FPGA、集创赛记录
文章目录
- 比赛历程
- FPGA创新设计竞赛
- 集成电路创新创业大赛
- 20.2.27 拟定短期目标
- 20.3.3 python脚本,2x2 2Dmesh NoC测试
- 20.3.10 $display,宏定义,自适应规模,verilog基本问题,按位与/位与
- 20.3.11 单片机与状态机FSM 系统函数$clog2()求位宽 生成块
- 20.3.12 python脚本写N接口的路由表
- 20.3.14 验证计划testbench以及display,fwrite等系统函数
- 20.3.14 display,fwrite等系统函数使用
- 20.3.15 系统函数$fopen(./name.txt,"w")产生的文件的位置问题
- 20.3.15 task调用、调用其他模块的信号/task
- 20.3.15 玩python验证
- 20.3.23 专利修改
- 20.3.27 小结
- 关于DyXY算法设计
- 关于绘图设计
- 20.3.28 自闭
- 20.3.29
- 20.4.2 将R矩阵文件写入verilog文件里module的接口上
- 20.4.2 关于python函数调用(跨文件)
- 20.4.3 将verilog生成的路由表生成矩阵文件,以便np读取
- 20.4.4 ifdef宏定义,En、多级堵塞
- 20.4.4 else-if 和else里嵌套if
- 20.4.6 Dijkstra、Floyd、bellman-ford、Spfa算法
- 20.4.6 Dijkstra
- 20.4. 14 记忆网络来动态调节Q模块
- 20.4. 15 金字塔类型的Q-routing的构想以及若干问题
- 20.4. 关于Python的一些操作
- 20.4.17 一些关于比赛科研的思考吧
- 20.4.18 Q模块作为基本,完善并例化出第二、三层Q模块,搭建金字塔
- 20.4.19 记忆网络产生路由表,表现出活锁,人工智障。。
- 20.4.20 金字塔继续完善
- 20.4.20 重挫
- 20.4.20 创新点
- 20.4.21 记忆网络灾难:雪崩
- 20.4.21 金字塔中间设计测试完成
- 20.4.21 routertable.v访问信号修改
- 20.5.21 时隔一个月
- 20.5.21 修改几层Q参数
- 20.5.21 综合
- 20.5.21 vivado实现
- 20.5.21 惊了
- 20.5.21 对于vivado添加新的芯片型号
- 20.5.21 对于mem类型定义的时候需要常量
- 20.5.22
- 20.5.22 scanf函数会极高的占用运行内存
- 20.5.22 ASIC异步复位,FPGA同步复位
- 20.5.22 RTL视图(不要加入综合后的网表信息,仿真巨慢)
- 20.5.23 小结:从一个全功能Qroute到通用(可例化成不同Qroute)
- 20.5.23 if-else if -else和if -if -if的区别
- 20.5.23 因为综合闹出的毛病
- 20.5.23 修正DyXY算法
- 20.5.30 主要是Q连线
- 20.5.31 错误的软件验证
- 20.5.31 关于仿真
- 20.6.1 队友沟通
- 20.6.1 龟速仿真
- 20.6.3 重复打印的问题
- 20.6.6不要在文件目录里出现空格
- 20.6.7 vivado如何读取以前的wave配置文件
- 20.6.8 三层Q之间的纠正与传输
- 20.6.17 关于IP
- 20.6.19 实验
- 基本上结束
比赛历程
FPGA创新设计竞赛
19.12.7
已经过去,拿到国二,有空再提。
20.1.15
这以前讨论了几次,加入了千核,容错这两个话题。阅读了十余篇期刊会议论文,确定自己研究的东西别人没有造过(造轮子难受,调研是个好习惯,可惜这次比赛匆忙没有调研)
20.2.10
这以前团队阅读了数十篇关于路由算法的硕博论文,个人完成了Q-learning的完全拆分模块化(rtl实现),构想了金字塔型(类似省市区一样分层治之)的Q-learning。队友完成了noc的重新规划。(无奈是并行的数据传输,后来还得改成串行的,毕竟业界还是串行为主)(加上了计数器?RR-arbiter,多通道选通器,可以实现多目标传输–之前比赛只能实现一个节点发一个节点收)
20.2.22
这以前学习了两三篇专利写作,调研了数十篇专利(呕)确定没有造轮子。完成了专利的初步撰写。ppt画图是个好东西,改了几十版,改专利(语文太次)改到吐。
集成电路创新创业大赛
20.2.27 拟定短期目标
继承之前的比赛项目,我们选择了集创赛的创新实践杯。
我们的题目还不确定,关键词大概是Q-learning,NoC,千核,容错,(金字塔?CNN?不知道)
其实我一直是一个喜欢想好再做的人。所以太拖沓了,因为金字塔不完善,因为各种问题不清楚所以一直没有动手实操。今天开会,指导老师要求多动手(/尴尬)。
拟定了短期目标:
1.完成python脚本的学习和撰写,路由器节点测试(2days)
2.Q-learning在2x2NoC上的测试,路由器继续改进(2days)
3.4x4x4 3DNoC平台搭建。(基于脚本和之前的模块化)(3-7days)
4.平台复用(和x-y算法对比),测试指标:平均延时。用Verilog代码记录时间存储到txt文件中。路由器造堵,串行传输,计数器,容错等多功能完成。
5.多目标传输。(4-5 1month)
6.8x8 2DNoC对比
7.其余算法的对比,传统动态路由算法。A*算法。
8.千核3Dnoc搭建。金字塔等方案考虑。
9.论文撰写。(6-9 1month)
比赛结束(6.1提交)
20.3.3 python脚本,2x2 2Dmesh NoC测试
- 开会完毕后两三天完成了一个脚本(从0学python,伤不起),可见我另一篇博客AIIC学习日记-python篇.
