强化学习笔记(1)——一些基本概念
本文目的
本文是个人对David Silver老师的强化学习课程的总结,主要目的还是为了理清强化学习的一些概念及方法,也可以参考其他大佬写的关于该课程的笔记。
Reinforcement learning, like many topics whose names end with “ing,” such as machine
learning and mountaineering, is simultaneously a problem, a class of solution methods
that work well on the problem, and the field that studies this problem and its solution
methods.
以上段落引自Richard S. Sutton的《Reinforcement Learning: An Introduction》。本文针对什么是强化学习问题、强化学习方法有哪些这两个问题对第一节课的课程内容进行整理。
1. 使用强化学习方法的直观示例
- 直升机/无人机特技飞行Fly Stunt
- 围棋比赛
- 管理投资Manage Investment Portfolio
- 人型机器人行走
2. 强化学习问题是什么?
(这里做一个小小的更新)
这里我按照我自己的理解给出一个比较直观的描述:强化学习问题就是让智能体在与环境的交互过程中不断学习一个序列化的动作(“交互”一词是比较宽泛的,我认为交互应该是智能体获得并利用环境的信息),最终学到一个能够最大化智能体的长期收益的动作序列。(至于强化学习的方法就是用什么样的方法去解决以上问题)
我觉得也可以把“强化学习”分成两个词来理解,第一个是Reinforcement,到底reinforce了什么?我目前理解的就是最大化长期收益(也就是后文的基本假设),第二个词是Learning,具体应该是who learns what,这个“who”我觉得就是智能体,"what”就是动作序列。
2.1 强化学习问题的基本特点
- 与其他机器学习方法(监督和无监督学习)不一样的是,强化学习问题中不存在监督学习那样的supervisor,又不像无监督学习完全没有supervisor。强化学习基于收益信号(Reward),并且该信号是时延的。
- 时间对于强化学习问题非常重要,这说明了强化学习问题与序列化决策过程有关,即智能体(Agent)每一时刻的动作选取都会影响下一时刻所接收的信息(即reward)。解决强化学习问题所得到的最终结果就是一系列动作(A Sequence of Actions)。
2.2 强化学习问题的基本假设
强化学习的基本假设:学习目标为最大化累计收益(maximization of cumulative reward)
2.3 强化学习问题中的一些元素
收益(Rewards)
收益是一个标量反馈信号,直观可以理解成衡量智能体在某个步骤中的表现好坏,用 R t R_t Rt表示。
具体的例子:直升机飞行特技中,如果直升机偏离预设轨迹,收益为负;围棋比赛中,赢得比赛收益为正;管理投资中,赚钱则收益为正。
序列化决策(Sequential Decision Making)
序列化动作中每一个动作会带来长期“影响”,即对收益的影响。所选取的序列化动作有的时候需要牺牲短期收益,获得长期收益。
具体的例子:在直升机飞行特技过程中,直升机可能出现没有燃料的情况,这时候尽管进行下一个飞行动作可能会带来很高的收益,但是很有可能下一个动作结束之后直升机由于没油了直接坠毁,这样就得不偿失。
智能体和环境
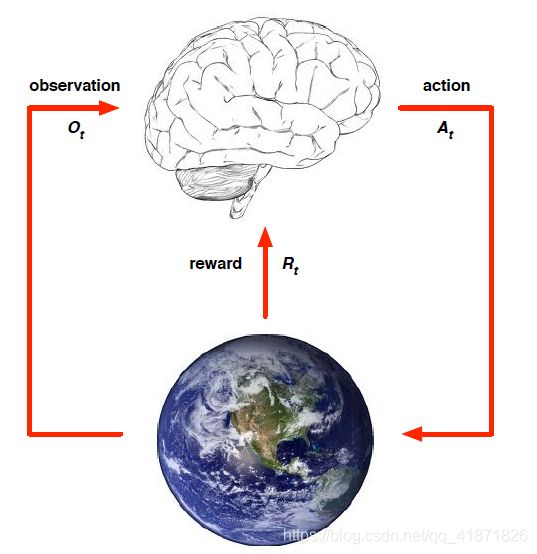
- 智能体
每一个时间t,智能体会做出以下“行为”:执行动作 A t A_t At, 获得对环境的观测值 O t O_t Ot,获取收益 R t R_t Rt。 - 环境
a. 每一个时间t,环境会做出以下“行为”:接收智能体的动作 A t A_t At, 发出智能体下一时刻将会观测到的值 O t + 1 O_{t+1} Ot+1,发出收益 R t + 1 R_{t+1} Rt+1。(这里假设智能体做出动作和收到环境发出的收益对应不同的时刻)
