【学习】web data mining(Second Edition)——(2)
web数据挖掘(第二版)——探索超链接、内容和使用数据
阅读的英文原版,这里借助有道翻译阅读
作者简介:Bing Liu 刘兵,伊利诺伊大学芝加哥分校(UIC)教授,他在爱丁堡大学获得人工智能博士学位。刘兵教授是Web挖掘研究领域的国际知名专家,在Web内容挖掘、互联网观点挖掘、数据挖掘等领域有非常高的造诣,他先后在国际著名学术期刊与重要国际学术会议(如KDD、WWW、AAAI、SIGIR、ICML、TKDE等)上发布关于数据挖掘、Web挖掘和文本挖掘论文一百多篇。刘兵教授担任过多个国际期刊的编辑,也是多个国际学术会议(如WWW、KDD与AAAI等)的程序委员会委员。更多的信息,可访问他的个人主页http://www.cs.uic.edu/~liub (来自豆瓣,侵删)
1、关联规则和顺序模式
关联规则是数据中一类重要的规则。关联规则挖掘是一项基本的数据挖掘任务。它可能是数据库和数据挖掘社区发明和广泛研究的最重要的模型。它的目标是在数据项之间找到所有的共现关系(称为关联)。自1993年Agrawal等人首次提出[2]以来,它吸引了大量的关注。许多有效的算法、扩展和应用程序已经被报道。
关联规则挖掘的经典应用是市场购物篮数据分析,它的目的是发现顾客在超市(或商店)购买的商品是如何关联的。关联规则的一个例子是:
Cheese —> Beer [support = 10%, confidence = 80%].
规则规定,10%的顾客同时购买奶酪和啤酒,购买奶酪的顾客80%的时间也购买啤酒。支持和信心是衡量规则强度的两个指标,我们将在后面定义。
这种挖掘模型实际上非常普遍,可以在许多应用中使用。例如,在Web和文本文档的上下文中,它可以用来查找单词的共现关系和Web使用模式,我们将在后面的章节中看到这一点。
然而,关联规则挖掘不考虑购买项的顺序。顺序模式挖掘可以解决这个问题。顺序模式的一个例子是“5%的顾客先买床,然后买床垫,再买枕头”。这些物品不是同时购买的,而是一个接一个购买的。在Web使用挖掘中,这些模式对于分析服务器日志中的点击流非常有用。它们也有助于从自然语言文本中发现语言或语言模式。
2.1 关联规则的基本概念
挖掘关联规则的问题可以表述为:设I ={i1, i2,…,im}为一组项。设T = (t1, t2,…,tn)是一组事务(数据库),其中每个事务ti ⊆ I。关联规则是表单的含义:
![]()
X(或Y)是一组项,称为项集
例1:我们想分析超市中出售的商品是如何相互关联的。I是超市出售的所有商品的集合。事务就是客户在购物篮中购买的一组商品。例如,一个事务可能是:
{牛肉、鸡肉、奶酪},
这意味着顾客在一个篮子里买了三样东西,牛肉、鸡肉和奶酪。关联规则可以是:
牛肉、鸡肉 —> 奶酪
其中{牛肉、鸡肉}为X,{奶酪}为y,为简单起见,事务和规则中通常省略括号“{”和“}”。
据说事务tiT包含itemset X,如果X是一个子集的ti(我们也说itemset X覆盖ti)。T中X的支持计数(用X.count表示)是包含X的T中事务的数量。
如果X是ti的子集,则事务ti∈T被称为包含一个itemset X(我们还说itemset X覆盖了ti)。T中X的支持计数(用X.count表示)是包含X的T中事务的数量。
支持度:规则X∪Y的支持度,是T中包含X -> Y的事务的百分比,可以看作概率的估计值Pr(X∪Y)。因此,规则支持决定了规则在事务集T中应用的频率。
规则X -> Y的支持度计算如下:

支持度是一个有用的度量标准,因为如果支持度太低,规则可能只是偶然发生的。此外,在业务环境中,覆盖太少情况(或事务)的规则可能没有用处,因为按照这样的规则行事没有商业意义(没有利润)。
