强化学习笔记(2)——MDP
本文概要
本文个人是对david silver强化学习课程第二课的总结,有任何不足之处希望大家指正!
马尔可夫决策过程(MDP)精确描述了环境,MDP假设环境是完全可观的并且环境中所有的状态都满足马尔可夫性。本节课老师的讲解思路是先从最基本的马尔可夫开始,一步增加某些元素过渡到MDP的具体数学模型,最后提出求得最优解的方法。
1. 马尔可夫过程(Markov Process)
1.1 MP定义

(不知道为什么从思维导图复制过来的截图变色了…)
从中可以看出MP的组成为 < S , P >
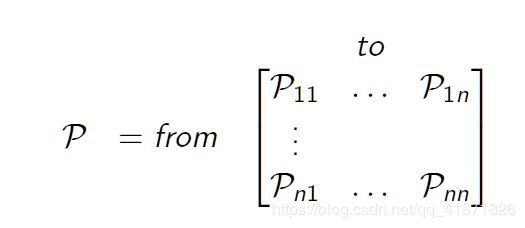
1.2 直观例子
本节课基本所有例子都在用学生上课过程的例子,如下图:

左图中圆圈代表状态,正方形代表停止的状态(实际过程中并不确定程序什么时候会停止)。右边是该过程的状态转移矩阵。假设我们从class 2状态开始进行采样,每一个时段内我们都会得到不同的状态序列,例如:
C 2 , C 3 , P a s s , S l e e p C2, C3, Pass, Sleep C2,C3,Pass,Sleep C 2 , C 3 , P u b , C 2 , S l e e p C2, C3, Pub, C2, Sleep C2,C3,Pub,C2,Sleep C 2 , C 3 , P u b , C 1 , C 2 , S l e e p C2, C3, Pub, C1,C2, Sleep C2,C3,Pub,C1,C2,Sleep C 2 , C 3 , P u b , C 1 , F B , F B , C 1 , C 2 , C 3 , P a s s , S l e e p C2, C3, Pub, C1,FB, FB, C1,C2,C3, Pass, Sleep C2,C3,Pub,C1,FB,FB,C1,C2,C3,Pass,Sleep
2. 马尔可夫收益过程(Markov Reward Process)
2.1 MRP定义
直观理解:MRP与MP类似,只是在MP的基础上加上了收益信号和折扣因子(discount factor),下图蓝色区域已经标出。
准确定义如下图:

定义中的收益函数 R R R是收益(标量信号)的期望,为什么收益函数需要用期望来表示?(下文MRP与MDP的关系也会提到),原因在于智能体在某个状态下,在不同的采样时刻可能获得的收益都是不同的。我觉得可以用一个游戏的例子来理解这个概念,比如在王者荣耀对局中,比如说你选择的是中路法师,现在在中路清理兵线,在某一个时候只有你一个人在清理兵线,那么你会独享这些收益;但是下一时刻,可能队友在你身边,那么收益就会降低。
折扣因子
使用折扣因子的原因:
- 数学表达上的方便
- 避免无限返回值
- 并不会完全描述未来的不确定性
2.2 根据定义中的量描述长期收益
返回值(Returns)
返回值(这里直接翻译了,也有更好的翻译是“回报值”)的定义如下所示:

这里折使用扣系数的幂次与未来的收益相乘,表达的物理意义就是在当前时刻下智能体对未来收益的一种"估算"。
值函数(Value Function)
在第一节课的笔记中提到,引入值函数的目的就是用来描述状态的长期收益或价值。准确定义如下:

2.3 MRP的贝尔曼方程(Bellman Equation)
数学推导过程及表达形式
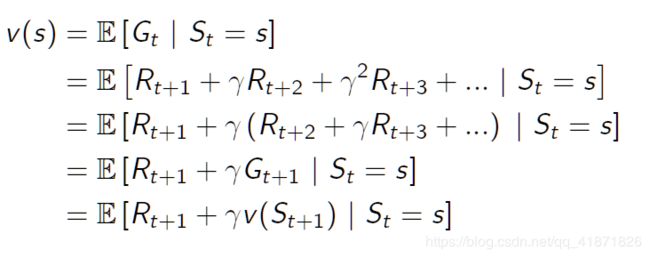
贝尔曼方程的目的:
贝尔曼方程的目的就是将上文中的值函数分解成两个部分:第一是当前立即获得的收益(immediate reward);第二个是下一个状态值函数的折扣值(discounted value)
这里把结论再重复一下(重要结论,下文推导也要使用):
v ( s ) = E [ R t + 1 + γ v ( S t + 1 = s ′ ) ∣ S t = s ] v(s)=\mathbb{E}[R_{t+1}+\gamma v(S_{t+1}=s')|S_t=s] v(s)=E[Rt+1+γv(St+1=s′)∣St=s]
贝尔曼方程的进一步化简
根据以上的结论,可以看出值函数的定义和贝尔曼方程中涉及到了期望函数,所以我们可以利用期望的线性叠加性质对公式进行化简(为了表示方便,把 v ( S t + 1 = s ′ ) v(S_{t+1}=s') v(St+1=s′)表示成 v ( s ′ ) v(s') v(s′)):
v ( s ) = E [ R t + 1 + γ v ( s ′ ) ∣ S t = s ] = E [ R t + 1 ] + γ E [ v ( S t + 1 = s ′ ∣ S t = s ) ] v(s)=\mathbb{E}[R_{t+1}+\gamma v(s')|S_t=s]=\mathbb{E}[R_{t+1}]+\gamma \mathbb{E}[v(S_{t+1}=s'|S_t=s)] v(s)=E[Rt+1+γv(s′)∣St=s]=E[Rt+1]+γE[v(St+1=s′∣St=s)] = R t + 1 + γ ∑ s ′ ∈ S v ( s ′ ) P [ S t + 1 = s ′ ∣ S t = s ] =R_{t+1}+\gamma \sum_{s'\in S}v(s')\mathbb{P}[S_{t+1}=s'|S_t=s] =Rt+1+γs′∈S∑v(s′)P[St+1=s′∣St=s]从而可以得到: v ( s ) = R t + 1 + γ ∑ s ′ ∈ S v ( s ′ ) P s s ′ v(s)=R_{t+1}+\gamma \sum_{s'\in S}v(s')P_{ss'} v(s)=Rt+1+γs′∈S∑v(s′)Pss′
用以下的树状图可以解释以上公式:

一个计算MRP中值函数的例子( γ = 1 \gamma =1 γ=1):
除了下图中给出的状态,也可以计算其他状态的值。例如,左上角的状态值: − 23 = − 1 + − 23 × 0.9 + ( − 13 × 0.1 ) -23=-1+-23\times0.9+(-13\times 0.1) −23=−1+−23×0.9+(−13×0.1)
这里 − 1 -1 −1代表到达左上角状态之后有的收益,也就是上述方程中的,后面是从当前状态可能到达的状态值乘以对应的状态转移概率。

