大厂面试 HBase系列(一) 系统设计开篇
“ 大厂面试系列主要两个目标:1让有经验同学快速复习,温故而知新;2作为萌新同学的入门砖”
本文是HBase系列第一篇,通过本文可以了解:1、HBase概述及数据模型;2、HBase系统架构;3、HBase 存储模型(了解数据高可用、高性能的实现)。同时本文会介绍一些其他的基础概念,如行级存储、列级存储、跳跃表等。
01
—
HBase简介
一、HBase概述
在Hadoop生态中,如果说HDFS解决了在大量廉价机器上存储海量数据的问题,MapReduce则解决了在大量廉价机器的基础上运行超大规模计算的问题;那HBase则是致力于结构化数据的存储及高效读写。目前HBase在国内应用较为广泛,尤其在小米更是有千台机器的集群规模,主要用来存储消息、用户画像、时序数据等。需要注意的是,如果使用HBase作为数据存储,服务本身要能容忍一定的读延迟。
二、HBase数据模型
在介绍HBase数据模型前先聊下行级存储和列式存储
| 存储方式 |
介绍 |
| 行级存储 | 把一行数据放在一块存储,写数据时,把一行写完再起一行;读数据时会把整行都读出来。 像Mysql就是行式存储,优点是读取一行数据时,效率较高,但如果只需要几列,数据库服务器会把整行数据读出来,然后截取目标列。执行读操作时有较多的内存占用 |
| 列式存储 | 列式存储会把一列的数据全部存在一块,不同列的数据独立开,这样只读某个列数据时速度较快,但要查一行完整数据时,由于不同列的数据可能分开存储的,因此得遍历多个服务器,性能较低 |
1. HBase 列簇存储
一般来说单次读写,往往对某几个具有共同属性的列来操作。比如用户消息表中,userInfo相关的几个列;或者是message相关的几个列。HBase 列簇存储正是基于这样的想法,提出了列簇概念,支持把具有公共属性的列聚合为一个列簇。
2. HBase逻辑视图
HBase有table、row、column、timestamp、cell几个概念。
table:表
row:行,一个表有多行数据,HBase每行的数据分布在多个列簇(CF),不同列簇间分开存储
column:列,由Column Family(列簇)和qualifier(具体列名)组成。一行数据有多个列簇,而每个列簇又有一个或多个qualifier
timestamp:时间戳,每个列都有多个时间版本的数据
cell:单元格,由(row、column、timestamp、type、value)组成。type标识操作类型,如put/delete等。在数据库中,hbase是KV结构存储的,四元组(row、column、timestamp、type)就是K,value为V。
为了方便理解,我们拿用户消息表的Mysql和hbase举例, 来展示hbase逻辑视图
以下是Mysql数据视图
| id |
userId |
userName |
userAccount |
msgTag |
msg Content |
| 1 | 1000000000 |
happy |
jghome |
tag1 |
content1 |
| 2 | 1000000001 | life |
jghome | tag1 | content2 |
| 3 |
1000000002 | wenhui |
jghome | tag2 | content3 |
以下是HBase逻辑视图
用户消息表有user、message两个列簇CF,这俩列簇分别有两个qualifier,其中rowKey为1的message:msgTag列有多个timestamp版本的数据
rowkey |
user |
message |
||
userId |
userName |
msgTag |
msgContent |
|
| 1 | t1:1000000000 |
t1:happy |
t1:content1 |
|
| t2:1000000000 |
t2:happy |
t2:content1 |
||
| 2 | t1:1000000001 | t1:life |
t1:tag1 | t1:content2 |
| 3 |
t1:1000000002 | t1:wenhui |
t1:tag2 | t1:content3 |
需要注意的是HBase同行数据并不是连续存储的,而是把同个CF的数据聚合在一起存储。另外和Mysql不同的是,HBase允许空值,比如上面表格中rowkey=1;CF=message;qualifier=msgTag的列就没有数据,在HBase中这样的没有列的值是不占内存的,而在Mysql中值为NULL的列依然占用空间.
3. HBase物理视图
3.1 基本概念
如上介绍的HBase逻辑视图,只是为了用户方便理解,但真要了解HBase,需要清除真正的物理存储模型。HBase存储时,是由一系列的KV组成,是一个稀疏的、多维的、有序的、分布式Map:
稀疏:HBase允许空值,且空值不占内存。
多维:HBase 的key是由一个复合结构组成,这个结构包括了row、column、timestamp、type
有序:构成HBase的KV在同一个文件内是有序存储的;现根据rowKey进行排序,rowKey相等时根据column排序,column想当的情况下,则根据timestamp排序,timestamp大的会排在前面,表示最新数据
分布式:HBase的所有Map都是分布式存储
上面也提到了HBase以CF为单位来存储,下面表格会展示用户消息表的物理存储结构
3.2 物理存储的视图
列簇user
| rowKey | timestamp |
CF:user |
| 1 |
t1 |
user:userId=1000000000 |
| 1 | t2 |
user:userId=1000000000 |
| 1 | t1 |
user:userName="happy" |
| 1 | t2 |
user:userName="happy" |
| 2 |
t1 |
user:userId=t1:1000000001 |
| 2 | t1 |
user:userName="happy" |
| 3 |
t1 | user:userId=t1:1000000002 |
| 3 | t1 | user:userName="wenhui" |
列簇message
| rowKey | timestamp |
CF:message |
| 1 |
t1 |
message:msgContent= "content1" |
| 1 | t2 |
message:msgContent= "content1" |
| 2 | t1 |
message:msgTag= "tag1" |
| 2 | t1 |
message:msgContent= "content2" |
| 3 |
t1 | message:msgTag= "tag2" |
| 3 | t1 | message:msgContent= "content3" |
注意上述表格存储时的排序哈
02
—
HBase系统架构
HBase系统架构如下,主要由HBase client、 Zookeeper、Master、RegionServer、HDFS组成
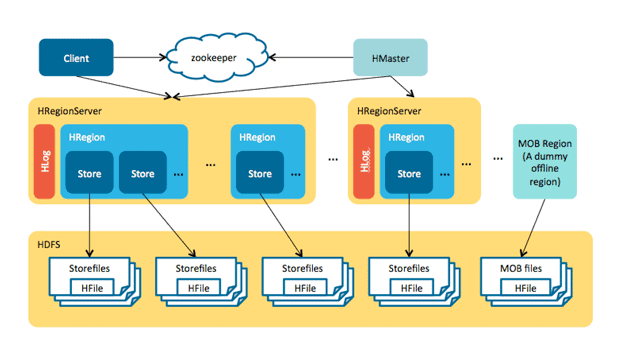
图片引自:https://ndu0e1pobsf1dobtvj5nls3q-wpengine.netdna-ssl.com/wp-content/uploads/2019/08/Apache-HBase-MOB-Architecture.png
一、HBase client
HBase提供了Shell脚本、java API、Thrift API 以及 MapReduce(用于批量数据读)编程接口。我们可以通过上述方式实现表的日常维护和增删改查等操作。需要注意的是HBase在访问数据前,先用找到目标数据所在的RegionServer,然后执行相关操作。HBase client通过zookeeper来获取元数据表的regionServer,然后从该regionServier获取到元信息,从元信息中查看当前所访问的数据行具体在哪个regionServer上。需要注意的是HBase客户端也会在本地保存元数据,这样下次请求该数据行时,就不用再访问Zookeeper
二、Master
1. Mater复杂客户端各种管理请求,如建表、修改表、权限管理、切分表、合并数据分片、compaction等操作
2. 管理集群内的regionServer,包括regionServer的region分配、迁移;以及regionServer的故障恢复
3. 清理过期日志与文件
三、RegionServer
RegionServer接受并处理 客户端的数据读写请求,是HBase中最核心的部分,主要由WAL、BlockCache、Region、HDFS组成:
1. WAL即预写日志(HLOG)
为了提高写性能,HBase在写入数据时,并不是直接写入HFile。而是先把数据写入memStore(写缓存),然后等写缓存写满后,再把写缓存数据异步的flush成一个HFile文件。为了防止写缓存还未flush到HFile就发生故障引起数据丢失,HBase把数据写到memStore后,还会把数据顺序追加到日志文件HLOG,这样如果出现故障,就可以通过HLOG来做数据恢复。HLog在HBase中主要用作写数据的高可用实现、HBase集群间主从复制(从服务器通过回放HLOG和主服务器数据保持一致)
2. BlockCache
读缓存,客户端从磁盘读完数据后,会往BlockCache缓存一份,下次访问可以直接从BlockCache获取数据,可以提供读性能。需要注意的是BlockCache缓存对象是一个block块,而不是一行数据。block上存放着物理相邻的KV数据。
3. Region
一个RegionServer下会有多个region,每个region保存着一张表的一个数据段。Region是HBase集群存储负载均衡的基本单位。由于在HBase中,不同列簇数据是分开存储的,region又把自身划分成多个Store,Store个数等于列簇的个数。因此我们建议把相同业务属性的数据,设置在同一个列簇中。
3.1 Store
