Java程序员面试题(一)JavaSE基础 - 上
如果觉得文章对您有一点点帮助,麻烦帮忙点个赞?哦
目录
- 一、Java面向对象
- 1. 面向对象都有哪些特性以及你对这些特性的理解
- 2.访问权限修饰符 public、private、protected, 以及不写(默认)时的区别
- 3.如何理解 clone 对象
- 3.1 为什么要用 clone?
- 3.2 new 一个对象的过程和 clone 一个对象的过程区别
- 3.3 clone 对象的使用
- 3.3.1 复制对象和复制引用的区别
- 3.3.2 深拷贝和浅拷贝
- 二、JavaSE 语法
- 1. Java 有没有 goto 语句?
- 2. & 和 && 的区别
- 3. 在 Java 中,如何跳出当前的多重嵌套循环
- 4. 两个对象值相同 (x.equals(y) == true) ,但却可有不同的 hashCode,这句话对不对?
- 5. 是否可以继承 String?
- 6. 当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
- 7. 重载(overload)和重写(override)的区别?重载的方法能否根据返回类型进行区分?
- 8. 为什么函数不能根据返回类型来区分重载?
- 9. char 型变量中能不能存储一个中文汉字,为什么?
- 10. 抽象类(abstract class)和接口(interface)有什么异同?
- 11. 抽象的(abstract)方法是否可同时是静态的(static), 是否可同时是本地方法(native),是否可同时被 synchronized
- 12. 阐述静态变量和实例变量的区别?
- 13. ==和 equals 的区别?
- 14. break 和 continue 的区别?
- 15. String s = "Hello";s = s + " world!";这两行代码执行后,原始的 String 对象中的内容到底变了没有?
- 16. Java 中实现多态的机制是什么?
- 三、Java 的异常处理
- 1. Java 中异常分为哪些种类
- 2. 调用下面的方法,得到的返回值是什么?
- 3. error 和 exception 的区别?
- 4. java 异常处理机制
- 5. 请写出你最常见的 5 个 RuntimeException
- 6. throw 和 throws 的区别
- 7. final、finally、finalize 的区别?
- 四、JavaSE 常用 API
- 1. Math.round(11.5)等于多少?Math.round(- 11.5) 又等于多少?
- 2. switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String上?
- 3. 数组有没有 length() 方法?String 有没有 length() 方法?
- 4. String 、StringBuilder 、StringBuffer 的区别?
- 5. 什么情况下用“+”运算符进行字符串连接比调用 StringBuffer/StringBuilder对象的 append 方法连接字符串性能更好?
- 6. 请说出下面程序的输出
- 7. Java 中的日期和时间
- 7.1 如何取得年月日、小时分钟秒?
- 7.2 如何取得从 1970 年 1 月 1 日 0 时 0 分 0 秒到现在的毫秒数?
- 7.3 如何取得某月的最后一天?
- 7.4 如何格式化日期?
- 五、Java 的数据类型
- 1. Java 的基本数据类型都有哪些各占几个字节
- 2. String 是基本数据类型吗?
- 3. short s1 = 1; s1 = s1 + 1; 有错吗?short s1 = 1; s1 += 1 有错吗;
- 4. int 和 和 Integer 有什么区别?
- 5. 下面 Integer 类型的数值比较输出的结果为?
- 6. String 类常用方法
- 7. 数据类型之间的转换
- 六、Java 的 IO
- 1. Java 中有几种类型的流
- 2. 字节流如何转为字符流
- 3. 如何将一个 java 对象序列化到文件里
- 4. 字节流和字符流的区别
- 5. 如何实现对象克隆?
- 6. 什么是 java 序列化,如何实现 java 序列化?
- 七、Java 的集合
- 1. HashMap 排序题,上机题。
- 2. 集合的安全性问题
- 3. ArrayList 内部用什么实现的?
- 4. 并发集合和普通集合如何区别?
- 5. List 的三个子类的特点
- 6. List 和 Map、Set 的区别
- 6.1 结构特点
- 6.2 实现类
- 6.3 区别
- 7. HashMap 和 HashTable 有什么区别?
- 8. 数组和链表分别比较适合用于什么场景,为什么?
- 9. Java 中 ArrayList 和 Linkedlist 区别?
- 10. List a=new ArrayList()和 ArrayList a =new ArrayList()的区别?
- 11. 要对集合更新操作时,ArrayList 和 LinkedList 哪个更适合?
- 12. 请用两个队列模拟堆栈结构
- 13. Collection 和 Map 的集成体系
- 14. Map 中的 key 和 value 可以为 null 么?
- [Java程序员面试题(一)JavaSE基础 - 下](https://blog.csdn.net/z_z_h_0/article/details/85041004)
一、Java面向对象
1. 面向对象都有哪些特性以及你对这些特性的理解
(1)继承:继承是从已有类得到继承信息创建新类的过程。提供继承信息的类被称为父类(超类、基类);得到继承信息的类被称为子类(派生类)。继承让变化中的软件系统有了一定的延续性,同时继承也是封装程序中可变因素的重要手段。
(2) 封装:通常认为封装是把数据和操作数据的方法绑定起来,对数据的访问只能通过已定义的接口。面向对象的本质就是将现实世界描绘成一系列完全自治、封闭的对象。我们在类中编写的方法就是对实现细节的一种封装;我们编写一个类就是对数据和数据操作的封装。可以说,封装就是隐藏一切可隐藏的东西,只向外界提供最简单的编程接口。
(3) 多态性:多态性是指允许不同子类型的对象对同一消息作出不同的响应。简单的说就是用同样的对象引用调用同样的方法但是做了不同的事情。多态性分为编译时的多态性和运行时的多态性。方法重载(overload)实现的是编译时的多态性(也称为前绑定),而方法重写(override)实现的是运行时的多态性(也称为后绑定)。运行时的多态是面向对象最精髓的东西,要实现多态需要做两件事:1. 方法重写(子类继承父类并重写父类中已有的或抽象的方法);2. 对象造型(用父类型引用,引用子类型对象,这样同样的引用,调用同样的方法就会根据子类对象的不同而表现出不同的行为)。
(4)抽象:抽象是将一类对象的共同特征总结出来构造类的过程,包括数据抽象和行为抽象两方面。抽象只关注对象有哪些属性和行为,并不关注这些行为的细节是什么。
注意:默认情况下面向对象有 3 大特性,封装、继承、多态,如果面试官问让说出 4 大特性,那么我们就把抽象加上去。
2.访问权限修饰符 public、private、protected, 以及不写(默认)时的区别
| 修饰符 | 当前类 | 同 包 | 子 类 | 其他包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
注:重点了解protected和default的区别
3.如何理解 clone 对象
3.1 为什么要用 clone?