贝尔曼方程的矩阵形式及解法
在上文化简的基础上,将以上公式写称矩阵形式:
[ v ( 1 ) ⋮ v ( n ) ] = [ R 1 ⋮ R n ] + γ [ P 11 … P 1 n ⋮ P n 1 … P n n ] [ v ( 1 ) ⋮ v ( n ) ] \begin{bmatrix} v(1) \\ \vdots \\ v(n) \end{bmatrix}=\begin{bmatrix}R_1 \\ \vdots \\ R_n\end{bmatrix} + \gamma \begin{bmatrix} P_{11} & \dots & P_{1n}\\ \vdots \\ P_{n1} & \dots & P_{nn}\end{bmatrix}\begin{bmatrix} v(1) \\ \vdots \\ v(n) \end{bmatrix} ⎣⎢⎡v(1)⋮v(n)⎦⎥⎤=⎣⎢⎡R1⋮Rn⎦⎥⎤+γ⎣⎢⎡P11⋮Pn1……P1nPnn⎦⎥⎤⎣⎢⎡v(1)⋮v(n)⎦⎥⎤
以上矩阵形式也可以直接用以下方程来表示 v = R + γ P v \textbf{v}=\textbf{R}+\gamma P\textbf{v} v=R+γPv
(加粗的字母代表向量, P P P表示状态转移矩阵)
a. 直接求解法
由线性代数的一些基本概念可以知道,以上方程可以通过矩阵求逆来求解:
v = ( I − γ P ) − 1 R \textbf{v}=(I-\gamma P)^{-1}\textbf{R} v=(I−γP)−1R
存在的问题:
- 算法复杂度为 O ( n 3 ) O(n^3) O(n3)
- 只适用于小数据量的MRP
b. 迭代法求解法(该系列后面的课程应该都会涉及到)
- 动态规划
- 蒙特卡洛方法
- 时序差分法
3. 马尔可夫决策过程(Markov Decision Process)
3.1 MDP定义
有了前文的MP和MRP,在此基础上加上“决策”相关的定义就构成了MDP。准确定义如下图:

与MRP对比可以发现,收益函数、状态转移概率的定义都多了一个动作的先验条件。而动作的概率分布就是策略。
需要说明的是,课程里的状态转移概率和矩阵其实做了省略,MDP中所谓的状态转移其实是后继状态和后继状态带来的收益的联合概率分布,即 p ( s ′ , r ∣ s , a ) = P [ S t + 1 = s ′ , R t + 1 = r ∣ S t = s , A t = a ] p(s',r|s,a)=\mathbb{P}[S_{t+1}=s', R_{t+1}=r|S_t=s,A_t=a] p(s′,r∣s,a)=P[St+1=s′,Rt+1=r∣St=s,At=a],这里的状态转移概率 P s s ′ a = ∑ r p ( s ′ , r ∣ s , a ) P_{ss'}^a=\underset{r}{\sum}p(s',r|s,a) Pss′a=r∑p(s′,r∣s,a)得到的边缘概率分布。
3.2 策略
策略的定义
- 随即策略(策略是动作的概率分布)

- 确定性策略: a = π ( s ) a=\pi(s) a=π(s)
策略的特点
- 策略完整定义了智能体的行为
- MDP中的策略取决于当前状态(而不是历史)
- 策略是静态stationary的,与时间无关,只与当前所处的状态有关。
3.3 MDP与MP、MRP的关系
根据MDP的定义,就可以发现其与MP、MRP的基本关系。
假设给定MDP和一个策略(即动作的概率分布已知),则状态序列 S 1 , S 2 , … S1,S2,\dots S1,S2,…是一个MP, < S , P π >
MRP与MDP中状态转移概率的关系
P s s ′ π = ∑ a ∈ A π ( a ∣ s ) P s s ′ a P_{ss'}^{\pi}=\sum_{a\in \mathcal{A}}\pi(a|s)P_{ss'}^{a} Pss′π=a∈A∑π(a∣s)Pss′a
该公式的推导来自于全概率公式,先回顾状态转移概率的准确定义:
P s s ′ π = P [ S t + 1 = s ′ ∣ S t = s ] P_{ss'}^{\pi}=\mathbb{P}[S_{t+1}=s'|S_t=s] Pss′π=P[St+1=s′∣St=s]而 P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] P_{ss'}^{a}=\mathbb{P}[S_{t+1}=s'|S_t=s, A_t=a] Pss′a=P[St+1=s′∣St=s,At=a]可以看出 P s s ′ a P_{ss'}^{a} Pss′a是基于 P s s ′ π P_{ss'}^{\pi} Pss′π的条件概率。又因为动作的概率分布已知,那么根据全概率公式就可以得到 P s s ′ π = ∑ a ∈ A π ( a ∣ s ) P s s ′ a P_{ss'}^{\pi}=\sum_{a\in \mathcal{A}}\pi(a|s)P_{ss'}^{a} Pss′π=a∈A∑π(a∣s)Pss′a
MRP与MDP中收益信号的关系
同理,收益函数的关系也是类似的。
R s π = E [ R t + 1 ∣ S t = s ] R_{s}^{\pi}=\mathbb{E}[R_{t+1}|S_t=s] Rsπ=E[Rt+1∣St=s]而 R s s ′ a = E [ R t + 1 ∣ S t = s , A t = a ] R_{ss'}^{a}=\mathbb{E}[R_{t+1}|S_t=s, A_t=a] Rss′a=E[Rt+1∣St=s,At=a]与之前唯一的区别就是定义中是期望函数,根据全概率公式也可以得到 R s π = ∑ a ∈ A π ( a ∣ s ) R s a R_{s}^{\pi}=\sum_{a\in \mathcal{A}}\pi(a|s)R_{s}^{a} Rsπ=a∈A∑π(a∣s)Rsa
3.4 MDP中的值函数定义
状态值函数

