从零推导支持向量机 (SVM)
雷锋网(公众号:雷锋网) AI 科技评论按,本文作者张皓,目前为南京大学计算机系机器学习与数据挖掘所(LAMDA)硕士生,研究方向为计算机视觉和机器学习,特别是视觉识别和深度学习。
个人主页:http://lamda.nju.edu.cn/zhangh/。该文为其给雷锋网 AI 科技评论的独家供稿,未经许可禁止转载。
摘要
支持向量机 (SVM) 是一个非常经典且高效的分类模型。但是,支持向量机中涉及许多复杂的数学推导,并需要比较强的凸优化基础,使得有些初学者虽下大量时间和精力研读,但仍一头雾水,最终对其望而却步。本文旨在从零构建支持向量机,涵盖从思想到形式化,再简化,最后实现的完整过程,并展现其完整思想脉络和所有公式推导细节。本文力图做到逻辑清晰而删繁就简,避免引入不必要的概念、记号等。此外,本文并不需要读者有凸优化的基础,以减轻读者的负担。对于用到的优化技术,在文中均有介绍。
尽管现在深度学习十分流行,了解支持向量机的原理,对想法的形式化、简化,及一步步使模型更一般化的过程,及其具体实现仍然有其研究价值。另一方面,支持向量机仍有其一席之地。相比深度神经网络,支持向量机特别擅长于特征维数多于样本数的情况,而小样本学习至今仍是深度学习的一大难题。
1. 线性二分类模型
给定一组数据
,其中
,二分类任务的目标是希望从数据中学得一个假设函数 h: R → {−1,1},使得 h(xi) =yi,即
用一个更简洁的形式表示是
更进一步,线性二分类模型认为假设函数的形式是基于对特征 xi 的线性组合,即
定理 1. 线性二分类模型的目标是找到一组合适的参数 (w, b),使得
即,线性二分类模型希望在特征空间找到一个划分超平面,将属于不同标记的样本分开。
证明.

2. 线性支持向量机
线性支持向量机 (SVM) [4]也是一种线性二分类模型,也需要找到满足定理 1 约束的划分超平面,即 (w, b)。由于能将样本分开的超平面可能有很多,SVM 进一步希望找到离各样本都比较远的划分超平面。
当面对对样本的随机扰动时,离各样本都比较远的划分超平面对扰动的容忍能力比较强,即不容易因为样 本的随机扰动使样本穿越到划分超平面的另外一侧而产生分类错误。因此,这样的划分超平面对样本比较稳健,不容易过拟合。另一方面,离各样本都比较远的划分超平面不仅可以把正负样本分开,还可以以比较大的确信度将所有样本分开,包括难分的样本,即离划分超平面近的样本。
2.1 间隔
在支持向量机中,我们用间隔 (margin) 刻画划分超平面与样本之间的距离。在引入间隔之前,我们需要 先知道如何计算空间中点到平面的距离。

定义 1 (间隔 γ ). 间隔表示距离划分超平面最近的样本到划分超平面距离的两倍,即
也就是说,间隔表示划分超平面到属于不同标记的最近样本的距离之和。
定理 3. 线性支持向量机的目标是找到一组合适的参数(w, b),使得
即,线性支持向量机希望在特征空间找到一个划分超平面,将属于不同标记的样本分开,并且该划分超平面距离各样本最远。
证明. 带入间隔定义即得。
2.2 线性支持向量机基本型
定理 3 描述的优化问题十分复杂,难以处理。为了能在现实中应用,我们希望能对其做一些简化,使其变 为可以求解的、经典的凸二次规划 (QP) 问题。
定义 2 (凸二次规划). 凸二次规划的优化问题是指目标函数是凸二次函数,约束是线性约束的一类优化问题。

由于对 (w, b) 的放缩不影响解,为了简化优化问题,我们约束 (w, b) 使得
定理 5 (线性支持向量机基本型). 定理 3 描述的线性支持向量机的优化问题等价于找到一组合适的参数 (w, b),使得

推论 6. 线性支持向量机基本型中描述的优化问题属于二次规划问题,包括 d + 1 个优化变量,m 项约束。
证明. 令

代入公式 10 即得。
3. 对偶问题
现在,我们可以通过调用现成的凸二次规划软件包来求解定理 5 描述的优化问题。不过,通过借助拉格朗 日 (Lagrange) 函数和对偶 (dual) 问题,我们可以将问题更加简化。
3.1 拉格朗日函数与对偶形式
构造拉格朗日函数是求解带约束优化问题的重要方法。
定义 3 (拉格朗日函数). 对于优化问题

证明.