置信度:规则X -> Y的置信度是包含X也包含Y的T中事务的百分比,可以看作是条件概率Pr(Y | X)的估计值,计算如下:
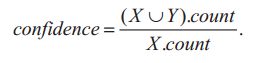
因此,信心决定了规则的可预测性。如果规则的置信度过低,就不能可靠地从x推断或预测Y。
目的:给定事务集T,挖掘关联规则的问题是发现T中所有支持度和置信度大于或等于用户指定的最小支持度(minsup)和最小置信度(minconf)的关联规则。这里的关键字是“全部”,即,关联规则挖掘完成。以前用于规则挖掘的方法通常只根据各种启发式生成规则子集(参见第3章)。
例2:图2.1显示了一组7个事务。每笔交易都是顾客在商店购物篮中购买的一组商品。set I是商店里销售的所有商品的集合。
t1:牛肉,鸡肉,牛奶
t2:牛肉、奶酪
t3:奶酪、靴子
t4:牛肉、鸡肉、奶酪
t5:牛肉,鸡肉,衣服,奶酪,牛奶
t6:鸡肉,衣服,牛奶
t7:鸡肉,牛奶,衣服
给定用户指定的minsup = 30%和minconf = 80%,下面的关联规则(sup是支持,conf是置信度)
鸡,衣服->牛奶[sup = 3/7, conf = 3/3]
为有效,支持度为42.86%(> 30%),置信度为100%(> 80%)。下面的规则也是有效的,其结果有两个项目:
衣服->牛奶,鸡肉[sup = 3/7, conf = 3/3]。
显然,可以发现更多的关联规则,我们稍后将看到这一点。
我们注意到图2.1的事务形式中的数据表示是购物篮的简单视图。例如,模型中没有考虑每种商品的数量和价格。
我们还注意到,可以将文本文档甚至单个文档中的一句话视为事务,而不考虑单词序列和每个单词出现的次数。因此,给定一组文档或一组句子,我们可以找到单词的共现关系。
文献中已经报道了大量的关联规则挖掘算法,它们具有不同的挖掘效率。然而,根据关联规则的定义,它们的结果规则集都是相同的。也就是说,给定一个事务数据集T,一个最小支持度和最小置信度,T中存在的关联规则集是唯一确定的。任何算法都应该找到相同的规则集,尽管它们的计算效率和内存需求可能不同。最著名的挖掘算法是[3]中提出的Apriori算法,我们接下来将对其进行研究。
2.2 Apriori算法
Apriori算法分为两个步骤:
1. 生成所有频繁项集:频繁项集是在minsup之上具有事务支持的项集。
2. 从频繁项集生成所有可信关联规则:可信关联规则是具有minconf之上的可信规则。
我们将itemset中的项数称为其大小,而大小为k的项集称为k-itemset。在上面的例子2中,{Chicken, Clothes, Milk}是一个常见的3项集,因为它的支持度是3/7 (minsup = 30%)。从itemset中,我们可以生成以下三条关联规则(minconf = 80%):
规则1:鸡肉,衣服->牛奶[sup = 3/7, conf = 3/3]
规则2:衣服,牛奶->鸡[sup = 3/7, conf = 3/3]
规则3:衣服->牛奶,鸡肉[sup = 3/7, conf = 3/3]。
下面,我们依次讨论这两个步骤。
2.2.1 频繁项目集生成
Apriori算法依赖于Apriori或向下闭包特性,有效地生成所有频繁项集。
向下闭包属性:如果一个itemset有最小支持,那么这个itemset的每个非空子集也都有最小支持。
这个想法很简单,因为如果一个事务包含一组条目X,那么它必须包含X的任何非空子集。
为了保证有效的项集生成,该算法假设I中的项按字典顺序(总顺序)排序。在整个算法中,每个项集都使用这个顺序。我们使用{w[1], w[2],…,w[k]}表示由w[1], w[2],…,w[k]项组成的k-itemset w,其中w[1] < w[2] <…
基于层次搜索的频繁项集生成Apriori算法如图2.2所示。它生成所有频繁项集