动作值函数
状态值函数的物理意义是衡量当前状态的好坏,而动作值函数的物理意义就是衡量执行当前动作的好坏。
这里 G t G_t Gt 依然是返回值,之前的定义一样。
3.5 贝尔曼期望方程(Bellman Expectation Equation)
值函数分解
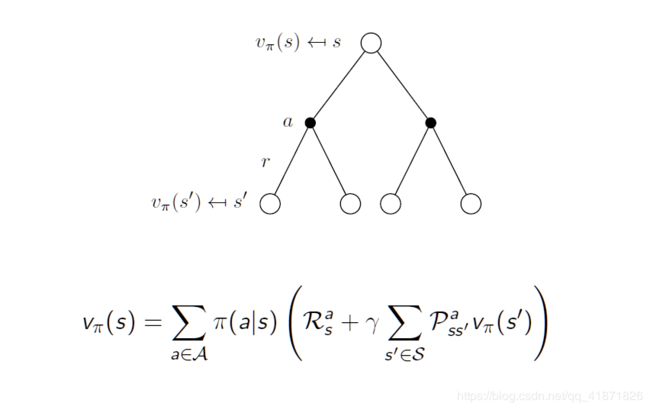
状态值函数分解
与MRP一样,状态值函数可以分解为当前收益和继任状态值的折扣值。
v π ( s ) = E [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] v_{\pi}(s)=\mathbb{E}[R_{t+1}+\gamma v_{\pi}(S_{t+1})|S_t=s] vπ(s)=E[Rt+1+γvπ(St+1)∣St=s]
动作值函数分解
动作值函数可以分解为当前收益和继任动作值的折扣值。
q π ( s , a ) = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + ⋯ + γ k R t + k + 1 + … ) ∣ S t = s , A t = a ] q_{\pi}(s,a)=\mathbb{E}[R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+\dots+\gamma^k R_{t+k+1}+\dots)|S_t=s,A_t=a] qπ(s,a)=E[Rt+1+γRt+2+γ2Rt+3+⋯+γkRt+k+1+…)∣St=s,At=a]或者是
q π ( s , a ) = E [ R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ] q_{\pi}(s,a)=\mathbb{E}[R_{t+1}+\gamma q_{\pi}(S_{t+1},A_{t+1})|S_t=s,A_t=a] qπ(s,a)=E[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]
值函数迭代(或状态值与动作值的关系)
一步迭代回溯
1. 状态值函数
从上文的状态值函数和动作值函数的定义可以看出,这一步的推导依然是基于全概率公式。

