=0 H(p,q)=0,也就是说我们把function的输出 f ( x n ) f(x^n) f(xn)以及target即 y n ∧ \overset{\wedge}{y^n} yn∧看成两个伯努利分布,我们希望这两个分布越接近越好,越接近则他们二者的交叉熵也就越小,目标就是要最小化cross entropy。

挖坑:为什么逻辑斯蒂回归不用线性回归中的方差作为损失函数的形式?
步骤三:find the best function
总体思想:梯度下降
已有公式:
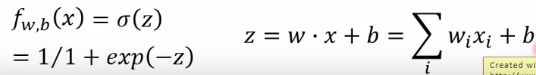
求导数:
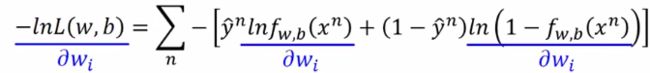
由于 l n f w , b ( x n ) lnf_{w,b}(x^n) lnfw,b(xn)从已有公式中可以看出它是一个复合函数,所以它对 w i w_i wi求偏导可以使用链式法则:

这里基本都可以秒懂,可能有些同学对于 ∂ σ ( z ) ∂ z {\frac {\partial \sigma(z)}{\partial z}} ∂z∂σ(z)的计算不清楚,这里有两个方法,一个就直接当公式记下来,另外一个就是理解一下,老师给出 σ ( z ) \sigma (z) σ(z)和 ∂ σ ( z ) ∂ z {\frac {\partial \sigma(z)}{\partial z}} ∂z∂σ(z)的图形,可以看到 σ ( z ) \sigma (z) σ(z)的头尾两端变化比较小(斜率小),中间变化比较大(斜率大)上面的式子消掉 σ ( z ) \sigma (z) σ(z)
,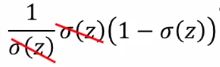
然后带回去:
同理,用链式法则算右边那项:
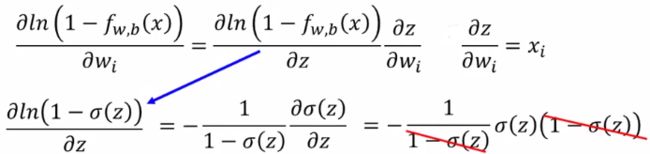
带入后:
整理:
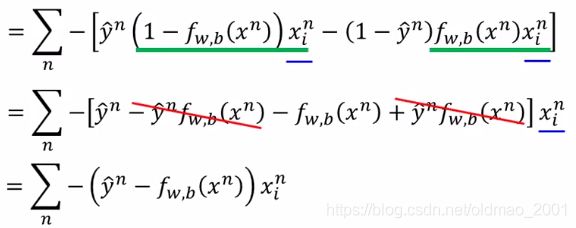
把蓝色部分 x i n x^n_i xin提出来,绿色部分展开,然后消掉得到结果。
然后老师对这个结果做了一个解释。
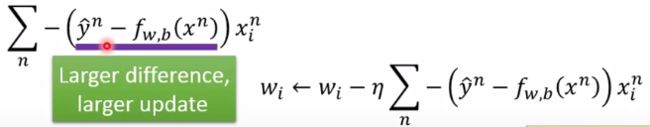
整个梯度更新涉及三个因素:
- Learning Rate
- x i n x^n_i xin,也就是输入的第i个component(这里怕翻译不准,直接引用老师原话)
- y n ∧ − f w , b ( x n ) \overset{\wedge}{y^n} -f_{w,b}(x^n) yn∧−fw,b(xn),这里 y n ∧ \overset{\wedge}{y^n} yn∧(在这里只能取0或1)是实际值(target), f w , b ( x n ) f_{w,b}(x^n) fw,b(xn)是我们的函数输出值,两者差异越大,说明需要更新的量也越大。
填坑:为什么Logistics回归的损失函数不用square error
假设我们现在用square error来计算损失函数会发生什么?
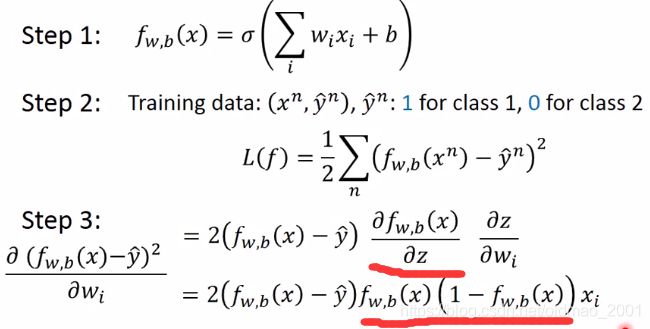
其实红线部分上一节有计算,担心看不懂,所以标一下,上下红线是对应的。
如果第n笔数据的标签是class1,也就是它的 y n ∧ = 1 \overset{\wedge}{y^n}=1 yn∧=1,则它对应两种函数的输出计算出来的偏导都为0,上面那个合理,下面那个不合理。