推论 8 (KKT 条件). 公式 21 描述的优化问题在最优值处必须满足如下条件。
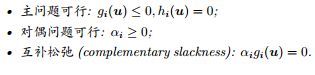
证明. 由引理 7 可知,u 必须满足约束,即主问题可行。对偶问题可行是公式 21 描述的优化问题的约束项。αigi(u) = 0 是在主问题和对偶问题都可行的条件下的最大值。
定义 4 (对偶问题). 定义公式 19 描述的优化问题的对偶问题为

引理 10 (Slater 条件). 当主问题为凸优化问题,即 f 和 gi 为凸函数,hj 为仿射函数,且可行域中至少有一点使不等式约束严格成立时,对偶问题等价于原问题。
证明. 此证明已超出本文范围,感兴趣的读者可参考 [2]。

3.2 线性支持向量机对偶型
线性支持向量机的拉格朗日函数为

证明. 因为公式 26 内层对 (w,b) 的优化属于无约束优化问题,我们可以通过令偏导等于零的方法得到 (w,b)的最优值。

将其代入公式 26,消去 (w, b),即得。
推论 13. 线性支持向量机对偶型中描述的优化问题属于二次规划问题,包括 m 个优化变量,m + 2 项约束。
证明. 令
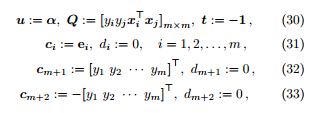
代入公式 10 即得。其中,ei 是第 i 位置元素为 1,其余位置元素为 0 的单位向量。我们需要通过两个不等式约束
和
来得到一个等式约束。
3.3 支持向量
定理 14 (线性支持向量机的 KKT 条件). 线性支持向量机的 KKT 条件如下。
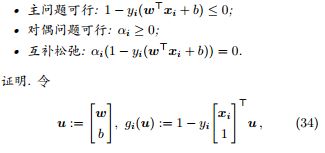
代入引理 8 即得。
定义 5 (支持向量). 对偶变量 αi > 0 对应的样本。
引理 15. 线性支持向量机中,支持向量是距离划分超平面最近的样本,落在最大间隔边界上。

定理 16. 支持向量机的参数 (w, b) 仅由支持向量决定,与其他样本无关。
证明. 由于对偶变量 αi > 0 对应的样本是支持向量,
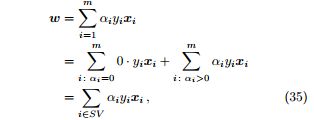
其中 SV 代表所有支持向量的集合,b 可以由互补松弛算出。对于某一支持向量 xs 及其标记 ys,由于
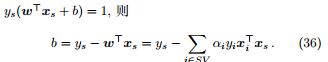
实践中,为了得到对 b 更稳健的估计,通常使用对所有支持向量求解得到 b 的平均值。
推论 17. 线性支持向量机的假设函数可表示为
证明. 代入公式 35 即得。
4. 核函数
至此,我们都是假设训练样本是线性可分的。即,存在一个划分超平面能将属于不同标记的训练样本分开。但在很多任务中,这样的划分超平面是不存在的。支持向量机通过核技巧 (kernel trick) 来解决样本不是线性可分的情况 [1]。
4.1 非线性可分问题
既然在原始的特征空间
不是线性可分的,支持向量机希望通过一个映射
,使得数据在新的空间
是线性可分的。
引理 18. 当 d 有限时,一定存在
,使得样本在空间
中线性可分.
证明. 此证明已超出本文范围,感兴趣的读者可参考计算学习理论中打散 (shatter) 的相应部分 [16]。
令 φ(x) 代表将样本 x 映射到
中的特征向量,参数 w 的维数也要相应变为
维,则支持向量机的基本型和对偶型相应变为:
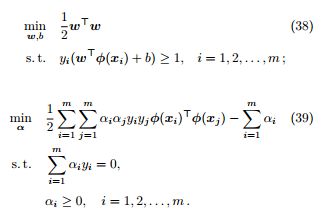
其中,基本型对应于
+ 1 个优化变量,m 项约束的二次规划问题;对偶型对应于 m 个优化变量,m + 2 项约束的二次规划问题。
4.2 核技巧
注意到,在支持向量机的对偶型中,被映射到高维的特征向量总是以成对内积的形式存在,即
如果先计算特征在空间
的映射,再计算内积,复杂度是
。当特征被映射到非常高维的空间,甚至是无穷维空间时,这将会是沉重的存储和计算负担。
核技巧旨在将特征映射和内积这两步运算压缩为一步, 并且使复杂度由
降为
。即,核技巧希望构造一个核函数 κ(xi,xj),使得
,并且 κ(xi,xj) 的计算复杂度是
。