在实际编程过程中,我们常常要遇到这种情况:有一个对象 A,在某一时刻 A 中已经包含了一些有效值,此时可能会需要一个和 A 完全相同新对象 B,并且此后对 B 任何改动都不会影响到 A 中的值,也就是说,A 与 B 是两个独立的对象,但 B 的初始值是由 A 对象确定的。在 Java 语言中,用简单的赋值语句是不能满足这种需求的。要满足这种需求虽然有很多途径,但实现 clone()方法是其中最简单,也是最高效的手段。
3.2 new 一个对象的过程和 clone 一个对象的过程区别
new 操作符的本意是分配内存。程序执行到 new 操作符时,首先去看 new 操作符后面的类型,因为知道了类型,才能知道要分配多大的内存空间。分配完内存之后,再调用构造函数,填充对象的各个域,这一步叫做对象的初始化,构造方法返回后,一个对象创建完毕,可以把他的引用(地址)发布到外部,在外部就可以使用这个引用操纵这个对象。
clone 在第一步是和 new 相似的,都是分配内存,调用 clone 方法时,分配的内存和原对象(即调用 clone 方法的对象)相同,然后再使用原对象中对应的各个域,填充新对象的域,填充完成之后,clone 方法返回,一个新的相同的对象被创建,同样可以把这个新对象的引用发布到外部。
3.3 clone 对象的使用
3.3.1 复制对象和复制引用的区别
Person p = new Person(23, "zhang");
Person p1 = p;
System.out.println(p);
System.out.println(p1);
当 Person p1 = p;执行之后, 是创建了一个新的对象吗? 首先看打印结果:
com.itheima.Person@2f9ee1ac
com.itheima.Person@2f9ee1ac
可以看出,打印的地址值是相同的,既然地址都是相同的,那么肯定是同一个对象。p 和 p1 只是引用而已,他们都指向了一个相同的对象 Person(23, “zhang”) 。 可以把这种现象叫做引用的复制。上面代码执行完成之后, 内存中的情景如下图所示:

而下面的代码是真真正正的克隆了一个对象。
Person p = new Person(23, "zhang");
Person p1 = (Person) p.clone();
System.out.println(p);
System.out.println(p1);
从打印结果可以看出,两个对象的地址是不同的,也就是说创建了新的对象, 而不是把原对象的地址赋给了一个新的引用变量:
com.itheima.Person@2f9ee1ac
com.itheima.Person@67f1fba0
3.3.2 深拷贝和浅拷贝
上面的示例代码中,Person 中有两个成员变量,分别是 name 和 age, name 是 String 类型, age 是 int 类型。代码非常简单,如下所示:
public class Person implements Cloneable{
private int age ;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public Person() {}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return (Person)super.clone();
}
}
由于 age 是基本数据类型,那么对它的拷贝没有什么疑议,直接将一个 4 字节的整数值拷贝过来就行。但是 name是 String 类型的, 它只是一个引用, 指向一个真正的 String 对象,那么对它的拷贝有两种方式: 直接将原对象中的 name 的引用值拷贝给新对象的 name 字段, 或者是根据原 Person 对象中的 name 指向的字符串对象创建一个新的相同的字符串对象,将这个新字符串对象的引用赋给新拷贝的 Person 对象的 name 字段。这两种拷贝方式分别叫做浅拷贝和深拷贝。深拷贝和浅拷贝的原理如下图所示:
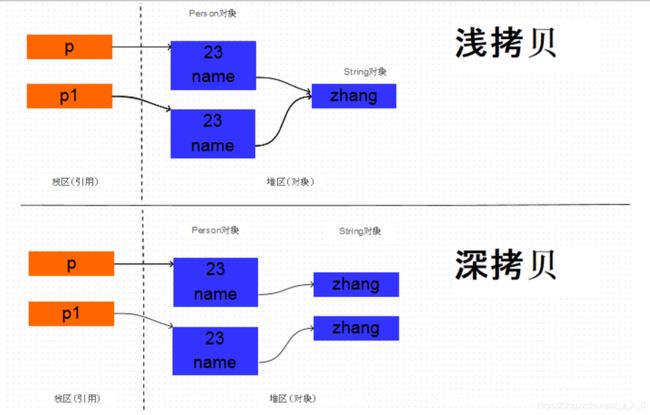
下面通过代码进行验证。如果两个 Person 对象的 name 的地址值相同, 说明两个对象的 name 都指向同一个String 对象,也就是浅拷贝, 而如果两个对象的 name 的地址值不同, 那么就说明指向不同的 String 对象, 也就是在拷贝 Person 对象的时候, 同时拷贝了 name 引用的 String 对象, 也就是深拷贝。验证代码如下:
Person p = new Person(23, "zhang");
Person p1 = (Person) p.clone();
String result = (p.getName() == p1.getName()) ? "clone 是浅拷贝的" : "clone 是深拷贝的";
System.out.println(result);
打印结果为:
clone 是浅拷贝的
所以,clone 方法执行的是浅拷贝, 在编写程序时要注意这个细节。
如何进行深拷贝:
由以上的内容可以得出如下结论:如果想要深拷贝一个对象,这个对象必须要实现 Cloneable 接口,实现 clone方法,并且在 clone 方法内部,把该对象引用的其他对象也要 clone 一份,这就要求这个被引用的对象必须也要实现Cloneable 接口并且实现 clone 方法。那么,按照上面的结论,实现以下代码 Body 类组合了 Head 类,要想深拷贝Body 类,必须在 Body 类的 clone 方法中将 Head 类也要拷贝一份。代码如下:
static class Body implements Cloneable{
public Head head;
public Body() {}
public Body(Head head) {this.head = head;}
@Override
protected Object clone() throws CloneNotSupportedException {
Body newBody = (Body) super.clone();
newBody.head = (Head) head.clone();
return newBody;
}
}
static class Head implements Cloneable{
public Face face;
public Head() {}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public static void main(String[] args) throws CloneNotSupportedException {
Body body = new Body(new Head(new Face()));
Body body1 = (Body) body.clone();
System.out.println("body == body1 : " + (body == body1) );
System.out.println("body.head == body1.head : " + (body.head == body1.head));
}
打印结果为:
body == body1 : false
body.head == body1.head : false
二、JavaSE 语法
1. Java 有没有 goto 语句?
goto 是 Java 中的保留字,在目前版本的 Java 中没有使用。根据 James Gosling(Java 之父)编写的《The Java Programming Language》一书的附录中给出了一个 Java 关键字列表,其中有 goto 和 const,但是这两个是目前无法使用的关键字,因此有些地方将其称之为保留字,其实保留字这个词应该有更广泛的意义,因为熟悉 C 语言的程序员都知道,在系统类库中使用过的有特殊意义的单词或单词的组合都被视为保留字。
2. & 和 && 的区别
&运算符有两种用法:(1)按位与;(2)逻辑与。
&&运算符是短路与运算。逻辑与跟短路与的差别是非常巨大的,虽然二者都要求运算符左右两端的布尔值都是true 整个表达式的值才是 true。
&&之所以称为短路运算是因为,如果&&左边的表达式的值是 false,右边的表达式会被直接短路掉,不会进行运算。很多时候我们可能都需要用&&而不是&,例如在验证用户登录时判定用户名不是 null 而且不是空字符串,应当写为 username != null &&!username.equals(""),二者的顺序不能交换,更不能用&运算符,因为第一个条件如果不成立,根本不能进行字符串的 equals 比较,否则会产生 NullPointerException 异常。注意:逻辑或运算符(|)和短路或运算符(||)的差别也是如此。
3. 在 Java 中,如何跳出当前的多重嵌套循环
在最外层循环前加一个标记如 A,然后用 break A;可以跳出多重循环。(Java 中支持带标签的 break 和 continue语句,作用有点类似于 C 和 C++中的 goto 语句,但是就像要避免使用 goto 一样,应该避免使用带标签的 break和 continue,因为它不会让你的程序变得更优雅,很多时候甚至有相反的作用)。
4. 两个对象值相同 (x.equals(y) == true) ,但却可有不同的 hashCode,这句话对不对?
不对,如果两个对象 x 和 y 满足 x.equals(y) == true,它们的哈希码(hashCode)应当相同。
Java 对于 eqauls 方法和 hashCode 方法是这样规定的:(1)如果两个对象相同(equals 方法返回 true),那么它们的 hashCode 值一定要相同;(2)如果两个对象的 hashCode 相同,它们并不一定相同。当然,你未必要按照要求去做,但是如果你违背了上述原则就会发现在使用容器时,相同的对象可以出现在 Set 集合中,同时增加新元素的效率会大大下降(对于使用哈希存储的系统,如果哈希码频繁的冲突将会造成存取性能急剧下降)。
关于 equals 和 hashCode 方法,很多 Java 程序员都知道,但很多人也就是仅仅知道而已,在 Joshua Bloch的大作《Effective Java》中是这样介绍 equals 方法的。
首先 equals 方法必须满足自反性(x.equals(x)必须返回 true)、对称性(x.equals(y)返回 true 时,y.equals(x)也必须返回 true)、传递性(x.equals(y)和 y.equals(z)都返回 true 时,x.equals(z)也必须返回 true)和一致性(当x 和 y 引用的对象信息没有被修改时,多次调用 x.equals(y)应该得到同样的返回值),而且对于任何非 null 值的引用 x,x.equals(null)必须返回 false。
实现高质量的 equals 方法的诀窍包括:
1. 使用 == 操作符检查"参数是否为这个对象的引用";
2. 使用 instanceof 操作符检查"参数是否为正确的类型";
3. 对于类中的关键属性,检查参数传入对象的属性是否与之相匹配;
4. 编写完 equals 方法后,问自己它是否满足对称性、传递性、一致性;
5. 重写 equals 时总是要重写 hashCode;
6. 不要将 equals 方法参数中的 Object 对象替换为其他的类型,在重写时不要忘掉@Override 注解。
5. 是否可以继承 String?
String 类是 final 类,不可以被继承。
继承 String 本身就是一个错误的行为,对 String 类型最好的重用方式是关联关系(Has-A)和依赖关系(UseA)而不是继承关系(Is-A)。
6. 当一个对象被当作参数传递到一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
是值传递。Java 语言的方法调用只支持参数的值传递。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的属性可以在被调用过程中被改变,但对对象引用的改变是不会影响到调用者的。C++和 C#中可以通过传引用或传输出参数来改变传入的参数的值。说明:Java 中没有传引用实在是非常的不方便,这一点在 Java 8 中仍然没有得到改进,正是如此在 Java 编写的代码中才会出现大量的 Wrapper 类(将需要通过方法调用修改的引用置于一个 Wrapper 类中,再将 Wrapper 对象传入方法),这样的做法只会让代码变得臃肿,尤其是让从 C 和 C++转型为 Java 程序员的开发者无法容忍。
7. 重载(overload)和重写(override)的区别?重载的方法能否根据返回类型进行区分?
方法的重载和重写都是实现多态的方式,区别在于前者实现的是编译时的多态性,而后者实现的是运行时的多态性。重载发生在一个类中,同名的方法如果有不同的参数列表(参数类型不同、参数个数不同或者二者都不同)则视为重载;重写发生在子类与父类之间,重写要求子类被重写方法与父类被重写方法有相同的返回类型,比父类被重写方法更好访问,不能比父类被重写方法声明更多的异常(里氏代换原则)。重载对返回类型没有特殊的要求。
方法重载的规则:
1.方法名一致,参数列表中参数的顺序,类型,个数不同。
2.重载与方法的返回值无关,存在于父类和子类,同类中。
3.可以抛出不同的异常,可以有不同修饰符。
方法重写的规则:
1.参数列表必须完全与被重写方法的一致,返回类型必须完全与被重写方法的返回类型一致。
2.构造方法不能被重写,声明为 final 的方法不能被重写,声明为 static 的方法不能被重写,但是能够被再次声明。
3.访问权限不能比父类中被重写的方法的访问权限更低。
4.重写的方法能够抛出任何非强制异常(UncheckedException,也叫非运行时异常),无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
8. 为什么函数不能根据返回类型来区分重载?
该道题来自华为面试题。
因为调用时不能指定类型信息,编译器不知道你要调用哪个函数。
例如:
float max(int a, int b);
int max(int a, int b);
当调用 max(1, 2);时无法确定调用的是哪个,单从这一点上来说,仅返回值类型不同的重载是不应该允许的。
再比如对下面这两个方法来说,虽然它们有同样的名字和自变量,但其实是很容易区分的:
void f() {}
int f() {}
若编译器可根据上下文(语境)明确判断出含义,比如在 int x=f()中,那么这样做完全没有问题。然而,我们也可能调用一个方法,同时忽略返回值;我们通常把这称为“为它的副作用去调用一个方法”,因为我们关心的不是返回值,而是方法调用的其他效果。所以假如我们像下面这样调用方法: f(); Java 怎样判断 f()的具体调用方式呢?而且别人如何识别并理解代码呢?由于存在这一类的问题,所以不能。
函数的返回值只是作为函数运行之后的一个“状态”,他是保持方法的调用者与被调用者进行通信的关键。并不能作为某个方法的“标识”。
9. char 型变量中能不能存储一个中文汉字,为什么?
char 类型可以存储一个中文汉字,因为 Java 中使用的编码是 Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这是统一的唯一方法),一个 char 类型占 2 个字节(16 比特),所以放一个中文是没问题的。
补充:
使用 Unicode 意味着字符在 JVM 内部和外部有不同的表现形式,在 JVM 内部都是 Unicode,当这个字符被从 JVM 内部转移到外部时(例如存入文件系统中),需要进行编码转换。所以 Java 中有字节流和字符流,以及在字符流和字节流之间进行转换的转换流,如 InputStreamReader 和 OutputStreamReader,这两个类是字节流和字符流之间的适配器类,承担了编码转换的任务;对于 C 程序员来说,要完成这样的编码转换恐怕要依赖于 union(联合体/共用体)共享内存的特征来实现了。
10. 抽象类(abstract class)和接口(interface)有什么异同?