- 随后两天完成了Q-learning在2x2 2Dmesh NoC上的测试。测试内容包括Q值(边缘部分处理、轮转到本身时是否产生最大奖励值,本地节点在非目的节点时是否正常传值)存储的路由表是否正确。缺乏数据包头微片访问Q返回方向这个测试(不会啊,这个片上网络是队友做的,我线上也说不清楚)
- Q-learning从传统算法改进,传统的R值包含了堵塞/目的值信息,而我们用片上网络计数器/温度传感器量化后的等级作为R值,所以目的信息无法得到。我采用了轮转的方式,依次让4个目的节点为终点(本次只例化了4个Router)。在这之前,本来不想让Q模块带上ID的,但是目的地信息没处来。
20.3.10 $display,宏定义,自适应规模,verilog基本问题,按位与/位与
仿真时:
$display (" `Rotary_ID is :",`Rotary_ID);宏定义:(可以用乘法等作为参数)
`define QRouter_Size 3 //正方形的路由器边长
`define QRouter_ID (`QRouter_Size )* (`QRouter_Size)//如果是引用宏定义,需要加上` !!!!。每个变量最好加上小括号,避免原变量是组合函数时出错verilog语言,满足条件后下一个上升沿才会执行语句。若要按软件的写法,那么需要条件提前。
如下,cnt=2满足else条件但是没有等到clk上升沿,所以test不变。
cnt=3时满足else if,但是没有上升沿,所以执行else,test=0。
cnt=4时等到了上升沿,所以test=1。
reg test=0;
always@(posedge Q_clk )begin
if(Q_Learn_cnt<=1)
test=1;
else if(Q_Learn_cnt>=3)
test=1;
else
test=0;
end
wave:
cnt 0 1 2 3 4 5 6
test 1 1 1 0 1 1 1按位与/位与:
按位与: a = b & c
位与 : a = & b
20.3.11 单片机与状态机FSM 系统函数$clog2()求位宽 生成块
刚才翻了翻FPGA驱动LCD12864,感觉单片机里函数的顺序执行,就等效于状态机的顺序执行。调用函数,等效于状态机跳转(+返回)。
系统函数$clog2()用于求位宽,不可综合。
`define Rotary_ID_Width $clog2(`Rotary_ID) //跑了几次,电脑都黑屏了好桑心啊,这函数有毒吧?生成块:自适应路由器数量真的迷,生成块给每个路由器专门准备了一个always块,用来复制路由表。
generate
for (k=0; k<=`QRouter_ID-1;k=k+1)
begin: bit
always@(posedge Q_clk or negedge rst)begin//write
if(!rst)
Router_Table[k]<=0;
else
Router_Table[k]<= Best_Act_Matrix[k];
end
end
endgenerate20.3.12 python脚本写N接口的路由表
路由表是一个宽度为6bit(方向为6的独热码,本地全1,非路径全0),深度为路由器数量的一维mem(verilog没有数组这个概念)。
由于3DNoC有6个方向+1个local,并且小组讨论后决定用坐标x,y,z来寻址查表,那么第一步就是把坐标译码为1维地址。然后按地址读取路由表数据即可。
但是变量名太多,生成块又不能满足变量为字符的情况。所以又拿起了python写脚本。(下面的代码并不是完整的,鄙人写了一些然后粘贴到verilog文件里,全都用python写太累了)
定义变量,实例化绑定接口用脚本不要太爽。
#!/usr/bin/python
f=open('./verilog_CMP.v','w')
direction={'E','W','S','N','U','D','L'}
for dir in direction: #in定义
for vector in{'x','y','z'}:
f.write(f' input[`Rotary_ID_Width-1:0] ')
f.write(f'NoC_Req_ID_{dir}_{vector};\n')
for dir in direction: #out 定义
f.write(f' output [`Action_Width-1:0] ')
f.write(f'Best_Dir_{dir};\n')
################################################################################################
for dir in direction: #合成ID 定义
f.write(f' reg [`Rotary_ID_Width-1:0] ')
f.write(f'NoC_Req_ID_{dir};\n')
for dir in direction:#ID生成器
f.write(f' //{dir}:NoC_reqest_direction_ID \n')
f.write(f' always@(posedge clk_Q or negedge rst)begin \n')
f.write(f' if(!rst) NoC_Req_ID_{dir} <= 0;\n')
f.write(f' else NoC_Req_ID_{dir} <= NoC_Req_ID_{dir}_x + \n')
f.write(f' `QRouter_Size * NoC_Req_ID_{dir}_y + \n')
f.write(f' `QRouter_Size * `QRouter_Size * NoC_Req_ID_{dir}_z; \n')
f.write(f' end \n\n')
##################################################################################################
for dir in direction: #out_reg 定义
f.write(f' reg [`Action_Width-1:0] ')
f.write(f'Best_Dir_{dir}_r;\n')
for dir in direction:#方向返回
f.write(f' //direction_reg:{dir} \n')
f.write(f' always@(posedge clk_Q or negedge rst)begin \n')
f.write(f' if(!rst) Best_Dir_{dir}_r <= 0;\n')
f.write(f' else begin\n')
f.write(f' if(Q_initial_End && Read_Dir_En)//仅当初始化完成且不在更新路由表时可以读取\n')
