【关系抽取】Tensorflow实现基于Attention的PCNN以及ResCNN等(1)
本科毕业设计就是做关系抽取,准备采用远程监督数据集NYT数据集,使用Tensorflow实现几篇经典的论文,以及做一些改进和创新,本系列博客记录毕设全过程。
经典PCNN论文:http://www.aclweb.org/anthology/D15-1203
ResCNN论文:https://arxiv.org/pdf/1707.08866.pdf
注意本ResCNN模型没有结合Attention机制,因此我会补充上去,作为创新点之一。
另外一个创新点在于,我将尝试引入图像分类的Inception结构,并将其与ResCNN、Attention机制结合,探索最优的编码模型结构。
这是我毕业论文的出发点:
基于卷积神经网络的模型和基于循环神经网络的模型在英文实体关系抽取任务上极具竞争力。卷积神经网络和循环神经网络的融合方法也已经出现。注意力机制也被频繁地运用在网络结构中,实验证明注意力机制可以有效地提高关系抽取的性能。值得一提的是,一个对句子有效的编码器对于关系抽取任务是至关重要的,编码器性能越强,往往相关的任务表现越好。然而,近几年的研究多集中在浅层较小的CNN,缺乏对深度多层、多尺度的CNN在关系抽取任务上的表现研究。本论文旨在探究深层、多尺度CNN在关系抽取任务上的性能表现。需要注意的是,网络模型越深、卷积核尺度越多、注意力层越多,会导致参数数量越多,与之带来了很多挑战,比如训练难度加大、容易过拟合等等。因此,如何平衡网络模型的深度与宽度以及注意力机制的使用,如何在加深网络深度和宽度的同时尽可能减少参数规模以利于训练,这些都将是本文研究的重点。本文将通过引入残差连接结构、Inception结构并与注意力机制相结合,在公开的数据集上进行性能评测并归纳实验结果。
总之,本文研究了基于注意力机制的深度多层、多尺度的CNN在关系抽取任务上的表现,并探究一些有效减少参数规模和利于训练的方法,最终在现有的基于CNN的编码器的基础上,归纳出一种表达能力更强的编码器,以改进现有的关系抽取任务表现结果。
先进行Project架构:
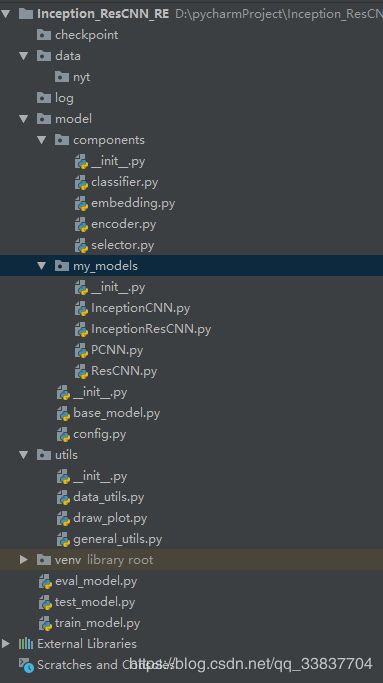
checkpoint: 模型训练保存的目录
data:存放数据的目录
log:存放模型训练日志的目录
model:模型
model-components:模型的基本构件
model-my_models:通过组合使用基本构件,形成自己的Model
base_model.py:抽象的Model的父类,所有的my_model都将继承自此类
config.py:参数的集合类
utils:工具类,data_utils专门负责提供数据处理
eval_model,test_model,train_model分别是验证,测试、训练model
本着面向对象编程出发,将Model抽象成对象,内部实现eval,test和train方法,eval_model,test_model,train_model只需要给Model传递消息并提供所需要的数据。其中model可以自由组合使用各种不同的components来完成独特的Model,config集中了需要调的参数,base_model里面主要写一些各种模型都会用到的函数,比如session的操作、模型的保存、tensorboard的使用等等。
base_model主要接口:
import os
import tensorflow as tf
class BaseModel(object):
def __init__(self):
pass
def initialize_session(self):
"""Defines self.sess and initialize the variables"""
pass
def restore_session(self,dir_model):
"""Reload weights into session"""
pass
def save_session(self,model_name):
"""Saves session"""
pass
def close_session(self):
"""Closes the session"""
pass
def add_train_op(self):
"""Defines self.train_op that performs an update on a batch"""
pass
def add_summary(self):
"""Defines variables for Tensorboard"""
pass
def train(self):
"""Performs training"""
pass
def evaluate(self, test):
"""Evaluates model on test set
Args:
test:instance of class Dataset
"""
pass
我们先从网络的架构一点点完成,
最简单的PCNN结构图:

第一要完成的就是embedding, 词向量,不懂得可以看别的资料,本系列博客对Nlp科普不多。。。
import tensorflow as tf
import numpy as np
from model.config import Config
class Embedding(object):
def __init__(self, word_vec_mat, word, pos1, pos2):
"""
A function to initial the class.
:param word_vec_mat: pre_trained word embedding matrix, shape=(vocab_size, dim_word)
:param word: the index of the word
:param pos1:
:param pos2:
"""
self.word_embedding = tf.get_variable("word_embedding", initializer=word_vec_mat, dtype=tf.float32)
if Config.add_unk_and_blank:
self.word_embedding = tf.concat([self.word_embedding,
tf.get_variable('unk_word_embedding', [1, Config.dim_word],
dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer()),
tf.constant(np.zeros((1, Config.dim_word), dtype=np.float32))], 0)
self.word = word
self.pos1 = pos1
self.pos2 = pos2
def get_word_embedding(self):
with tf.variable_scope("word_embedding", reuse=tf.AUTO_REUSE):
x = tf.nn.embedding_lookup(self.word_embedding, self.word)
return x
def get_pos_embedding(self):
with tf.variable_scope("pos_embedding", reuse=tf.AUTO_REUSE):
pos_tol = Config.max_len * 2
pos1_embedding = tf.get_variable("pos1_embedding", [pos_tol, Config.dim_pos], dtype=tf.float32, \
initializer=tf.contrib.layers.xavier_initializer())
pos2_embedding = tf.get_variable("pos2_embedding", [pos_tol, Config.dim_pos], dtype=tf.float32, \
initializer=tf.contrib.layers.xavier_initializer())
input_pos1 = tf.nn.embedding_lookup(pos1_embedding, self.pos1)
input_pos2 = tf.nn.embedding_lookup(pos2_embedding, self.pos2)
x = tf.concat([input_pos1, input_pos2], -1)
return x
def get_word_position_embedding(self):
w_embedding = self.get_word_embedding()
p_embedding = self.get_pos_embedding()
return tf.concat([w_embedding, p_embedding], -1)
embedding的核心函数:https://www.cnblogs.com/gaofighting/p/9625868.html
其中已经用到的一些参数:
import os
import numpy as np
class Config():
def __init__(self):
pass
# embeddings
dim_word = 50
dim_pos = 5
dim = dim_word + 2*dim_pos
add_unk_and_blank = True
max_len = 120
这两天就写了这么多,明天有点事,暂时搁浅两天。