Pytorch使用tensorboardX可视化
TensorboardX 用于Pytorch的可视化,支持scalar, image, figure, histogram, audio, text, graph, onnx_graph, embedding, pr_curve and videosummaries等不同的可视化展示方式,具体介绍移步至项目Github 观看详情: https://github.com/lanpa/tensorboardX。
论坛地址:https://github.com/lanpa/tensorboardX/wiki
TensorboardX可以提供中很多的可视化方式,本文主要介绍scalar 和 graph。
安装:
pip install tensorboardX
pip install tensorboard1、scalar 使用
import numpy as np
from tensorboardX import SummaryWriter
writer = SummaryWriter()
for epoch in range(100):
writer.add_scalar('scala/test', np.random.rand(), epoch)
# writer.add_scalar('scalar/scalars_test',{'xsinx': epoch * np.sin(epoch), 'xcosx': epoch*np.cos(epoch)}, epoch)
# 第二个writer会报错,提示NotImplementedError: Got , but expected numpy array or torch tensor.
writer.close() 代码解释:
首先导入:
from tensorboardXimport SummaryWriter,
然后定义一个SummaryWriter() 实例。
看到SummaryWriter()的参数为:
def __init__(self, log_dir=None, comment='', **kwargs):
其中log_dir为生成的文件所放的目录,comment为文件名称。默认目录为生成runs文件夹目录。
运行代码:

当我们为SummaryWriter(comment='base_scalar')

当我们为SummaryWriter(log_dir='scalar') 添加log_dir参数,可以看到生成了新的目录。生成结果目录为:

解释writer.add_scalar()
writer.add_scalar('scalar/test', np.random.rand(), epoch)
# 这句代码作用是:
# 将需要的数据保存到文件里提供可视化使用。这里是Scalar类型(标量),所以使用add_scalar()。
# 第一个参数可以理解为保存图片的名称。
# 第二个参数可以理解为Y轴数据。
# 第三个参数可以理解为X轴数据。生成文件后,在runs同级目录下使用命令行:
# 输入
tensorboard --logdir runs
# 其他路径 如:SummaryWriter(log_dir='scalar')
tensorboard --logdir scalar
点击连接,显示可视化结果:

最后调用writer.close()。
2、Graph使用

# 在tensorboard 添加可视化,其中使用了python的上下文管理,with 语句,可以避免因w.close未写造成的问题。推荐使用此方式。
with SummaryWriter(comment='Net1')as w:
w.add_graph(model, (dummy_input,))
# 参数说明:
# 其中第一个参数为需要保存的模型,第二个参数为输入值,元祖类型。打开tensorvboard控制台,可得到如下结果。

点击Net1部分可以将其网络展开,查看网络内部构造。
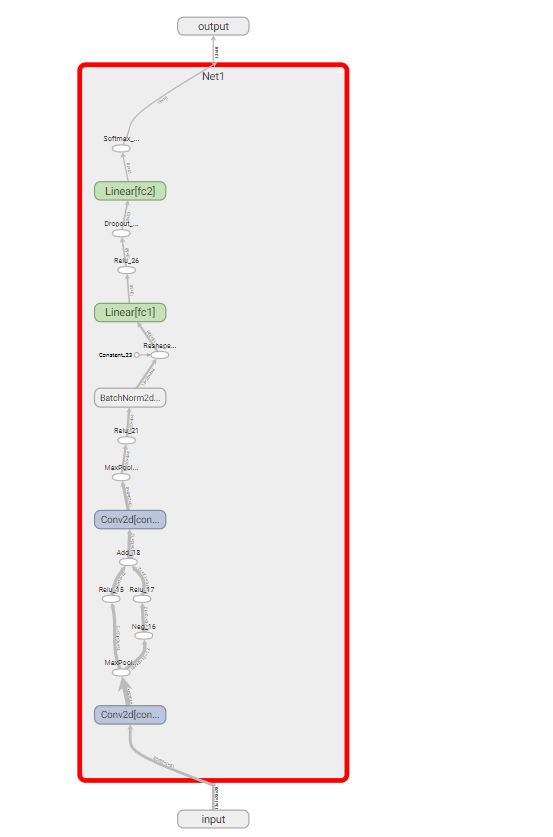
模型可视化结果
案例一:
官网实例:
项目地址:https://github.com/lanpa/tensorboardX
python examples/demo.py
tensorboard --logdir runs
http://localhost:6006/ #在chrome浏览器中打开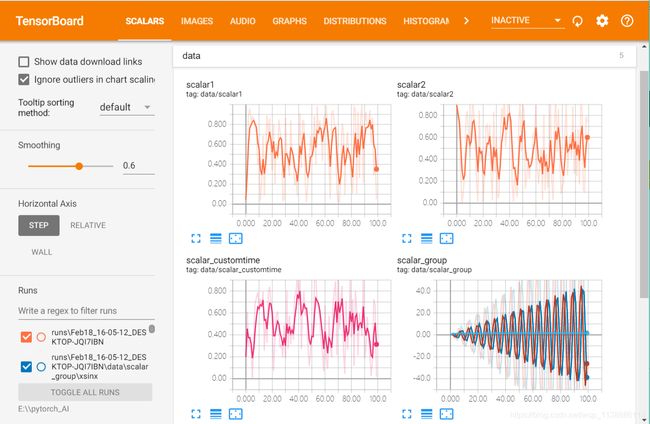