f.write(f' Best_Dir_{dir}_r <= Router_Table[NoC_Req_ID_{dir}];\n')
f.write(f' else Best_Dir_{dir}_r <=0;\n')
f.write(f' end \n')
f.write(f' end \n\n')
for dir in direction:#assign
f.write(f' assign Best_Dir_{dir} = Best_Dir_{dir}_r;\n')生成ID需要1clk,查表需要1clk,还是有点慢啊,但如果用组合逻辑可能时序上有问题,算了,让队友背锅。
复制路由表需要两次复制,不能复制正在训练的矩阵。
这个也不知道有没有用,先存着。
generate如何传递不同参数
20.3.14 验证计划testbench以及display,fwrite等系统函数
模块越来越大,手工写激励根本不行,而且得到的结果太抽象,无法通过肉眼判断,波形也太麻烦了,所以痛下决心想写一个testbench。
20.3.14 display,fwrite等系统函数使用
由于系统函数是不同综合的,所以我们仿真的时候可以随便用。不一定要放到tb里,直接在监控的地方上display就好(不过这样不便于管理)(好处是不用跨越一层层的实例化调用去访问那些底层的信息)
Verilog里语句都是块语句(always或者initial)或者生成块generate,在其他地方加一句系统函数会报错(非块语句)。always按clk或者事件触发,还是initial+task的方式来检测路由表信息吧。
以下只打印两次:
../CMP.v
initial begin
#100;
detect_router_table;
#100;
detect_router_table;
end
task detect_router_table;
reg[`Rotary_ID_Width-1:0]tb;
begin
$display("time:",$time);
for(tb=0;tb<=`Rotary_ID;tb=tb+1)begin
// $display("Router_Table[",tb,"]:","%b",Router_Table[tb]);//"%b"规定后面的变量用二进制表示。默认十进制。
$display("Router_Table[%d]:%b;",tb,Router_Table[tb]);//和上面一句效果相同
end
$display("\n");
end
endtask以下为tcl窗口打印出来的信息:
time: 100
Router_Table[ 0]:001000
Router_Table[ 1]:000010
Router_Table[ 2]:000000
Router_Table[ 3]:000000
time: 200
Router_Table[ 0]:000001
Router_Table[ 1]:000001
Router_Table[ 2]:000010
Router_Table[ 3]:000001更疯狂一点:(打印结果就不放了 )每次路由表改变时自动打印:
initial begin
forever//每次更新路由表的时候自动打印
detect_router_table;
end
task detect_router_table;//每次更新路由表的时候打印
reg[`Rotary_ID_Width-1:0]tb;
begin
wait(Q_initial_End && !Read_Dir_En);
wait(Q_initial_End && Read_Dir_En);//在更新完路由表之后才能执行
$display("time:",$time);
for(tb=0;tb<=`Rotary_ID;tb=tb+1)begin
$display("Router_Table[%d]:%b;",tb,Router_Table[tb]);
end
$display("\n");
end
endtask打印系统时间:桌面的时间。
//打印系统时间
initial begin
int data;
integer file;
$system("date +%s>tmp_time.txt");
file=$fopen("tmp_time.txt","r");
$fscanf(file,"%d",data);
$fclose(file);
$system("rm tmp_time.txt");
$display("The time is %d",data);
end20.3.15 系统函数$fopen(./name.txt,“w”)产生的文件的位置问题
关于vivado2018.1系统函数$fopen(./name.txt,“w”)的位置问题
integer pp;
initial begin
pp=$fopen("2.txt","w");
$fdisplay(pp,"%d",$time);
$fclose(pp);
end 结果别人生成的文件给扔这儿来了:(无语至极,直接生成在.v文件旁边不香吗)
…\V0\project_1\project_1.sim\sim_1\behav\xsim
建议直接搜索文件名。
20.3.15 task调用、调用其他模块的信号/task
随机数random
task里定义变量之后初始化。。学问。
x_vector初始化为0,解除了x;
next_agent初始化为0,解除了次态以及很多bug(连环bug,无法打开文件等等)
对于如何传值,真的很头大。还是学学C语言把,先初始化,再放到循环里。一个task真的搞不定。
在不混淆的情况下,可以在task外直接定义变量(reg/integer),这样两个task里都能用。
function和task都是瞬间完成的,调用、循环等都是瞬间完成,得到最后的结果(只能打印出最后一次 调用、循环结果)
并且在被实例化的模块里打印,会同时打印几次信息(每个实例化的模块都会打印)
头大,一样的信息,打印就是正确的结果,写到文件里就只有最后一行。我傻了, 应该用“a”格式打开文件。
$fopen(“name”,“w”)会直接覆盖之前的内容,所以task反复调用,最好写成(“a”)的形式来循环;初始化的时候用(“w”),并且在完成之后等待(sim_period_time)clk,eg:#1;这样仿真时间不再为0,该初始化的值都初始化了 (很多变量在sim_time=0时为x状态,这点很坑,看波形图发现不了,因为x只是在sim_time=0一个瞬间)
for(ii=0;ii<=10;ii=ii+1)
begin
p2=$fopen("../agent.v","w");
$display(ii,$time,"; routerID",Router_ID);
$fdisplay(p2,ii,$time,"; routerID:",Router_ID);
$fclose(p2);