4.3 核函数选择
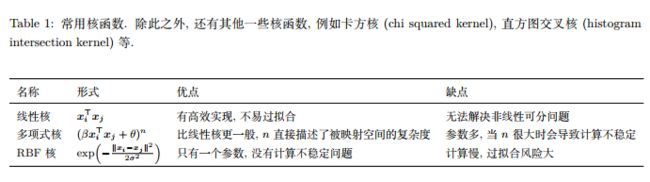
通过向高维空间映射及核技巧,我们可以高效地解决样本非线性可分问题。但面对一个现实任务,我们很 难知道应该具体向什么样的高维空间映射,即应该选什么样的核函数,而核函数选择的适合与否直接决定整体的性能。
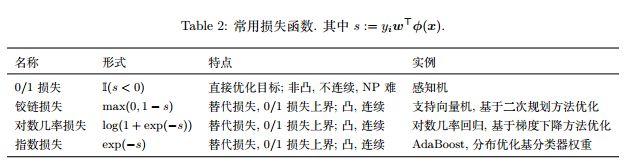
表 1 列出了几种常用的核函数。通常,当特征维数 d 超过样本数 m 时 (文本分类问题通常是这种情况),使用线性核;当特征维数 d 比较小,样本数 m 中等时,使用 RBF 核;当特征维数 d 比较小,样本数 m 特别大时,支持向量机性能通常不如深度神经网络。
除此之外,用户还可以根据需要自定义核函数,但需要满足 Mercer 条件 [5]。

反之亦然。
新的核函数还可以通过现有核函数的组合得到,使用多个核函数的凸组合是多核学习 [9] 的研究内容。

4.4 核方法
上述核技巧不仅使用于支持向量机,还适用于一大类问题。

即 Φα 比 w 有更小的目标函数值,说明 w 不是最优解,与假设矛盾。因此,最优解必定是样本的线性组合。
此外,原版表示定理适用于任意单调递增正则项 Ω(w)。此证明已超出本文范围,感兴趣的读者可参考 [13]。
表示定理对损失函数形式没有限制,这意味着对许多优化问题,最优解都可以写成样本的线性组合。更进 一步,
将可以写成核函数的线性组合
通过核函数,我们可以将线性模型扩展成非线性模型。这启发了一系列基于核函数的学习方法,统称为核方法 [8]。
5. 软间隔
不管直接在原特征空间,还是在映射的高维空间,我们都假设样本是线性可分的。虽然理论上我们总能找 到一个高维映射使数据线性可分,但在实际任务中,寻找到这样一个合适的核函数通常很难。此外,由于数据中通常有噪声存在,一味追求数据线性可分可能会使模型陷入过拟合的泥沼。因此,我们放宽对样本的要求,即允许有少量样本分类错误。
5.1 软间隔支持向量机基本型
我们希望在优化间隔的同时,允许分类错误的样本出现,但这类样本应尽可能少:

其中,
是指示函数,C 是个可调节参数,用于权衡优化间隔和少量分类错误样本这两个目标。但是,指示函数不连续,更不是凸函数,使得优化问题不再是二次规划问题。所以我们需要对其进行简化。
公式 60 难以实际应用的原因在于指示函数只有两个离散取值 0/1,对应样本分类正确/错误。为了能使优 化问题继续保持为二次规划问题,我们需要引入一个取值为连续值的变量,刻画样本满足约束的程度。我们引入松弛变量 (slack variable) ξi,用于度量样本违背约束的程度。当样本违背约束的程度越大,松弛变量值越大。即,