界面说明
SCALAR
对标量数据进行汇总和记录,通常用来可视化训练过程中随着迭代次数准确率(val acc)、损失值(train/test loss)、学习率(learning rate)、每一层的权重和偏置的统计量(mean、std、max/min)等的变化曲线
IMAGES
可视化当前轮训练使用的训练/测试图片或者 feature maps
GRAPHS
可视化计算图的结构及计算图上的信息,通常用来展示网络的结构
HISTOGRAMS
可视化张量的取值分布,记录变量的直方图(统计张量随着迭代轮数的变化情况)
PROJECTOR
全称Embedding Projector 高维向量进行可视化
案例二
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
from PIL import Image
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import models,datasets
from tensorboardX import SummaryWriter
cat_img = Image.open('./Felis_silvestris_catus_lying_on_rice_straw.jpg')
transform_224 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
])
cat_img_224=transform_224(cat_img)
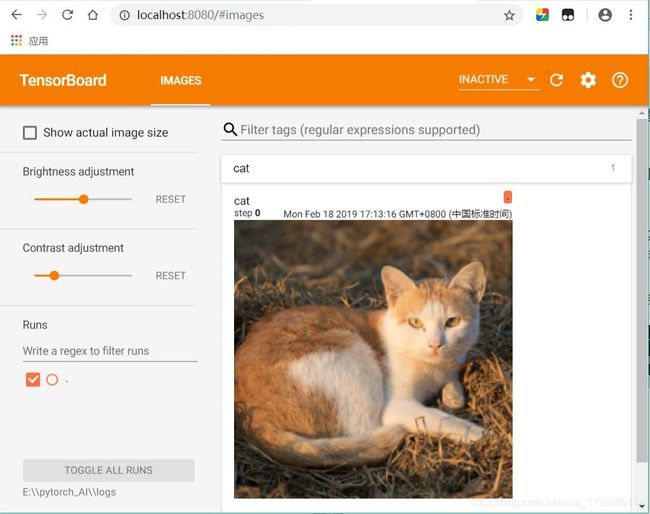
# 将图片展示在tebsorboard中:
writer = SummaryWriter(log_dir='./logs', comment='cat image') # 这里的logs要与--logdir的参数一样
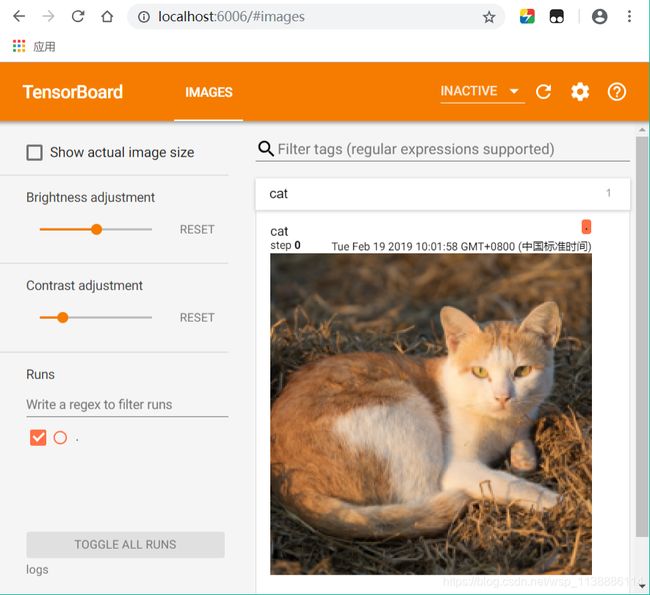
writer.add_image("cat",cat_img_224)
writer.close()# 执行close立即刷新,否则将每120秒自动刷新
# 更新损失函数
# 更新损失函数和训练批次我们与visdom一样使用模拟展示,这里用到的是tensorboard的SCALAR页面
x = torch.FloatTensor([100])
y = torch.FloatTensor([500])
for epoch in range(100):
x /= 1.5
y /= 1.5
loss = y - x
with SummaryWriter(log_dir='./logs', comment='train') as writer: #with语法:自动调用close方法
writer.add_histogram('his/x', x, epoch)
writer.add_histogram('his/y', y, epoch)
writer.add_scalar('data/x', x, epoch)
writer.add_scalar('data/y', y, epoch)
writer.add_scalar('data/loss', loss, epoch)
writer.add_scalars('data/data_group', {'x': x,
'y': y,
'loss': loss}, epoch)
查看图像:
方法一:
激活环境 --> 进入logs目录 -->执行命令 --> chrome下打开http://localhost:8080/
(AI_PyTorch_GPU) E:\pytorch_AI\logs>tensorboard --logdir=E:\\pytorch_AI\\logs --port=8080
TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:8080 (Press CTRL+C to quit)如图:
方法二:
激活环境 --> 进入logs父目录 -->执行命令 --> chrome下打开http://localhost:6006/
(AI_PyTorch_GPU) E:\pytorch_AI>tensorboard --logdir logs
TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:6006 (Press CTRL+C to quit)如图:
3、使用PROJECTOR对高维向量可视化
PROJECTOR的的原理是通过PCA,T-SNE等方法将高维向量投影到三维坐标系(降维度)。Embedding Projector从模型运行过程中保存的checkpoint文件中读取数据,默认使用主成分分析法(PCA)将高维数据投影到3D空间中,也可以通过设置设置选择T-SNE投影方法,这里做一个简单的展示。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from tensorboardX import SummaryWriter
""" ==================使用PROJECTOR对高维向量可视化====================
PROJECTOR的的原理是通过PCA,T-SNE等方法将高维向量投影到三维坐标系(降维度)。
Embedding Projector从模型运行过程中保存的checkpoint文件中读取数据,
默认使用主成分分析法(PCA)将高维数据投影到3D空间中,也可以通过设置设置选择T-SNE投影方法,
这里做一个简单的展示。
"""
BATCH_SIZE=256
EPOCHS=20
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = DataLoader(datasets.MNIST('./mnist', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('./mnist', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=BATCH_SIZE, shuffle=True)
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# 1,28x28
self.conv1=nn.Conv2d(1,10,5) # 10, 24x24
self.conv2=nn.Conv2d(10,20,3) # 128, 10x10
self.fc1 = nn.Linear(20*10*10,500)
self.fc2 = nn.Linear(500,10)
def forward(self,x):
in_size = x.size(0)
out = self.conv1(x) #24
out = F.relu(out)
out = F.max_pool2d(out, 2, 2) #12
out = self.conv2(out) #10
out = F.relu(out)
out = out.view(in_size,-1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out,dim=1)
return out
model = ConvNet().to(DEVICE)
optimizer = torch.optim.Adam(model.parameters())
def train(model, DEVICE,train_loader, optimizer, epoch):
n_iter=0
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data,target = data.to(DEVICE),target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if(batch_idx+1)%30 == 0:
n_iter=n_iter+1
print('Train Epoch: {} [{}/{} ({:.0f}%)]\t Loss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#主要增加了一下内容
out = torch.cat((output.data.cpu(), torch.ones(len(output), 1)), 1) # 因为是投影到3D的空间,所以我们只需要3个维度
with SummaryWriter(log_dir='./pytorch_tensorboardX_03_logs', comment='mnist') as writer:
#使用add_embedding方法进行可视化展示
writer.add_embedding(
out,
metadata=target.data,
label_img=data.data,
global_step=n_iter)
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # 损失相加
pred = output.max(1, keepdim=True)[1] # 找到概率最大的下标
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\n Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, EPOCHS + 1):
train(model, DEVICE, train_loader, optimizer, epoch)
test(model, DEVICE, test_loader)
# 保存模型
torch.save(model.state_dict(), './pytorch_tensorboardX_03.pth')
# Test set: Average loss: 0.0400, Accuracy: 9913/10000 (99%)如上代码直接点击运行。
可视化展示:
(AI_PyTorch_GPU) E:\pytorch_AI>tensorboard --logdir pytorch_tensorboardX_03_logs
TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:6006 (Press CTRL+C to quit)复制http://localhost:6006/到chrome打开:
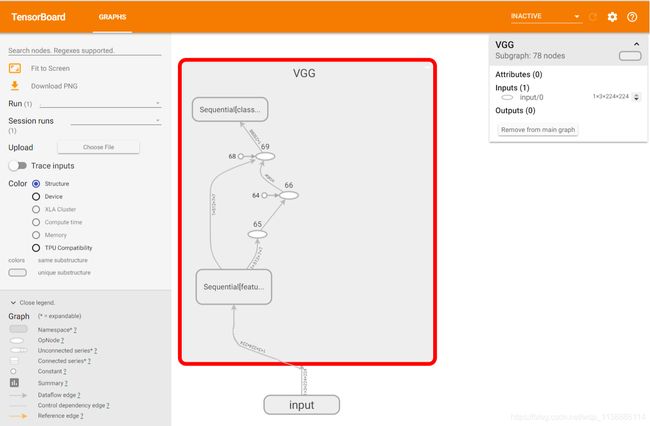
绘制网络结构
import torch
import numpy as np
from torchvision import models,transforms
from PIL import Image
from tensorboardX import SummaryWriter
vgg16 = models.vgg16() # 这里下载预训练好的模型
print(vgg16) # 打印一下这个模型
transform_2 = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
# convert RGB to BGR
# from
transforms.Lambda(lambda x: torch.index_select(x, 0, torch.LongTensor([2, 1, 0]))),
transforms.Lambda(lambda x: x*255),
transforms.Normalize(mean = [103.939, 116.779, 123.68],
std = [ 1, 1, 1 ]),
])
cat_img = Image.open('./Felis_silvestris_catus_lying_on_rice_straw.jpg')
vgg16_input=transform_2(cat_img)[np.newaxis]# 因为pytorch的是分批次进行的,所以我们这里建立一个批次为1的数据集
print(vgg16_input.shape)
# 开始前向传播,打印输出值
raw_score = vgg16(vgg16_input)
raw_score_numpy = raw_score.data.numpy()
print(raw_score_numpy.shape, np.argmax(raw_score_numpy.ravel()))
# 将结构图在tensorboard进行展示
with SummaryWriter(log_dir='./vgg16_logs', comment='vgg16') as writer:
writer.add_graph(vgg16, (vgg16_input,)) # 可视化
(AI_PyTorch_GPU) E:\pytorch_AI>tensorboard --logdir vgg16_logs
TensorBoard 1.12.2 at http://DESKTOP-JQI7IBN:6006 (Press CTRL+C to quit)