语音识别基础(一)——语音信号的产生和特性
最近在看语音识别,一直弄不明白模型到底是怎么进行工作的,于是决定从最基础的了解起,包括语音信号的产生、传播、分析。并在此记录以下,方便以后查找复习。由于重心放在声学模型、算法上,所以这些知识并没有很深入的介绍,都是为了理解确实可以用GMM-HMM或深度学习方法来进行语音识别而服务的。估计写两到三篇,如有不当之处,还请各位大佬指正。
声明:
本篇文章所有内容均由赵力老师编著的《语音信号处理》第二版和韩纪庆、张磊、郑铁然老师编著的《语音信号处理》总结或摘抄而来,版权仍归原版权所有人所有,如有侵权,请联系我删除,仅作学习交流使用,不得商用。
文章目录
- 1. 综述
- 2. 语音信号的产生
- 2.1 人的说话过程
- 2.2 语音的产生
- 2.3 术语总结
- 2.4 语音的声学特征
- 3. 语音信号的数学表示
- 3.1 时域波形
- 3.2 频域表示
- 3.3 语谱图
- 4. 语音分类
- 4.1 汉语中的语音分类
- 4.2 英语音素表
1. 综述
语音是在说话人和听者之间互相传递的信息,传递的媒介是声波。说话人的发音器官做出发声动作,接着空气振动形成声波,声波传到听者的耳朵里,立即引起听者的听觉反应,语音的传递就是这样一个过程。其中,发音动作属于生理现象,空气振动属于物理现象,而听觉反应属于心理现象。
从语音传递过程来研究语音的三个分支:
- 发音语音学(articulatory phonetics):它从生理角度研究语音,是最早发展起来的语音学。通过直接观察发音器官分析和仪器分析相结合,可以清楚的认识到语音的发音部位和发音方法。
- 声学语音学(acoustic phonestic):它从声学角度研究语音的物理性质,同时考察语音物理性质和发音器官之间的关系,从20世纪40年代开始发展。随着“频谱仪”(sound spectrograph)以及其他电子声学仪器的发明,声学语音学也得到迅速发展,人们对语音的声学性质的认知不断深入。于是,进一步出现了声音模拟、语音合成以及语音识别等研究。
- 听觉语音学和心理语言学(auditory phonestic and psycholingustics):因为语言传递的起点和终点都在大脑,因此,它以大脑作为研究对象,是比较新的学科。其目的是探索大脑通过什么步骤或者什么方式来进行语音的发出和接受,以及语言信息又是以什么形式在大脑的什么部位存储起来。声音到达大脑的第一关是人耳,即听觉系统的起点在人耳,因此,听觉语音学和心理语言学还要研究人耳的构造,以及人耳是如何传递声波的。
2. 语音信号的产生
2.1 人的说话过程

如图1,首先,人在头脑里产生想要用语言表达的信息;然后将这些信息转化为语言编码,即将这些信息用其所包含的音素序列、韵律、响度、基音周期的升降等表示出来,一旦对这些信息完成编码以后,说话人利用一些神经肌肉命令有关部分的肌肉(包括:唇,舌头,声带,腭等)协调地动作,发出声音来;再通过声波为媒介,将语音信号传到听话人耳中,听者开始感知语音信号。听者内耳的基底膜对语音信号进行动态的频谱分析,神经传感器将基底膜的频谱信号转换成对听觉神经的触动信号(类似特征提取),作用在听觉神经上的活动信息,在大脑的更高层的中枢转化成语言编码并由此产生语义信息。
2.2 语音的产生
人类用来产生语音的发声器官自下而上包括:肺部(lung)、气管(trachea)、喉(larynx)、鼻腔(nasal cavity)、口腔(oral cavity)和上、下唇。它们作为一个整体形成了一个形状复杂的管道,如图2所示。喉的部分称为声门,从声门到嘴唇的呼气通道叫做声道(咽腔、口腔、鼻腔三个腔体),随着发出的语音的不同,其形状是不断变化的。语音的产生可以大致分为三步:
- 肺部的空气被横隔膜挤出,形成气流,这个气流就是语音产生的原动力。气流经过气管到达喉部(由甲状软骨、杓状软骨、环状软骨和会厌软骨组成),喉部的两个声带(甲状软骨到杓状软骨之间的韧带褶)之间组成声门(呈“ Λ \Lambda Λ”型,如图3)。此时,声带受到气流的冲击产生振动,不断的张开和闭合,使声门向上送出一连串的喷流形成一系列准周期的脉冲,一般用非对称的三角波表示。声道以下称为“声门子系统“,用于激励振动,是激励系统,可以用数学方法对其进行建模,称为”激励模型“(这里就不介绍了);