其中,C 是个可调节参数,用于权衡优化间隔和少量样本违背大间隔约束这两个目标。当 C 比较大时,我们希望更多的样本满足大间隔约束;当 C 比较小时,我们允许有一些样本不满足大间隔约束。

5.2 软间隔支持向量机对偶型
定理 25 (软间隔支持向量机对偶型). 软间隔支持向量机的对偶问题等价于找到一组合适的 α,使得
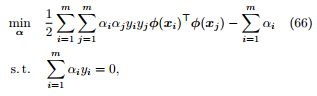

因为内层对 (w, b, ξ) 的优化属于无约束优化问题,我们可以通过令偏导等于零的方法得到 (w, b, ξ) 的最优值。

推论 26. 软间隔支持向量机对偶型中描述的优化问题属于二次规划问题,包括 m 个优化变量,2m+2 项约束。
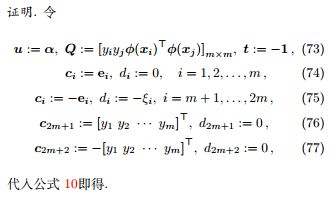
5.3 软间隔支持向量机的支持向量
定理 27 (软间隔支持向量机的 KKT 条件). 软间隔支持向量机的 KKT 条件如下.

引理 28. 软间隔支持向量机中,支持向量落在最大间隔边界,内部,或被错误分类的样本。

定理 29. 支持向量机的参数 (w, b) 仅由支持向量决定,与其他样本无关。
证明. 和线性支持向量机证明方式相同。
5.4 铰链损失
引理 30. 公式 61 等价为


其中,第一项称为经验风险,度量了模型对训练数据的拟合程度;第二项称为结构风险,也称为正则化项,度量了模型自身的复杂度。正则化项削减了假设空间,从而降低过拟合风险。λ 是个可调节的超参数,用于权衡经验风险和结构风险。

6. 优化方法
6.1 SMO
如果直接用经典的二次规划软件包求解支持向量机对偶型,由于
的存储开销是
,当训练样本很多时,这将是一个很大的存储和计算开销。序列最小化 (SMO) [10]是一个利用支持 向量机自身特性高效的优化算法。SMO 的基本思路是坐标下降。
定义 7 (坐标下降). 通过循环使用不同坐标方向,每次固定其他元素,只沿一个坐标方向进行优化,以达到目标函数的局部最小,见算法 1.
我们希望在支持向量机中的对偶型中,每次固定除 αi 外的其他变量,之后求在 αi 方向上的极值。但由于 约束
,当其他变量固定时,αi 也随着确定。这样,我们无法在不违背约束的前提下对 αi 进行优化。因此,SMO 每步同时选择两个变量 αi 和 αj 进行优化,并固定其他参数,以保证不违背约束。

定理 32 (SMO 每步的优化目标). SMO 每步的优化目标为

推论 33. SMO 每步的优化目标可等价为对 αi 的单变量二次规划问题。
证明. 由于
,我们可以将其代入 SMO 每步的优化目标,以消去变量 αj。此时,优化目标函数是对于 αi 的二次函数,约束是一个取值区间 L ≤ αi ≤ H。之后根据目标函数顶点与区间 [L, H] 的位置关系,可以得到 αi 的最优值。理论上讲,每步优化时 αi 和 αj 可以任意选择,但实践中通常取 αi 为违背 KKT 条件最大的变量,而 αj取对应样本与 αi 对应样本之间间隔最大的变量。对 SMO 算法收敛性的测试可以用过检测是否满足 KKT 条件得到。
6.2 Pegasos
我们也可以直接在原问题对支持向量机进行优化,尤其是使用线性核函数时,我们有很高效的优化算法,如 Pegasos [14]。Pegasos 使用基于梯度的方法在线性支持向量机基本型
进行优化,见算法 2。

