leetcode 100-200
文章目录
- 100. 相同的树
- 101. 对称二叉树
- 102. 二叉树的层序遍历
- 103. 二叉树的锯齿形层次遍历
- 104. 二叉树的最大深度(***********)
- 105. 从前序与中序遍历序列构造二叉树
- 从数组恢复成二叉树
- 106. 从中序与后序遍历序列构造二叉树
- 107. 二叉树的层次遍历 II
- 108. 将有序数组转换为二叉搜索树
- 109. 有序链表转换二叉搜索树
- 110. 平衡二叉树
- 111. 二叉树的最小深度
- 112. 路径总和
- 113. 路径总和 II
- 114. 二叉树展开为链表(*****)
- 115. 不同的子序列
- 116. 填充每个节点的下一个右侧节点指针(bfs)
- size_t要转int,size_t每次都加个类型转换,不然会造成未知的错误
- 117. 填充每个节点的下一个右侧节点指针 II(bfs)
- 118. 杨辉三角
- 119. 杨辉三角 II
- 121. 买卖股票的最佳时机(dp)
- 122. 买卖股票的最佳时机 II
- 123. 买卖股票的最佳时机 III
- 124. 二叉树中的最大路径和(dfs,不懂)
- 125. 验证回文串
- 大小写转换
- 判断是否是字母
- 126. 单词接龙 II
- 127. 单词接龙(dfs,bfs)
- 128. 最长连续序列
- unordered_set
- 129. 求根到叶子节点数字之和
- 130. 被围绕的区域
- 131. 分割回文串
- 132. 分割回文串 II
- 134. 加油站
- 135. 分发糖果
- 双端遍历法
- 136. 只出现一次的数字(位运算)
- 异或
- 137. 只出现一次的数字 II(位运算)
- 138. 复制带随机指针的链表
- 139. 单词拆分
- 140. 单词拆分 II
- 141.环形链表
- 142.环形链表2
- 143. 重排链表
- 链表易错点
- 144. 二叉树的前序遍历
- 非迭代版本
- 145. 二叉树的后序遍历
- 146. LRU缓存机制
- 148. 排序链表
- 链表归并排序
- 150. 逆波兰表达式求值
- 151. 翻转字符串里的单词
- 152. 乘积最大子数组(dp)
- 153. 寻找旋转排序数组中的最小值
- 154. 寻找旋转排序数组中的最小值 II
- 155. 最小栈
- 160. 相交链表
- 162. 寻找峰值
- 165. 比较版本号
- 167. 两数之和 II - 输入有序数组
- 168. Excel表列名称
- 169. 多数元素(mol计数)
- 171. Excel表列序号
- 172. 阶乘后的零
- 173. 二叉搜索树迭代器
- 174. 地下城游戏(倒序选择)
- 175. 组合两个表
- 176. 第二高的薪水
- 177. 第N高的薪水
- 178. 分数排名
- 179. 最大数
- 181. 超过经理收入的员工
- 182. 查找重复的电子邮箱
- 183. 从不订购的客户
- 187. 重复的DNA序列
- 189. 旋转数组
- 198. 打家劫舍(dp)
- 199. 二叉树的右视图
100. 相同的树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSameTree(TreeNode* p, TreeNode* q) {
if(!p && !q)return true;
if(!p || !q || p->val!=q->val)return false;
return isSameTree(p->left,q->left) && isSameTree(p->right,q->right);;
}
};
101. 对称二叉树
易错点时三个条件不能少,而且注意对称时左节点的左孩子和右节点的右孩子相比
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isok(TreeNode* root1, TreeNode* root2)
{
if(!root1 && !root2)return true;
if(!root1 || !root2 || root1->val!=root2->val)return false;
return isok(root1->left,root2->right) && isok(root1->right,root2->left);
}
bool isSymmetric(TreeNode* root) {
if(!root)return true;
return isok(root->left,root->right);
}
};
102. 二叉树的层序遍历
推荐bfs
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
if(!root)return {};
queue<TreeNode*> qt;
qt.push(root);
vector<vector<int>> res ;
while(!qt.empty())
{
int len = qt.size();
vector<int> cur;
for(int i = 0;i<len;i++)
{
auto temp = qt.front();qt.pop();
cur.push_back(temp->val);
if(temp->left)qt.push(temp->left);
if(temp->right)qt.push(temp->right);
}
res.push_back(cur);
}
return res;
}
};
103. 二叉树的锯齿形层次遍历
印象中是使用堆栈的,但是直接用一个bool量来标记也很方便
还可以正常层序遍历,然后隔一个倒叙一下就可以,和1007一样,都是遍历之后对数组做处理
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
private:
vector<vector<int> > res;
bool flag;
public:
void dfs(vector<TreeNode*> cur)
{
if(cur.size()==0){return;}
vector<TreeNode*> next;
vector<int> temp;
for(auto i:cur)
{
if(i->left!=NULL){next.push_back(i->left);}
if(i->right!=NULL){next.push_back(i->right);}
temp.push_back(i->val);
}
if(!flag){reverse(temp.begin(),temp.end());}
flag = !flag;
res.push_back(temp);
dfs(next);
}
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {
if(root==NULL){return res;}
vector<TreeNode*> temp;
temp.push_back(root);
flag = 1;
dfs(temp);
return res;
}
};
104. 二叉树的最大深度(***********)
有一种很简单的写法,很多处会用到
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root==NULL)return 0;
return max( maxDepth( root->left) , maxDepth( root->right) )+1;
}
};
105. 从前序与中序遍历序列构造二叉树
从数组恢复成二叉树
给题可能会做,但直接问也要能叙述出来:从前序遍历的第一个数或者后序遍历的最后一个数可以获得根节点,然后再中序遍历中根节点左边的就是左子树,右边的就是右子树,这样的过程不断进行递归就能求出来
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if(preorder.empty())return NULL;
auto temp = preorder[0];
auto root = new TreeNode(temp);
auto i = find(inorder.begin(),inorder.end(),temp)-inorder.begin();
vector<int> preleft(preorder.begin()+1,preorder.begin()+1+i);
vector<int> preright(preorder.begin()+1+i,preorder.end());
vector<int> inleft(inorder.begin(),inorder.begin()+i);
vector<int> inright(inorder.begin()+i+1,inorder.end());
root->left = buildTree(preleft,inleft);
root->right = buildTree(preright,inright);
return root;
}
};
106. 从中序与后序遍历序列构造二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if(inorder.empty())return NULL;
auto temp = postorder.back();
auto root = new TreeNode(temp);
auto i = find(inorder.begin(),inorder.end(),temp)-inorder.begin();
vector<int> inleft(inorder.begin(),inorder.begin()+i);
vector<int> inright(inorder.begin()+i+1,inorder.end());
vector<int> postleft(postorder.begin(),postorder.begin()+i);
vector<int> postright(postorder.begin()+i,postorder.end()-1);
root->left = buildTree(inleft,postleft);
root->right = buildTree(inright,postright);
return root;
}
};
107. 二叉树的层次遍历 II
完全可以从上到下遍历,然后拿一个堆栈存放,或者直接返回reverse的结果?!不是更简单,看来在使用堆栈的倒叙功能时,用reverse可能更方便
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
private:
stack<vector<int>> res;
public:
void dfs(vector<TreeNode*> cur)
{
if(cur.size()==0){return;}
vector<int> temp;
vector<TreeNode*> next;
for(auto i:cur)
{
if(i->left!=NULL){next.push_back(i->left);}
if(i->right!=NULL){next.push_back(i->right);}
temp.push_back(i->val);
}
res.push(temp);
dfs(next);
}
vector<vector<int>> levelOrderBottom(TreeNode* root) {
vector<TreeNode*> temp;
temp.push_back(root);
vector<vector<int>> r;
if(root==NULL){return r;}
dfs(temp);
while(!res.empty())
{
r.push_back(res.top());
res.pop();
}
return r;
}
};
108. 将有序数组转换为二叉搜索树
class Solution {
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
int len = nums.size();
if(len==0)return NULL;
auto root = new TreeNode(nums[len/2]);
vector<int> numsleft(nums.begin(),nums.begin()+len/2);
vector<int> numsright(nums.begin()+len/2+1,nums.end());
root->left = sortedArrayToBST(numsleft);
root->right = sortedArrayToBST(numsright);
return root;
}
};
109. 有序链表转换二叉搜索树