- 声带振动产生声音,这是产生声音的基本声源,称为声带声源。声带声源进一步调制后经过不同的声道构型,发出不同的语音。是“声道系统”,用数学方法可以建立声道模型。需要注意的是,在此过程中,声道变化非常复杂,是自声门、声带之后最重要、对发音起决定性作用的器官;
- 最后就是在嘴唇开口处将语音辐射出去,是“辐射系统”,对应数学模型的辐射模型。

2.3 术语总结
总结发音过程中的术语,后面会用到
- 基音周期(pitch period):声带每开启和闭合一次的时间就是基音周期,倒数称为基音频率(多种因素综合作用)。一般在80Hz~500Hz之间,是反映说话人特点的一个重要参数,同时也反映汉语语音中的声调变化。
- 音色:也叫音质,由于发声体的材料和结构等不同,发出的音色不同,是区别两种声音的基本特征;
- 声音的音高是由发声体的振动频率决定的,声音的响度是由发声体的振幅决定的.音高与频率,响度与频率均成正比;
- 倍音:某一语音频率是基音频率的整数倍,则称之为倍音;
- 复合音(complex tone)和纯音(pure tone):纯音中仅含基音(频率最低的音),复合音中包含基音和倍音,一般我们听到的声音多为复合音;
- 声带放松时,会产生噪声型音或摩擦音,还有爆破音,用不上,就不介绍了。
2.4 语音的声学特征
前面介绍了语音的形成过程,现在来看看语音的声学特征。语音通过声波传递,声波是一种纵波,即它的传播方向和振动方向相同。和普通波一样,声波也具有频率和振幅两个特性,频率与声音的音高有关,振幅与声音的响度有关。
说话时一次发出的,具有一个响亮的中心,并被明显感觉到的语音片段叫做音节(syllable)。一个音节由一个音素(phoneme)或者几个音素组成,它是语音发音的最小单位。任何语言都具有元音(vowel)和辅音(consonant)两种音素。形成原理:
- 当声带振动发出的声音气流丛喉腔、咽腔进入口腔丛唇腔出去时,这些声腔完全开放,气流顺利通过,这种声音称为元音;
- 当呼出的气流由于通路的某一部分封闭起来或受到阻碍,气流被阻不能畅通,而克服发音器官的这种阻碍而产生的音素称为辅音。辅音分为浊音(voiced sound)和清音(unvoiced sound)两种:当声带振动时产生的声音为浊音,不伴有声带振动的声音为清音。
根据研究观察,不管从长度还是能量看,元音构成一个音节的主干,辅音则只出现在音节的前、后端或前后两端。决定元音的主要因素是舌头的形状和位置、嘴唇的形状等。

如果将舌位高低分为高、中、低,前后分为前、中、后,再配合口唇开放程度、咽宽度就可以发出十多种不同的单元音,如图5所示。
元音的另一个重要声学特征是共振峰。共振现象是普遍存在的。因此,从物理角度看,声波在声道中传播的时候,有的被反弹,有的被吸收,造成一部分频率增强,一部分频率衰减。因此,在发声时声道可以看成是一个共鸣器。当元音激励进入声道时会引起共振特性,产生一组共振频率,称为共振峰频率,简称共振峰,不同的元音对应一组不同的共振峰参数(一般包括共振峰的位置和频带宽度)。实际应用中,一般采用前三个共振峰(分别为 F 1 , F 2 , F 3 F_1,F_2,F_3 F1,F2,F3)就能够区分开来。