2. 动作函数
这一步的推导基于动作值函数的定义:
q π ( s , a ) = E [ G t ∣ S t = s , A t = s ] , G t = R t + 1 + γ v π ( S t + 1 = s ′ ) q_{\pi}(s,a)=\mathbb{E}[G_t|S_t=s,A_t=s], \quad G_t=R_{t+1}+\gamma v_{\pi}(S_{t+1}=s') qπ(s,a)=E[Gt∣St=s,At=s],Gt=Rt+1+γvπ(St+1=s′)
联立两者可以得到:
q π ( s , a ) = R t + 1 + γ E [ v π ( s ) ∣ S t = s , A t = a ] = R t + 1 + γ ∑ s ′ ∈ S v π ( s ) P [ S t = s ′ ∣ S t = s , A t = a ] q_{\pi}(s,a)=R_{t+1}+\gamma \mathbb{E}[v_{\pi}(s)|S_t=s,A_t=a]=R_{t+1}+\gamma \sum_{s'\in \mathcal{S}}v_{\pi}(s)\mathbb{P}[S_t=s'|S_t=s, A_t=a] qπ(s,a)=Rt+1+γE[vπ(s)∣St=s,At=a]=Rt+1+γs′∈S∑vπ(s)P[St=s′∣St=s,At=a] = R t + 1 + γ ∑ s ′ ∈ S v π ( s ) P s s ′ a =R_{t+1}+\gamma \sum_{s'\in \mathcal{S}}v_{\pi}(s)P_{ss'}^a =Rt+1+γs′∈S∑vπ(s)Pss′a
(推导思路就是将定义式在满足期望性质的前提下展开,其中 R t + 1 R_{t+1} Rt+1是确定的,可以提出来,后面的线性项根据返回值与状态值的关系继续化简)

两步迭代回溯
迭代两步的情况就是组合上文迭代一步的情况,第一种情况将动作值函数的表达形式带入状态值函数;第二种情况将状态值函数的表达式代入动作值函数。
1. 状态值函数
2. 动作值函数

贝尔曼方程的矩阵形式
贝尔曼方程的矩阵形式与MRP中的形式一样。
状态值函数的计算实例

图中的计算例子基于以下式子:

除了图中标出的状态,我们也可以看其他状态的值是怎么计算的,例如计算最中间的状态(值为2.7的状态): 2.7 = 0.5 ∗ ( − 2 + 7.4 ) + 0.5 ∗ 0 2.7=0.5*(-2+7.4)+0.5*0 2.7=0.5∗(−2+7.4)+0.5∗0
4. 如何求得最优解
4.1 最优值函数 (Optimal Value Function) 定义

最优值函数的意义在于从所有策略中找到能够实现最大的状态值或者动作值的策略。MDP的解决过程就是求最优值函数找到最优策略的过程。
4.2 最优策略 (Optimal Policy)
最优策略的定义基于偏序关系,策略之间的比较基于该策略下所达状态值函数的大小。

上述定理说明:
- 任意的MDP都存在至少一个最优策略。
- 所有的最优策略都能让状态值函数、动作值函数达到最优。
4.3 如何寻找最优策略
方法:通过最大化动作值函数来寻找最优策略。
这里的最优策略的意义就是只使用能够让动作值函数最大的动作,也就是从原先的随机策略转化为了确定策略。

对上图的解释可以参考下表:
| Action | Probability |
|---|---|
| arg max a ∈ A q ∗ ( s , a ) \underset{a\in\mathcal{A}}{\arg\max}\ q_*(s,a) a∈Aargmax q∗(s,a) | 1 |
| other actions | 0 |
下图给出寻找最优策略的例子。比如起始点为左上角的点,如果已知了每一步中的 q ∗ ( s , a ) q_*(s,a) q∗(s,a),则最优策略会立即得到。

4.4 贝尔曼最优方程(Bellman Optimality Equation)
与贝尔曼期望方程的关系:
贝尔曼最优方程是建立在贝尔曼期望方程的基础上的,在假设得到最优策略的情况下对两种值函数做了更进一步的推断。
一步迭代回溯
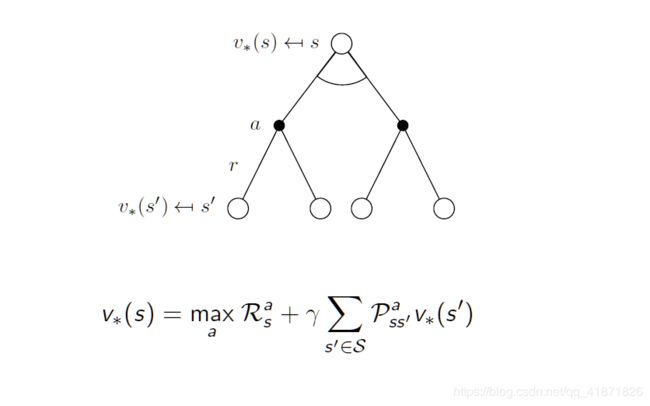
1. 最优状态值函数
与前文的迭代方法几乎类似,唯一不同的就是最优的状态值是通过最大化最优动作值函数得到的,后文给出对于该公式的证明。

