《Kubernetes in action》集群服务(一)
Kubernetes 集群服务
- 《Kubernetes in action》集群服务(一)
- 通过kubectl expose创建服务
- 服务发现
- 连接集群外部的服务
- 将服务暴露给外部客户端
- 使用 NodePort 类型的服务
- 使用JSONPath获取所有节点的IP
- 了解外部连接的特性
- 通过Ingress暴露服务
《Kubernetes in action》集群服务(一)
Kubemetes 服务是一种为一组功能相同的 pod 提供单一不变的接入点的资源。当服务存在时,它的 IP 地址和端口不会改变。 客户端通过 IP 地址和端口号建立连接,这些连接会被路由到提供该服务的任意一个 pod 上。 通过这种方式, 客户端不需要知道每个单独的提供服务的 pod 的地址, 这样这些 pod 就可以在集群中随时被创建或移除。
结合实例解释服务
- 外部客户端无须关心服务器数量而连接到前端 pod 上。
- 前端的 pod需要连接后端的数据库。 由于数据库运行在 pod 中, 它可能会在集群中移来移去, 导致 IP 地址变化。 当后台数据库被移动时, 无须对前端pod 重新配置。
通过为前端 pod 创建服务,并且将其配置成可以在集群外部访问, 可以暴露一个单一不变的 IP 地址让外部的客户端连接 pod。 同理, 可以为后台数据库 pod 创建服务, 并为其分配一个固定的 IP 地址。 尽管 pod 的 IP 地址会改变, 但是服务的 IP地址固定不变。 另外, 通过创建服务, 能够让前端的 pod 通过环境变量或 DNS 以及服务名来访问后端服务。