#1;
end20.3.15 玩python验证
接下来的十几天都在搞python,验证路由表,matplotlib绘图。写软件算法。
经典路由表
虚通道、死锁的证明
有人说pdf转html然后用谷歌浏览器翻译,很强。
这个软件非常好用吧,只是不能翻pdf,需要自己手动选中
英文翻译软件1
20.3.23 专利修改
- 图片里只能黑白色无填充,不要用英文,简称除外(ECC勉强可以)
- 强化学习除了用FPGA并行,也可以用GPU、ASIC并行,调查怎么做的(算不算创新点)
- 随机数,别人做强化学习的时候,在其他领域比如游戏路径规划,怎么用并行处理的,我们的是不是创新并行
- 容错是不是别人没有做过的方法,是不是创新
- 多级堵塞算不算创新点,别人有做过吗,我们的有什么区别,如果算创新点的话,我们要加入详细描述
- 文章里很多词不一样,比如R矩阵有很多种写法,
- 单词、简写第一次出现的时候,都给出英文全称和中文的
可累了。果然专利不一样。关键在于独创点,有没有新的东西,改进的地方。(换个角度看问题)
20.3.27 小结
最近一段时间都在做python软件算法验证:
1.对verilog生成的txt文件进行分析(即路由表信息)
1)根据路由表可以固定测试源目节点之间的路径并写入新的txt中
2)根据路由表可以随机指定源目节点,测试其路径并写入新的txt中(包含总跳数)
3)根据路由表可以指定测试源目节点(固定、随机)的次数。
4)根据一次更新的路由表(多次尚且不行)绘出3D路径(利用matplotlib)
2.重建软件验证架构:激励(R堵塞),算法堆,测试体(agent),结果输出(绘图,记录跳数、路径,对网络进行打分)(python)
1)R
2)MAP(依赖项)
3)Q算法
4)XY算法
5)DyXY算法
6) agent(根据路由表进行绘制,打分,等)
7)agent根据路由表记录路径、跳数。(仿上1)
8)计分
9)绘图,并保存到文件 3D保存到文件
关于DyXY算法设计
自个折腾了个判断列表内元素最小的代码。挺不容易。突然发现能直接函数找出最小值和位置。(这不就mmp了,最开始查的时候以为最小值都都打印出来,而我只需要一个最小值)
关于绘图设计
在agent.py里将途经的路由器节点写入txt文件里(注意需要对齐,深度为测了多少次,宽度为Qsize-1)。从agent_draw里直接读取(用np读数组不要太爽!)然后 fig = plt.figure()新建一个窗口,for写完一条路径(路径其实就是两个点的连线,从数组里得到依次的点,最后几个点重合不影响),然后存入磁盘:plt.savefig(f’./Draw/pic{times}.PNG’) 其中times是第几次测试(for外的for)
Track_table = np.loadtxt("./TABLE/Track_table.v" , dtype=np.int32, delimiter=',') # 路径信息
for times in range(run_alltimes):
ax = draw_init(0)#定义画布
agent_track_init(ax, Track_table[times,0], Track_table[times,Qsize-1-1])#源目信息
for current in range(Qsize-1-1):#跳数比Qsize少1,线段比点少1
agent_track(ax, Track_table[times,current], Track_table[times,current+1])#依次绘制线段
plt.savefig(f'./Draw/pic{times}.PNG') # 与plt.show不能共存,还能写入不同的图里不要太爽
20.3.28 自闭
队友天天找我问bug。
1.tb里没有initial,rst没有复位,所有的信号都是x。Q无法工作
2.队友的clk周期是4,我是2。
3.队友的马虎,在路由器设计里,把NoC_Edge信号连接到Q模块的对应端口时
.Noc_Edge({edgeeast,edgewest,edgesouth,edgenorth,edgeup,edgedown}),杀了我吧,说好的独热码6‘b000001表示东,他给我整成6’b100000是东。全倒了过来。
查波形找信号。一个半小时。自闭。
以下为debug记录:
首先拿到bug工程,(他加了define到我的文件里,我并不知道,我拿到文件肯定会直接替换旧的Q文件夹)
我把仿真结果产生的路由表copy到python平台里,仿真得出结果,路由表是死循环。证明工程的确有问题。
然后看工程(还是没有initial,clk不对,修改)再跑,问题还在。
继续看tb,因为确定问题在tb里。随机寻找路由器的连线。发现没有问题。
所以,打开先前的Q网络工程,发现,两者的路由表不一样!因为Q网络R不同的原因(之前调试)所以修改旧Q的R值,和bug工程完全一样。并且从verilog写入txt,对比两个工程生成的R.txt,一样。但是,两者生成的路由表文件却不同。怪了
无奈,完全一样的环境,怎么会不一样?只好对着两个工程的波形图发愣。发现,bug工程的Q值传输的很原Q不一样。很大一部分都是0或者不变,正常的Q应该是一直在计算改变的。
继续找,一级一级查找信号,看Qmaxout这一级级传输在哪里断掉了。
灵光一现:看到NoC_Edge不对劲!0节点向上居然是边界!仔细看,全错了。最后找到病根。
开始撕逼。
20.3.29
鼓捣python验证中。
20.4.2 将R矩阵文件写入verilog文件里module的接口上
试试将R矩阵文件写入verilog里,有点麻烦。
verilog写入读出文件
verilog写入读出文件
$readmemh("../R_table_in.v",mem[0],0, 1);//只能写入mem类型的变量里。而且,要求每行一个数据,不能有逗号‘,’
r = $fread(file, mem[0], start, count);//感觉和上面的差不多感觉,还行,成功把存R矩阵的文件(一行6个数据,逗号分隔,一共27行)写入verilog文件里module的接口上。
//$fscanf(file,"%d%[^,]",mem)[1];//读文件的格式,这样也可以吧
//$fscanf(file,"%d,",mem1[1]);
//$fscanf(file,"%d,%d,%d,%d,%d,%d\n",mem2[5:0]);//这个好像不行,虽然长度相等;mem2[0]读到的是文本的第一个数据
file=$fopen("../R_table_in.v","r");
repeat(id+1)begin//多次读取以覆盖之前的数据,从而达到读取第几行的目的。如果是第二个路由器,就读第二行。毕竟是在被例化的模块里去读取各行,不那么容易。
$fscanf(file,"%d,%d,%d,%d,%d,%d\n",E,W,S,N,U,D);#只能读一行,以逗号分隔的六个数据.