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* sortedListToBST(ListNode* head) {
if(!head)return NULL;
if(!head->next)return new TreeNode(head->val);
auto fast = head;
auto slow = head;
auto pre = head;
while(fast && fast->next)
{
fast = fast->next->next;
pre = slow;
slow = slow->next;
}
pre->next = NULL;
auto root = new TreeNode(slow->val);
root->left = sortedListToBST(head);
root->right = sortedListToBST(slow->next);
return root;
}
};
110. 平衡二叉树
class Solution {
public:
int maxdepth(TreeNode* root)
{
if(!root)return 0;
return max(maxdepth(root->left),maxdepth(root->right))+1;
}
bool isBalanced(TreeNode* root) {
if(!root)return true;
if(abs(maxdepth(root->left)-maxdepth(root->right))>1)return false;
return isBalanced(root->left) && isBalanced(root->right);
}
};
111. 二叉树的最小深度
形式基本上是仿照最大深度来的,但是有一点不一样,要注意对最小深度的定义,不是出现null就行,而是必须出现叶节点,即本身存在但是左右孩子不存在的,这是唯一的情况,由于root可能会存在左右孩子为null的情况,所以不能将左右孩子直接输入,而是将根节点输入。
class Solution {
public:
int minDepth(TreeNode* root) {
if(!root)return 0;
if(!root->left && !root->right)return 1;
if(root->left && !root->right)return minDepth(root->left)+1;
if(!root->left && root->right)return minDepth(root->right)+1;
if(root->left && root->right)return min(minDepth(root->left),minDepth(root->right))+1;
return INT_MAX;
}
};
112. 路径总和
class Solution {
public:
bool hasPathSum(TreeNode* root, int sum) {
if(!root) return false;
if(root->val==sum && !root->left && !root->right){
return true;
}
return hasPathSum(root->left,sum-root->val) || hasPathSum(root->right,sum-root->val);
}
};
作者:free_styles
链接:https://leetcode-cn.com/problems/path-sum/solution/di-gui-he-die-dai-liang-chong-jie-fa-cgao-zhi-lian/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
要注意几点:
1.当根节点为空,其路径和不存在而不是为空,0和空在这里是不一样的,之前这个地方就错过
2.这题的终止条件是到叶节点,所以终结条件(正+负)必须是关于叶节点的
3.不论是最大最小还是其他,逻辑关系都体现在dfs的返回方式的逻辑关系上
4.sum这种变化的值可以作为参数
没找到问题出在哪里
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int path = 0;
bool b = false;
void dfs(TreeNode* root, int sum)
{
if(b)return;
if(path>sum)return;
if(!root)return;
if(!root->left && !root->right)
{
if(path==sum)b=true;
return;
}
if(root->left)
{
path += root->left->val;
dfs(root->left,sum);
path -=root->left->val;
}
if(root->right)
{
path += root->right->val;
dfs(root->right,sum);
path -= root->right->val;
}
}
bool hasPathSum(TreeNode* root, int sum) {
if(!root)return false;
path = root->val;
dfs(root, sum);
return b;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool dfs(TreeNode* root, int sum)
{
if(!root->left && !root->right)
{
if(root->val==sum)return true;
return false;
}
if(!root->left && root->right)return dfs(root->right,sum-root->val);
if(!root->right && root->left)return dfs(root->left,sum-root->val);
return dfs(root->left,sum-root->val) || dfs(root->right,sum-root->val);
}
bool hasPathSum(TreeNode* root, int sum) {
if(!root)return false;
return dfs(root,sum);
}
};
113. 路径总和 II
难点是如何应对什么时候存节点,什么时候放节点的问题,这个可以根据例子倒推一下
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
void dfs(TreeNode* root,int sum, int target)
{
if(!root)return;
if(!root->left && !root->right)
{
if(sum + root->val==target){auto path1 = path; path1.push_back(root->val);res.push_back(path1);}
return;
}
path.push_back(root->val);
sum += root->val;
dfs(root->left,sum,target);
dfs(root->right,sum,target);
sum -= root->val;
path.pop_back();
}
vector<vector<int>> pathSum(TreeNode* root, int sum) {
dfs(root,0,sum);
return res;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
public:
void dfs(TreeNode* root,int sum)
{
if(!root->left && !root->right)
{
path.push_back(root->val);
if(root->val==sum) res.push_back(path);
path.pop_back();
return;
}
if(root->left)
{
path.push_back(root->val);
dfs(root->left,sum-root->val);
path.pop_back();
}
if(root->right)
{
path.push_back(root->val);
dfs(root->right,sum-root->val);
path.pop_back();
}
}
vector<vector<int>> pathSum(TreeNode* root, int sum) {
if(!root)return res;
dfs(root,sum);
return res;
}
};
114. 二叉树展开为链表(*****)
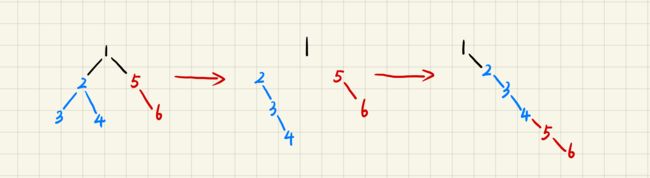
其实是分为三步:
首先将根节点的左子树变成链表
其次将根节点的右子树变成链表
最后将变成链表的右子树放在变成链表的左子树的最右边
这就是一个递归的过程,递归的一个非常重要的点就是:不去管函数的内部细节是如何处理的,我们只看其函数作用以及输入与输出。对于函数flatten来说:
函数作用:将一个二叉树,原地将它展开为链表
输入:树的根节点
输出:无
作者:ming-zhi-shan-you–m9RfkvKDad
链接:https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/solution/114-er-cha-shu-zhan-kai-wei-lian-biao-by-ming-zhi-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution {
public void flatten(TreeNode root) {
if(root == null){
return ;
}
//将根节点的左子树变成链表
flatten(root.left);
//将根节点的右子树变成链表
flatten(root.right);
TreeNode temp = root.right;
//把树的右边换成左边的链表
root.right = root.left;
//记得要将左边置空
root.left = null;
//找到树的最右边的节点
while(root.right != null) root = root.right;
//把右边的链表接到刚才树的最右边的节点
root.right = temp;
}
}
作者:ming-zhi-shan-you--m9RfkvKDad
链接:https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/solution/114-er-cha-shu-zhan-kai-wei-lian-biao-by-ming-zhi-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从最右边的叶节点往回排,即找到最右节点设为last,再找倒数第二个节点,让他右节点设为last,左节点为NULL……直到root节点:
后序遍历
class Solution {
public:
void flatten(TreeNode *root){
TreeNode *last = NULL;
rightorder(root,last);
}
private:
void rightorder(TreeNode *node, TreeNode *&last){
if(!node) return;
rightorder(node->right,last);
rightorder(node->left, last);
node->right = last;
node->left = NULL;
last = node;
}
作者:eaadc
链接:https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list/solution/cong-zui-hou-yi-ge-dao-zhao-lai-gao-xiao-si-lu-by-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
115. 不同的子序列
对于这种矩阵块同时又是字符串的基本都应该使用dp做法,递归很容易超时,dp的表达式可以写几个例子并在例子中进行观察
class Solution {
public:
int numDistinct(string s, string t) {
if(s.empty() || t.empty() ||s.size()<t.size())return 0;
int lens = s.size(), lent = t.size();
vector<vector<long long>> board(lent,vector<long long>(lens,0));
board[0][0] = (s[0]==t[0])?1:0;
for(int j = 1;j<lens ;j++)
{
if(s[j]==t[0])board[0][j]=board[0][j-1]+1;
else board[0][j]=board[0][j-1];
}
for(int i =1 ;i<lent;i++)
{
for(int j =1;j<lens;j++)
{
if(t[i]==s[j])board[i][j]=board[i-1][j-1]+board[i][j-1];
else board[i][j]=board[i][j-1];
}
}
return board[lent-1][lens-1];
}
};
关于字符串的题使用递归由超时了,但是思路应该时对的:把t中的每个字符在s中的位置求出来并组成一个二维数组,里面存放每个t中字符的位置,然后对这个dfs递归计数,在值小于前一个个时需要进行剪枝,这个递归和求所有根节点到子节点时的模板非常像(也有道理)
class Solution {
public:
int res = 0;
string path;
void dfs(string s, string t, int p,int q)
{
if(path==t)
{
res++;
return;
}
for(int i = p;i<s.size();i++)
{
if(s[i]==t[q])
{
path.push_back(s[i]);;
dfs(s,t,i+1,q+1);
path.pop_back();
}
}
}
int numDistinct(string s, string t) {
dfs(s,t,0,0);
return res;
}
};
116. 填充每个节点的下一个右侧节点指针(bfs)
size_t要转int,size_t每次都加个类型转换,不然会造成未知的错误
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node* next;
Node() : val(0), left(NULL), right(NULL), next(NULL) {}
Node(int _val) : val(_val), left(NULL), right(NULL), next(NULL) {}
Node(int _val, Node* _left, Node* _right, Node* _next)
: val(_val), left(_left), right(_right), next(_next) {}
};
*/
class Solution {
public:
Node* connect(Node* root) {
if(!root)return NULL;
queue<Node*> qt;
qt.push(root);
while(!qt.empty())
{
int len = qt.size();
vector<Node*> temp;
for(int i = 0 ; i<len;i++)
{
Node* t = qt.front(); qt.pop();
if(t->left)
{
temp.push_back(t->left);
qt.push(t->left);
}
if(t->right)
{
temp.push_back(t->right);
qt.push(t->right);
}
}
for(int i = 0;i<(int)temp.size()-1;i++)
{
temp[i]->next = temp[i+1];
}
}
return root;
}
};
117. 填充每个节点的下一个右侧节点指针 II(bfs)
和116的代码一摸一样
118. 杨辉三角
class Solution {
public:
vector<vector<int>> generate(int numRows) {
if(numRows==0)return {};
vector<vector<int>> vt = {{1}};
numRows--;
while(numRows-->0)
{
auto pre = vt.back();
int len = pre.size();
vector<int> cur = {1};
for(int i = 0;i<len-1;i++)
{
cur.push_back(pre[i]+pre[i+1]);
}
cur.push_back(1);
vt.push_back(cur);
}
return vt;
}
};
119. 杨辉三角 II
倒推的思想很好使
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
if(triangle.empty())return 0;
int high = triangle.size()-1;
for(int i = 0;i<triangle[high].size();i++)triangle[high][i]=-triangle[high][i];
for(int i = high-1;i>=0;i--)
{
for(int j = 0;j<triangle[i].size();j++)
{
triangle[i][j]= -triangle[i][j]+ max(triangle[i+1][j],triangle[i+1][j+1]);
}
}
return -triangle.front()[0];
}
};
121. 买卖股票的最佳时机(dp)
class Solution {
public:
int maxProfit(vector<int>& prices) {
int m = INT_MAX;
int res = INT_MIN;
for(int i = 0;i<(int)prices.size()-1;i++)
{
m = min(m,prices[i]);
res = max(res,prices[i+1]-m);
}
return res<0?0:res;
}
};
122. 买卖股票的最佳时机 II
class Solution {
public:
int maxProfit(vector<int>& prices) {
int res = 0;
for(int i=1; i< (int)prices.size() ;i++)
{
res += (prices[i]>prices[i-1])?(prices[i]-prices[i-1]):0;
}
return res;
}
};
这道题不适合动态规划,可以用贪心结合双指针做
不用非等到上升到最高点才买,只要上升一次就买一次,低了就不动
class Solution {
public:
int maxProfit(vector<int>& prices) {
//快慢指针标记
int i=0,j=1,sum=0;
//判断vector大小
if(prices.size()<=1)
return 0;
//两个指针一直紧挨在一起,只有j的值大于i的值时,就把差值加入sum中
while(j<prices.size()){
if(prices[j]-prices[i]>0)
sum+=(prices[j]-prices[i]);
i++;
j++;
}
return sum;
}
};
作者:zhong-zhong-ban-da-dui-chang
链接:https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii/solution/ctan-xin-suan-fa-by-zhong-zhong-ban-da-dui-chang/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
123. 买卖股票的最佳时机 III
上题作为一个函数,思路十分清晰
class Solution {
public:
int maxsub(vector<int> prices, int a, int b)
{
int res = 0;
int m = prices[a];
for(int i =a+1;i<b;i++)
{
m = min(m,prices[i-1]);
res = max(res,prices[i]-m);
}
return res;
}
int maxProfit(vector<int>& prices) {
int res = 0;
for(int i =0;i<prices.size();i++)
{
res = max(res,maxsub(prices,0,i)+maxsub(prices,i,prices.size()));
}
return res;
}
};
是在上一题的基础上做的,但是次数再多就不行了,而且这种双循环方式也超时了,但是思路是对的
class Solution {
public:
int maxProfit(vector<int>& prices) {
if(prices.empty())return 0;
int res1 = 0, dp1 = prices[0], res = 0;
for(int i =1 ; i< (int)prices.size() ;i++)
{
dp1 = min(dp1, prices[i]);
res1 = max(res1, prices[i]-dp1);
int dp2 = prices[i];
int res2 = 0;
for(int j = i+1 ; j<(int)prices.size() ;j++)
{
dp2 = min(dp2, prices[j]);
res2 = max(res2, prices[j]-dp2);
}
res = max(res, res1+res2);
}
return res;
}
};
124. 二叉树中的最大路径和(dfs,不懂)
//一个 根,左,右 的路径情况有(根,左+根,根+右,左+根+右)
//但是该根作为其父亲的孩子时,其max 应该为 max(根,左+根,根+右).如果包含左+根+右,则加上其父亲就构不成路径了
class Solution {
public:
int func(TreeNode* root, int &res)
{
if(!root)return 0;
int leftmax = func(root->left,res);
int rightmax = func(root->right,res);
int temp = root->val;
res = max(res, max(temp+leftmax,max(temp+rightmax,max(temp+leftmax+rightmax,temp))));
return max(temp,max(temp+leftmax,temp+rightmax));
}
int maxPathSum(TreeNode* root) {
if(!root)return 0;
int res = 0;
func(root,res);
return res;
}
};
125. 验证回文串
大小写转换
tramsform(s.begin(),s.end(),::tolower)
判断是否是字母
isalpha(c)
class Solution {
public:
bool isPalindrome(string s) {
string s1;
transform(s.begin(),s.end(),s.begin(),::tolower);
for(auto i:s)
{
if(isalpha(i)||isdigit(i))s1 += i;
}
string s2 = s1;
reverse(s1.begin(),s1.end());
return s1==s2;
}
};
bool isPalindrome(string s) {
string s1;
transform(s.begin(),s.end(),s.begin(),::tolower);
int i = 0,j = s.size()-1;
while(i<s.size()&&j>=0)
{
while(i<s.size()&&!isalpha(s[i])&&!isdigit(s[i]))i++;
while(j>=0&&!isalpha(s[j])&&!isdigit(s[j]))j--;
if(i<s.size() && j>=0 && s[i++]!=s[j--])return false;
}
return true;
}
126. 单词接龙 II
dfs超时但是可以做,看到记忆搜索使用一个数据记录
class Solution {
public:
set<vector<string>> res;
vector<string> path;
int m = INT_MAX;
int judge(string a, string b)
{
int count = 0;
for(int i = 0;i<a.size();i++)
{
if(a[i]!=b[i])count++;
}
return count;
}
void dfs(vector<string>& wordList, string start, string end, vector<int>& ref)
{
if(start==end){res.insert(path);m = min(m , (int)path.size()) ;return;}
if(path.size()==wordList.size()-1)return;
for(int i =0;i<wordList.size();i++)
{
if(ref[i]==0 && judge(start,wordList[i])==1)
{
ref[i]=1;
path.push_back(wordList[i]);
dfs(wordList,wordList[i],end,ref);
path.pop_back();
ref[i]=0;
}
}
}
vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {
if(find(wordList.begin(),wordList.end(),endWord)==wordList.end())return {};
vector<int> ref(wordList.size(),0);
vector<vector<string>> r;
dfs(wordList,beginWord,endWord,ref);
for(auto i:res)
{
if(i.size()==m){i.insert(i.begin(),beginWord);r.push_back(i);}
}
return r;
}
};
127. 单词接龙(dfs,bfs)
bfs单向的超时了,双向的不会超时,或者构造出这个图来
class Solution {
public:
int judge(string a, string b)
{
int count = 0;
for(int i = 0;i<a.size();i++)
{
if(a[i]!=b[i])count++;
}
return count;
}
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> st;
queue<string> qt;
st.insert(beginWord); qt.push(beginWord);
int num = 1;
while(!qt.empty())
{
int len = qt.size();
for(int i = 0;i<len;i++)
{
auto temp = qt.front();qt.pop();
if(temp==endWord)return num;
for(int i = 0;i<wordList.size();i++)
{
if(judge(temp,wordList[i])==1&&st.find(wordList[i])==st.end())
{
qt.push(wordList[i]);st.insert(wordList[i]);
}
}
}
num++;
}
return 0;
}
};
dfs
class Solution {
public:
set<vector<string>> res;
vector<string> path;
int m = INT_MAX;
int judge(string a, string b)
{
int count = 0;
for(int i = 0;i<a.size();i++)
{
if(a[i]!=b[i])count++;
}
return count;
}
void dfs(vector<string>& wordList, string start, string end, vector<int>& ref)
{
if(start==end){res.insert(path);m = min(m , (int)path.size()) ;return;}
if(path.size()==wordList.size()-1)return;
for(int i =0;i<wordList.size();i++)
{
if(ref[i]==0 && judge(start,wordList[i])==1)
{
ref[i]=1;
path.push_back(wordList[i]);
dfs(wordList,wordList[i],end,ref);
path.pop_back();
ref[i]=0;
}
}
}
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
if(find(wordList.begin(),wordList.end(),endWord)==wordList.end())return {};
vector<int> ref(wordList.size(),0);
vector<vector<string>> r;
dfs(wordList,beginWord,endWord,ref);
return (m==INT_MAX)?0:m+1;
}
};
128. 最长连续序列
unordered_set
set本身是带排序的,和map一样,如果只用到set的集合无重复功能而不是其排序的话,最好使用unordered_set而不是set,对于unordered_set来说,其查找与unordered_map哈希表一样,同样是常数的时间。然而红黑树是log的时间
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
if(nums.empty()){
return 0;
}
unordered_set<int> myset(nums.begin(), nums.end());
int res = 0;
for(auto num : nums){
if(myset.count(num-1)==0){
int x = num + 1;
while(myset.count(x)){
x ++;
}
res = max(res, x-num);
}
}
return res;
}
};
作者:anyaleung
链接:https://leetcode-cn.com/problems/longest-consecutive-sequence/solution/cdai-ma-li-yong-unordered_set-by-anyaleung/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
129. 求根到叶子节点数字之和
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<string> res;
string path;
void dfs(TreeNode* root)
{
if(!root->left && !root->right)
{
path += to_string(root->val);
res.push_back(path);
return;
}
path += to_string(root->val);
if(root->left)
{
dfs(root->left);
path.pop_back();
}
if(root->right)
{
dfs(root->right);
path.pop_back();
}
}
int sumNumbers(TreeNode* root) {
if(!root)return 0;
dfs(root);
int count = 0;
for(auto r:res)
{
count +=stoi(r);
}
return count;
}
};
130. 被围绕的区域
典型的记忆性搜索
class Solution {
public:
bool dfs(vector<vector<char>>& board,int len1 ,int len2,int i, int j)
{
if(i<0 || i>=len1 || j<0 || j>=len2)return false;
if(board[i][j]=='X'|| board[i][j]=='A')return true;
board[i][j]='A';
bool k = dfs(board,len1,len2,i-1,j) && dfs(board,len1,len2,i+1,j) && dfs(board,len1,len2,i,j-1) && dfs(board,len1,len2,i,j+1);
board[i][j]='O';
return k;
}
void solve(vector<vector<char>>& board) {
if(board.empty())return;
int len1 = board.size();
int len2 = board[0].size();
for(int i =0;i<len1 ;i++)
{
for(int j=0;j<len2;j++)
{
if(dfs(board,len1,len2,i,j))board[i][j]='X';
}
}
return ;
}
};
131. 分割回文串
class Solution {
public:
bool isok(string a)
{
string a1 = a;
reverse(a.begin(),a.end());
return a==a1;
}
vector<vector<string>> res;
vector<string> path;
void dfs(string s, int p)
{
if(p==s.size())
{
res.push_back(path);
return;
}
for(int i = 1;i<s.size()-p+1;i++)
{
if(isok(s.substr(p,i)))
{
path.push_back(s.substr(p,i));
dfs(s,p+i);
path.pop_back();
}
}
}
vector<vector<string>> partition(string s) {
if(s.empty())return {};
dfs(s,0);
return res;
}
};
132. 分割回文串 II
class Solution {
public:
bool isok(string a)
{
string a1 = a;
reverse(a.begin(),a.end());
return a==a1;
}
vector<string> path;
int res = INT_MAX;
void dfs(string s, int p)
{
if(p==s.size()){res=min(res,(int)path.size());return;}
for(int i=s.size()-p+1;i>=1;i--)
{
if(isok(s.substr(p,i)))
{
path.push_back(s.substr(p,i));
dfs(s,i+p);
path.pop_back();
}
}
}
int minCut(string s) {
if(s.empty())return 0;
dfs(s,0);
return res-1;
}
};
134. 加油站
class Solution {
public:
int canCompleteCircuit(vector<int>& gas, vector<int>& cost) {
int len = gas.size();
for(int i = 0;i<len;i++)
{
int count = gas[i];
for(int j = (i+len)%len; j-i<len; j++)
{
count -= cost[(j+len)%len];
if(count<0)break;
count += gas[(j+1)%len];
}
count -= cost[i];
if(count>=0){return i;}
}
return -1;
}
};
135. 分发糖果
双端遍历法
对于某些题目,左右各有各自的规则,这种情况不应使用双指针,而是两个数组的双端遍历,最后根据某种关系再结合
左右各遍历一遍然后取最大
class Solution {
public:
int candy(vector<int>& ratings) {
int len = ratings.size();
vector<int> vt1(len,1);
vector<int> vt2(len,1);
for(int i = 1;i<len;i++)
{
if(ratings[i]>ratings[i-1])vt1[i]=vt1[i-1]+1;
}
for(int i = len-2;i>=0;i--)
{
if(ratings[i]>ratings[i+1])vt2[i]=vt2[i+1]+1;
}
int res = 0;;
for(int i=0;i<len;i++)
{
res +=max(vt1[i],vt2[i]);
}
return res;
}
};
136. 只出现一次的数字(位运算)
异或
位运算里面的异或是按二进制来的
0与任何数异或时,如果那个位为0,那么相同则为0,如果那位为1,那么不同还为1.同理1和任何数同或都为1.
class Solution {
public:
int singleNumber(vector<int>& nums) {
//交换律:a ^ b ^ c <=> a ^ c ^ b
//任何数于0异或为任何数 0 ^ n => n
//相同的数异或为0: n ^ n => 0
int res = 0;
for(auto i:nums)res ^= i;
return res;
}
};
137. 只出现一次的数字 II(位运算)
统计所有数字中每个位中1出现的总数,那么对于某个位,1出现的次数一定是3的倍数+1或0,那么对这个数%3得到的结果就是目的数字在该位上的值
class Solution {
public:
int singleNumber(vector<int>& nums) {
int res = 0;
for(int i = 0;i < 32;++i){
int sum = 0;
for(int j = 0;j < nums.size();++j){
sum += (nums[j] >> i) & 1;
}
res ^= (sum % 3) << i;
}
return res;
}
};
作者:yzh
链接:https://leetcode-cn.com/problems/single-number-ii/solution/zhi-chu-xian-yi-ci-de-shu-zi-wei-yun-suan-ke-yi-tu/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
138. 复制带随机指针的链表
class Solution {
public:
//方法1
Node* copyRandomList(Node* head)
{
if (head == nullptr)
return head;
//遍历原链表 创建新链表节点并建立映射关系
unordered_map<Node*, Node*> map; //key: 原链表节点 value: 新创建节点
Node* cur = head;
while (cur)
{
map[cur] = new Node(cur->val);
cur = cur->next;
}
//遍历原链表 根据map找新链表的random
cur = head;
while (cur)
{
map[cur]->next = map[cur->next];
map[cur]->random = map[cur->random];
cur = cur->next;
}
return map[head];
}
//方法2
Node* copyRandomList(Node* head)
{
if (head == nullptr)
return head;
//遍历原链表 遍历过程中插入新副本节点
Node* cur = head;
while (cur)
{
Node* node = new Node(cur->val);
Node* next = cur->next;
node->next = next;
cur->next = node;
cur = next;
}
//遍历原链表 对新副本节点设置random指针
cur = head;
while (cur)
{
cur->next->random = cur->random ? cur->random->next : nullptr;
cur = cur->next->next;
}
//分离出原链表与新副本链表
cur = head;
Node* new_cur = head->next;
Node* res = new_cur;
while (cur)
{
cur->next = cur->next->next;
cur = cur->next;
new_cur->next = cur ? cur->next : nullptr;
new_cur = new_cur->next;
}
return res; //注意:不能再返回head->next了,head已经是分离后的原链表
}
};
作者:eric-345
链接:https://leetcode-cn.com/problems/copy-list-with-random-pointer/solution/c-by-eric-345-80/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
139. 单词拆分
class Solution {
public:
bool dfs(string s, vector<string>& wordDict,int start)
{
if(start>=s.size())return true;
for(int i =start; i<s.size();i++)
{
if(find(wordDict.begin(),wordDict.end(),s.substr(start,i-start+1))!=wordDict.end())
{
int temp = start;
bool k = dfs(s,wordDict,i+1);
if(k)return true;
else start = temp;
}
}
return false;
}
bool wordBreak(string s, vector<string>& wordDict) {
return dfs(s,wordDict,0);
}
};
140. 单词拆分 II
class Solution {
public:
vector<string> res;
string path;
void dfs(string s, vector<string>& wordDict,int start)
{
if(start>=s.size()){res.push_back(path);return;}
for(int i =start; i<s.size();i++)
{
if(find(wordDict.begin(),wordDict.end(),s.substr(start,i-start+1))!=wordDict.end())
{
int temp = start;
string temps = path;
path+=s.substr(start,i-start+1)+" ";
dfs(s,wordDict,i+1);
path = temps;
start = temp;
}
}
}
vector<string> wordBreak(string s, vector<string>& wordDict) {
dfs(s,wordDict,0);
for(int i =0;i<res.size();i++)res[i].pop_back();
//for(auto i:res)i.pop_back();
return res;
}
};
141.环形链表
注意fast一开始也是head
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
if(!head||!head->next)return false;
auto slow = head;
auto fast = head->next;
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
if(slow==fast)return true;
}
return false;
}
};
142.环形链表2
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if(!head||!head->next)return NULL;
auto slow = head;
auto fast = head->next;
while(fast && fast->next)
{
fast = fast->next->next;
slow = slow->next;
if(slow==fast)
{
slow = head;
while(fast!=slow)
{
fast = fast->next;
slow = slow->next;
}
return NULL;;
}
}
return NULL;
}
};
143. 重排链表
链表易错点
这几句的顺序不能随意颠倒,如果把第二句放到后面,会发生temp->next赋值时将head也改变了,因为用的是同样的地址,但是将head改变后其地址该改变了就
temp->next = head;
head = head->next;
temp = temp->next;
temp->next = head2;
temp = temp->next;
head2 = head2->next;
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* rever(ListNode* head)
{
ListNode* head1 = new ListNode(0);
head1->next = head;
auto pre = head1;
auto cur = head;
while(cur)
{
auto temp = cur->next;
cur->next = pre;
pre = cur;
cur = temp;
}
head->next = NULL;
return pre;
}
void reorderList(ListNode* head) {
if(!head||!head->next)return ;
auto slow = head;
auto fast = head;
auto p = head;
while(fast&&fast->next)
{
fast = fast->next->next;
p = slow;
slow = slow ->next;
}
p->next = NULL;
auto head2 = rever(slow);
auto root = new ListNode(0);
auto temp =root;
while(head&&head2)
{
temp->next = head;
head = head->next;
temp = temp->next;
temp->next = head2;
temp = temp->next;
head2 = head2->next;
}
head = root->next;
delete root;
return;
}
};
144. 二叉树的前序遍历
非迭代版本
1.首先对在放入左右子节点之前不需要判断,因为有NULL的存在。即使是递归的版本也没放
2.其次对于栈来说,要后进先出,所以右孩子先进,左孩子后进
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> ans;
stack<TreeNode*> s;
s.push(root);
while(!s.empty()){
TreeNode* r=s.top();
s.pop();
if(!r) continue;
ans.push_back(r->val);
s.push(r->right);
s.push(r->left);
}
return ans;
}
};
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
private:
vector<int> res;
public:
void dfs(TreeNode* root)
{
if(root==NULL)return;
res.push_back(root->val);
dfs(root->left);
dfs(root->right);
}
vector<int> preorderTraversal(TreeNode* root) {
dfs(root);
return res;
}
};
145. 二叉树的后序遍历
stack<TreeNode*> mystack;
vector<int> ans;
TreeNode* curr = root;
TreeNode* pre = NULL;
while(curr || !mystack.empty())
{
while(curr)
{
mystack.push(curr);
curr = curr->left;
}
curr = mystack.top();
//若右节点已经访问过或者没有右节点 则输出该节点值
if(!curr->right || pre == curr->right){
mystack.pop();
ans.push_back(curr->val);
pre = curr;
curr = NULL;
}else{
curr = curr->right;
pre = NULL;
}
}
return ans;
作者:jjjjjz
链接:https://leetcode-cn.com/problems/binary-tree-postorder-traversal/solution/c-by-jjjjjz-2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
stack<TreeNode*> mystack;
TreeNode* curr = root;
vector<int> ans;
while(curr || !mystack.empty())
{
while(curr)
{
ans.push_back(curr->val);
mystack.push(curr);
curr = curr->left;
}
curr = mystack.top();
mystack.pop();
curr = curr->right;
}
return ans;
<!-- 中序 -->
vector<int> ans;
stack<TreeNode*> mystack;
TreeNode* curr = root;
while(curr || !mystack.empty())
{
while(curr)
{
mystack.push(curr);
curr = curr->left;
