JAVA通过freemaker生成标准格式DOCX文件再转换为PDF格式
1. 生成docx模板和xml模板
生成docx模板
按照项目需要生成固定格式的docx格式的模板。
为方便测试做了个简单的例子,docx模板的内容如下图:

生成xml模板
从docx模板中取出word/document.xml,由于docx属于zip格式,可以用winrar打开,如图:
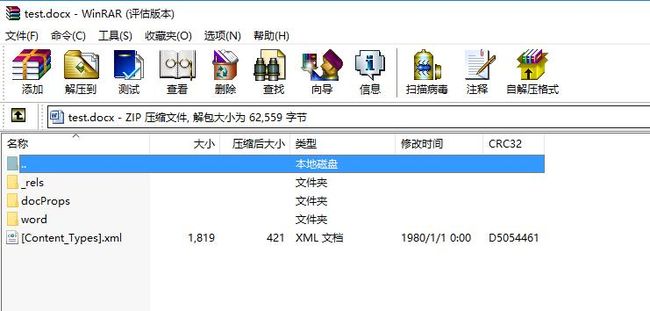
除word文件夹外其它文件为基本配置文件,取出word/document.xml(存放word文件的文本内容)如下图:
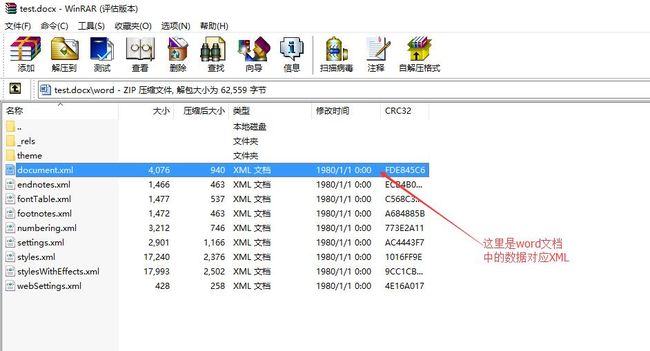
需要把document.xml解压出来,修改里面需要从数据库导出的数据用freemarker的指令代替,例如${test} 同时可以用遍历函数
替换完成后相当于生成了xml模板
生成的Xml模板:
[html] view plain copy
- 这是一个测试Word
- ${test}
- <#list students as s>
- ${s}
2. 利用freemarker填充数据并生成word文件
这里把数据库中的数据放到map中,把map和xml模板交给freemarker来生成(填充完数据)的xml具体实现方法如下:
[java] view plain copy
- package com.hannet.yigehui;
- import java.io.File;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.OutputStreamWriter;
- import java.io.Writer;
- import java.util.HashMap;
- import java.util.Map;
- import freemarker.template.Configuration;
- import freemarker.template.Template;
- import freemarker.template.TemplateException;
- public class XmlToExcel {
- private static XmlToExcel tplm = null;
- private Configuration cfg = null;
- private XmlToExcel() {
- cfg = new Configuration();
- try {
- //注册tmlplate的load路径
- cfg.setClassForTemplateLoading(this.getClass(), "/template/");
- } catch (Exception e) {
- }
- }
- private static Template getTemplate(String name) throws IOException {
- if(tplm == null) {
- tplm = new XmlToExcel();
- }
- return tplm.cfg.getTemplate(name);
- }
- /**
- *
- * @param templatefile 模板文件
- * @param param 需要填充的内容
- * @param out 填充完成输出的文件
- * @throws IOException
- * @throws TemplateException
- */
- public static void process(String templatefile, Map param ,Writer out) throws IOException, TemplateException{
- //获取模板
- Template template=XmlToExcel.getTemplate(templatefile);
- template.setOutputEncoding("UTF-8");
- //合并数据
- template.process(param, out);
- if(out!=null){
- out.close();
- }
- }
- }
利用freemarker生成数据
调用freemarker中的process方法(上图中的方法)来填充数据。
例(用1中生成的xml为模板填充数据):
//xml的模板路径 template/test.xml
String xmlTemplate = "test.xml";
//填充完数据的临时xml
String xmlTemp = "d:\\temp.xml";
Writer w = new FileWriter(new File(xmlTemp));
//1.需要动态传入的数据
Map
List
students.add("张三");
students.add("李四");
students.add("王二");
p.put("test", "测试一下是否成功");
p.put("students", students);
//2.把map中的数据动态由freemarker传给xml
XmlToExcel.process(xmlTemplate, p, w);
注:下文中会给出源码这里只是方便理解。
导出word文件
利用java的zipFile 和 ZipOutputStream 及zipFile.getInputStream() 来根据docx模板导出 (需要把word/document.xml文件替换成(填充完数据)的xml)具体操作流程如下:
[java] view plain copy
- package com.hannet.yigehui;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileNotFoundException;
- import java.io.FileOutputStream;
- import java.io.FileWriter;
- import java.io.IOException;
- import java.io.InputStream;
- import java.io.Writer;
- import java.net.URISyntaxException;
- import java.util.ArrayList;
- import java.util.Enumeration;
- import java.util.HashMap;
- import java.util.List;
- import java.util.Map;
- import java.util.zip.ZipEntry;
- import java.util.zip.ZipException;
- import java.util.zip.ZipFile;
- import java.util.zip.ZipOutputStream;
- import freemarker.template.TemplateException;
- /**
- * 其实docx属于zip的一种,这里只需要操作word/document.xml中的数据,其他的数据不用动
- * @author yigehui
- *
- */
- public class XmlToDocx {
- /**
- *
- * @param documentFile 动态生成数据的docunment.xml文件