end
$fclose(file);并行读入写出文件(通过#延时)还是一种蛮不错的办法。
20.4.2 关于python函数调用(跨文件)
如果每个调用的函数对应的py文件里都要读文件(txt)操作的话,注意,from……import……时,就会把引入的函数(以及之前的读操作,毕竟python是shell编程一句一句执行的)执行一次,(如果要读文件A但是该文件A不存在,即使你想在主函数里先生成这个文件A——晚于from……import……时)就会报错。
解决办法:在生成文件A的py文件里先生成一次,后续在主函数里再生成一次覆盖掉之前的数据即可。
Python 两个文件之间相互调用会出bug。
20.4.3 将verilog生成的路由表生成矩阵文件,以便np读取
很坑的是,np数组需要每行最后一个数据不能有逗号!(否则当成空的字符来处理而出错?)
另外,并行的子模块向同一个文件写入数据,可以通过#(ID)来延时仿真时间,从而让打印到文件的顺序是按自己的想法的。多个文件的多个task任务,仅第一个task延时即可(其他的延时了貌似又出问题了)
代码规范1
代码规范2
20.4.4 ifdef宏定义,En、多级堵塞
`define A string //居然可以宏定义字符串。
`ifdef QRouter_IDout730
`define Q_Target_Reward 730*1093 //797890=20bit二进制
`define QLearn_cnt_AllTime (729*4+`QLearn_cnt_RTime)
`else
`define Q_Target_Reward (`QRouter_ID-1)*1093
`define QLearn_cnt_AllTime (`QRouter_ID-1)*4+`QLearn_cnt_RTime//表示Q计算过程中的状态机,第0~QLearn_cnt_RTime 个clk更新R值,第2~(QLearn_cnt_AllTime-1)进行计算
`endifEn是数据包访问有效信号和读出的方向有效信号,一个状态机搞定(7个方向要7个状态机)。详见修正文档。
多级堵塞。原则是:
流量划等级=
R划程度
依据是延时
高一级延时T=低一级延时t*3+120.4.4 else-if 和else里嵌套if
真坑。elseif 和else里嵌套if
else begin//else里含if,必加begin-end,否则变成elseif 等级和if一样,只要满足elseif,就会覆盖if内容
if(R_ValueX==R_ValueY)//最后一步是终点的话,特别处理 优先级XYZ会出现死锁if else里嵌套if else-if 也要begin-end,不然结果又是惨不忍睹。
建议:begin-end if-else必备。
if if else (两个if和else同级也有问题)
20.4.6 Dijkstra、Floyd、bellman-ford、Spfa算法
20.4.6 Dijkstra
Dijkstra基础理解
Dijkstra python实现(个人感觉比较好)
Dijkstra python实现2
Dijkstra python实现3
20.4. 14 记忆网络来动态调节Q模块
准备学习做一个记忆网络来动态调节Q。
卷积
最后现实的写了一个减法器。每次规划后给R矩阵加堵塞权重,过了一个轮转后权重-1。卷积还是要看noc的时间表现。。目前也做不了卷积。
20.4. 15 金字塔类型的Q-routing的构想以及若干问题
1.关于底层学习后,得到Qmax中最小的作为R的量化值,给上层学习。
2.自适应问题,想每层都做成长宽高可以define的。
3.省路由表问题。如果9x9需要81个地址的路由表,我需要9+9个地址的路由表。但是操作起来很麻烦。
4.关于在过渡区域的路由器路由表方向问题,因为是自下而上的学习,只管自己区域的终点,虽然在最顶层一致,但是具体实现的时候效果并不好,可能会下层没法串联出一条通路。解决办法是,上层会纠正下层的边界,同时取下层的方向给临近上层(这样在头微片访问上层非目的区域内部时,内部也有一个准确的方向)
5.关于在学习的时候多花时间还是访问路由表的时候多花时间,两者的折衷考虑。关键点还是4.中的问题,在过渡区域(上层非目的区域时),头微片的访问,其实只有上层ID有效,其余的ID都是无用的。在过渡区域(中层非目的区域时),头微片的访问,其实只有中层ID有效,其余的ID都是无用的。在最后的一个底层区域内,底层ID才有效。(关于9+9+9的节省路由表)
一定要在define有数学运算时,加上括号!否则会发生意外。
generate 操作学习
generate 神操作
20.4. 关于Python的一些操作
pycharm查看每个变量
20.4.17 一些关于比赛科研的思考吧
1. 做了那么久的项目,其实只是把去年fpga的东西换成了一种类似IP的东西,能堆叠起很大的规模,很方便。从算法本质上。根本就没有什么大的改进。
2.指导老师一直想让我们做逼格高的算法,让我们做的项目和SCI的比较,我的天,我们垃圾算法怎么可能比的过。我知道要发SCI什么的好论文必须有好的对比才行。但是,连我们现在的项目都实现不了,(金字塔构想),我哪里有精力去想SCI复现的事情?我太累了,根本就不能完成这样的任务,如果给一个时间,我认为需要1个月去复现SCI的东西。而我们现在的项目算法都没有完成,太多问题了(我也纳闷了,做算法的就只剩——一直都只是我一个人),我踏马我很无奈好不好?我是个本科生ok?指导老师又不能给具体的实现细节,哪怕是一点点的想法也好啊,一个想,我真的只是一个平凡的人,最后成为码农,哪里有那么聪明去创新那么多东西。
3. 另外,想科研,的确是一直在和优秀的论文在比较。除了精进自己的能力,还要在意别人的做法。
4. 写了专利,也看到了很多以前看不到的东西。比如我们从软件Q-learning到硬件Qrouting的设计(尽管国外有个团队很早就实现了,只是自己找不到这个信息,自己又造轮子了,轮子略有不同而已),特点就是随机数探索(别人在强化学习其他领域怎么对随机数并行化处理,自己的创新在哪里),容错是自己原创的吗(不是原创但是创新的应用到这里,也是新颖的地方),多级堵塞别人怎么做的(自己的依赖于算法而让多级堵塞更优,说不上多级堵塞的创新)
5. 一定要知道自己在做什么东西!创新点是什么!别人做过这个了吗!