该关系可以通过反证法来证明:
首先最优策略本身也满足先前的贝尔曼期望方程,所以下式是一定成立的。但是这里只能说明是小于等于关系,而上图中的公式中只有等于,那么证明思路就就是用反证法说明该公式中不可能出现小于号。
v π ∗ ( s ) = ∑ a ∈ A π ∗ ( a ∣ s ) q π ∗ ( s , a ) ≤ max a q π ∗ ( s , a ) v_{\pi_*}(s)=\sum_{a\in \mathcal{A}} \pi_*(a|s)q_{\pi_*}(s,a)\leq \underset{a}{\max}\ q_{\pi_*}(s,a) vπ∗(s)=a∈A∑π∗(a∣s)qπ∗(s,a)≤amax qπ∗(s,a)
反证法:(参考《白板推导——强化学习系列》)
假设 v π ∗ ( s ) < max a q π ∗ ( s , a ) v_{\pi_*}(s)<\underset{a}{\max}\ q_{\pi_*}(s,a) vπ∗(s)<amax qπ∗(s,a),则可以构造一个新的策略 π o p t i o n a l ( a ∣ s ) \pi_{optional}(a|s) πoptional(a∣s),使其动作的概率分布满足下表:
| π o p t i o n a l \pi_{optional} πoptional中的动作 | probability |
|---|---|
| arg max a q π ∗ ( s , a ) \underset{a}{\arg\max}\ q_{\pi_*}(s,a) aargmax qπ∗(s,a) | 1 |
| other actions | 0 |
这时利用上表的概率分布可得, v π o p t i o n a l ( s ) = ∑ a ∈ A π o p t i o n a l ( a ∣ s ) q π o p t i o n a l ( s , a ) = max a q π ∗ ( s , a ) > v π ∗ ( s ) v_{\pi_{optional}}(s)=\underset{a\in \mathcal{A}}{\sum} \pi_{optional}(a|s)q_{\pi_{optional}}(s,a)=\underset{a}{\max}\ q_{\pi_*}(s,a)>v_{\pi_*}(s) vπoptional(s)=a∈A∑πoptional(a∣s)qπoptional(s,a)=amax qπ∗(s,a)>vπ∗(s),又因为如果 v π o p t i o n a l ( s ) > v π ∗ ( s ) v_{\pi_{optional}}(s)>v_{\pi_*}(s) vπoptional(s)>vπ∗(s),则 π o p t i o n a l > π ∗ \pi_{optional}>\pi_{*} πoptional>π∗,这与 π ∗ \pi_{*} π∗是最优策略相矛盾,所以一定存在: v π ∗ ( s ) = max a q π ∗ ( s , a ) v_{\pi_*}(s)=\underset{a}{\max}\ q_{\pi_*}(s,a) vπ∗(s)=amax qπ∗(s,a)
2. 最优动作值函数
最优动作值函数与之前的动作值函数迭代过程类似,只是将策略换成了最优策略 π ∗ \pi_* π∗,相应值函数也就换成了 v ∗ ( s ) v_*(s) v∗(s)。

两步迭代回溯
1. 最优状态值函数
联立一步迭代回溯的情况,将最优动作值函数的表达式代入最优状态值函数。
2. 动作值函数
联立一步迭代回溯的情况,将最优状态值函数的表达式代入最优动作值函数。

5. MDP的扩展
- Infinite and continuous MDP
- Partially Observable MDP (POMDP)
- Undiscounted, average reward MDPs