通过kubectl expose创建服务
pod
kubectl run kubia --image=luksa/kubia --port=8080
pod/kubia created
Expose
kubectl create deploy kubia --image=luksa/kubia --replicas=3
deploy/kubia create
kubectl get pod
kubia-6c68d68756-44kvt 1/1 Running 0 5m31s
kubia-6c68d68756-pp6pl 0/1 ContainerCreating 0 4s
kubia-6c68d68756-r8kqr 1/1 Running 0 4s
kubectl get deploy
kubia 3/3 3 3 10m
kubectl expose deploy kubia --type=NodePort --name kubia-http
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubia-http NodePort 10.97.10.52 80:32767/TCP 5m38s
Service
kubia-svc.yaml
```
apiVersion: v1
kind: Service
metadata:
name: kubia-svc
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
```
Result
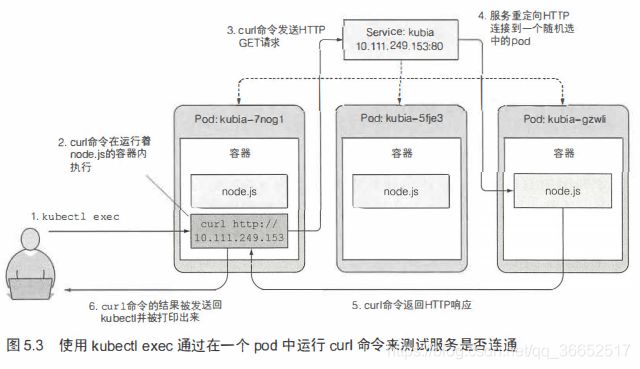
在运行的容器中远程执行命令
kubectl exec kubia-6c68d68756-44kvt -- curl -s http://10.96.232.104
You've hit kubia-6c68d68756-44kvt
配置服务上的会话亲和性
如果希望特定客户端产生的所有请求每次都指向同 一个 pod, 可以设置服务的 sessionAffinity 属性为 ClentIP (而不是 None,None 是默认值)
apiVersion: v1
kind: Service
spec:
sessionAffinity: ClientIP
Kubernetes 仅仅支持两种形式的会话亲和性服务: None 和 Client工P。你或许惊讶竞然不支持基于 cookie 的会话亲和性的选项,但是你要了解 Kubernetes 服务不是在 HTTP 层面上工作。服务处理 TCP 和 UDP 包,并不关心其中的载荷内容。因为 cookie 是 HTTP 协议中的一部分,服务并不知道它们,这就解释了为什么会话 亲和性不能基于 cookie 。
同—个服务暴露多个端口
cat many-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: many-port
labels:
app: kubia
spec:
containers:
- name: kubia
image: luksa/kubia
ports:
- name: http
containerPort: 8080
- name: https
containerPort: 8443
cat many-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia
spec:
ports:
- name: http
port: 80
targetPort: 8080
- name: https
port: 443
targetPort: 8443
selector:
app: kubia
服务发现
通过创建服务,现在就可以通过一个单一稳定的 IP 地址访 pod 。在服务整个生命周期内这个地址保持不变
通过环境变量发现服务
kubectl exec many-pod env
MYAPP_SERVICE_HOST=10.97.156.36
MYAPP_SERVICE_PORT=80
通过 DNS 发现服务(待)
在集群 中的其他 pod 都被配置成使用其作为 dns ( Kubemetes 通过修改每 容器的/ etc/reso conf 实现)。
kubectl exec many-port -it – /bin/sh
cat /etc/resolv.conf
nameserver 10.96.0.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
无法 ping 通服务 IP 的原因
curl 个服务是工作的,但是却 ping 不通。这是因为服务的集群 IP是一个虚拟 IP ,并且只有在与服务端口结和时才有意义。
连接集群外部的服务
在进入如何做到这一点之前,先阐述一下服务。服务并不是和 pod 直接相连的。相反,有一种资源介于两者之间-—-它就是 Endpoint 资源。
kds svc kubia-svc
TargetPort: 8080/TCP
Endpoints: 10.244.0.108:8080,10.244.0.109:8080,10.244.0.110:8080 + 1 more…
Session Affinity: None
尽管在 spec 服务中定义了 pod选择器,但在重定向传入连接时不会直接使用它。相反,选择器用于构建 IP 和端口列表,然后存储在 Endpoint 资源中。当客户端连接到服务时,服务代理选择这些 IP 和端口对中的一个,并将传入连接重定向到在该位置监听的服务器。
手动配置服务的 endpoint
服务的 endpoint 与服务解耦后,可以分别手动配置和如果创建了不包含 pod选择器的服务,Kubemetes 将不会创建 Endpoint 资源(毕竟,缺少选择器,将不会知道服务中包含哪些 pod)。这样就需要创建 Endpoint 资源来指定该服务的 endpoint 列表。
kubia-endp.yaml
apiVersion: v1
kind: Endpoints
metadata:
name: external-service
subsets:
- addresses:
- ip: 11.11.11.11
- ip: 22.22.22.22
ports:
- port: 80 #endpoint的目标端口
Endpoint对象需要与服务具有相同的名称,并包含该服务的目标IP地址和端口列表。服务和Endpoint资源都发布到服务器后,这样服务就可以像具有pod选择器那样的服务正常使用。在服务创建后创建的容器将包含 服务的环境变量,并且与其IP:port对的所有连接都将 在服务端点之间进行负载均衡。

