python - 机器学习lightgbm相关实践
相关文章:
R+python︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
python︱sklearn一些小技巧的记录(训练集划分/pipelline/交叉验证等)
GBDT一个藤上,进化的xgb以及lgb。
比较好的几则练习代码:
- QLMX/data_mining_models
- Anfany/Machine-Learning-for-Beginner-by-Python3
文章目录
- 0 相关理论
- 0.1 内存更小
- 0.2 速度更快
- 0.3 直接支持类别特征(即不需要做one-hot编码)
- 0.4 LightGBM参数调优
- 0.5 调参经验
- 0.6 安装
- 1 二分类参数选择
- 2 多分类参数选择
- 3 回归任务参数设置
- 3.1 案例一
- 3.2 案例二
- 4 其他相关
- 4.1 Spark - LightGBM
- 4.2 LightGBM比赛里用的很多,为何公司里很少?
- 5 排序算法&LightGBM
- 5.1 案例一
- 5.2 案例二
0 相关理论
GDBT模型、XGBoost和LightGBM之间的区别与联系
0.1 内存更小
XGBoost 使用预排序后需要记录特征值及其对应样本的统计值的索引,而 LightGBM 使用了直方图算法将特征值转变为 bin 值,且不需要记录特征到样本的索引,将空间复杂度从 [公式] 降低为 [公式] ,极大的减少了内存消耗;
LightGBM 采用了直方图算法将存储特征值转变为存储 bin 值,降低了内存消耗;
LightGBM 在训练过程中采用互斥特征捆绑算法减少了特征数量,降低了内存消耗。
0.2 速度更快
LightGBM 采用了直方图算法将遍历样本转变为遍历直方图,极大的降低了时间复杂度;
LightGBM 在训练过程中采用单边梯度算法过滤掉梯度小的样本,减少了大量的计算;
LightGBM 采用了基于 Leaf-wise 算法的增长策略构建树,减少了很多不必要的计算量;
LightGBM 采用优化后的特征并行、数据并行方法加速计算,当数据量非常大的时候还可以采用投票并行的策略;
LightGBM 对缓存也进行了优化,增加了 Cache hit 的命中率。
对比优势:
- 更快的训练效率,速度较快,是XGBoost速度的16倍,内存占用率为XGBoost的1/6
- 低内存使用
- 更好的准确率(我对比 XGBoost 没太大差别)
- 支持并行学习
- 可处理大规模数据
缺点:
1)可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合
2)基于偏差的算法,会对噪点较为敏感
3)在寻找最优解时,依据的最优切分变量,没有将最优解是全部特征的综合这一理念来考虑
-
- 树的切分策略不同:XGB 是 level-wise,而 LGB 是leaf-wise。level-wise 的建树方式对当前层的所有叶节点一视同仁,有些叶节点的分裂收益很小仍然需要进行分裂,增加了计算代价。leaf-wise 方式的精度更高,但容易过拟合,所以要控制树的最大深度。
-
- 在选择数据分割点时:XGB 是通过预排序的方式,空间消耗较大;LGB是通过直方图算法,不需要进行预排序,内存占用更低。
-
- 在并行策略上,XGB 主要集中在特征并行上,而 LGB 的并行策略包含特征并行、数据并行和投票并行(Data parallel,Feature parallel, Voting parallel)。
Level-wise和Leaf-wise
Level-wise:
在XGBoost中,树是按层生长的,称为Level-wise tree growth,同一层的所有节点都做分裂,最后剪枝,
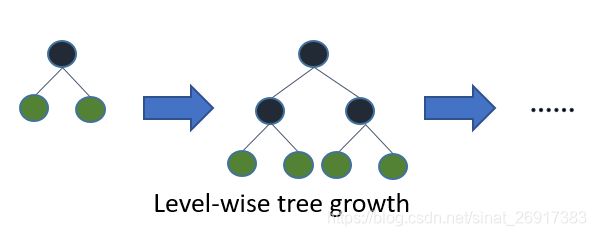
在Histogram算法之上,LightGBM进行进一步的优化,采用的Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。

LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合
0.3 直接支持类别特征(即不需要做one-hot编码)
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征,转化到多维的one-hot编码特征,降低了空间和时间的效率。
而类别特征的使用是在实践中很常用的。
基于这个考虑,LightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的one-hot编码展开。并在决策树算法上增加了类别特征的决策规则。
在Expo数据集上的实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。

0.4 LightGBM参数调优
LightGBM实战总结



0.5 调参经验
LightGBM实战总结

下表对应了Faster Spread,better accuracy,over-fitting三种目的时,可以调整的参数

0.6 安装
中文文档:
https://lightgbm.apachecn.org/#/docs/3
依赖:
pip install setuptools wheel numpy scipy scikit-learn -U
为了验证是否安装成功, 可以在 Python 中 import lightgbm 试试:
import lightgbm as lgb
1 二分类参数选择
【lightgbm, xgboost, nn代码整理一】lightgbm做二分类,多分类以及回归任务(含python源码)
官方参数文档
参数的选择:
params = {'num_leaves': 60, #结果对最终效果影响较大,越大值越好,太大会出现过拟合
'min_data_in_leaf': 30,
'objective': 'binary', #二分类,定义的目标函数
'max_depth': -1,
'learning_rate': 0.03,
"min_sum_hessian_in_leaf": 6,
"boosting": "gbdt",
"feature_fraction": 0.9, #提取的特征比率
"bagging_freq": 1,
"bagging_fraction": 0.8,
"bagging_seed": 11,
"lambda_l1": 0.1, #l1正则
# 'lambda_l2': 0.001, #l2正则
"verbosity": -1,
