Kafka: ------ 开启幂等性精准一次写入
幂等性
HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
Methods can also have the property of “idempotence” in that (aside from error or expiration issues) the side-effects of N > 0 identical requests is the same as for a single request.
Kafka在0.11.0.0版本支持增加了对幂等的支持。幂等是针对生产者角度的特性。幂等可以保证上生产者发送的消息,不会丢失,而且不会重复。实现幂等的关键点就是服务端可以区分请求是否重复,过滤掉重复的请求。要区分请求是否重复的有两点:
唯一标识:要想区分请求是否重复,请求中就得有唯一标识。例如支付请求中,订单号就是唯一标识
记录下已处理过的请求标识:光有唯一标识还不够,还需要记录下那些请求是已经处理过的,这样当收到新的请求时,用新请求中的标识和处理记录进行比较,如果处理记录中有相同的标识,说明是重复交易,拒绝掉。
Kafka可能存在多个生产者,会同时产生消息,但对Kafka来说,只需要保证每个生产者内部的消息幂等就可以了,所有引入了PID来标识不同的生产者。
对于Kafka来说,要解决的是生产者发送消息的幂等问题。也即需要区分每条消息是否重复。
Kafka通过为每条消息增加一个Sequence Numbler,通过Sequence Numbler来区分每条消息。每条消息对应一个分区,不同的分区产生的消息不可能重复。所有Sequence Numbler对应每个分区
Broker端在缓存中保存了这seq number,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。
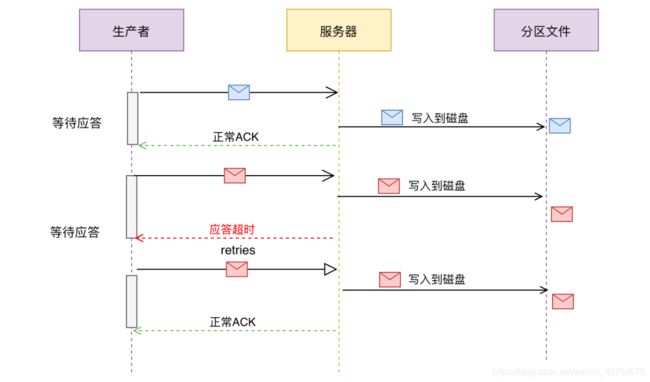
幂等性生产者
package com.baizhi.jsy.ACKandRetries;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Properties;
public class ProductKafkaIdempotence {
public static void main(String[] args) {
//创建生产者
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "Centos:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//优化参数
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 1024 * 1024);//生产者尝试缓存记录,为每一个分区缓存一个mb的数据
properties.put(ProducerConfig.LINGER_MS_CONFIG, 500);//最多等待0.5秒.
//开启幂等性 acks必须是-1
properties.put(ProducerConfig.ACKS_CONFIG,"-1");
//允许超时最大时间
properties.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG,100);
//失败尝试次数
properties.put(ProducerConfig.RETRIES_CONFIG,3);
//开幂等性 精准一次写入
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG,true);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(
"topic01",
"Ack",
"Test Ack And Retries (Idempotence)");
kafkaProducer.send(record);
kafkaProducer.flush();
kafkaProducer.close();
}
}
幂等性消费者
package com.baizhi.jsy.ACKandRetries;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Iterator;
import java.util.Properties;
public class ConsumerKafkaIdempotence {
public static void main(String[] args) {
//创建消费者
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"Centos:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"group01");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
kafkaConsumer.subscribe(Arrays.asList("topic01"));
try {
while (true){
//设置间隔多长时间取一次数据
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
//判断数据是否是空的
if(!consumerRecords.isEmpty()){
Iterator<ConsumerRecord<String, String>> iterator = consumerRecords.iterator();
while (iterator.hasNext()){
ConsumerRecord<String, String> next = iterator.next();
String topic = next.topic();
System.out.println("topic = " + topic);
String key = next.key();
System.out.println("key = " + key);
String value = next.value();
System.out.println("value = " + value);
long offset = next.offset();
System.out.println("offset = " + offset);
int partition = next.partition();
System.out.println("partition = " + partition);
long timestamp = next.timestamp();
System.out.println("timestamp = " + timestamp);
System.out.println();
}
}
}
} catch (Exception e) {
e.printStackTrace();
}finally {
kafkaConsumer.close();
}
}
}