}
curr = mystack.top();
mystack.pop();
ans.push_back(curr->val);
curr = curr->right;
}
return ans;
作者:jjjjjz
链接:https://leetcode-cn.com/problems/binary-tree-postorder-traversal/solution/c-by-jjjjjz-2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
146. LRU缓存机制
使用哈希map和双链表:
逻辑
// key 映射到 Node(key, val)
HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
DoubleList cache;
int get(int key) {
if (key 不存在) {
return -1;
} else {
将数据 (key, val) 提到开头;
return val;
}
}
void put(int key, int val) {
Node x = new Node(key, val);
if (key 已存在) {
把旧的数据删除;
将新节点 x 插入到开头;
} else {
if (cache 已满) {
删除链表的最后一个数据腾位置;
删除 map 中映射到该数据的键;
}
将新节点 x 插入到开头;
map 中新建 key 对新节点 x 的映射;
}
}
较简化的版本
class LRUCache {
public:
//删除、查找、插入的复杂度都O(1)
LRUCache(int capacity) {
cap=capacity;
}
int get(int key) {
if(hashtable.count(key)==0) return -1;
else//更新到表头
{
auto iter = hashtable[key];//找到对应结点地址
cache.splice(cache.begin(),cache,iter);//移动到链表头
return cache.begin()->second;//返回value
}
}
void put(int key, int value) {
if(hashtable.count(key)==0) {
//如果容量到了,删除尾部元素,再加上新结点
if(cache.size()==cap) {
hashtable.erase(cache.back().first);
cache.pop_back();
}//直接添加
cache.push_front(make_pair(key,value));
hashtable[key]=cache.begin();
}
else {//如果插入相同key的元素,除了要移动,value也需要更新
auto iter = hashtable[key];
iter->second=value;//更新地址value
cache.splice(cache.begin(),cache,iter);//移动到链表头
hashtable[key]=cache.begin(); //更新hashtable的value
}
}
unordered_map<int,list<pair<int,int>>::iterator> hashtable;
list<pair<int,int>> cache;//key value
int cap=0;
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
作者:tong-guai
链接:https://leetcode-cn.com/problems/lru-cache/solution/ha-xi-shuang-xiang-lian-biao-you-hua-ban-ben-by-to/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class LRUCache {
public:
LRUCache(int capacity) {
_capacity = capacity;
}
int get(int key) {
if(_map.count(key) != 0)
{
int ret = (*_map[key]).second;
_list.erase(_map[key]);
_list.push_front({key, ret});
_map[key] = _list.begin();
return ret;
}
else return -1;
}
void put(int key, int value) {
if(_map.count(key) == 0)
{
if(_list.size() == _capacity)
{
int k = _list.back().first;
_map.erase(_map.find(k));
_list.pop_back();
}
}
else{
_list.erase(_map[key]);
_map.erase(_map.find(key));
}
_list.push_front({key, value});
_map[key] = _list.begin();
}
private:
unordered_map<int, list<pair<int, int>>::iterator> _map;
list<pair<int, int>> _list;
int _capacity;
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
作者:ma-te-zai-wei-ma
链接:https://leetcode-cn.com/problems/lru-cache/solution/lruhuan-cun-ji-zhi-by-ma-te-zai-wei-ma/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution {
public:
ListNode* insertionSortList(ListNode* head) {
if (!head || !head->next)
return head;
ListNode *dummyhead = new ListNode(-1);//伪头指针
dummyhead->next = head;
ListNode *prev = head;
ListNode *node = head->next;
while (node)
{
if (node->val < prev->val)
{
ListNode* temp = dummyhead;//!!temp要等于dummyhead,这样才可以比较第一个元素
while (temp->next->val < node->val)//!!!这里是temp->next:因为要修改前面的temp的指向
{
temp = temp->next;//指针后移
}
prev->next = node->next;
node->next = temp->next;
temp->next = node;
node = prev->next;//此时不用改变prev指向!因为prev没有变,只是待排序元素变了位置。
}
else
{
prev = prev->next;
node = node->next;
}
}
return dummyhead->next;//!!!不能返回head!!因为后面会改变head所指向内存的位置!
}
};
作者:Smart_Shelly
链接:https://leetcode-cn.com/problems/insertion-sort-list/solution/ccha-ru-pai-xu-xiao-bai-ban-by-tryangel/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
148. 排序链表
链表归并排序
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* merge(ListNode* h1,ListNode* h2 )
{
auto head = new ListNode(0);
auto p =head;
while(h1 && h2)
{
if(h1->val<h2->val){head->next = new ListNode(h1->val);h1 = h1->next;}
else {head->next = new ListNode(h2->val);h2 = h2->next;}
head = head->next;
}
head->next = h1?h1:h2;
return p->next;
}
ListNode* sortList(ListNode* head) {
if(!head || !head->next)return head;
auto slow = head,fast =head;
auto pre = head;
while(fast && fast->next)
{
pre = slow;
slow = slow->next;
fast = fast->next->next;
}
pre->next = NULL;
return merge(sortList(head),sortList(slow));
}
};
150. 逆波兰表达式求值
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
for(auto i:tokens)
{
if(i.back()>='0' && i.back()<='9')
{
st.push(stoi(i));
}
else
{
auto x1 = st.top();st.pop();
auto x2 = st.top();st.pop();
if(i=="+")st.push(x1+x2);
else if(i=="-")st.push(x2-x1);
else if(i=="/")st.push(x2/x1);
else if(i=="*")st.push(x1*x2);
}
}
return st.top();
}
};
151. 翻转字符串里的单词
class Solution {
public:
string reverseWords(string s) {
string res;
int len = (int)s.size();
int j = len -1;
while(j>=0)
{
while(j>=0 && s[j]==' ')j--;
if(j<0)break;
int end = j;
while(j>=0 && s[j]!=' ')j--;
res = res +s.substr(j+1,end-j)+ " ";
}
if(!res.empty())res.pop_back();
return res;
}
};
152. 乘积最大子数组(dp)
解题思路
这题是求数组中子区间的最大乘积,对于乘法,我们需要注意,负数乘以负数,会变成正数,所以解这题的时候我们需要维护两个变量,当前的最大值,以及最小值,最小值可能为负数,但没准下一步乘以一个负数,当前的最大值就变成最小值,而最小值则变成最大值了。
class Solution {
public:
int maxProduct(vector<int>& nums) {
if(nums.empty())return 0;
if(nums.size()==1)return nums[0];
int len = nums.size();
vector<int> resmax(len,0);
vector<int> resmin(len,0);
resmax[0] = nums[0];
resmin[0] = nums[0];
for(int i = 1;i<nums.size();i++)
{
resmax[i] = max(resmax[i-1]*nums[i],max(nums[i],resmin[i-1]*nums[i]));
resmin[i] = min(resmax[i-1]*nums[i],min(nums[i],resmin[i-1]*nums[i]));
}
return *max_element(resmax.begin(),resmax.end());
}
};
153. 寻找旋转排序数组中的最小值
class Solution {
public:
int findMin(vector<int>& nums) {
int left = 0;
int right = nums.size();
if(nums.front()<=nums.back())
{
return nums.front();
}
while(left<right)
{
int mid = left + (right-left)/2;
if(nums[mid-1]>nums[mid])
{
return nums[mid];
}
else if(nums[mid]>nums[0])
{
left = mid+1;
}
else
{
right = mid;
}
}
return 0;
}
};
154. 寻找旋转排序数组中的最小值 II
class Solution {
public:
int findMin(vector<int>& nums) {
while(nums.size()>1 && nums.front()==nums.back())nums.pop_back();
if(nums.empty())return 0;
if(nums.front()<=nums.back())return nums.front();
int i = 0;
int len = nums.size();
vector<int> nums1;
while(i<len)
{
int temp = nums[i];
while(i<len && nums[i]==temp)i++;
nums1.push_back(temp);