"nthread": -1, #线程数量,-1表示全部线程,线程越多,运行的速度越快
'metric': {'binary_logloss', 'auc'}, ##二分类,评价函数选择
"random_state": 2019, #随机数种子,可以防止每次运行的结果不一致
# 'device': 'gpu' ##如果安装的事gpu版本的lightgbm,可以加快运算
}
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
prob_oof = np.zeros((train_x.shape[0], ))
test_pred_prob = np.zeros((test.shape[0], ))
## train and predict
feature_importance_df = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train)):
print("fold {}".format(fold_ + 1))
trn_data = lgb.Dataset(train_x.iloc[trn_idx], label=train_y[trn_idx])
val_data = lgb.Dataset(train_x.iloc[val_idx], label=train_y[val_idx])
clf = lgb.train(params,
trn_data,
num_round,
valid_sets=[trn_data, val_data],
verbose_eval=20,
early_stopping_rounds=60)
prob_oof[val_idx] = clf.predict(train_x.iloc[val_idx], num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = features
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
test_pred_prob += clf.predict(test[features], num_iteration=clf.best_iteration) / folds.n_splits
threshold = 0.5
for pred in test_pred_prob:
result = 1 if pred > threshold else 0
目标函数采用的是binary,评价函数采用的是{'binary_logloss', 'auc'},可以根据需要对评价函数做调整,可以设定一个或者多个评价函数;'num_leaves'对最终的结果影响较大,如果值设置的过大会出现过拟合现象。
常用的5折统计有两种:StratifiedKFold和KFold,其中最大的不同是StratifiedKFold分层采样交叉切分,确保训练集,测试集中各类别样本的比例与原始数据集中相同,实际使用中可以根据具体的数据分别测试两者的表现。
2 多分类参数选择
【lightgbm, xgboost, nn代码整理一】lightgbm做二分类,多分类以及回归任务(含python源码)
官方参数文档
params = {'num_leaves': 60,
'min_data_in_leaf': 30,
'objective': 'multiclass', # 多分类需要注意
'num_class': 33, # 多分类需要注意
'max_depth': -1,
'learning_rate': 0.03,
"min_sum_hessian_in_leaf": 6,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.8,
"bagging_seed": 11,
"lambda_l1": 0.1,
"verbosity": -1,
"nthread": 15,
'metric': 'multi_logloss', # 多分类需要注意
"random_state": 2019,
# 'device': 'gpu'
}
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
prob_oof = np.zeros((train_x.shape[0], 33))
test_pred_prob = np.zeros((test.shape[0], 33))
## train and predict
feature_importance_df = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train)):
print("fold {}".format(fold_ + 1))
trn_data = lgb.Dataset(train_x.iloc[trn_idx], label=train_y.iloc[trn_idx])
val_data = lgb.Dataset(train_x.iloc[val_idx], label=train_y.iloc[val_idx])
clf = lgb.train(params,
trn_data,
num_round,
valid_sets=[trn_data, val_data],
verbose_eval=20,
early_stopping_rounds=60)
prob_oof[val_idx] = clf.predict(train_x.iloc[val_idx], num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = features
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
test_pred_prob += clf.predict(test[features], num_iteration=clf.best_iteration) / folds.n_splits
result = np.argmax(test_pred_prob, axis=1)
3 回归任务参数设置
3.1 案例一
【lightgbm, xgboost, nn代码整理一】lightgbm做二分类,多分类以及回归任务(含python源码)
官方参数文档
params = {'num_leaves': 38,
'min_data_in_leaf': 50,
'objective': 'regression', # 回归设置
'max_depth': -1,
'learning_rate': 0.02,