同理:

做图来看:
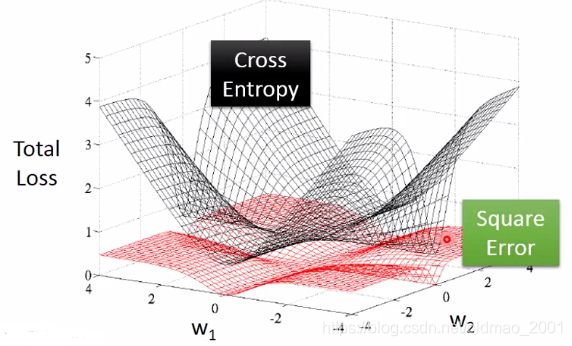
红色是square error。可以从图中看出,中心点为最低点,最低点Loss为0,这个没错,但是离中心点很远的地方,它的Loss也为0,意味着它的参数update速度很慢,实际程序运行就好像卡住一样,反观交叉熵,离中心点越远,他的偏导值越大,更新参数步伐也就越大。
当然square error可以把learning rate设置大一点,以解决梯度参数update过慢的问题,但是这样也会有问题,如果初始点就在中心点附近,这个时候过大的learning rate可能over shooting。
总之使用square error来做二分类在编程上或者说理论上没有问题,但是没有交叉熵来的顺。
Discriminative vs Generative
两类方法的比较,上节课讲的概率生成模型(generative model)以及本节课讲的逻辑斯蒂回归模型(discriminative model)都是使用同一个function set: P ( C 1 ∣ x ) = σ ( w ⋅ x + b ) P(C_1|x)=\sigma(w\cdot x+b) P(C1∣x)=σ(w⋅x+b)。这句话要复习一下
概率生成模型在把两个类别的协方差矩阵取同一个值的时候,就是得到 P ( C 1 ∣ x ) P(C_1|x) P(C1∣x)这个function set。
由于我们的假设不一样,所以在同一个function set中,我们求出来的w和b是不一样的。概率生成模型中的假设是数据来自高斯分布(当然也可以用伯努利分布之类的),而逻辑斯蒂回归没有假设

回到宝可梦一般系和水系预测问题

如果只考虑两个属性两个算法差不多,如果考虑7个属性,可以看到后者要强一丢丢,一些文献上也有这样的说法,为什么??举一个栗子:
那个模型比较强?
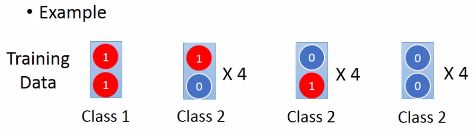
假设数据如上图所示,每笔数据有两个feature,然后两个1的label为class 1,其他的为class 2,如果现在人为看到这么一个数据:

你会怎么分?当然是认为它属于class 1咯。但是我们如果用Naive Bayes的方法来看这个问题,先祭出朴素贝叶斯的公式:
P ( x ∣ C i ) = P ( x 1 ∣ C i ) P ( x 2 ∣ C i ) P(x|C_i)=P(x_1|C_i)P(x_2|C_i) P(x∣Ci)=P(x1∣Ci)P(x2∣Ci)
说人话 从某个class产生x的几率等于从某个class产生x1的几率乘以从某个class产生x2的几率。
然后分别计算下面几个概率:
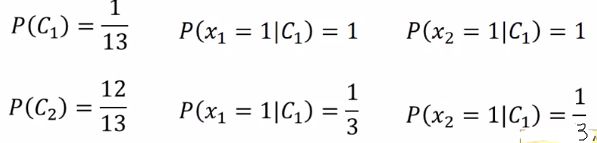
上图中第二排后面两个C1应该是C2.,再计算:
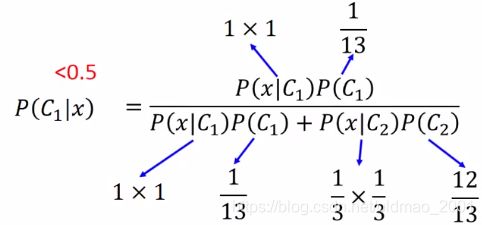
为什么呢?因为朴素贝叶斯不考虑不同dimension之间的corelation,对于朴素贝叶斯而言,这两个dimension是independent产生的。没有在class2中观察到两个dimension都为1的数据没有出现在training data中是因为sample得还不够多。
回到之前的问题:Discriminative vs Generative二者的区别在于哪里?
Generative模型对数据作了一些假设(用老师的话来说就这个模型对数据做了脑补,强行给它加了一些设定),假设数据来自某个分布。脑补这个事情通常不好,因为数据没有明确告诉我们这个设定,但如果数据比较少,脑补会比较有用,就是你得到的情报很少,脑补可以让你得到更多的情报。
最后结论
两个模型在不同场合性能会各有千秋

- Generative会遵循自己的假设,有时候甚至会忽略数据,所以在数据量小的时候比较有优势,Discriminative 则靠数据说话,随着数据量增大,Discriminative 模型的error应该是越来越小。
- 当数据所含noise比较多,Generative要比Discriminative 模型要好,因为数据的label有问题,Generative做了脑补会把数据中的noise问题忽视掉。
- 这里Priors和class-dependent probability没怎么听懂,回头再补充。
多分类问题Multi-class Classification
问题描述
此处以3个分类为例假设有三个类,参数如下:

然后把 z 1 , z 2 , z 3 z_1,z_2,z_3 z1,z2,z3求e的指数运算,红色数字是举栗子算的结果,中间蓝色框是softmax函数,里面进行的操作可以看红色箭头,就是先对各个z求e的指数运算,然后累加,然后分别做为分子被 e z i e^{z_i} ezi除,得到输出 y i = P ( C i ∣ x ) y_i=P(C_i|x) yi=P(Ci∣x),y的含义是用来估计probability,也就是输入x,属于class1的几率为多少(这里是0.88),属于class2的几率是多少(这里是0.12),属于class3的几率是多少(这里是趋近于0)。
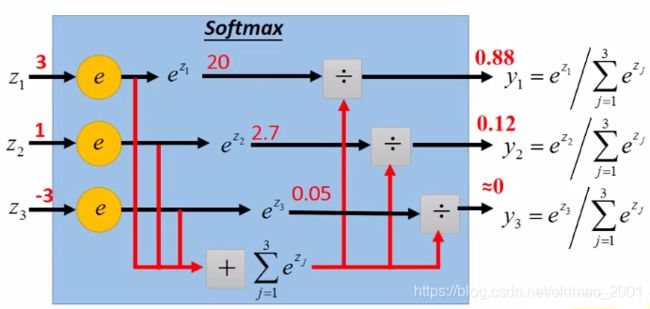
注意:y的集合本身就是一个probability distribution
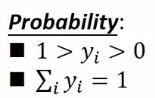
**SOFTMAX函数的含义:**max是求最大值,softmax是对最大值做了强化,强化的意思是由于做了 e z i e^{z_i} ezi运算,放大每个 z i {z_i} zi的值使得每个 z i {z_i} zi值之间的差距拉大
挖坑:为什么这里分类函数是softmax呢?
- 无赖的回答:我喜欢,如果我用别的function你也会问同样的问题。
- 科学的回答:假设数据来自高斯分布,每个类所属分布都使用同一个协方差矩阵,则经过推导,那么就会得到softmax函数。
- 坑:如果从信息论的观点来看这个问题,进行推导后会得到最大熵maximum entropy模型(这个李航的《统计学习方法》里面有)。有能力的同学可以自己推导。
解决问题.
把上面的内容总结得到:

前面说过y是一个probability distribution, y ^ \hat{y} y^做为target应该也是一个probability distribution,这个时候两个分布就可以计算它们的交叉熵,公式如上图中所示,ppt少了一个负号。
y ^ \hat{y} y^的取值怎么弄?如下图:
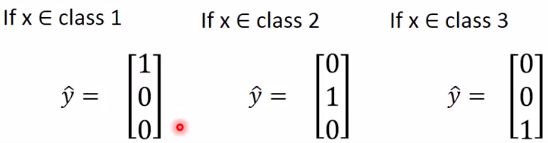
这里要说明一下,为什么不把类别的值设为:
c l a s s 1 = 1 , c l a s s 2 = 2 , c l a s s 3 = 3 class_1=1,class_2=2,class_3=3 class1=1,class2=2,class3=3
这样设置会隐性的给分类加入了额外的限制, c l a s s 1 class_1 class1和 c l a s s 2 class_2 class2比较近(1和2差1), c l a s s 1 class_1 class1和 c l a s s 3 class_3 class3比较远(1和3差2)。所示用上面向量的方式表示就没有问题了。
逻辑斯蒂回归的限制 Limitation of Logistic Regression
不能解决与非门。

无论我们选择什么参数,分界线都不可能把蓝色和红色的点完全分开
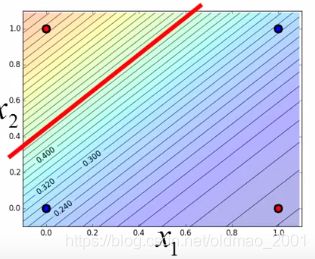
解决方案
做Feature Transformation
转换的原则可以自己定,这里的例子使用的原则是:
x 1 ′ : 转 换 点 到 [ 0 0 ] 的 距 离 x'_1:转换点到\begin{bmatrix} 0\\ 0 \end{bmatrix}的距离 x1′:转换点到[00]的距离
x 1 ′ : 转 换 点 到 [ 1 1 ] 的 距 离 x'_1:转换点到\begin{bmatrix} 1\\ 1 \end{bmatrix}的距离 x1′:转换点到[11]的距离
例如: [ 0 0 ] \begin{bmatrix} 0\\ 0\end{bmatrix} [00]到 [ 0 0 ] \begin{bmatrix} 0\\ 0\end{bmatrix} [00]的距离为0
[ 0 0 ] \begin{bmatrix} 0\\ 0\end{bmatrix} [00]到 [ 1 1 ] \begin{bmatrix} 1\\ 1\end{bmatrix} [11]的距离为 2 \sqrt{2} 2
转换结果就是 [ 0 2 ] \begin{bmatrix} 0\\ \sqrt{2}\end{bmatrix} [02]
下面几个箭头就是转换后的结果对应关系

问题:transformation这个事情不好做,如果要人自己来做,那就失去了机器学习的意义,那如何用机器来做个事情?
解决方案Cont. 逻辑斯蒂回归的级联(cascading)
明显这里是引入DL的引入了

例子:

右上是蓝色那个sigmoid function通过调整w和b可以得到的输出,右下是绿色那个sigmoid function通过调整w和b可以得到的输出,这里的输出就是transformation的结果!

从右下角的图可以看到,通过transformation,把两个红色点变到了(0.73, 0.05)和(0.05, 0.73),把蓝色的点变到了(0.27, 0.27)。这样就把蓝色和红色点分开了。
这就是下一节的内容:深度学习!