6. 一定要享受思考解决问题的过程!解决问题的成就感!写的HDL是一门艺术作品!
7. 做了要好好包装IP,以后就不用造轮子了。做了要好好反思,之前的架构有什么问题、写这个HDL的过程中犯了哪些错误。
生活还是充满期待的。只不过,充满荆棘。
20.4.18 Q模块作为基本,完善并例化出第二、三层Q模块,搭建金字塔
除了输入(R、Q值),输出routertable这俩暂时不动,中间的计算过程其实没什么区别就都例化了把。只不过,每个Q
模块的ID分别为三层。
20.4.19 记忆网络产生路由表,表现出活锁,人工智障。。
重要问题。大部分节点去1节点的时候,会死锁在3-12之间(活锁,不停循环)。debug ing.
发现了很多问题,版本控制,几个人之间的不一样;自己手里也有几个版本(最新的修正了很多问题,但是以前的没有修改,队友用的是有问题的代码,我拿到之后又重新改,把之前的覆盖了)
另外问题是,QlearnCnt最后一个clk的学习使能(以前少学了1clk)
软件验证的时候,宏定义输入为RtableOut(而不是RtableIn,队友可能用的是动态R,而自己的是静态R,用RtableIn)
对于一个always块里(时序控制)对一个变量,用两个并行的if判断,后者会覆盖前者的值(如果两次if都满足的话)
20.4.20 金字塔继续完善
上层纠正下层方向(如何纠正),下层反传输给上层方向,取最长的一层Qrouting完成一整个轮转(所有目的节点)为PyQcontrol开始的触发。因为需要提前储备好路由表。(无论是从路由表模块读取,还是本地重新记录,都需要存完备的路由表)
哎。接口上不能运算。难受
其实最关键是还是如何将一个很大的项目,合理的拆分为可以执行的一部分一部分的,有观测指标能验证的部分,这种能力很重要。
20.4.20 重挫
因为比不过DyXY算法而留下了眼泪。注入率0.05,全局平均注入包的情况下,DyXYZ优于记忆Q,优于Qrouting。
为此,开始了漫长的翻阅论文之路。突然发现很多注入率其实都不高,0.01~0.2,另外延时也蛮高的。
一个教训就是,要先看别人怎么做的,自己再做,别做出来了发现比别人差。那就凉凉了。
先学再做。调查,很重要!!