b. 环境的分类: I. 完全可观测环境(Fully Observable)中智能体直接观测环境状态,并且满足 O t = S t a = S t e O_t=S_t^a=S_t^e Ot=Sta=Ste,即智能体状态与环境状态相等(后文有详细解释),建模为Markov Decision Process (MDP) II. 部分可观测环境(Partially Observable)中智能体间接观测环境状态,agent state不等于environment state, 智能体需要构造自己的状态描述,建模为POMDP(Partially Observable Markov Decision Process)
历史(History)和状态(State)
历史:
历史是到当前时间为止,智能体所有的动作、观测、收益的序列,数学表示为: H t = A 1 , O 1 , R 1 , . . . , A t − 1 , O t − 1 , R t − 1 , O t , R t H_t=A_1,O_1,R_1,...,A_{t-1},O_{t-1},R_{t-1},O_t,R_t Ht=A1,O1,R1,...,At−1,Ot−1,Rt−1,Ot,Rt
引入历史的意义在于智能体对于动作的选择和环境对于发出观测值/收益的选择均取决于历史。
状态:
状态的直观含义是对历史的一个“总结”(summary),数学上的精确定义是:状态是历史的一个函数, S t = f ( H t ) S_t=f(H_t) St=f(Ht)
- 环境状态
环境状态的表示为 S t e S_t^e Ste,其含义是环境的私有表示 (private representation),环境在其状态信息的基础上选择所发出的收益信号或观测信号;一般来说,智能体对这些环境状态不可知;并且环境状态信息中一般也会包含不相关信息。 - 智能体状态
智能体状态的表示为 S t a S_t^a Sta,它是智能体的一个内部表示(internal representation),智能体在此基础上选择下一个动作;智能体状态是历史的一个函数, S t a = f ( H t ) S_t^a=f(H_t) Sta=f(Ht)(所以前文中的状态指的是智能体状态) - 信息状态(Information State)
又称为Markov state,包含历史中有用的信息;信息状态满足Markov property:

马尔可夫性可以理解为:未来与过去无关,只与现在有关;也就是说一旦当前状态已知,智能体就放弃历史信息。(环境状态和历史均满足马尔可夫性)
2.4 强化学习问题中存在的Trade-off
探索和利用(Exploration V.S. Exploitation)
- Exploration
exploration是发现更多关于环境的信息,一种极端情况是在探索中智能体收到的收益越来越低。 - Exploitation
exploitation则是利用已知的环境信息最大化智能体的收益 - 一个非常直观的例子
在选择餐馆吃饭这个情境下,如果我们每次只去自己非常熟悉的店,因为我们能保证这家餐馆肯定比较符合我们的胃口,因此收益不差,这就是exploitation。如果我们想换个口味,选择跟朋友找一些新的餐馆,这时就是exploration。发现新美食的过程中我们很可能遇到不合自己口味的或者是店员服务很差的情况,这样我们的收益就降低了;但也有可能遇到了更适合自己的口味的餐馆,这时收益猛涨。
2.5 序列决策过程中的两大类问题
规划问题
- 环境模型已知
- 智能体用已知的环境模型做计算(并不存在于环境的交互)
- 智能体在计算之后改进策略
- 例如:在王者荣耀中,“玩家”了解所有的游戏规则,那么规划问题转化为一个查询问题,方法有树搜索的方法。(显然并不现实)
核心的强化学习问题
- 环境模型未知
- 智能体与环境交互
- 智能体在与环境交互之后改进策略
- 例如,在王者荣耀中,“玩家”并不了解所有的游戏规则,那么要想玩好只能边玩边了解。
3. 强化学习方法有哪些?