"min_sum_hessian_in_leaf": 6,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.7,
"bagging_seed": 11,
"lambda_l1": 0.1,
"verbosity": -1,
"nthread": 4,
'metric': 'mae', # 回归设置
"random_state": 2019,
# 'device': 'gpu'
}
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / (y_true))) * 100
def smape_func(preds, dtrain):
label = dtrain.get_label().values
epsilon = 0.1
summ = np.maximum(0.5 + epsilon, np.abs(label) + np.abs(preds) + epsilon)
smape = np.mean(np.abs(label - preds) / summ) * 2
return 'smape', float(smape), False
folds = KFold(n_splits=5, shuffle=True, random_state=2019)
oof = np.zeros(train_x.shape[0])
predictions = np.zeros(test.shape[0])
train_y = np.log1p(train_y) # Data smoothing
feature_importance_df = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_x)):
print("fold {}".format(fold_ + 1))
trn_data = lgb.Dataset(train_x.iloc[trn_idx], label=train_y.iloc[trn_idx])
val_data = lgb.Dataset(train_x.iloc[val_idx], label=train_y.iloc[val_idx])
clf = lgb.train(params,
trn_data,
num_round,
valid_sets=[trn_data, val_data],
verbose_eval=200,
early_stopping_rounds=200)
oof[val_idx] = clf.predict(train_x.iloc[val_idx], num_iteration=clf.best_iteration)
fold_importance_df = pd.DataFrame()
fold_importance_df["Feature"] = features
fold_importance_df["importance"] = clf.feature_importance()
fold_importance_df["fold"] = fold_ + 1
feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0)
predictions += clf.predict(test, num_iteration=clf.best_iteration) / folds.n_splits
print('mse %.6f' % mean_squared_error(train_y, oof))
print('mae %.6f' % mean_absolute_error(train_y, oof))
result = np.expm1(predictions) #reduction
result = predictions
在回归任务中对目标函数值添加了一个log平滑,如果待预测的结果值跨度很大,做log平滑很有很好的效果提升。
3.2 案例二
LightGBM_Regression_pm25案例
def Train(data, modelcount, censhu, yanzhgdata):
model = lgbm.LGBMRegressor(boosting_type='gbdt', objective='regression', num_leaves=1200,
learning_rate=0.17, n_estimators=modelcount, max_depth=censhu,
metric='rmse', bagging_fraction=0.8, feature_fraction=0.8, reg_lambda=0.9)
model.fit(data[:, :-1], data[:, -1])
# 给出训练数据的预测值
train_out = model.predict(data[:, :-1])
# 计算MSE
train_mse = mse(data[:, -1], train_out)
# 给出验证数据的预测值
add_yan = model.predict(yanzhgdata[:, :-1])
# 计算MSE
add_mse = mse(yanzhgdata[:, -1], add_yan)
print(train_mse, add_mse)
return train_mse, add_mse
4 其他相关
4.1 Spark - LightGBM
参考:实战!LightGBM算法原理、训练与预测
原生的Spark版本的LightGBM算法集成在了微软的开源项目MMLSPARK(Microsoft Machine Learning for Apache Spark),该项目是微软在认知工具包(Microsoft Cognitive Toolkit,曾用名 CNTK)的基础上开发的基于Apache Spark大数据框架的实现,由于mmlspark集成了大量了机器学习和深度学习算法,导致依赖该项目的maven后,项目打的jar包巨大(400M+),因此,需要对mmlspark项目进行一定阉割,只保留LightGBM算法(分类,回归均支持)进行重新编译。
笔者在进行预测代码的开发中,踩了好多坑,一把辛酸泪。尝试了不同的预测打分方式,这其中包括了PMML解决方案、MMLSPARK原生预测解决方案以及Java重构的预测解决方案。最终选择了java重构的预测解决方案,放弃前两种解决方案的原因如下:
1、PMML的解决方案会有一定的打分误差,并打分耗时不太满足当前业务
2、MMLSPARK原生预测解决方案中代码依赖了底层的C++动态链接库,并且预测代码有一定的优化空间,打分耗时巨大(每次打分都需要重新初始化C++依赖的一些数据对象)
