Python语音基础操作--2.2语音编辑
《语音信号处理试验教程》(梁瑞宇等)的代码主要是Matlab实现的,现在Python比较热门,所以把这个项目大部分内容写成了Python实现,大部分是手动写的。使用CSDN博客查看帮助文件:
Python语音基础操作–2.1语音录制,播放,读取
Python语音基础操作–2.2语音编辑
Python语音基础操作–2.3声强与响度
Python语音基础操作–2.4语音信号生成
Python语音基础操作–3.1语音分帧与加窗
Python语音基础操作–3.2短时时域分析
Python语音基础操作–3.3短时频域分析
Python语音基础操作–3.4倒谱分析与MFCC系数
Python语音基础操作–4.1语音端点检测
Python语音基础操作–4.2基音周期检测
Python语音基础操作–4.3共振峰估计
Python语音基础操作–5.1自适应滤波
Python语音基础操作–5.2谱减法
Python语音基础操作–5.4小波分解
Python语音基础操作–6.1PCM编码
Python语音基础操作–6.2LPC编码
Python语音基础操作–6.3ADPCM编码
Python语音基础操作–7.1帧合并
Python语音基础操作–7.2LPC的语音合成
Python语音基础操作–10.1基于动态时间规整(DTW)的孤立字语音识别试验
Python语音基础操作–10.2隐马尔科夫模型的孤立字识别
Python语音基础操作–11.1矢量量化(VQ)的说话人情感识别
Python语音基础操作–11.2基于GMM的说话人识别模型
Python语音基础操作–12.1基于KNN的情感识别
Python语音基础操作–12.2基于神经网络的情感识别
Python语音基础操作–12.3基于支持向量机SVM的语音情感识别
Python语音基础操作–12.4基于LDA,PCA的语音情感识别
代码可在Github上下载:busyyang/python_sound_open
信号相加
读取了语音信号之后可以看到是一个一维数组,可以直接通过一维数组(列表)的形式进行操作。在两个序列长度不一样时候,可以在短的一个序列后补零。
class soundBase:
def __init__(self, path):
self.path = path
def sound_add(self, data1, data2):
if len(data1) < len(data2):
tmp = np.zeros([len(data2)])
for i in range(len(data1)):
tmp[i] += data1[i]
return tmp + data2
elif len(data1) > len(data2):
tmp = np.zeros([len(data1)])
for i in range(len(data2)):
tmp[i] += data2[i]
return tmp + data1
else:
return data1 + data2
卷积
卷积是一个常用的计算,两个序列 x 1 , x 2 x_1,x_2 x1,x2的卷积表达式为:
y ( n ) = ∑ k = − ∞ ∞ x 1 ( k ) x 2 ( n − k ) y(n)=\sum\limits_{k=-\infty}^{\infty}x_1(k)x_2(n-k) y(n)=k=−∞∑∞x1(k)x2(n−k)
对于离散信号来说:
y ( n ) = ∑ k = 0 N x 1 ( k ) x 2 ( n − k ) y(n)=\sum\limits_{k=0}^{N}x_1(k)x_2(n-k) y(n)=k=0∑Nx1(k)x2(n−k)
计算方式可以参考一维信号的卷积认识
采样频率的转化
采样频率的转化是为了做升采样和降采样。降采样是对序列 x ( n ) x(n) x(n)间隔 D − 1 D-1 D−1个点进行抽取:
x D ( m ) = x ( D m ) (抽取) x_D(m)=x(Dm)\tag{抽取} xD(m)=x(Dm)(抽取)
其中 D D D为正整数。为了米面抽取序列后频谱混叠,通常在抽取前将信号通过一个抗混叠滤波器。
内插就是在原序列的样本点之间插入 I − 1 I-1 I−1个值,原始序列为 x ( n ) x(n) x(n),内插后的序列为 x I ( m ) x_I(m) xI(m)
x I ( m ) = { x ( m I ) , m = 0 , ± I , ± 2 I . . . 0 , o t h e r s (内插) x_I(m)=\left\{\begin{array}{ll} x(\frac{m}{I})&,m=0,±I,±2I...\\ 0&,others \end{array}\right.\tag{内插} xI(m)={x(Im)0,m=0,±I,±2I...,others(内插)
内插之后,通过低通滤波器,移植混叠信号。
在matlab中都可以通过resample函数来进行,通过配置参数的不同即可。在python的实现中,利用audiowrite的参数fs来实现,在读取信号的时候,输出fs,然后对fs进行变化后写入。
class soundBase:
def __init__(self, path):
self.path = path
def audiowrite(self, data, fs, binary=True, channel=1, path=[]):