不同:
抽象类:
1.抽象类中可以定义构造器
2.抽象类中的成员全都是 public 的
3.有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法
4.一个类只能继承一个抽象类
接口:
1.接口中不能定义构造器
2.接口中的成员可以是 private、默认、protected、public
3.接口中定义的成员变量实际上都是常量
4.一个类可以实现多个接口
Java8的新特性:接口可以存在默认方法(default 修饰)和静态方法
相同:
1.不能够实例化
2.可以将抽象类和接口类型作为引用类型
3.一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要被声明为抽象类
11. 抽象的(abstract)方法是否可同时是静态的(static), 是否可同时是本地方法(native),是否可同时被 synchronized
都不能。抽象方法需要子类重写,而静态的方法是无法被重写的,因此二者是矛盾的。本地方法是由本地代码(如 C 代码)实现的方法,而抽象方法是没有实现的,也是矛盾的。synchronized 和方法的实现细节有关,抽象方法不涉及实现细节,因此也是相互矛盾的。
12. 阐述静态变量和实例变量的区别?
静态变量: 是被 static 修饰符修饰的变量,也称为类变量,它属于类,不属于类的任何一个对象,一个类不管创建多少个对象,静态变量在内存中有且仅有一个拷贝;
实例变量: 必须依存于某一实例,需要先创建对象然后通过对象才能访问到它。
静态变量可以实现让多个对象共享内存。
13. ==和 equals 的区别?
equals 和 == 最大的区别是一个是方法一个是运算符。
==:如果比较的对象是基本数据类型,则比较的是数值是否相等;如果比较的是引用数据类型,则比较的是对象的地址值是否相等。
equals():用来比较方法两个对象的内容是否相等。
注意:equals 方法不能用于基本数据类型的变量,如果没有对 equals 方法进行重写,则比较的是引用类型的变量所指向的对象的地址。
14. break 和 continue 的区别?
break 和 continue 都是用来控制循环的语句。
break 用于完全结束一个循环,跳出循环体执行循环后面的语句。
continue 用于跳过本次循环,执行下次循环。
15. String s = “Hello”;s = s + " world!";这两行代码执行后,原始的 String 对象中的内容到底变了没有?
没有。因为 String 被设计成不可变(immutable)类,所以它的所有对象都是不可变对象。在这段代码中,s 原先指向一个 String 对象,内容是 “Hello”,然后我们对 s 进行了“+”操作,那么 s 所指向的那个对象是否发生了改变呢?
答案是没有。这时,s 不指向原来那个对象了,而指向了另一个 String 对象,内容为"Hello world!",原来那个对象还存在于内存之中,只是 s 这个引用变量不再指向它了。
通过上面的说明,我们很容易导出另一个结论,如果经常对字符串进行各种各样的修改,或者说,不可预见的修改,那么使用 String 来代表字符串的话会引起很大的内存开销。因为 String 对象建立之后不能再改变,所以对于每一个不同的字符串,都需要一个 String 对象来表示。这时,应该考虑使用 StringBuffer 类,它允许修改,而不是每个不同的字符串都要生成一个新的对象。并且,这两种类的对象转换十分容易。同时,我们还可以知道,如果要使用内容相同的字符串,不必每次都 new 一个 String。例如我们要在构造器中对一个名叫 s 的 String 引用变量进行初始化,把它设置为初始值,应当这样做:
public class Demo {
private String s;
...
s = "Initial Value";
...
}
而非
s = new String("Initial Value");
后者每次都会调用构造器,生成新对象,性能低下且内存开销大,并且没有意义,因为 String 对象不可改变,所以对于内容相同的字符串,只要一个 String 对象来表示就可以了。也就说,多次调用上面的构造器创建多个对象,他们的 String 类型属性 s 都指向同一个对象。
上面的结论还基于这样一个事实:对于字符串常量,如果内容相同,Java 认为它们代表同一个 String 对象。而用关键字 new 调用构造器,总是会创建一个新的对象,无论内容是否相同。 至于为什么要把 String 类设计成不可变类,是它的用途决定的。其实不只 String,很多 Java 标准类库中的类都是不可变的。在开发一个系统的时候,我们有时候也需要设计不可变类,来传递一组相关的值,这也是面向对象思想的体现。不可变类有一些优点,比如因为它的对象是只读的,所以多线程并发访问也不会有任何问题。当然也有一些缺点,比如每个不同的状态都要一个对象来代表,可能会造成性能上的问题。所以 Java 标准类库还提供了一个可变版本,即 StringBuffer。
16. Java 中实现多态的机制是什么?
靠的是父类或接口定义的引用变量可以指向子类或具体实现类的实例对象,而程序调用的方法在运行期才动态绑定,就是引用变量所指向的具体实例对象的方法,也就是内存里正在运行的那个对象的方法,而不是引用变量的类型中定义的方法。
三、Java 的异常处理
1. Java 中异常分为哪些种类
(1)按照异常需要处理的时机分为编译时异常(也叫强制性异常)也叫CheckedException 和运行时异常(也叫非强制性异常)也叫 RuntimeException。只有 java 语言提供了 Checked 异常,Java 认为 Checked异常都是可以被处理的异常,所以 Java 程序必须显式处理 Checked 异常。如果程序没有处理 Checked 异常,该程序在编译时就会发生错误无法编译。这体现了 Java 的设计哲学:没有完善错误处理的代码根本没有机会被执行。对 Checked 异常处理方法有两种:
1 当前方法知道如何处理该异常,则用 try…catch 块来处理该异常。
2 当前方法不知道如何处理,则在定义该方法是声明抛出该异常。
(2)运行时异常只有当代码在运行时才发行的异常,编译时不需要 try catch。Runtime 如除数是 0 和数组下标越界等,其产生频繁,处理麻烦,若显示申明或者捕获将会对程序的可读性和运行效率影响很大。所以由系统自动检测并将它们交给缺省的异常处理程序。当然如果你有处理要求也可以显示捕获它们。
2. 调用下面的方法,得到的返回值是什么?
public int getNum(){
try {
int a = 1/0;
return 1;
} catch (Exception e) {
return 2;
}finally{
return 3;
}
代码在走到第 3 行的时候遇到了一个 MathException,这时第四行的代码就不会执行了,代码直接跳转到 catch语句中,走到第 6 行的时候,异常机制有这么一个原则如果在 catch 中遇到了 return 或者异常等能使该函数终止的话那么有 finally 就必须先执行完 finally 代码块里面的代码然后再返回值。因此代码又跳到第 8 行,可惜第 8 行是一个return 语句,那么这个时候方法就结束了,因此第 6 行的返回结果就无法被真正返回。如果 finally 仅仅是处理了一个释放资源的操作,那么该道题最终返回的结果就是 2。因此上面返回值是 3。
3. error 和 exception 的区别?
Error 类和 Exception 类的父类都是 Throwable 类,他们的区别如下。
Error 类一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢出等。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。
Exception 类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
Exception 类又分为运行时异常(Runtime Exception)和受检查的异常(Checked Exception ),运行时异常;ArithmaticException,IllegalArgumentException,编译能通过,但是一运行就终止了,程序不会处理运行时异常,出现这类异常,程序会终止。而受检查的异常,要么用 try…catch 捕获,要么用 throws 字句声明抛出,交给它的父类处理,否则编译不会通过。
4. java 异常处理机制
Java 对异常进行了分类,不同类型的异常分别用不同的 Java 类表示,所有异常的根类为 java.lang.Throwable,Throwable 下面又派生了两个子类:Error 和 Exception,Error 表示应用程序本身无法克服和恢复的一种严重问题。Exception 表示程序还能够克服和恢复的问题,其中又分为系统异常和普通异常,系统异常是软件本身缺陷所导致的问题,也就是软件开发人员考虑不周所导致的问题,软件使用者无法克服和恢复这种问题,但在这种问题下还可以让软件系统继续运行或者让软件死掉,例如,数组脚本越界(ArrayIndexOutOfBoundsException),空指针异常(NullPointerException)、类转换异常(ClassCastException);普通异常是运行环境的变化或异常所导致的问题,是用户能够克服的问题,例如,网络断线,硬盘空间不够,发生这样的异常后,程序不应该死掉。
java 为系统异常和普通异常提供了不同的解决方案,编译器强制普通异常必须 try…catch 处理或用 throws 声明继续抛给上层调用方法处理,所以普通异常也称为 checked 异常,而系统异常可以处理也可以不处理,所以,编译器不强制用 try…catch 处理或用 throws 声明,所以系统异常也称为 unchecked 异常。
5. 请写出你最常见的 5 个 RuntimeException
下面列举几个常见的 RuntimeException。
(1)java.lang.NullPointerException 空指针异常;出现原因:调用了未经初始化的对象或者是不存在的对象。
(2)java.lang.ClassNotFoundException 指定的类找不到;出现原因:类的名称和路径加载错误;通常都是程序试图通过字符串来加载某个类时可能引发异常。
(3)java.lang.NumberFormatException 字符串转换为数字异常;出现原因:字符型数据中包含非数字型字符。
(4)java.lang.IndexOutOfBoundsException 数组角标越界异常,常见于操作数组对象时发生。
(5)java.lang.IllegalArgumentException 方法传递参数错误。
(6)java.lang.ClassCastException 数据类型转换异常。
(7)java.lang.NoClassDefFoundException 未找到类定义错误。
(8)SQLException SQL 异常,常见于操作数据库时的 SQL 语句错误。
(9)java.lang.InstantiationException 实例化异常。
(10)java.lang.NoSuchMethodException 方法不存在异常。
6. throw 和 throws 的区别
throw:
1)throw 语句用在方法体内,表示抛出异常,由方法体内的语句处理。
2)throw 是具体向外抛出异常的动作,所以它抛出的是一个异常实例,执行 throw 一定是抛出了某种异常。
throws:
1)throws 语句是用在方法声明后面,表示如果抛出异常,由该方法的调用者来进行异常的处理。
2)throws 主要是声明这个方法会抛出某种类型的异常,让它的使用者要知道需要捕获的异常的类型。
3)throws 表示出现异常的一种可能性,并不一定会发生这种异常。
7. final、finally、finalize 的区别?
(1)final:用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,被其修饰的类不可继承。
(2)finally:异常处理语句结构的一部分,表示总是执行。
(3)finalize:Object 类的一个方法,在垃圾回收器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。该方法更像是一个对象生命周期的临终方法,当该方法被系统调用则代表该对象即将“死亡”,但是需要注意的是,我们主动行为上去调用该方法并不会导致该对象“死亡”,这是一个被动的方法(其实就是回调方法),不需要我们调用。
四、JavaSE 常用 API
1. Math.round(11.5)等于多少?Math.round(- 11.5) 又等于多少?
Math.round(11.5)的返回值是 12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在参数上加 0.5然后进行取整。
2. switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String上?
Java5 以前 switch(expr)中,expr 只能是 byte、short、char、int。从 Java 5 开始,Java 中引入了枚举类型,expr 也可以是 enum 类型。
从 Java 7 开始,expr 还可以是字符串(String),但是长整型(long)在目前所有的版本中都是不可以的。
3. 数组有没有 length() 方法?String 有没有 length() 方法?
数组没有 length()方法,而是有 length 的属性。String 有 length()方法。JavaScript 中,获得字符串的长度是通过 length 属性得到的,这一点容易和 Java 混淆。
4. String 、StringBuilder 、StringBuffer 的区别?
Java 平台提供了两种类型的字符串:String 和 StringBuffer/StringBuilder,它们都可以储存和操作字符串,区别如下。
(1)String 是只读字符串,也就意味着 String 引用的字符串内容是不能被改变的。初学者可能会有这样的误解:
String str = “abc”;
str = “bcd”;
如上,字符串 str 明明是可以改变的呀!其实不然,str 仅仅是一个引用对象,它指向一个字符串对象“abc”。第二行代码的含义是让 str 重新指向了一个新的字符串“bcd”对象,而“abc”对象并没有任何改变,只不过该对象已经成为一个不可及对象罢了。
(2)StringBuffer/StringBuilder 表示的字符串对象可以直接进行修改。
(3)StringBuilder 是 Java5 中引入的,它和 StringBuffer 的方法完全相同,区别在于它是在单线程环境下使用的,因为它的所有方法都没有被 synchronized 修饰,因此它的效率理论上也比 StringBuffer 要高。
5. 什么情况下用“+”运算符进行字符串连接比调用 StringBuffer/StringBuilder对象的 append 方法连接字符串性能更好?
该题来自华为。
字符串是 Java 程序中最常用的数据结构之一。在 Java 中 String 类已经重载了"+"。也就是说,字符串可以直接使用"+"进行连接,如下面代码所示:
String s = "abc" + "ddd";
但这样做真的好吗?当然,这个问题不能简单地回答 yes or no。要根据具体情况来定。在 Java 中提供了一个StringBuilder 类(这个类只在 J2SE5 及以上版本提供,以前的版本使用 StringBuffer 类),这个类也可以起到"+"的作用。那么我们应该用哪个呢?
下面让我们先看看如下的代码:
package string;
public class TestSimplePlus
{
public static void main(String[] args)
{
String s = "abc";
String ss = "ok" + s + "xyz" + 5;
System.out.println(ss);
}
}
上面的代码将会输出正确的结果。从表面上看,对字符串和整型使用"+"号并没有什么区别,但事实真的如此吗?下面让我们来看看这段代码的本质。
我们首先使用反编译工具(如 jdk 带的 javap、或 jad)将 TestSimplePlus 反编译成 Java Byte Code,其中的奥秘就一目了然了。在本文将使用 jad 来反编译,命令如下:
jad -o -a -s d.java TestSimplePlus.class
反编译后的代码如下:
package string;
import java.io.PrintStream;
public class TestSimplePlus
{
public TestSimplePlus()
{
// 0 0:aload_0
// 1 1:invokespecial #8 读者可能看到上面的 Java 字节码感到迷糊,不过大家不必担心。本文的目的并不是讲解 Java Byte Code,因此,并不用了解具体的字节码的含义。
使用 jad 反编译的好处之一就是可以同时生成字节码和源代码。这样可以进行对照研究。从上面的代码很容易看出,虽然在源程序中使用了"+",但在编译时仍然将"+“转换成 StringBuilder。因此,我们可以得出结论,在 Java 中无论使用何种方式进行字符串连接,实际上都使用的是 StringBuilder。
那么是不是可以根据这个结论推出使用”+“和 StringBuilder 的效果是一样的呢?这个要从两个方面的解释。如果从运行结果来解释,那么”+“和 StringBuilder 是完全等效的。但如果从运行效率和资源消耗方面看,那它们将存在很大的区别。
当然,如果连接字符串行表达式很简单(如上面的顺序结构),那么”+"和 StringBuilder 基本是一样的,但如果结构比较复杂,如使用循环来连接字符串,那么产生的 Java Byte Code 就会有很大的区别。先让我们看看如下的代码:
package string;
import java.util.*;
public class TestComplexPlus
{
public static void main(String[] args)
{
String s = "";
Random rand = new Random();
for (int i = 0; i < 10; i++)
{
s = s + rand.nextInt(1000) + " ";
}
System.out.println(s);
}
}
上面的代码返编译后的 Java Byte Code (仅保留源代码)如下:
package string;
import java.io.PrintStream;
import java.util.Random;
public class TestComplexPlus
{
public TestComplexPlus()
{
}
public static void main(String args[])
{
String s = "";
Random rand = new Random();
for(int i = 0; i < 10; i++)
s = (new StringBuilder(String.valueOf(s))).append(rand.nextInt(1000)).append(" ").t
oString();
System.out.println(s);
}
}
大家可以看到,虽然编译器将"+"转换成了 StringBuilder,但创建 StringBuilder 对象的位置却在 for 语句内部。这就意味着每执行一次循环,就会创建一个 StringBuilder 对象(对于本例来说,是创建了 10 个 StringBuilder对象),虽然 Java 有垃圾回收器,但这个回收器的工作时间是不定的。如果不断产生这样的垃圾,那么仍然会占用大量的资源。解决这个问题的方法就是在程序中直接使用 StringBuilder 来连接字符串,代码如下:
package string;
import java.util.*;
public class TestStringBuilder
{
public static void main(String[] args)
{
String s = "";
Random rand = new Random();
StringBuilder result = new StringBuilder();
for (int i = 0; i < 10; i++)
{
result.append(rand.nextInt(1000));
result.append(" ");
}
System.out.println(result.toString());
}
}
上面代码反编译后的结果如下:
package string;
import java.io.PrintStream;
import java.util.Random;
public class TestStringBuilder
{
public TestStringBuilder()
{
// 0 0:aload_0
// 1 1:invokespecial #8 从上面的反编译结果可以看出,创建 StringBuilder 的代码被放在了 for 语句外。虽然这样处理在源程序中看起来复杂,但却换来了更高的效率,同时消耗的资源也更少了。
在使用 StringBuilder 时要注意,尽量不要"+"和 StringBuilder 混着用,否则会创建更多的 StringBuilder 对象,如下面代码所:
for (int i = 0; i < 10; i++)
{
result.append(rand.nextInt(1000));
result.append(" ");
}
改成如下形式:
for (int i = 0; i < 10; i++)
{
result.append(rand.nextInt(1000) + " ");
}
则反编译后的结果如下:
for(int i = 0; i < 10; i++)
//* 10 19:iconst_0
//* 11 20:istore 4
//* 12 22:goto 65
{
result.append((new StringBuilder(String.valueOf(rand.nextInt(1000)))).append(" ").toString());
// 13 25:aload_3
// 14 26:new #21 从上面的代码可以看出,Java 编译器将"+“编译成了 StringBuilder,这样 for 语句每循环一次,又创建了一个StringBuilder 对象。
如果将上面的代码在 JDK1.4 下编译,必须将 StringBuilder 改为 StringBuffer,而 JDK1.4 将”+"转换为StringBuffer(因为 JDK1.4 并没有提供 StringBuilder 类)。StringBuffer 和 StringBuilder 的功能基本一样,只是StringBuffer 是线程安全的,而 StringBuilder 不是线程安全的。因此,StringBuilder 的效率会更高。
6. 请说出下面程序的输出
class StringEqualTest {
public static void main(String[] args) {
String s1 = "Programming";
String s2 = new String("Programming");
String s3 = "Program";
String s4 = "ming";
String s5 = "Program" + "ming";
String s6 = s3 + s4;
System.out.println(s1 == s2); //false
System.out.println(s1 == s5); //true
System.out.println(s1 == s6); //false
System.out.println(s1 == s6.intern()); //true
System.out.println(s2 == s2.intern()); //false
}
}
补充:解答上面的面试题需要知道如下两个知识点:
- String 对象的 intern()方法会得到字符串对象在常量池中对应的版本的引用(如果常量池中有一个字符串与String 对象的 equals 结果是 true),如果常量池中没有对应的字符串,则该字符串将被添加到常量池中,然后返回常量池中字符串的引用;
- 字符串的+操作其本质是创建了 StringBuilder 对象进行 append 操作,然后将拼接后的 StringBuilder 对象用 toString 方法处理成 String 对象,这一点可以用 javap -c StringEqualTest.class 命令获得 class 文件对应的 JVM 字节码指令就可以看出来。
7. Java 中的日期和时间
7.1 如何取得年月日、小时分钟秒?
public class DateTimeTest {
public static void main(String[] args) {
Calendar cal = Calendar.getInstance();
System.out.println(cal.get(Calendar.YEAR));
System.out.println(cal.get(Calendar.MONTH)); // 0 - 11
System.out.println(cal.get(Calendar.DATE));
System.out.println(cal.get(Calendar.HOUR_OF_DAY));
System.out.println(cal.get(Calendar.MINUTE));
System.out.println(cal.get(Calendar.SECOND));
// Java 8
LocalDateTime dt = LocalDateTime.now();
System.out.println(dt.getYear());
System.out.println(dt.getMonthValue()); // 1 - 12
System.out.println(dt.getDayOfMonth());
System.out.println(dt.getHour());
System.out.println(dt.getMinute());
System.out.println(dt.getSecond());
}
}
7.2 如何取得从 1970 年 1 月 1 日 0 时 0 分 0 秒到现在的毫秒数?
Calendar.getInstance().getTimeInMillis(); //第一种方式
System.currentTimeMillis(); //第二种方式
// Java 8
Clock.systemDefaultZone().millis();
7.3 如何取得某月的最后一天?
//获取当前月第一天:
Calendar c = Calendar.getInstance();
c.add(Calendar.MONTH, 0);
c.set(Calendar.DAY_OF_MONTH,1);//设置为 1 号,当前日期既为本月第一天
String first = format.format(c.getTime());
System.out.println("===============first:"+first);
//获取当前月最后一天
Calendar ca = Calendar.getInstance();
ca.set(Calendar.DAY_OF_MONTH, ca.getActualMaximum(Calendar.DAY_OF_MONTH));
String last = format.format(ca.getTime());
System.out.println("===============last:"+last);
//Java 8
LocalDate today = LocalDate.now();
//本月的第一天
LocalDate firstday = LocalDate.of(today.getYear(),today.getMonth(),1);
//本月的最后一天
LocalDate lastDay =today.with(TemporalAdjusters.lastDayOfMonth());
System.out.println("本月的第一天"+firstday);
System.out.println("本月的最后一天"+lastDay);
7.4 如何格式化日期?
(1)Java.text.DataFormat 的子类(如 SimpleDateFormat 类)中的 format(Date)方法可将日期格式化。
(2)Java 8 中可以用 java.time.format.DateTimeFormatter 来格式化时间日期,代码如下所示:
import java.text.SimpleDateFormat;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Date;
class DateFormatTest {
public static void main(String[] args) {
SimpleDateFormat oldFormatter = new SimpleDateFormat("yyyy/MM/dd");
Date date1 = new Date();
System.out.println(oldFormatter.format(date1));
// Java 8
DateTimeFormatter newFormatter = DateTimeFormatter.ofPattern("yyyy/MM/dd");
LocalDate date2 = LocalDate.now();
System.out.println(date2.format(newFormatter));
}
}
补充:Java 的时间日期 API 一直以来都是被诟病的东西,为了解决这一问题,Java 8 中引入了新的时间日期 API,其中包括 LocalDate、LocalTime、LocalDateTime、Clock、Instant 等类,这些的类的设计都使用了不变模式,因此是线程安全的设计。
五、Java 的数据类型
1. Java 的基本数据类型都有哪些各占几个字节
如下表所示:
| 类型 | 种类 | 字节数 | 数据表示范围 |
|---|---|---|---|
| 整型 | byte | 1 | -27~27-1 |
| 整型 | short | 2 | -215~215-1 |
| 整型 | int | 4 | -231~231-1 |
| 整型 | long | 8 | -263~263-1 |
| 浮点型 | float | 4 | -3.403E38~3.403E38 |
| 浮点型 | double | 8 | -1.798E308~1.798E308 |
| 字符型 | char | 2 | 表示一个字符,如(‘a’,‘A’,‘0’,‘家’) |
| 布尔型 | boolean | 1 | 只有两个值 true 与 false |
2. String 是基本数据类型吗?
String 是引用类型,底层用 char 数组实现的。
3. short s1 = 1; s1 = s1 + 1; 有错吗?short s1 = 1; s1 += 1 有错吗;
前者不正确,后者正确。对于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 类型,因此 s1+1 运算结果也是 int 型,需要强制转换类型才能赋值给 short 型。而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 =(short)(s1 + 1);其中有隐含的强制类型转换。
4. int 和 和 Integer 有什么区别?
Java 是一个近乎纯洁的面向对象编程语言,但是为了编程的方便还是引入了基本数据类型,为了能够将这些基本数据类型当成对象操作,Java 为每一个基本数据类型都引入了对应的包装类型(wrapper class),int 的包装类就是Integer,从 Java 5 开始引入了自动装箱/拆箱机制,使得二者可以相互转换。
Java 为每个原始类型提供了包装类型:
- 原始类型: boolean,char,byte,short,int,long,float,double
- 包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
clas Test {
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3; //将3自动装箱成Integer类型
int c = 3;
System.out.println(a == b); //false 两个引用没有引用同一对象
System.out.println(a == c); //true 自动拆箱成int类型再和c比较
}
}
5. 下面 Integer 类型的数值比较输出的结果为?
clas Test {
public static void main(String[] args) {
Integer f1=100,f2=100,f3=150,f4=150;
System.out.println(f1 == f2);
System.out.println(f3 == f4);
}
}
如果不明就里很容易认为两个输出要么都是 true 要么都是 false。首先需要注意的是 f1、f2、f3、f4 四个变量都是 Integer 对象引用,所以下面的==运算比较的不是值而是引用。装箱的本质是什么呢?当我们给一个 Integer 对象赋一个 int 值的时候,会调用 Integer 类的静态方法 valueOf,如果看看 valueOf 的源代码就知道发生了什么。
源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
IntegerCache 是 Integer 的内部类,其代码如下所示:
/**
* Cache to support the object identity semantics of autoboxing for values between
* -128 and 127 (inclusive) as required by JLS.
*
* The cache is initialized on first usage. The size of the cache
* may be controlled by the {@code -XX:AutoBoxCacheMax=} option.
