简单看下Java 的内存及其共享
简单看下Java 的内存及其共享
本文简单分析下Java的内存, 结合CPU的的架构, 看看内存共享, 以及为什么会遇到的伪共享的问题.
- 第一: CPU的相关知识
目前的程序大部分跑在多核多线程处理器上, 下面是i3 双核4线程的相关参数图

牙膏厂的i3 处理器架构

上面两张图都是在CPU 内部, 和内存条还没有关系呢
缓存存在的意义: 当时的内存条 速度太慢了, 跟不上CPU的节奏, 等CPU运行完抽两颗烟, 操作RAM的数据在没读写完呢, 同理RAM的存在的意义也是这样的, HDD 硬盘的存取速度太太满了~
注: RAM 包括 缓存和内存条
CPU -> L1 Cache -> L2 Cache -> L3 Cache -> 内存条 ->HDD

上图的读写参数仅供参考, 只是对比速度
盗图一张

总结:
缓存的工作原理是当CPU要读取一个数据时,首先从缓存中查找,如果找到就立即读取并送给CPU处理;如果没有找到,就用相对慢的速度从内存中读取并送给CPU处理,同时把这个数据所在的数据块调入缓存中,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
正是这样的读取机制使CPU读取缓存的命中率非常高,也就是说CPU下一次要读取的数据大部分都在缓存中,只有大约10%需要从内存读取。这大大节省了CPU直接读取内存的时间,也使CPU读取数据时基本无需等待。总的来说,CPU读取数据的顺序是先缓存后内存。
Java 虽是采用JVM的共组机制, 但是原理上还是逃不掉冯·诺依曼体系结构

线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量
在处理器的设计层次上有一个条件: 处理器操作的内存数据是彼此透明的, 即Core1 操作的内存的数据Core2是能看到的.
为了满足这个条件, 处理器一般有会采用两种内存模型(Memory model), 强内存模型, 弱内存模型 的其中一种, 重点是弱内存模型在编程中的使用, 牵涉到内存屏障刷新本地缓存, 并使本地缓存无效, 目的是满足刚才的数据透明条件.
为了保证内存的可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。Java内存模型把内存屏障分为LoadLoad、LoadStore、StoreLoad和StoreStore
举个例子:
ClassCore{
int x = 0, y = 0;
public void writer{
x = 10;
y = 20;
}
public void reader {
int a = y;
int b = x
}
}当并发运行这段代码, 读取Y会得到20, 从程序上看, x = 10; 在执行 y = 20之前; 但是此时去读取X的值能得到10吗? 未必!
因为编译器在编译的时候, 可能把代码执行顺序移动了,
只要代码移动不会改变程序的语义,当编译器认为程序中移动一个写操作到后面会更有效的时候,编译器就会对代码进行移动。如果编译器推迟执行一个操作,其他线程可能在这个操作执行完之前都不会看到该操作的结果,这反映了缓存的影响。
如果被重排了, 那么, a 的值 20, b的值可能是0;

Java 的内存模型 描述了<程序中的变量>以及<内存或者寄存器获取或者读取他们的细节>之间的关系.
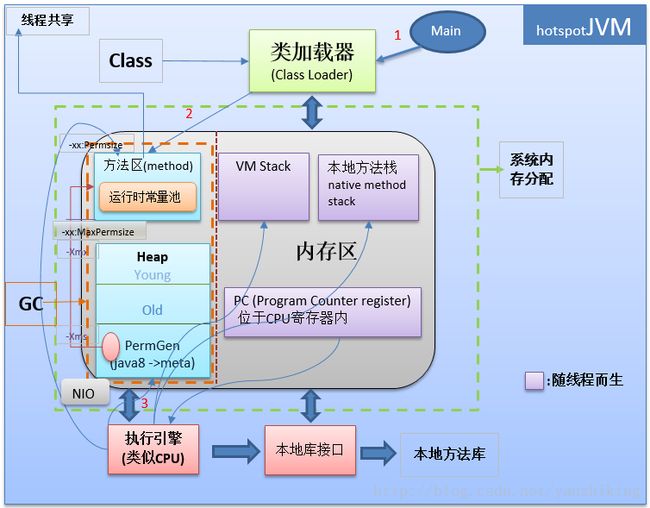
Java 中volatile, final, synchronized关键字的存在, 目的是为了帮助程序员向编译器描述一个程序的并发需求。Java 定义了 volatile synchronized在内存模型中的行为, 为了保证Java 跨平台 跨处理器架构的正确运行.
关于主内存与工作内存之间的具体交互协议 , Java内存模型定义了以下八种操作来完成:
- lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
- unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
- read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
- write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
- load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
- use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
- assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
- store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
Volatile字段是用于线程间通讯的特殊字段。每次读volatile字段都会看到其它线程写入该字段的最新值
伪共享(False Sharing)
缓存系统中是以缓存行(cache line)为单位存储的, 常见是一条缓存行64字节(老式的CPU是32bit的, 缓存行是32B的), 当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
缓存行参见: https://en.wikipedia.org/wiki/CPU_cache
Intel VTune 工具可以分析 相互独立的变量是否存在同一个缓存行内.
如果Core 1, Core 2 想要同时访问位于同一缓存行内的两个不同的变量, 会出现什么问题?
画图来描述下这个问题吧:

变量A , B 位于同一缓存行中, 而Core1 想操作这行中的A, Core2 想操作B, 那他们之间需要竞争获取这行缓存的操作权, 假如Core1 先执行了改变A的值(改变后会更新到主内存), 那么其他缓存中的缓存行的值也就失效了, Core2 刚才费劲load 到的缓存行被标记无效了, 那Core2 不得不从主内存中Read一遍刚才更新后的缓存行进行操作B (必须以整个缓存行作为单位来处理). 缓存中为了保证数据的一致性, 他们会通过L3 来进行中转这种操作. 伪共享就出现了~
解决方案1: 填充缓存行
既然是因为两个变量放在了同一缓存行中导致的问题, 那我们通过填充补全64Byte, 来避免这种冲突.
–下面以long 数据类型为例, 其他数据类型, 需要计算–
//long类型占8Byte cache line padding
public long p1, p2, p3, p4, p5, p6, p7;
//被保护的数据放在中间, 不论怎样截取加载, 都不会和其他有用的数据放在同一缓存行
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, pa, pb, pc, pd, pe;
解决方案2: Java8使用@sun.misc.Contended避免伪共享
原理: 在使用此注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。
/**
* jdk8新特性,Contended注解避免false sharing
* Restricted on user classpath
* Unlock: -XX:-RestrictContended
*/
@sun.misc.Contended
public final static class VolatileLong {
public volatile long value = 1024L;
}
/*或注解加载具体的变量上*/
public class testPadding{
byte a;
@sun.misc.Contended("b")
long b;
@sun.misc.Contended("c")
long c;
int d;
....
}
在运行时需要设置JVM启动参数-XX:-RestrictContended