if binary:
wf = wave.open(self.path, 'wb')
wf.setframerate(fs)
wf.setnchannels(channel)
wf.setsampwidth(2)
wf.writeframes(b''.join(data))
else:
if len(path) == 0:
path = self.path
wavfile.write(path, fs, data)
def audioread(self, formater='sample'):
"""
读取语音文件
2020-2-26 Jie Y. Init
这里的wavfile.read()函数修改了里面的代码,返回项return fs, data 改为了return fs, data, bit_depth
如果这里报错,可以将wavfile.read()修改。
:param formater: 获取数据的格式,为sample时,数据为float32的,[-1,1],同matlab同名函数. 否则为文件本身的数据格式
指定formater为任意非sample字符串,则返回原始数据。
:return: 语音数据data, 采样率fs,数据位数bits
"""
fs, data, bits = wavfile.read(self.path)
if formater == 'sample':
data = data / (2 ** (bits - 1))
return data, fs, bits
sb = soundBase('C2_2_y.wav')
data, fs = sb.audioread()
sb_cc = soundBase('C2_2_y_conved_2.wav')
sb_c.audiowrite(data, fs * 2)
加法与卷积示例
from soundBase import soundBase
from random import randint, random
import matplotlib.pyplot as plt
import numpy as np
# 2.2 练习1
sb = soundBase('C2_2_y.wav')
# 读取语音
'''
这里的wavfile.read()函数修改了里面的代码,返回项return fs, data 改为了return fs, data, bit_depth
如果这里报错,可以将wavfile.read()修改。
:param formater: 获取数据的格式,为sample时,数据为float32的,[-1,1],同matlab同名函数. 否则为文件本身的数据格式
指定formater为任意非sample字符串,则返回原始数据。
:return: 语音数据data, 采样率fs,数据位数bits
'''
data, fs, nbits = sb.audioread()
print(fs)
max_data = max(data)
noise = [random() * 0.1 for i in range(len(data))]
fixed2 = sb.sound_add(data, noise)
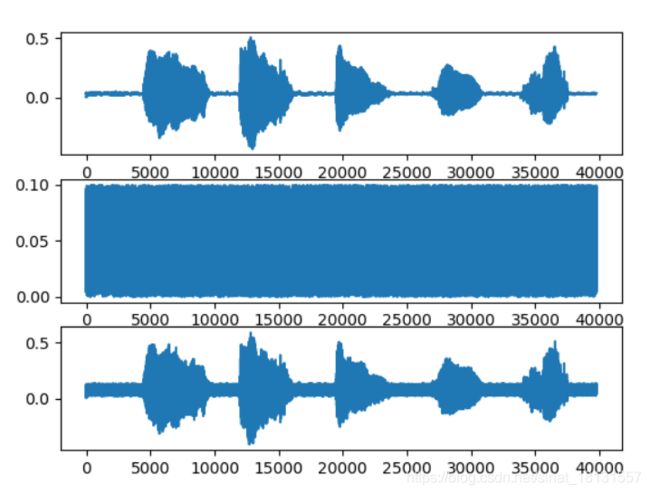
plt.subplot(311)
plt.plot(data)
plt.subplot(312)
plt.plot(noise)
plt.subplot(313)
plt.plot(fixed2)
plt.show()
sb_f = soundBase('C2_2_y_noised.wav')
sb_f.audiowrite(fixed2, fs)
# sb_f.audioplayer()
# 2.2 练习2
conved = np.convolve(data, noise, 'same')
sb_c = soundBase('C2_2_y_conved.wav')
sb_c.audiowrite(conved, fs)
# sb_c.audioplayer()
# 2.2 练习3
plt.subplot(211)
x = [i / fs for i in range(len(data))]
plt.plot(x, data)
sb_cc = soundBase('C2_2_y_conved_2.wav')
sb_c.audiowrite(data, fs * 2)
'''
这里的wavfile.read()函数修改了里面的代码,返回项return fs, data 改为了return fs, data, bit_depth
如果这里报错,可以将wavfile.read()修改。
:param formater: 获取数据的格式,为sample时,数据为float32的,[-1,1],同matlab同名函数. 否则为文件本身的数据格式
指定formater为任意非sample字符串,则返回原始数据。
:return: 语音数据data, 采样率fs,数据位数bits
'''
data, fs_, nbits = sb_c.audioread()
x = [i / fs_ for i in range(len(data))]
print(fs_)
plt.subplot(212)
plt.plot(x, data)
plt.show()
相加的结果:
卷积的结果:
