html表单导出为word文件(内含图片和CKeditor富文本框)
最近在做信息填报网站开发,需要将html页面中的表单信息导出为相应的word文档。但是由于我处理的表单中需要使用富文本框上传图片,使用一般的poi无法将富文本框中的图片导出,因此查看网上多方信息,最终使用freemarker模板加java帮助类完成了富文本框图片的导出。下面详细介绍一下具体步骤。
一、制作mht模板。新建一个word文档,按照想要的格式编制文档样式,并在需要导出信息的单元格添加占位符,例如想导出联系人信息,就在相应单元格添加${contactPerson}占位符。富文本框编辑的地方也使用占位符替换,例如企业简介信息,使用${enterpriseIntroduction}替换。


将整个word文档格式调整完成后,转存为单个网页(.mht)格式文件。右击新生成的mht文件,使用word应用打开,查看文件内容是否与刚刚编辑的word文档一致,如果不一致,进行微调后保存。使用文件编辑器(notepad++)打开mht文件则可以查看该网页文件的源码。
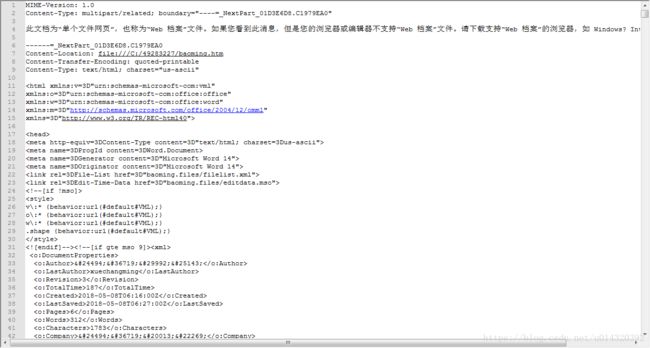
二、对刚刚生成的mht源码进行修改。首先对于普通的文本单元格导出,mht源码中已有相应的占位符${contactPerson},因此不需要进行任何修改,之后在java代码中直接替换为需要导出的字符串即可。
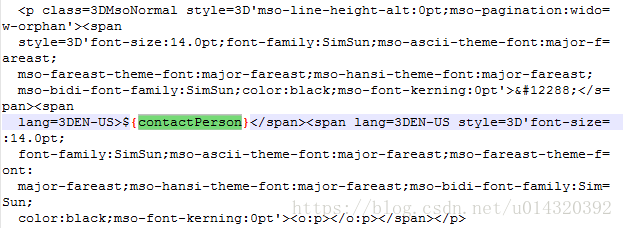
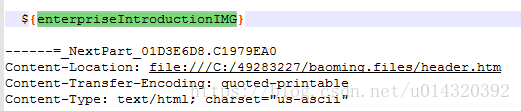
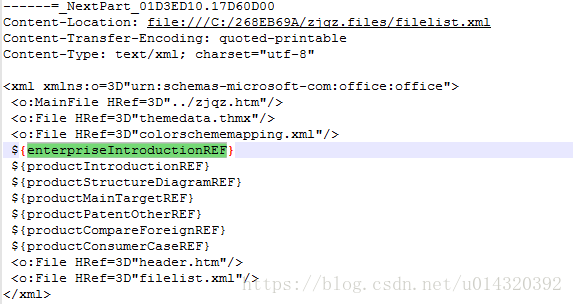
对于富文本框内容替换,mht源码中也已自动生成相应占位符${enterpriseIntroduciton}。但是,由于我们需要导出富文本框中的图片,因此我们还需要在mht文件中添加辅助占位符。由于mht中的图片采用了base64字符串编码,我们需要添加一个图片base64编码占位符${enterpriseIntroductionIMG},之后在java代码中将这个辅助占位符替换为相应图片的base64编码字符串,一般我会在mht文件中声明header.htm的上面添加该占位符。另外,还需要在mht文件的末尾添加资源引用的占位符${enterpriseIntroductionREF}。如果有多个富文本框,则每个富文本框都对应这三个占位符。

这样mht模板就已经做好了。保存后,我们就可以编写java代码对于模板文件中的占位符进行操作啦~!
三、java编码操作mht文件。我们可以专门建立一个dataUtil类,实现以下函数,便于在多个不同的表单中复用文本导出功能。首先我们需要读取已经设置好的mht模板,并将文件内容作为mht字符串输出。String readIn=readFile(realPath);
/*读取mht文件到字符串
*
*/
public static String readFile(String filepath) throws IOException{
StringBuffer buffer=new StringBuffer("");
BufferedReader br=null;
try {
br=new BufferedReader(new InputStreamReader(new FileInputStream(filepath),"UTF-8"));
buffer=new StringBuffer();
while(br.ready()) {
buffer.append((char)br.read());
}
}catch(Exception e) {
e.printStackTrace();
}
finally {
if(br!=null) {
br.close();
}
}
return buffer.toString();
} 之后,替换mht字符串中设置的占位符。对于普通的文本占位符,使用replace函数,将占位符替换为相应表单中填写的字符串。readIn=readIn.replace("${contactPerson}", contact.getContactPerson());对于富文本框内容,读取前台传输过来的富文本编辑器html源码,截取完整的标签,将src属性中存储的图片转换为base64字符串。使用html源码替换占位符${enterpriseIntroduction},使用转换好的base64字符串替换${enterpriseIntroductionIMG},使用对应的格式替换文档末尾的${enterpriseIntroductionREF}。以上步骤通过函数addEditorImageEnterpriseIntroduction实现,该函数的第一个参数为富文本编辑器enterpriseIntroduction字段的html源码,第二个参数为读入的mht模板文件字符串,第三个参数为http请求request。readIn=addEditorImageEnterpriseIntroduction(enterpriseIntroduction,readIn,request);
/*
* 截取富文本编辑器中完整的![]() 标签,并调用方法将其替换为可读取的base64字符串填回富文本编辑器中
* @editorContent 富文本编辑器字符串
* @template 模板字符串
*/
public static String addEditorImageEnterpriseIntroduction(String editorContent, String template, HttpServletRequest request) {
StringBuffer enterpriseIntroduction= new StringBuffer();
StringBuffer enterpriseIntroductionIMG=new StringBuffer();
StringBuffer enterpriseIntroductionREF=new StringBuffer();
if(!"".equals(editorContent)) {
String[] stringSplit_img=editorContent.split("
标签,并调用方法将其替换为可读取的base64字符串填回富文本编辑器中
* @editorContent 富文本编辑器字符串
* @template 模板字符串
*/
public static String addEditorImageEnterpriseIntroduction(String editorContent, String template, HttpServletRequest request) {
StringBuffer enterpriseIntroduction= new StringBuffer();
StringBuffer enterpriseIntroductionIMG=new StringBuffer();
StringBuffer enterpriseIntroductionREF=new StringBuffer();
if(!"".equals(editorContent)) {
String[] stringSplit_img=editorContent.split("");
for(int j=0;j"+stringSplit_p[j]);
}else {
//此时stringSplit_p[j]已为完整的 其中,nextPart和Content-Location处的内容要和mht文件的文件头保持一致,并且三个StringBuffer中jpg的名称必须保持一致。另外,图片转换为base64字符串的方法如下。
/*
* 将图片转存为base64字符串的方法
* @imagePath 文件存储路径
*
* */
public static String getImageStr(String imagePath) {
InputStream in=null;
byte[] data=null;
try {
in =new FileInputStream(imagePath);
data=new byte[in.available()];
in.read(data);
in.close();
}catch(IOException e) {
e.printStackTrace();
}
BASE64Encoder encoder=new BASE64Encoder();
return encoder.encode(data);
}当完成所有占位符的替换后,需要将mht字符串进行转码。因为mht采用3Dus-ascii编码,该编码格式为10进制的ASCII码(非16进制),如果不进行处理,会导致最终导出的文件中有中文乱码,转换函数如下。
/*
* 将字符串转换为10进制ASCII码
*
* */
public static String string2ASCII(String s) {
if(s==null||"".equals(s)) {
return null;
}
char[] chars=s.toCharArray();
StringBuffer asciiString=new StringBuffer();
int n=0;
for(char c:chars) {
n=c;
String a="";
if((19968<=n && n<40623)) {
a="&#"+n+";";
}else {
a=c+"";
}
asciiString.append(a);
}
return asciiString.toString();
}四、将转换好的字符串作为文件输出。
try {
os = response.getOutputStream();
response.reset();
response.setCharacterEncoding("utf-8");
response.setContentType("application/msword"); // word格式
response.setHeader("Content-Disposition", "attachment; filename=" + fileName);
byte[] b = readIn.getBytes("UTF-8");
os.write(b);
} catch (FileNotFoundException e) {
e.printStackTrace();
}finally {
if(os != null) { os.flush();os.close();}
}至此,我们完成了富文本编辑器中图片的文档导出。如果表单内有多个富文本框,可以设置多个占位符并分别替换。我在完成此功能的过程中,参考了博文http://blog.sina.com.cn/s/blog_14e8bca5a0102w9qm.html,获得了很大的帮助。根据自己的成功经验,重新梳理了富文本框图片的导出过程,在此与大家分享,希望各路大神批评指正~!