一个Store由一个MemStore和多个HFile组成,MemStore即上文的写缓存,写缓存数据满了后会异步的刷成一个新的HFile文件,为防止HFile碎文件过多,HBase会动Hfile进行compact操作(原因可参考HDFS为啥不适合存储大量小文件)
4.HDFS
HBase底层依赖HDFS来实现数据存储,HFIle和Hlog都是存在HDFS之上。也正是这个原因,HFIle文件需要进行compact
四、Zookeeper
在HBase中zookeeper扮演者重要角色,主要包括以下:
1. 实现Master高可用。通常情况下HBase只有一个master在工作,当master宕机后,Zookeeper会检测到该宕机事件,选举出新的Master
2.RegionServer高可用。Zookeeper通过心跳机制和监控器来监控RegionServer是否宕机,并在发现RegionServer宕机,则通知Master对RegionServer进行故障恢复
3.保存HBase元数据 -> RegionServer地址 的映射关系
4. 分布式锁:HBase使用Zookeeper来实现分布式锁
03
—
HBase 存储模型
RegionServer 是HBase最核心的模块,由一个HLog(新版本会有多个)、一个BlockCache和多个Region组成,这些Region共用HLog和BlockCache。每个Region包含了Table所有的列簇,所以HBase可以对region进行水平切分来容纳更多的数据。
一、HLog
HLog用来保证数据的高可用以及主从复制的数据一致性保证。HBase为了保证行级别的原子性,如果一个Put操作涉及多个CF,那多个CF的操作会合并为一条log记录写入log文件。需要注意的是当MemStore数据落盘到HFile后,Hlog的数据会被删除。RegionServer中的HLog也是用HDFS作为其底层实现
二、Store
每个Store存放一个CF的数据,Store由MemStore(内存)和HFile(磁盘)写入。HBase基于LSM设计了存储模型。
LSM

(图片摘自HBase原理与实践)
Mysql基于通过B+树实现了聚簇索引,读性能较高,但写性能较差。HBase在缓存被击穿后,为了保证读性能,HFile KV数据的K必须有序排列,如果在写到HFile时再排序,将会是磁盘随机写,写性能会很差。为了同时兼顾读写性能,HBase基于LSM来设计存储模型。如上图,MemStore采用跳跃表(java中对应ConcurrentSkipListMap)来作为底层实现,在MemStore的数据 flush到HFile之前,会对MemStore中的数据先进性排序。这样原本一次磁盘的随机写入就转换成了内存随机写和磁盘顺序写。
三、布隆过滤器
借助布隆过滤器,可以使用较小的空间来确定一个元素是"可能存在"还是"一定不存在",HBase在获取数据时,可以通过布隆过滤器过滤一些不包含数据的数据块,从而减少磁盘IO次数,提高查询性能
四、MemStore GC问题优化
另外在物理层面上,所有Region的MemStore其实是共享了一快大的JVM堆内存。
MemStore for Region1 |
MemStore for Region2 |
MemStore For Region3 |
MemStore for Region1 |
MemStore for Region2 |
MemStore For Region3 |
如图,不同Region的Memstore是交替存在的,也就是说同一个Region的内存在物理上并不是挨着的,这样随着内存分配和释放,会产生大量碎片(假如region1的memStore flush到HFile后被回收掉,那么region1对应的堆空间-即两个粉红色的heap快会被回收,而这些被回收的空间不是连续的,接下来可能会在刚释放的两个heap块为其他region5.memStore和region6.memStore分配内存,而region5新分配到的memStore在堆空间上依旧不连续,如下图)。
memstore for region5 |
memStore for region6 |
MemStore for Region2 |
memStore for region6 |
memstore for region5 |
MemStore for Region1 |
MemStore for Region2 |
MemStore For Region3 |
假设此时深黄色的内存快被回收(每个数据块大小变成之前1/2了),那未被使用的内存块将会越来越碎,最后造成 full gc频繁。
为了解决碎片问题引发的FULL GC,HBase借鉴了java TLAB的方式来解决碎片问题:每个MemStore在java中对应一个MemstoreLAB对象(默认2M),同一个RegionServer下的多个MemstoreLAB对象在物理上是相邻的。
MemStore for Region1 |
MemStore for Region2 |
MemStore For Region3 |
MemStore for Region1 |
MemStore for Region2 |
MemStore For Region3 |
至此,本篇对HBase的入门介绍算是结束,后续还会介绍:HBase读写流程及性能优化、HBase高可用的实现、HBase高性能的实现、HBase 负载均衡实现、HBase Compaction、HBase最佳实践等
您的转发是对我最大的支持
长按订阅 WeCoding▼

如有收获,点个在看,诚挚感谢