20.4.20 创新点
利于做成IP核。随意扩展大小。
能实时根据堵塞情况动态规划。其他dijkstra等原始只能对固定堵塞做规划。
1.random->分布式全学习。
2.用整数而非浮点数,用减法而非乘法。
3.对R矩阵合理删减,只留下可用的方向
4.对Q矩阵合理规划,削弱Q矩阵概念,reg实现。
5.分布式实现,在每个点进行学习。(每个点独立拥有R矩阵,Q矩阵:这个Q只保存到reg,并且下次规划时就失去记忆了,没有存储功能)(每个节点拥有Qmax)(每个节点拥有动作矩阵、路由表)
6.轮转设置目的节点,实现多目标学习。同时固定目标节点的最大值,从而大幅缩减收敛时间为网络节点数量*4。(因为每个节点处理需要4clk)
7.不需要设置起点,只依靠终点就能完整得到所有目标的路由表。缺点是终点附近太过集中。
8.多级堵塞。
记忆网络:能对已经规划的路径进行加权。从而使下一次路径规划不再选这条路。使结果稍微分散。均衡。
金字塔:
1.拥有聚集的功能,能大幅减少路由表的开销。
2.聚集功能大幅缩减了收敛时间。时间从节点数量3x3x3-1 变为 (3-1)+(3-1)+(3-1)。
在软件Python上:
1.软件模拟硬件仿真,生成路由表。(用于验证硬件生成路由表结果)
2.软件生成激励(R矩阵)
3.软件验证路由表结果,判断路径是否正确。(分为报告和图形验证)
20.4.21 记忆网络灾难:雪崩
记忆上次选择的路径,不能对R加权,只能对Q衰减。控制R就相当于选择了Q的流通方向。闭环变开环,控制不当,就会相互之间取Q衰减,最终导致整个网络Q崩溃。
20.4.21 金字塔中间设计测试完成
从纠正,反传输(以及中间的过度矩阵),到over信号传到routertable模块正确存入路由表,返回一个上次的动作给QsingleAction模块,信号正常。
20.4.21 routertable.v访问信号修改
在某些特殊的情况下,访问路由表的信号有效(高电平)后,返回的dir_valid_en=0,(说明得到的方向不是可用的)。此外有一种情况,在dir_valid_en=1时,返回的方向为0(0代表不是方向)(虽然我觉得没毛病,得不到有效方向,noc当然会重新访问,,但是队友吧感觉难搞,,所以我就把 在dir_valid_en=1时,返回的方向为0 这种情况改为了dir_valid_en=0。
6行代码的事情。。
assign Dir_E_ValidEn = Q_initial_End && Read_Dir_En && Best_Dir_E_r ? Dir_E_ValidEn_r:0;20.5.21 时隔一个月
偷牛去了,隔壁中兴算法大赛搞了一波,灰头土脸回来了。画了一波版图,最近又开始考试了,人生真难啊。
20.5.21 修改几层Q参数
包括Gate_clk_unit,Q_CMP,routertable,QbaseLv等关键性模块都需要重新设置选用哪一层参数(比如Q_learn_time,end_time,rotarytime,targetValue,这里信号名写的比较随意)
20.5.21 综合
3x3x3的noc综合通过。
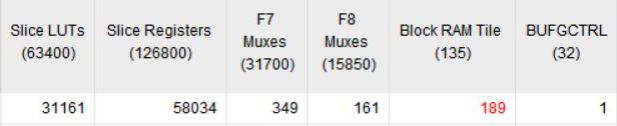
综合的资源如下,感觉用的还是蛮多的。因为noc用的fifo比较多,FIFO用IP核实现的(自然会用BRAM实现),而我使用Artix7-100T的器件模型跑的,所以有些捉襟见肘。

![]()
看起来,Q占的比重还是挺大的。大概占了路由器的1/3的样子。
20.5.21 vivado实现
这一步还没有做,但是想提个醒,前期约束不够的时候,或者顶层模块没有输入输出,实现时会自动优化很多单元,这时候需要单独设置一波。
Vivado综合没问题实现的时候却优化了很多资源,如何解决?
20.5.21 惊了
原来用了那么久的vivado,仿真居然是modelsim的,我还以为是自家的,哈哈哈。
1、选择vivado菜单“Tools”——>“Compile Simulation Libraries…”命令。
2、在弹出的对话框中设置器件库编译参数,仿真工百具“Simulator”选为ModelSim,语言“Language”、库“Library”、器件家族“Family”都为默认设置All(当然也可以根据自己的需求进行度设置),然后在“Compiled
library location”栏设置编译器件库的存放路径,这里选择新建的vivado2014_lib文件夹,此外专在“Simulator
executable path”栏设置Modelsim执行文件的路径,其他参数默认。
20.5.21 对于vivado添加新的芯片型号
我还是不会。
20.5.21 对于mem类型定义的时候需要常量
reg [7:0]mem[1:0]//两个8bit的mem。这里的1只能是常量,可以用define宏定义为1注意,常量只有两种声明方式:一是define,还有一种就是parameter也可以组合起来:
generate
if (Q_Lv==0)begin
`define QRouter_ID_define0 0
reg no =0;
end
endgenerate
`ifdef a
parameter QRouter_ID_define =`QRouter_ID_Lv0;
`elsif b
`define QRouter_ID_define `QRouter_ID_Lv1
`else
`define QRouter_ID_define `QRouter_ID_Lv2
`endif除此之外,在模块接口的地方用parameter也可以!!