- * @param docxTemplate docx的模板
- * @param toFileName 需要导出的文件路径
- * @throws ZipException
- * @throws IOException
- */
- public void outDocx(File documentFile,String docxTemplate,String toFilePath) throws ZipException, IOException {
- try {
- String fileName = XmlToDocx.class.getClassLoader().getResource("").toURI().getPath()+docxTemplate;
- File docxFile = new File(fileName);
- ZipFile zipFile = new ZipFile(docxFile);
- Enumeration zipEntrys = zipFile.entries();
- ZipOutputStream zipout = new ZipOutputStream(new FileOutputStream(toFilePath));
- int len=-1;
- byte[] buffer=new byte[1024];
- while(zipEntrys.hasMoreElements()) {
- ZipEntry next = zipEntrys.nextElement();
- InputStream is = zipFile.getInputStream(next);
- //把输入流的文件传到输出流中 如果是word/document.xml由我们输入
- zipout.putNextEntry(new ZipEntry(next.toString()));
- if("word/document.xml".equals(next.toString())){
- //InputStream in = new FileInputStream(new File(XmlToDocx.class.getClassLoader().getResource("").toURI().getPath()+"template/test.xml"));
- InputStream in = new FileInputStream(documentFile);
- while((len = in.read(buffer))!=-1){
- zipout.write(buffer,0,len);
- }
- in.close();
- }else {
- while((len = is.read(buffer))!=-1){
- zipout.write(buffer,0,len);
- }
- is.close();
- }
- }
- zipout.close();
- } catch (URISyntaxException e) {
- e.printStackTrace();
- }catch (FileNotFoundException e) {
- e.printStackTrace();
- }
- }
- }
这里输出的文件即为完整的docx格式的word文件
//经过本人测试,也可直接将输出文件取.doc后缀,也可以打开与转换,且解决低版本jodconverter无法转换DOCX文件的问题
测试调用的代码:
[java] view plain copy
- public static void main(String[] args) throws IOException, TemplateException {
- //xml的模板路径*/*
- String xmlTemplate = "test.xml";
- //设置docx的模板路径 和文件名
- String docxTemplate = "template/test.docx";
- String toFilePath = "d:\\test.docx";
- //填充完数据的临时xml
- String xmlTemp = "d:\\temp.xml";
- Writer w = new FileWriter(new File(xmlTemp));
- //1.需要动态传入的数据
- Map
- List
students = new ArrayList (); - students.add("张三");
- students.add("李四");
- students.add("王二");
- p.put("test", "测试一下是否成功");
- p.put("students", students);
- //2.把map中的数据动态由freemarker传给xml
- XmlToExcel.process(xmlTemplate, p, w);
- //3.把填充完成的xml写入到docx中
- XmlToDocx xtd = new XmlToDocx();
- xtd.outDocx(new File(xmlTemp), docxTemplate, toFilePath);
转换成PDF
1)基于openoffice(跨平台、需安装openoffice、复杂格式有错位)
原理:
通过第三方工具openoffice,将word、excel、ppt、txt等文件转换为pdf文件
先安装openoffice软件(Windows或Linux有提供软件)
使用JODConverter的Java的OpenDocument 文件转换器API操作Office系列文件转换为PDF文件
优点:
转换效果比较好。是比较主流的做法
缺点:
服务器需要安装openoffice,比较负重
具体实现:
1.下载安装软件
1)Openoffice:Apache下的一个开放免费的文字处理软件
下载地址:http://www.openoffice.org/zh-cn/download/
2)JODConverter一个Java的OpenDocument 文件转换器,只用到它的jar包
下载地址:https://sourceforge.net/projects/jodconverter/files/JODConverter/
2.启动服务:
打开dos窗口,进入openoffice安装盘符,输入以下代码来启动服务:
soffice -headless -accept="socket,host=127.0.0.1,port=8100;urp;" -nofirststartwizard
3.Java实现操作转化:
Pom.xml依赖
转换工具:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ConnectException;
import java.text.SimpleDateFormat;
import java.util.Date;
import com.artofsolving.jodconverter.DocumentConverter;
import com.artofsolving.jodconverter.openoffice.connection.OpenOfficeConnection;
import com.artofsolving.jodconverter.openoffice.connection.SocketOpenOfficeConnection;
import com.artofsolving.jodconverter.openoffice.converter.OpenOfficeDocumentConverter;