6.3 近似算法
当使用非线性核函数下的支持向量机时,由于核矩阵
,所以时间复杂度一定是
,因此,有许多学者致力于研究一些快速的近似算法。例如,CVM [15]基于近似最小包围球算法,Nyström 方法[18]通过从 K 采样出一些列来得到 K 的低秩近似,随机傅里叶特征[12]构造了向低维空间的随机映射。本章介绍了许多优化算法,实际上现在已有许多开源软件包对这些算法有很好的实现,目前比较著名的有 LibLinear[7] 和 LibSVM[3],分别适用于线性和非线性核函数。
7. 支持向量机的其他变体
ProbSVM. 对数几率回归可以估计出样本属于正类的概率,而支持向量机只能判断样本属于正类或负类,无法得到概率。ProbSVM[11]先训练一个支持向量机,得到参数 (w, b)。再令
,将
当做新的训练数据训练一个对数几率回归模型,得到参数
。因此,ProbSVM 的假设函数为
对数几率回归模型可以认为是对训练得到的支持向量机的微调,包括尺度 (对应 θ1) 和平移 (对应 θ0)。通常 θ1 > 0,θ0 ≈ 0。
多分类支持向量机. 支持向量机也可以扩展到多分类问题中. 对于 K 分类问题,多分类支持向量机 [17] 有 K 组参数
,并希望模型对于属于正确标记的结果以 1 的间隔高于其他类的结 果,形式化如下
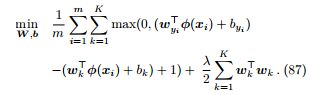

References
[1] B. E. Boser, I. M. Guyon, and V. N. Vapnik. A training algorithm for optimal margin classifiers. In Proceedings of the Annual Workshop on Computational Learning Theory, pages 144–152, 1992. 5
[2] S. Boyd and L. Vandenberghe. Convex optimization. Cambridge university press, 2004. 4
[3] C.-C. Chang and C.-J. Lin. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology, 2(3):27, 2011. 10
[4] C. Cortes and V. Vapnik. Support-vector networks. Machine Learning, 20(3):273–297, 1995. 1 [5] N. Cristianini and J. Shawe-Taylor. An introduction to support vector machines and other kernel-based learning methods. Cambridge University Press, 2000. 6
[6] H. Drucker, C. J. Burges, L. Kaufman, A. J. Smola, and V. Vapnik. Support vector regression machines. In Advances in Neural Information Processing Systems, pages 155–161, 1997. 10
[7] R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, and C.-J. Lin. LIBLINEAR: A library for large linear classification. Journal of Machine Learning Research, 9(8):1871–1874, 2008. 10
[8] T. Hofmann, B. Schölkopf, and A. J. Smola. Kernel methods in machine learning. The Annals of Statistics, pages 1171–1220, 2008. 6
[9] G. R. Lanckriet, N. Cristianini, P. Bartlett, L. E. Ghaoui, and M. I. Jordan. Learning the kernel matrix with semidefinite programming. Journal of Machine Learning Research, 5(1):27–72, 2004. 6 [10] J. Platt. Sequential minimal optimization: A fast algorithm for training support vector machines. Micriosoft Research, 1998. 9
[11] J. Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in Large Margin Classifiers, 10(3):61–74, 1999. 10
[12] A. Rahimi and B. Recht. Random features for largescale kernel machines. In Advances in Neural Information Processing Systems, pages 1177–1184, 2008. 10
[13] B. Scholkopf and A. J. Smola. Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT press, 2001. 6
[14] S. Shalev-Shwartz, Y. Singer, N. Srebro, and A. Cotter. Pegasos: Primal estimated sub-gradient solver for SVM. Mathematical Programming, 127(1):3–30, 2011. 9
[15] I. W. Tsang, J. T. Kwok, and P.-M. Cheung. Core vector machines: Fast SVM training on very large data sets. Journal of Machine Learning Research, 6(4):363– 392, 2005. 10
[16] V. Vapnik. The nature of statistical learning theory. Springer Science & Business Media, 2013. 5
[17] J. Weston, C. Watkins, et al. Support vector machines for multi-class pattern recognition. In Proceedings of the European Symposium on Artificial Neural Networks, volume 99, pages 219–224, 1999. 10
[18] C. K. Williams and M. Seeger. Using the nyström method to speed up kernel machines. In Advances in Neural Information Processing Systems, pages 682–688, 2001. 10
[19] 周志华. 机器学习. 清华大学出版社, 2016. 9
雷锋网特约稿件,未经授权禁止转载。详情见转载须知。