}
int left = 0,right = nums1.size();
while(left<right)
{
int mid = left + (right-left)/2;
if(nums1[mid-1]>nums1[mid])
{
return nums1[mid];
}
else if(nums1[mid]>nums1[0])
{
left = mid+1;
}
else
{
right = mid;
}
}
return 0;
}
};
155. 最小栈
class MinStack {
public:
/** initialize your data structure here. */
stack<pair<int,int>> st;
MinStack() {
}
void push(int x) {
if(st.empty())
{
st.push(make_pair(x,x));return;
}
else
{
auto temp = st.top();
st.push(make_pair(x,min(x,temp.second)));return;
}
}
void pop() {
st.pop();
}
int top() {
return st.top().first;
}
int getMin() {
return st.top().second;
}
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(x);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->getMin();
*/
160. 相交链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if(!headA || !headB)return NULL;
auto a = headA,b = headB;
while(a!=b)
{
if(!a)a=headB;
else a = a->next;
if(!b)b=headA;
else b = b->next;
}
return a;
}
};
162. 寻找峰值
直接做是不符合要求的,看到logN应该直接想到使用二分法
class Solution {
public:
int findPeakElement(vector<int>& nums) {
int len = nums.size();
if(len==1)return 0;
if(nums[0]>nums[1])return 0;
if(nums[len-1]>nums[len-2])return len-1;
int left = 1;
int right = len-1;
while(left<right)
{
int mid = left + (right-left)/2;
if(nums[mid]>nums[mid-1] && nums[mid]>nums[mid+1])
{
return mid;
}
else if(nums[mid-1]<nums[mid])
{
left = mid +1;
}
else
{
right = mid;
}
}
return 0;
}
};
165. 比较版本号
class Solution {
public:
vector<int> func(string s)
{
vector<int> res;
int i = 0,len = s.size();
while(i<len)
{
int j = i;
while(i<len && s[i]!='.')i++;
string s1 = s.substr(j,i-j);
int k = 0, l = s1.size();
while(k<l-1 && s1[k]=='0')k++;
string s2 = s1.substr(k,l-k);
res.push_back(stoi(s2));
i++;
}
return res;
}
int compareVersion(string version1, string version2) {
auto v1 = func(version1);
auto v2 = func(version2);
int i = 0,j = 0;
while(i<v1.size() && j<v2.size())
{
if(v1[i]==v2[j]){i++;j++;continue;}
else if(v1[i]<v2[j])return -1;
else return 1;
}
if(i<v1.size())
{
while(i<v1.size() && v1[i]==0)i++;
if(i==v1.size())return 0;
else return 1;
}
if(j<v2.size())
{
while(j<v2.size() && v2[j]==0)j++;
if(j==v2.size())return 0;
else return -1;
}
return 0;
}
};
167. 两数之和 II - 输入有序数组
之前做过一道两数之和的,所以 在这里面使用了查找法,凡是查找需要遍历,所以这样做会超时,更好的办法是双指针一个在前一个在后,这里双指针法更好的原因是数组已经排序好了,,可以有规律的缩小双指针的范围
class Solution {
public:
vector<int> twoSum(vector<int>& numbers, int target) {
int left = 0;
int right = numbers.size()-1;
while(left<right)
{
if(numbers[left]+numbers[right]==target)return {left+1,right+1};
else if(numbers[left]+numbers[right]>target)right--;
else left++;
}
return {};
}
};
168. Excel表列名称
class Solution {
public:
string convertToTitle(int n) {
string res;
while (n > 26)
{
auto temp = n / 26;
n = n % 26;
if (n == 0){temp--; n+=26;}
if (temp > 26) {
res += convertToTitle(temp); continue;
}
if (n == 0){temp--; n+=26;}
string s = "";
s += ('A' + temp-1);
res += s;
}
string s = "";
s += 'A'+n-1;
res += s;
return res;
}
};
169. 多数元素(mol计数)
class Solution {
public:
int majorityElement(vector<int>& nums) {
int num = 0,count = 0;
for(auto i:nums)
{
if(i==num)count++;
else
{
if(count==0)num=i;
else count--;
}
}
return num;
}
};
171. Excel表列序号
这道题是之前翻过来了,从这道题的解法可以知道之前只要先对数做一下
class Solution {
public:
int titleToNumber(string s) {
int res = 0;
for(auto c:s)
{
auto temp = c-'A'+1;
res = res *26 + temp;
}
return res;
}
};
172. 阶乘后的零
class Solution {
public:
int trailingZeroes(int n) {
int res = 0;
while(n)
{
res += n/5;
n = n/5;
}
return res;
}
};
173. 二叉搜索树迭代器
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class BSTIterator {
public:
vector<int> tree;
int i = 0,len = 0;
BSTIterator(TreeNode* root) {
midorder(root);
len = tree.size();
}
/** @return the next smallest number */
int next() {
return tree[i++];
}
/** @return whether we have a next smallest number */
bool hasNext() {
return i!=len;
}
private:
void midorder(TreeNode* root)
{
if(!root)return;
if(root->left)midorder(root->left);
tree.push_back(root->val);
if(root->right)midorder(root->right);
}
};
/**
* Your BSTIterator object will be instantiated and called as such:
* BSTIterator* obj = new BSTIterator(root);
* int param_1 = obj->next();
* bool param_2 = obj->hasNext();
*/
174. 地下城游戏(倒序选择)
使用深度优先搜索,会超时
class Solution {
public:
vector<int> res;
pair<int,int> path;
void dfs(vector<vector<int>>& dungeon,int m,int n,int i,int j)
{
if(i==m || j==n)return;
if(i==m-1 && j==n-1)
{
path.first = path.first + dungeon[m-1][n-1];
path.second = min(path.first,path.second);
res.push_back(path.second);
}
int temp1 = path.first,temp2 = path.second;
path.first = path.first + dungeon[i][j];
path.second = min(path.first,path.second);
dfs(dungeon,m,n, i+1,j);
path.first = temp1;
path.second = temp2;
int temp3 = path.first,temp4 = path.second;
path.first = path.first + dungeon[i][j];
path.second = min(path.first,path.second);
dfs(dungeon,m,n, i,j+1);
path.first = temp3;
path.second = temp4;
}
int calculateMinimumHP(vector<vector<int>>& dungeon) {
int m = dungeon.size();
int n = dungeon[0].size();
dfs(dungeon,m,n,0,0);
return 0-*max_element(res.begin(),res.end())+1;
}
};
dp
这就有一个尴尬的地方,动态规划应该只用一个dp,在取舍是左到右还是上到下的时候,你第一反应是哪个dp小取哪个,但是有可能hp也会对判断造成干扰[[1,-3,3],[0,-2,0],[-3,-3,-3]]也就是在计算dp[1][2][0]的时候应当是选择从dp[0][2][0]那条路线而非选择dp[1][2][0]那条路线。出现了错误同上。因此,应当从右下角开始回到起点。
这道题的变种之前遇到过,但是并没有把那道题的精髓应用到这里,尤其在这种路径选择的题目上,除了dfs全试一遍,我们是不知道哪条路径最好的在做动态规划的时候,所以我们采取从后往前的方式,方向不同结果是不一样的
class Solution {
public:
int calculateMinimumHP(vector<vector<int>>& dungeon) {
int m = dungeon.size();
int n = dungeon[0].size();
vector<vector<pair<int,int>>> dp(m,vector<pair<int,int>>(n,make_pair(0,0)));
dp[0][0].first = dp[0][0].second = dungeon[0][0];
for(int i = 1;i<m;i++)
{
dp[i][0].first = dp[i-1][0].first + dungeon[i][0];
dp[i][0].second = min(dp[i-1][0].second, dp[i][0].first);
}
for(int j =1 ;j<n;j++)
{
dp[0][j].first = dp[0][j-1].first + dungeon[0][j];
dp[0][j].second = min(dp[0][j-1].second ,dp[0][j].first);
}
for(int i =1;i<m;i++)
{
for(int j = 1;j<n;j++)
{
int temp1 = min(dp[i-1][j].first+dungeon[i][j],dp[i-1][j].second);
int temp2 = min(dp[i][j-1].first + dungeon[i][j],dp[i][j-1].second);
if(temp1>temp2)
{