4.2 LightGBM比赛里用的很多,为何公司里很少?
https://www.zhihu.com/question/344433472/answer/959927756
LightGBM在所有大厂里有会用到,你所说的很少大概是指线上模型?据我所知只有美团和阿里有部分线上模型是用了改进版的Lightgbm在做排序,结合了pair-wise损失。但是用的最多的还是离线模型效果,因为原生的lightgbm虽然使用了缓存加速和直方图做差,不用预排序存储了,但不支持扩展。
这意味着,在超大规模数据集用lightgbm是很不明智的,也不会有公司直接使用。
更多的是来快速地验证数据、想法是否正确可行,是很多团队都会先抽小规模的数据用LightGBM跑一遍,有效果了再做深度模型和算法改进。
最后一点,lightGBM虽然直接支持分类变量,也可以输出分桶,但是特征工程还是非常重要的,也需要一定时间调参。这算不上什么创新应用,自然没有公司刻意推崇。
作者:图灵的猫
链接:https://www.zhihu.com/question/344433472/answer/959927756
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
5 排序算法&LightGBM
5.1 案例一

参考:https://lightgbm.apachecn.org/#/docs/5
Below are two rows from MSLR-WEB10K dataset:
0 qid:1 1:3 2:0 3:2 4:2 … 135:0 136:0
2 qid:1 1:3 2:3 3:0 4:0 … 135:0 136:0
5.2 案例二
lightgbm用于排序
jiangnanboy/learning_to_rank
1.raw_train.txt
0 qid:10002 1:0.007477 2:0.000000 ... 45:0.000000 46:0.007042 #docid = GX008-86-4444840 inc = 1 prob = 0.086622
0 qid:10002 1:0.603738 2:0.000000 ... 45:0.333333 46:1.000000 #docid = GX037-06-11625428 inc = 0.0031586555555558 prob = 0.0897452 ...
模型的参数:
train params = {
'task': 'train', # 执行的任务类型
'boosting_type': 'gbrt', # 基学习器
'objective': 'lambdarank', # 排序任务(目标函数)
'metric': 'ndcg', # 度量的指标(评估函数)
'max_position': 10, # @NDCG 位置优化
'metric_freq': 1, # 每隔多少次输出一次度量结果
'train_metric': True, # 训练时就输出度量结果
'ndcg_at': [10],
'max_bin': 255, # 一个整数,表示最大的桶的数量。默认值为 255。lightgbm 会根据它来自动压缩内存。如max_bin=255 时,则lightgbm 将使用uint8 来表示特征的每一个值。
'num_iterations': 200, # 迭代次数,即生成的树的棵数
'learning_rate': 0.01, # 学习率
'num_leaves': 31, # 叶子数
'max_depth':6,
'tree_learner': 'serial', # 用于并行学习,‘serial’: 单台机器的tree learner
'min_data_in_leaf': 30, # 一个叶子节点上包含的最少样本数量
'verbose': 2 # 显示训练时的信息
}