如图6就是以 F 1 F_1 F1为横坐标, F 2 F_2 F2为纵坐标绘制的汉语元音三角图。需要注意的是元音在图中的分布是一个区域,而不是一个点,因为不同的人发同一元音共振峰是不同的。
3. 语音信号的数学表示
前面说了那么多语音的发声知识之类的,都是为了理解怎么把语音转化为数学表示。更深入的了解就没有必要了,重点是理解声学模型。下面开始了。
3.1 时域波形
语音信号最直观、最直接的表示就是它的时域波形。如下图7所示,是一个女性说“开始”的时域波形。语音数据是在实验室环境下用普通麦克风录制的,采样频率为 16 k H z 16kHz 16kHz,每个采样点用16位进行量化。图中横轴表示时间,纵轴表示信号的幅度。图中,虽然无法辨别语音波形的细节,但是可以看出语音能量的起伏,以及语音信号随时间变化的过程。
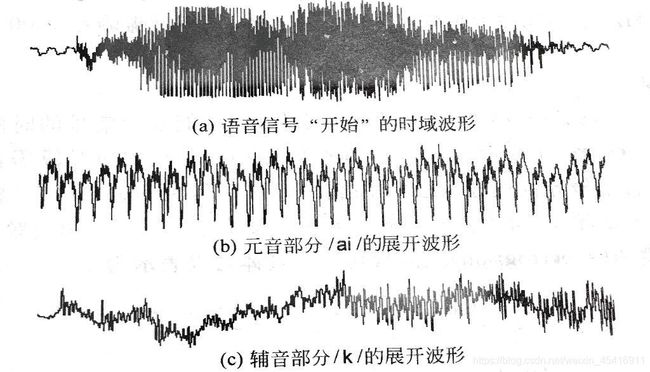
图(b)是将“开”的元音部分 / a i / /ai/ /ai/拉长过后的形状。可以看出,这段语音信号具有很强的周期性,且具有较强的振幅,它的周期对应的就是基音频率。图(c)是辅音 / k / /k/ /k/的展开图,可以看出,辅音波形类似于白噪声,并且具有很弱的振幅。
3.2 频域表示
语音的时域表示简单直接,但是不利于分析其特性,所以一般变换到频域进行分析。无论是从发音器官的共振角度还是听觉器官的频率响应角度来看,频谱都是表征语音特性的基本参数。比如说共振峰就是一个典型的频域参数,它决定信号频谱的总体轮廓或谱包络(spectrum envelope)。
在语音的发音过程中,声道通常处于运动状态,这个运动状态同振动过程相比要缓慢得多,因此一般假设语音信号是短时平稳信号,在一个很短的时间内(10~30ms)是相对平稳的,但在长时间语音周期中语音信号的特性会发生变化,这种变化的不同决定了产生语音的不同。根据语音的这个特点,在每一时刻都可以用该时刻附近的一短段语音信号分析的得到一个频谱。如下图8所示,给出来“开始”中的 / a i / /ai/ /ai/的频谱特性。其中横轴表示频率,变化范围是采样频率的一半,纵轴表示该频率的强弱,以分贝( d B dB dB)为单位。短时分析为汉明窗,进行频谱分析的窗长为512个采样点。

3.3 语谱图
从上面介绍可以看出对语音进行单独的时域分析或频域分析都无法同时兼顾语音的频率特性和它随时间变化的关系。因为语音信号是一种短时平稳信号,可以在每个时刻附近的的短时段语音信号分析得到一种频谱,将语音信号连续的进行这种频谱分析,可以得到一种三维频谱,它的横坐标表示时间,纵坐标表示频率,每个像素的灰度值大小反映相应时刻和相应频率的能量。这种把和时序相关的傅里叶分析的显示图形称为语谱图(sonogram或spectrogram)。它综合了频谱图和时域波形的特点,明显地显示出语音频谱随时间变化的情况,或者说是一种动态的频谱。
语谱图由语谱仪得到,语谱仪中的带通滤波器有两种带宽可以供选择:窄带为 45 H z 45Hz 45Hz,宽带为 300 H z 300Hz 300Hz。窄带语谱图具有良好的频率分辨率,有利于显示基音频率及其各次谐波,但是它的时间分辨率较差(约11ms左右),不利于观察共振峰的变化;宽带语谱图相反,具有较差的频率分辨率,但是它的时间分辨率良好(约1.6ms),宽带语谱图能够给出语音的共振峰频率及清辅音的能量汇集区,共振峰呈现为黑色的条纹。还是以“开始”的发音为例,下图9分别是宽带和窄带语谱图:

由于宽带语谱图滤波器冲激响应的宽度大约与基音周期相同,因此垂直条纹的间隔时间即为基音周期。窄带语谱图中,可以看到元音的共振峰频率及其随着时间的变化,图中较粗的黑色带即为共振峰,该“横杠”随时间起伏变化。各个谐波表现为横向的波纹。
4. 语音分类
经过上面的学习,对语音信号的产生和它的一些声学特征有了粗略的了解,现在再来看下汉语和英语的语音分类。
4.1 汉语中的语音分类
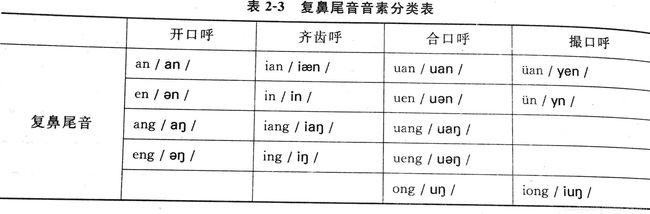
前面说过音素是指发出各不相同音的最小单位,在汉语中,音素构成声母和韵母,汉语包括22个声母(包括零声母)和38个韵母[1]。根据声母和韵母发音动作的不同,可以将音素分为辅音、单元音、复元音和复鼻尾音,这里就不多介绍了,感兴趣的请看韩纪庆、张磊等老师编写的《语音信号处理》这本书。在此,只贴出它们的音素表:


4.2 英语音素表

[1] 权威的汉语拼音方案(非专业人士,不太懂)是1958年定制的(没查到有更新的,望大佬指教),链接:中华人民共和国第一届全国人民代表大会第五次会议关于汉语拼音方案的决议
[2] 赵力.语音信号处理(第二版)[M];机械工业出版社,2009
[3] 韩纪庆,张磊,郑铁然.语音信号处理[M];清华大学出版社,2004