dp[i][j].first = dp[i-1][j].first + dungeon[i][j];
dp[i][j].second = min(dp[i-1][j].second, dp[i][j].first);
}
else
{
dp[i][j].first = dp[i][j-1].first + dungeon[i][j];
dp[i][j].second = min(dp[i][j-1].second ,dp[i][j].first);
}
}
}
return max(1,0-dp[m-1][n-1].second+1);
}
};
从后往前想问题就容易多了
class Solution {
public:
int calculateMinimumHP(vector<vector<int>>& dungeon) {
int m=dungeon.size();
int n=dungeon[0].size();
vector<vector<int>> dp(m+1,vector<int>(n+1,INT_MAX));
dp[m-1][n]=1;
dp[m][n-1]=1;
dp[m-1][n-1]=max(1,1-dungeon[m-1][n-1]);
for(int i=m-1;i>=0;i--){
for(int j=n-1;j>=0;j--){
dp[i][j]=max(1, min(dp[i+1][j],dp[i][j+1])-dungeon[i][j] );
}
}
return dp[0][0];
}
};
作者:yyc-13
链接:https://leetcode-cn.com/problems/dungeon-game/solution/174-dungeon-game-qiong-ju-dong-tai-gui-hua-yyc-by-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
175. 组合两个表
# Write your MySQL query statement below
select FirstName,LastName,City,State from Person left join Address on Person.PersonId = Address.PersonId;
176. 第二高的薪水
# Write your MySQL query statement below
select max(Salary) as SecondHighestSalary from Employee where Salary<
(
select max(Salary) from Employee
);
177. 第N高的薪水
思路2:子查询
排名第N的薪水意味着该表中存在N-1个比其更高的薪水
注意这里的N-1个更高的薪水是指去重后的N-1个,实际对应人数可能不止N-1个
最后返回的薪水也应该去重,因为可能不止一个薪水排名第N
由于对于每个薪水的where条件都要执行一遍子查询,注定其效率低下
select count(distinct Salary) from Employee where Salary >= e.Salary 查找比当前薪资大与等于的个数。个数即排名。也就是这就话在做查找当前记录的排名
(select count(distinct Salary) from Employee where Salary >= e.Salary )相当于对salary进行了排名,salary相同的排同一个名次
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
SELECT
DISTINCT e.salary 去重工资
FROM
employee e 指定表
WHERE
(SELECT count(DISTINCT salary) FROM employee WHERE salary>e.salary) = N-1
);
END
178. 分数排名
select s1.Score,count(distinct(s2.score)) Rank
from
Scores s1,Scores s2
where
s1.score<=s2.score
group by s1.Id
order by Rank
179. 最大数
一开始想的是把所有数字都变成数组的形式,然后使用sort进行排序,但是会有一个问题,30和3进行比较的话肯定会认为30大并且在前,但是最后303显然没有330大,所以这种方法是有问题的
题目解析:根据题目中给的例子来看,主要就是要给给定数组进行排序,但是排序方法不是普通的升序或者降序,因为9要排在最前面,而9既不是数组中最大的也不是最小的,所以我们要自定义排序方法。对于两个数字a和b来说,如果将其都转为字符串,如果ab > ba,则a排在前面,比如9和34,由于934>349,所以9排在前面,再比如说30和3,由于303<330,所以3排在30的前面。按照这种规则对原数组进行排序后,将每个数字转化为字符串再连接起来就是最终结果。
————————————————
版权声明:本文为CSDN博主「pushup8」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/pushup8/article/details/85196465
class Solution {
public:
string largestNumber(vector<int>& nums) {
string res = "";
sort(nums.begin(), nums.end(), [](int a, int b){
return to_string(a) + to_string(b) > to_string(b) + to_string(a);
});
for(auto num : nums){
res += to_string(num);
}
return res[0] == '0' ? "0" : res;
}
};
自己写的
注意sort函数重写的四个要素1.static2.inline3.const4.&
class Solution {
public:
static inline bool func(const string& a, const string& b)
{
return a+b>b+a;
}
string largestNumber(vector<int>& nums) {
vector<string> st;
//st.assign(nums.begin(),nums.end());
for(auto i:nums)st.push_back(to_string(i));
sort(st.begin(),st.end(),func);
string res;
for(auto i:st)res += i;
while( (int)res.size()>1 && res[0]=='0')res = res.substr(1,(int)res.size()-1);
return res;
}
};
181. 超过经理收入的员工
from 之后的还必须加,如果不加as重新命名就会出错
# Write your MySQL query statement below
select name employee from Employee as a where
(
salary > (
select salary from Employee where id = a.managerid
)
);
182. 查找重复的电子邮箱
select Email from
(
select Email, count(Email) as num
from Person
group by Email
) as statistic
where num > 1
;
作者:LeetCode
链接:https://leetcode-cn.com/problems/duplicate-emails/solution/cha-zhao-zhong-fu-de-dian-zi-you-xiang-by-leetcode/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
183. 从不订购的客户
# Write your MySQL query statement below
select name as customers from customers c where c.id not in
(
select customerid from orders
);
187. 重复的DNA序列
class Solution {
public:
vector<string> findRepeatedDnaSequences(string s) {
if(s.size()<10)return {};
unordered_map< string,int> mp;
set<string> res;
for(int i = 0;i<=s.size()-10;i++)
{
auto temp = s.substr(i,10);
if(mp.find(temp)==mp.end())
{
mp[temp]++;
}
else
{
res.insert(temp);
}
}
vector<string> r(res.begin(),res.end());
return r;
}
};
189. 旋转数组
class Solution {
public:
void rotate(vector<int>& nums, int k) {
int len = nums.size();
vector<int> res;
for(int i = len-k%len;i<2*len-k%len;i++)
{
res.push_back(nums[i%len]);
}
nums = res;
}
};
198. 打家劫舍(dp)
有点像爬楼梯问题,找到与之前的关系就行了
class Solution {
public:
int rob(vector<int>& nums) {
//这个特别像台阶问题,当前值又当前值加上前一个和前两个的最大值
int len = nums.size();
if(len==0)return 0;
if(len==1)return nums[0];
if(len==2)return max(nums[0],nums[1]);
vector<int> dp = nums;
dp[0]= nums[0]; dp[1]=max(nums[0],nums[1]);
for(int i = 2 ; i<len ; i++)
{
dp[i] = max( nums[i]+dp[i-2] , dp[i-1] );
}
return dp[len-1];
}
};
class Solution {
public:
int rob(vector<int>& nums) {
if(nums.empty())return 0;
if(nums.size()==1)return nums[0];
if(nums.size()==2)return max(nums[0],nums[1]);
int len = nums.size();
vector<int> dp(len);
dp[0]=nums[0];
dp[1]=nums[1];
dp[2]=max(nums[1],nums[0]+nums[2]);
int res = max(nums[0]+nums[2],nums[1]);
for(int i =3;i<len;i++)
{
dp[i]=max(dp[i-1],max(dp[i-2]+nums[i],dp[i-3]+nums[i]));
res = max(res,dp[i]);
}
return res;
}
};
199. 二叉树的右视图
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
private:
vector<int> res;
public:
void dfs(vector<TreeNode*> cur)
{
if(cur.empty())return;
int len = cur.size();
res.push_back(cur[len-1]->val);
vector<TreeNode*> next;
for(auto i:cur)
{
if(i->left!=NULL)next.push_back(i->left);
if(i->right!=NULL)next.push_back(i->right);
}
dfs(next);
}
vector<int> rightSideView(TreeNode* root) {
if(root==NULL)return {};
vector<TreeNode*> temp={root};
dfs(temp);
return res;
}
};
非递归
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
if(!root)return {};
vector<vector<int>> res;
queue<TreeNode*> qt;
qt.push(root);
res.push_back({root->val});
while(1)
{
int len = qt.size();
vector<int> r;
for(int i = 0;i<len;i++)
{
auto temp = qt.front();qt.pop();
if(temp->left){qt.push(temp->left);r.push_back(temp->left->val);}
if(temp->right){qt.push(temp->right);r.push_back(temp->right->val);}
}
if(!r.empty())res.push_back(r);
else break;
}
vector<int> rr;
for(auto i:res)
{
rr.push_back(i.back());
}
return rr;
}
};