3.1 Agent所含的三种元素
策略(Policy)
策略也就是智能体的行为agent’s behaviour。策略的准确定义是状态到动作的映射。一般有两种:(这里实在翻译水平有限,见谅)
- Deterministic Policy(确定性策略)
a = π ( s ) a = \pi(s) a=π(s) - Stochastic Policy(随机性策略)
π ( a ∣ s ) = P ( A t = a ∣ S t = s ) \pi(a|s)=P(A_t=a|S_t=s) π(a∣s)=P(At=a∣St=s)
值函数(Value Function)
值函数是对未来收益的预测,用于评估状态的好坏。公式如下:
v π ( s ) = E π [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + … ∣ S t = s ] v_{\pi}(s)=E_{\pi}[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3} + \dots|S_t=s] vπ(s)=Eπ[Rt+1+γRt+2+γ2Rt+3+…∣St=s]
模型(Model)
模型是智能体对于环境的表示,用于预测环境下一步会做什么。
模型一般由状态转移概率和收益组成:
- 状态转移概率
P S S ′ a = P ( S t + 1 = s ′ ∣ S t = s , A t = a ) \bold P_{SS'}^a=P(S_{t+1}=s'|S_t=s, A_t=a) PSS′a=P(St+1=s′∣St=s,At=a) - 收益
R S a = E ( R t + 1 = s ′ ∣ S t = s , A t = a ) \bold R_{S}^a=E(R_{t+1}=s'|S_t=s, A_t=a) RSa=E(Rt+1=s′∣St=s,At=a)
(这里收益的定义与期望有关,这是因为给定当前状态和动作的情况下,下一个状态是随机的,所以求均值)
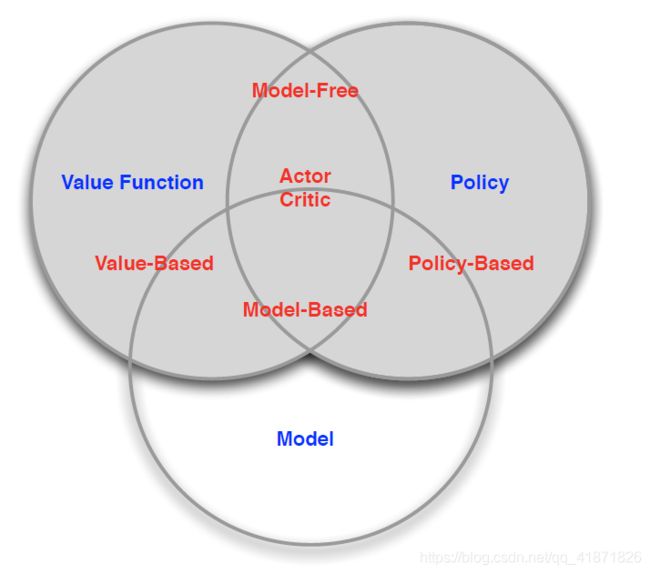
3.2 强化学习方法的两种分类
根据策略和值函数的有无分类
- Value Based(有值函数,不含策略,有模型)
- Policy Based(没有值函数,含策略,有模型)
- Actor-Critic(有值函数,含策略,有模型)
根据有无模型分类
- model free(有策略和值函数,没有模型)
- model based(有策略和值函数,有模型)
分类示意图:
3.3 强化学习方法的大致过程
(这里按照自己的理解整理的,可能跟原课程老师的意思不太一样,望指正)
- 预测
给定一个策略,对未来进行评估,从而判断智能体的状态是好是坏 - 控制
在预测的基础上,对未来的累计收益(值函数)进行优化,即找到一个最好的策略
课程视频网址:
https://www.bilibili.com/video/BV1kb411i7KG