/**
* 利用jodconverter(基于OpenOffice服务)将文件(*.doc、*.docx、*.xls、*.ppt)转化为html格式或者pdf格式,
* 使用前请检查OpenOffice服务是否已经开启, OpenOffice进程名称:soffice.exe | soffice.bin
*/
public class Doc2HtmlUtil {
private static Doc2HtmlUtil doc2HtmlUtil;
/** * 获取Doc2HtmlUtil实例 */
public static synchronized Doc2HtmlUtil getDoc2HtmlUtilInstance() {
if (doc2HtmlUtil == null) {
doc2HtmlUtil = new Doc2HtmlUtil();
}
return doc2HtmlUtil;
}
/*** 转换文件成pdf */
public String file2pdf(InputStream fromFileInputStream, String toFilePath,String type) throws IOException {
Date date = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss");
String timesuffix = sdf.format(date);
String docFileName = null;
String htmFileName = null;
if(".doc".equals(type)){
docFileName = "doc_" + timesuffix + ".doc";
htmFileName = "doc_" + timesuffix + ".pdf";
}else if(".docx".equals(type)){
docFileName = "docx_" + timesuffix + ".docx";
htmFileName = "docx_" + timesuffix + ".pdf";
}else if(".xls".equals(type)){
docFileName = "xls_" + timesuffix + ".xls";
htmFileName = "xls_" + timesuffix + ".pdf";
}else if(".ppt".equals(type)){
docFileName = "ppt_" + timesuffix + ".ppt";
htmFileName = "ppt_" + timesuffix + ".pdf";
}else{
return null;
}
File htmlOutputFile = new File(toFilePath + File.separatorChar + htmFileName);
File docInputFile = new File(toFilePath + File.separatorChar + docFileName);
if (htmlOutputFile.exists())
htmlOutputFile.delete();
htmlOutputFile.createNewFile();
if (docInputFile.exists())
docInputFile.delete();
docInputFile.createNewFile();
/*** 由fromFileInputStream构建输入文件 */
try {
OutputStream os = new FileOutputStream(docInputFile);
int bytesRead = 0;
byte[] buffer = new byte[1024 * 8];
while ((bytesRead = fromFileInputStream.read(buffer)) != -1) {
os.write(buffer, 0, bytesRead);
}
os.close();
fromFileInputStream.close();
} catch (IOException e) {
}
// 连接服务
OpenOfficeConnection connection = new SocketOpenOfficeConnection(8100);
try {
connection.connect();
} catch (ConnectException e) {
System.err.println("文件转换出错,请检查OpenOffice服务是否启动。");
}
// convert 转换
DocumentConverter converter = new OpenOfficeDocumentConverter(connection);
converter.convert(docInputFile, htmlOutputFile);
connection.disconnect();
// 转换完之后删除word文件
docInputFile.delete();
return htmFileName;
}
public static void main(String[] args) throws IOException {
Doc2HtmlUtil coc2HtmlUtil = getDoc2HtmlUtilInstance ();
File file = null;
FileInputStream fileInputStream = null;
file = new File("C:/Users/MACHENIKE/Desktop/xxx.doc");
fileInputStream = new FileInputStream(file);
coc2HtmlUtil.file2pdf(fileInputStream, "E:/360","doc");
}
}
简易实现:
public void createPdf(String docFileName) throws IOException{
String path = this.getSession().getServletContext().getRealPath("/")+"attachment/";
File inputFile = new File(path+"/doc/"+ docFileName + ".doc");
File outputFile = new File(path+"/pdf/"+docFileName + ".pdf");
// connect to an OpenOffice.org instance running on port 8100
OpenOfficeConnection connection = new SocketOpenOfficeConnection(8100);
connection.connect();
// convert
DocumentConverter converter = new OpenOfficeDocumentConverter(connection);
converter.convert(inputFile, outputFile);
// close the connection
connection.disconnect();
本文由各个大神的博客总结,加上自身测试而成,可解决Freemaker生成的文档手机端不能打开,与转换成的PDF文档是XML格式问题。