汽车之家 css自定义字体反爬解析
本文主要是通过哦爬取汽车之家论坛一些用户热门精华帖子,介绍利用前端页面自定义字体的方式来实现反爬的技术手段,来实践破解它。
自定义字体:@font-face是CSS3中的一个模块,主要是实现将自定义的Web字体嵌入到指定网页中去。
使用了其中一个网址来进行分析:https://club.autohome.com.cn/bbs/thread/d1751c7bd0539de0/79229668-1.html
目录
一、发现问题
二、找出反爬规律
三、代码实现破解
一、发现问题
- 问题:页面显示很正常的文字,在源码中某些文字却是一段span标签包裹的不可见文本,网页源代码里面是一串字符编码,如下图


二、找出反爬规律
1.该页面使用了自定义字体:myfont
2.查看网页源代码,很快就找到了@font-face定义方法。每次访问,字体文件访问地址都会随机变化
访问其中.ttf文件的url,可以将其下载到本地,例:http://k3.autoimg.cn/g1/M08/D2/96/wKgHGFsUz2uAJY3tAABj-Ae-bJ473..ttf
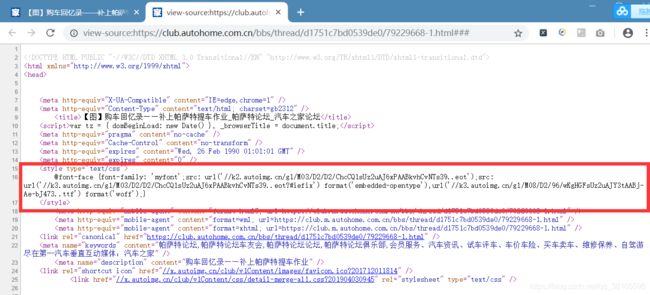
3.字体解析
我们使用一个专用工具FontCreator查看,下载地址:http://www.onlinedown.net/soft/88758.htm

由此可发现,每个文字对应一个字符编码,我们只需要获取它们的对应关系就可以还原网页展示的那些数据了。
我们发现,每次访问论坛页面,下载的ttf文件中的文字都是不变的,但是字符编码是变化的,所以,我们需要根据每次访问动态解析字体文件
4.找到专门解析font的python包:fontTools
# 解析字体库font文件
font = TTFont('autohome.ttf')
print(font)
uniList = font['cmap'].tables[0].ttFont.getGlyphOrder()
print(uniList)运行结果:![]()
三、代码实现破解
# -*- coding:utf-8 -*-
import requests
from lxml import html
from lxml import etree
import re
from fontTools.ttLib import TTFont
# 抓取autohome评论
class AutoSpider:
# 页面初始化
def __init__(self):
self.headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
# "Cookie": "RDTaskClose_0=1555299062792; fvlid=1554860242161X44XwAM6iq; sessionip=101.254.141.188; sessionid=ED31FBA8-2281-4D3F-B3CE-40055C1A0C3D%7C%7C2019-04-10+09%3A37%3A15.170%7C%7Cwww.cnblogs.com; autoid=7d90ffe46eb2ed803070689d1d7b367c; area=379999; ahpau=1; csrfToken=dTPiFh5NroBla6Kf7fC3pEkC; cookieCityId=110100; sessionuid=ED31FBA8-2281-4D3F-B3CE-40055C1A0C3D%7C%7C2019-04-10+09%3A37%3A15.170%7C%7Cwww.cnblogs.com; Hm_lvt_9924a05a5a75caf05dbbfb51af638b07=1555040530; Hm_lpvt_9924a05a5a75caf05dbbfb51af638b07=1555040530; ahpvno=4; ref=www.baidu.com%7C0%7C0%7Cwww.cnblogs.com%7C2019-04-15+11%3A31%3A02.414%7C2019-04-12+11%3A40%3A26.229; ahrlid=1555299061852eKVy3iSadl-1555306246295",
# "Host": "club.autohome.com.cn",
"Referer": "https://www.autohome.com.cn/beijing/",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36",
}
# 获取评论
def getNote(self):
url = "https://club.autohome.com.cn/bbs/thread/d1751c7bd0539de0/79229668-1.html###"
host = {"host": "club.autohome.com.cn",
"cookie": "RDTaskClose_0=1555299062792; fvlid=1554860242161X44XwAM6iq; sessionip=101.254.141.188; sessionid=ED31FBA8-2281-4D3F-B3CE-40055C1A0C3D%7C%7C2019-04-10+09%3A37%3A15.170%7C%7Cwww.cnblogs.com; autoid=7d90ffe46eb2ed803070689d1d7b367c; area=379999; ahpau=1; csrfToken=dTPiFh5NroBla6Kf7fC3pEkC; cookieCityId=110100; sessionuid=ED31FBA8-2281-4D3F-B3CE-40055C1A0C3D%7C%7C2019-04-10+09%3A37%3A15.170%7C%7Cwww.cnblogs.com; Hm_lvt_9924a05a5a75caf05dbbfb51af638b07=1555040530; Hm_lpvt_9924a05a5a75caf05dbbfb51af638b07=1555040530; papopclub=FF3E120EDCD7855D53DB092DCA188C31; pbcpopclub=3738e3d3-5941-4019-a37c-0905bd1fda12; sessionvid=6C6683F9-E968-4873-92CB-AF3517665337; pepopclub=2107880B94A03DF91DA626D9DE3DD896; ahpvno=6; ahrlid=1555312530362iQUHblNyyj-1555312532305; ref=www.baidu.com%7C0%7C0%7Cwww.cnblogs.com%7C2019-04-15+15%3A15%3A35.083%7C2019-04-12+11%3A40%3A26.229"}
# print(type(self.headers.items()))
# print(type(host.items()))
headers = dict(self.headers, **host)
# 获取页面内容
r = requests.get(url, headers=headers)
response = html.fromstring(r.text)
# 匹配ttf font
cmp = re.compile(",url\('(//.*.ttf)'\)\sformat\('woff'\)")
rst = cmp.findall(r.text)
ttf = requests.get("http:" + rst[0], stream=True)
with open("autohome.ttf", "wb") as pdf:
for chunk in ttf.iter_content(chunk_size=1024):
if chunk:
pdf.write(chunk)
font = TTFont('autohome.ttf')
uniList = font['cmap'].tables[0].ttFont.getGlyphOrder()
print(uniList)
# print(len(uniList))
# 给字体编码转成utf-8的格式
utf8List = [eval("'\\u" + uni[3:] + "'") for uni in uniList[1:]]
wordList = ["近", "更", "下", "低", "和", "了", "是", "八", "很", "小", "好", "五", "少", "三",
"矮", "的", "二", "着", "地", "高", "上", "短", "呢", "一", "六", "多", "左", "大",
"长", "七", "十", "坏", "不", "四", "右", "得", "远", "九"]
# 获取发帖内容
# note = response.xpath("//div[@class='conttxt']//div[@class='w740']//text()")
# print(note)
print(utf8List)
# print(len(utf8List))
'''fromstring'''
note = response.cssselect(".tz-paragraph")[0].text_content()
print(note)
print("-----------------------after-----------------------")
for i in range(len(utf8List)):
# print(type(utf8List[i]))
# print(type(wordList[i]))
note = note.replace(utf8List[i], wordList[i])
print(note)
if __name__ == '__main__':
autohome = AutoSpider()
autohome.getNote()