为外部服务创建别名
cat externalname.yaml
apiVersion: v1
kind: Service
metadata:
name: external-name-service
spec:
type: ExternalName
externalName: someapi.app.com
ports:
- port: 80
kubia-ex.yaml
apiVersion: v1
kind: Service
metadata:
name: external-service
spec:
ports:
- port: 80
curl someapi.app.com
301 Moved Permanently
301 Moved Permanently
nginx/1.2.7
ExternalName服务仅在DNS级别实施一为服务创建了简单的CNAME
将服务暴露给外部客户端
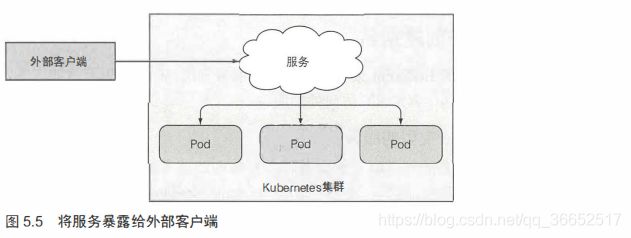
有几种方式可以在外部访问服务:
- 将服务的类型设置成NodePort-每个集群节点都会在节点上打 开 一个端口, 对于NodePort服务, 每个集群节点在节点本身(因此得名NodePort)上打开一个端口,并将在该端口上接收到的流量重定向到基础服务。该服务仅在内部集群 IP 和端口上才可访间, 但也可通过所有节点上的专用端口访问。
- 将服务的类型设置成LoadBalance, NodePort类型的一 种扩展一—这使得服务可以通过一个专用的负载均衡器来访问, 这是由Kubernetes中正在运行的云基础设施提供的。 负载均衡器将流量重定向到跨所有节点的节点端口。客户端通过负载均衡器的 IP 连接到服务。
- 创建一 个Ingress资源, 这是一 个完全不同的机制, 通过一 个IP地址公开多个服务——它运行在 HTTP 层(网络协议第7 层)上
使用 NodePort 类型的服务
cat nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-nodeport
spec:
type: NodePort
ports:
- port: 80
targetPort: 8080
nodePort: 30123
selector:
app: kubia
[root@kmaster wangyang]# kgp
kubia-6c68d68756-44kvt 1/1 Running 0 27h
kubia-6c68d68756-pp6pl 1/1 Running 0 27h
kubia-6c68d68756-r8kqr 1/1 Running 0 27h
[root@kmaster wangyang]# curl 10.107.34.4:80
You've hit many-port
[root@kmaster wangyang]# curl 10.107.34.4:80
You've hit kubia-6c68d68756-r8kqr
[root@kmaster wangyang]# curl 10.107.34.4:80
You've hit kubia-6c68d68756-44kvt
[root@kmaster wangyang]# curl kmaster:30123
You've hit kubia-6c68d68756-r8kqr

使用JSONPath获取所有节点的IP
kubectl get nodes -o jsonpath='{.items[*].status.addresses[*].address}'
192.168.145.128 kmaster 192.168.145.129 kubernode1 192.168.145.130 kubernode2
使用 LoadBalancer类型的服务
创建
cat loadbalancer.yaml
apiVersion: v1
kind: Service
metadata:
name: kubia-loadbalancer
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 8080
selector:
app: kubia
查看
[root@kmaster wangyang]# kg svc -w
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
external-name-service ExternalName someapi.app.com 80/TCP 4h57m
external-service ClusterIP 10.105.57.192 80/TCP 5h9m
kubernetes ClusterIP 10.96.0.1 443/TCP 32h
kubia ClusterIP 10.109.52.215 80/TCP,443/TCP 6h10m
kubia-http NodePort 10.97.10.52 80:32767/TCP 27h
kubia-loadbalancer LoadBalancer 10.104.78.31 80:32462/TCP 99s
测试
[root@kmaster wangyang]# curl 10.104.78.31:80
You've hit kubia-6c68d68756-r8kqr
[root@kmaster wangyang]# curl 10.104.78.31:80

了解外部连接的特性
了解并防止不必要的网络跳数
-
当外部客户端通过节点端口连接到服务时 (这也包括先通过负载均衡器时的情况), 随机选择的pod并不一定在接收连接的同 一节点上运行。 可能需要额外的网络跳转才能到达pod, 但这种行为并不符合期望。
-
可以通过将服务配置为仅将外部通信重定向到接收连接的节点上运行的pod来阻止此额外跳数。
spec: externalTrafficPolicy: Local -
如果服务定义包含此设置, 并且通过服务的节点端口打开外部连接, 则服务代理将选择本地运行的pod。 如果没有本地pod存在, 则连接将挂起(它不会像不使用注解那样, 将其转发到随机的全局pod)。 因此, 需要确保负载平衡器将连接转发给至少具有一个pod的节点。
-
假设节点A运行一个pod, 节点B运行另外两个pod。 如果负载平衡器在两个节点间均匀分布连接, 则节点A上的pod将接收所有连接的50%, 但节点B上的两个pod每个只能接收25%

记住客户端IP是不记录的 -
通常, 当集群内的客户端连接到服务时, 支持服务的pod可以获取客户端的IP地址 。 但是, 当通过节点端口接收到连接时, 由于对数据包执行了源网络地址转换(SNAT), 因此数据包的源IP将发生更改。
-
后端的pod无法看到实际的客户端IP, 这对于某些需要了解客户端IP的应用程序来说可能是个问题。 例如, 对千Web服务器, 这意味着访问日志无法显示浏览
器的IP。 -
上一节中描述的local外部流量策略会影响客户端IP的保留, 因为在接收连接的节点和托管目标pod的节点之间没有额外的跳跃(不执行SNAT)。
通过Ingress暴露服务
为什么需要 Ingress?
- 一个重要的原因是每个 LoadBalancer 服务都需要自己的负载均衡器, 以及独有的公有 IP 地址, 而 Ingress 只需要一个公网 IP 就能为许多服务提供访问。 当客户端向 Ingress 发送 HTTP 请求时, Ingress 会根据请求的主机名和路径决定请求转发到的服务
- ingress 在网络栈 (HTTP) 的应用层操作, 并且可以提供一些服务不能实现的功能, 诸如基于 cookie 的会话亲和性 (session affinity) 等功能。

cat ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
rules:
- host: kubia-example.com
http:
paths:
- path: /
backend:
serviceName: kubia-nodeport
servicePort: 80
了解 Ingress 的工作原理
客户端首先对 kubi example.com 执行 DNS 找, DNS 务器(或本地操作系统)返回了igress 控制器的 IP 。客户端然后 Ingress 控制器发送 HTTP 请求,并在 Host中指 kubia example.com 。控制器从该头部确定客户端尝试访问哪个服务,通过与该服务关联endpoint对象查看 pod IP, 并将客户端的请求转发给其中一个pod。

不同的服务映射到相同主机的不同路径
ingress-diffpath.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
rules:
- host: kubia-example.com
http:
paths:
- path: /kubia
backend:
serviceName: kubia-nodeport
servicePort: 80
- path: /foo
backend:
serviceName: bar
servicePort: 80
不同的服务映射到不同主机的路径
ingress-diffhost.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
rules:
- host: kubia-example.com
http:
paths:
- path: /kubia
backend:
serviceName: kubia-nodeport
servicePort: 80
- host: bar.example.com
http:
paths:
- path: /foo
backend:
serviceName: bar
servicePort: 80
为Ingress 创建 TLS 认证
客户端创建到 ngress 控制器的 TLS 连接时,控制器将终止 TLS 连接。客户端和控制器之间的通信是加密的,而控制器和后端 pod 之间的通信不是 。运行在pod 上的应用程序不需要支持 TLS
openssl genrsa -out tls.key 2048
openssl req -new -x509 -key tls.key -out tls.cert -days 360 -subject
[root@kmaster wangyang]# ls
externalname.yaml ingress-diffpath.yaml kubia-ex.yaml loadbalancer.yaml nodeport.yaml
ex.yaml ingres.yaml kubia-svc.yaml many-pod.yaml tls.cert
ingress-diffhost.yaml kubia-endp.yaml
cat ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kubia
spec:
tls:
- hosts: kubia.example.com
secertName: tls-secret
rules:
- host: kubia-example.com
http:
paths:
- path: /kubia
backend:
serviceName: kubia-nodeport
servicePort: 80
[root@kmaster wangyang]# kubectl apply -f ingres.yaml
ingress.extensions/kubia configured
[root@kmaster wangyang]# curl -k -v https://kubia.example.com/kubia