generate不能只搭配define(末尾无分号,还需要再写一行)
generate里不能有parameter(禁止)
20.5.22
20.5.22 scanf函数会极高的占用运行内存
20.5.22 ASIC异步复位,FPGA同步复位
其实异步复位指的也是异步置位。对于FPGA来说,就算是异步也要多花面积等效为同步复位(不知道理解是否正确),否则时序未必收敛。
所以很难受了,以前的 posedge clk or negedge rst不能用了。(综合的时候会报warning最后失败)(其实直接去掉敏感信号,低电平同步复位也不是不是的哈)
20.5.22 RTL视图(不要加入综合后的网表信息,仿真巨慢)
20.5.23 小结:从一个全功能Qroute到通用(可例化成不同Qroute)
主要是parameter定义位宽,mem数量
还有generate if 来决定不同的实例化应该生成什么语句。
20.5.23 if-else if -else和if -if -if的区别
if-else if -else 会生成一个同优先级的MUX(多输入的MUX)
if -if -if (平行结构)会生成一个不同优先级的MUX(2输入)最后的一个if优先级最高,在最后一级。
20.5.23 因为综合闹出的毛病
1.由于复制了工程,自带的“副本”二字,导致综合失败。vivado综合(以及RTL)时,文件路径不能有中文/日文名。所以这也是一年前电脑RTL闪退的原因?重装系统才好的。
2.Gate_clk_unit 把always@(posedge clk_Q or negedge sysrst or negedge Q_learn_En)
换成always@(posedge clk_Q ) 导致其他后续的模块连线出现问题(直接没有了)
但是这里想说一下,FPGA主要用同步复位,ASIC用异步逻辑。FPGA如果用异步复位还要考虑是否满足撤销和恢复的时序关系。(我感觉他可能是中间插入了DFF,把异步当成同步处理的)
20.5.23 修正DyXY算法
这个算法的确要考虑R值的比较,但是这个是第二步。(R指堵塞程度)
第一步应该是比较还有几个方向可以走。(如果是3D的最多3个方向。DyXY不能绕路是最短路由算法)如果有一个坐标已经和目标节点相同,那么就只能在余下的两个方向里选(根据R选)。而不是一上来就比R大小。
20.5.30 主要是Q连线
协商好上层Q的连线。
对于某些节点学三层Q,这个正常,但是某些节点只学1、2层Q,其他的部分路由表是空的,这个必须解决。
所以构想卡着start_adjust的时间(刚刚一次Q学习结束时)开始把多层学习的原始方向送给区域的其他节点。(通过para接口判断是否是多层学习节点,这也决定了要写一个arbiter,来裁决PyQcontrol的方向来源是其他节点还是本节点)
由于模块组织很大可能布线延时太长,所以这个送方向还是要好好考虑一下。
20.5.31 错误的软件验证
最初没有设计好,按每8个路由分成一组,这一组会将路由表写入一个文件里。但是有很多个这样的组,导致最后结果都写到一个文件里,这样无法复原出完整的路由表(即只有第一组有效,其他的底层路由组结果凭空消失了)
看来只能在生成路由表时,做手脚了。
(python都写好了三个层,判断在哪一层选哪个区的路由表,但是这种只对有唯一路由表的有效啊)
20.5.31 关于仿真
wait(电平触发)
@(边沿触发)
这两种都不可综合。但是在仿真中可以极大提高效率。(模拟输入)
深刻意识到了VLSI 的UVM仿真的重要性。
太难了。
现在就是模拟数据包申请方向,遍历每个目的节点读出数据然后写入硬盘文件中。
20.6.1 队友沟通
bug一片不忍直视。
队友负责连线,我在搞内部的东西。
这两天也是感觉任务很重。虽然不是什么特别硬的,就是活儿多。
top连线,router规范,都耗时间啊。
信号名的大小写不对应,命名规则等!
20.6.1 龟速仿真
例化了512个模块,仿真用了7分钟。
set_param general.maxThreads 6 之后缩短到2分半。
引用:加快modelsim仿真速度的方法(原创)
减小仿真时钟精度能提高1倍仿真速度。
20.6.3 重复打印的问题
很魔性。明明只有router==0才能打印一次,居然打印了四次。
找了一整天的bug。最后和队友一起看代码。
我一直忽视的warning。6bit被截断。是问题所在。
因为2^6=64,但是我们却在top例化的时候到了512,这样就导致了重复了4次以上的节点(被截断的位宽8bit被当成了6bit,所以有4个router==0。打印了4次)
哎。
队友交流啊。
20.6.6不要在文件目录里出现空格
会导致工程仿真的时候抽疯,找不到这个工程文件。
20.6.7 vivado如何读取以前的wave配置文件
以前的工程崩溃了,只能重新建立一个工程,以前辛辛苦苦配置的波形不见了怎么办?
点击Vivado的菜单栏中的 File -> simulation waveform ->Open Configuration,选择我们之前保存的
.WCFG文件即可恢复上一次的仿真结果
加入之后,选择file->simulation waveform ->save as ->然后选择加入工程即可
20.6.8 三层Q之间的纠正与传输
很难受。
req模块的dir也有问题(en写错了,lv0的写成了lv1的en)
纠正和反传输的模型都太简单了。真的应该先做一个软件代码来验证的。simulate太慢了。
纠正的话要独立纠正。给出纠正信号用来反传输。(纠正的来源的两处,lv2\lv1分开;反传输也是两处来源,由是否有纠正信号决定,有纠正就用纠正的dir来反传输)
解决了内部的细节,宏定义2但实际上要-1(这些忘记考虑),以及纠正lv1却判断lv2是否在边界这些弱智问题。。
20.6.17 关于IP
使用IP的时候,如果代码是别人的,自己复制过来的时候/器件更换之后,IP是被锁定的,选择IP,右键-upgrade,然后确定。
如果是fifo的话,建议用globl模式的(前面没有方框),局部的话(前面是黄色方框)
20.6.19 实验
明天就交报告了,现在还在做实验。
二代和三代,2d和3d,鱼龙混杂,搞蒙了。工程一大堆,各个版本的交织起来,苦不堪言。
用python生成top连线。(这个脚本也太多版本了)
用Python生成injector(表示堵塞的环境)。然后从0-63发包。
三代2d的测试都做好了,二代2d的对比对象DyXY还没有做好,最后才发现两代reqID方式不同,一个是xyz,一个是Lv012。(在3d的时候,333的xyz的确和333的lv012相同,表示64号节点)
居然还有位宽问题。QintialCnt设置的6bit只能到63,当规模为63时,Cnt>65才能完成初始化。难受了
基本上结束
写了2W字的设计报告、项目简介、海报、ppt、项目复盘,总结创新点,这所有的事情都让自己对项目有了更深的理解,(当然是套话,本来就理解了,只不过做了很久自己都忘了)最关键的是如何去表达一个很技术的项目,这样的汇报非常的锻炼人,除了对项目的理解,还有不断总结精炼词句(让别人听懂的那种)(还不能很low)
啊,晋级华东赛区复赛了,就这样吧,得准备找工作了,加油!