* During VM initialization, java.lang.Integer.IntegerCache.high property
* may be set and saved in the private system properties in the
* sun.misc.VM class.
*/
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer cache[];
static {
// high value may be configured by property
int h = 127;
String integerCacheHighPropValue =
sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
if (integerCacheHighPropValue != null) {
try {
int i = parseInt(integerCacheHighPropValue);
i = Math.max(i, 127);
// Maximum array size is Integer.MAX_VALUE
h = Math.min(i, Integer.MAX_VALUE - (-low) -1);
} catch( NumberFormatException nfe) {
// If the property cannot be parsed into an int, ignore it.
}
}
high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
private IntegerCache() {}
}
简单的说,如果整型字面量的值在-128 到 127 之间,那么不会 new 新的 Integer 对象,而是直接引用常量池中的 Integer 对象,所以上面的面试题中 f1 == f2 的结果是 true,而 f3 == f4 的结果是 false。
提醒:越是貌似简单的面试题其中的玄机就越多,需要面试者有相当深厚的功力。
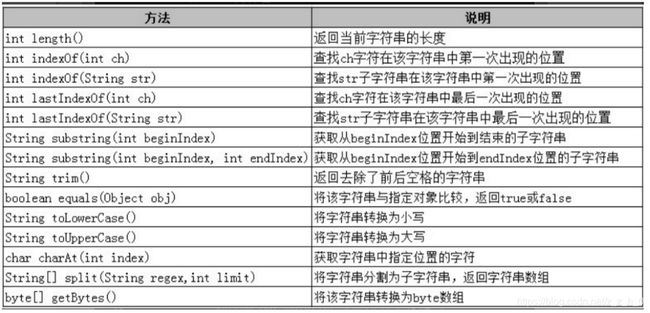
6. String 类常用方法
7. 数据类型之间的转换
(1)、字符串如何转基本数据类型?
调用基本数据类型对应的包装类中的方法 parseXXX(String)或 valueOf(String)即可返回相应基本类型。
(2)、基本数据类型如何转字符串?
一种方法是将基本数据类型与空字符串("")连接(+)即可获得其所对应的字符串;另一种方法是调用 String类中的 valueOf()方法返回相应字符串。
六、Java 的 IO
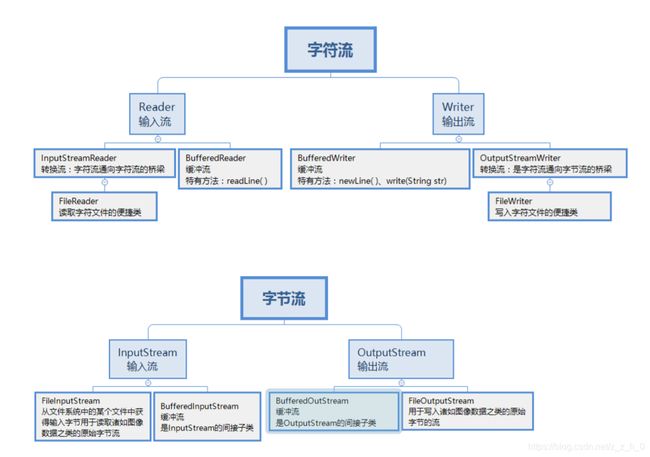
1. Java 中有几种类型的流
按照流的方向:输入流(inputStream)和输出流(outputStream)。
按照实现功能分:节点流(可以从或向一个特定的地方(节点)读写数据。如 FileReader)和处理流(是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如 BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。)
按照处理数据的单位:字节流和字符流。字节流继承于 InputStream 和 OutputStream,字符流继承于InputStreamReader 和 OutputStreamWriter。
2. 字节流如何转为字符流
字节输入流转字符输入流通过 InputStreamReader 实现,该类的构造函数可以传入 InputStream 对象。
字节输出流转字符输出流通过 OutputStreamWriter 实现,该类的构造函数可以传入 OutputStream 对象。
3. 如何将一个 java 对象序列化到文件里
java 中能够被序列化的类必须先实现 Serializable 接口,该接口没有任何抽象方法只是起到一个标记作用。
//对象输出流
ObjectOutputStream objectOutputStream =
new ObjectOutputStream(new FileOutputStream(new File("D://obj")));
objectOutputStream.writeObject(new User("zhangsan", 100));
objectOutputStream.close();
//对象输入流
ObjectInputStream objectInputStream =
new ObjectInputStream(new FileInputStream(new File("D://obj")));
User user = (User)objectInputStream.readObject();
System.out.println(user);
objectInputStream.close();
4. 字节流和字符流的区别
字节流读取的时候,读到一个字节就返回一个字节; 字符流使用了字节流读到一个或多个字节(中文对应的字节数是两个,在 UTF-8 码表中是 3 个字节)时。先去查指定的编码表,将查到的字符返回。 字节流可以处理所有类型数据,如:图片,MP3,AVI 视频文件,而字符流只能处理字符数据。只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流。字节流主要是操作 byte 类型数据,以 byte 数组为准,主要操作类就是 OutputStream、InputStream。
字符流处理的单元为 2 个字节的 Unicode 字符,分别操作字符、字符数组或字符串,而字节流处理单元为 1 个字节,操作字节和字节数组。所以字符流是由 Java 虚拟机将字节转化为 2 个字节的 Unicode 字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点。在程序中一个字符等于两个字节,java 提供了 Reader、Writer 两个专门操作字符流的类。
5. 如何实现对象克隆?
有两种方式。
(1). 实现 Cloneable 接口并重写 Object 类中的 clone()方法;
(2). 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下。
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class MyUtil {
private MyUtil() {
throw new AssertionError();
}
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用 ByteArrayInputStream 或 ByteArrayOutputStream 对象的 close 方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
}
}
测试代码:
import java.io.Serializable;
/**
* 人类
*/
class Person implements Serializable {
private static final long serialVersionUID = -9102017020286042305L;
private String name; // 姓名
private int age; // 年龄
private Car car; // 座驾
public Person(String name, int age, Car car) {
this.name = name;
this.age = age;
this.car = car;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Car getCar() {
return car;
}
public void setCar(Car car) {
this.car = car;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", car=" + car + "]";
}
}
/**
* 小汽车类
*/
class Car implements Serializable {
private static final long serialVersionUID = -5713945027627603702L;
private String brand; // 品牌
private int maxSpeed; // 最高时速
public Car(String brand, int maxSpeed) {
this.brand = brand;
this.maxSpeed = maxSpeed;
}
public String getBrand() {
return brand;
}
public void setBrand(String brand) {
this.brand = brand;
}
public int getMaxSpeed() {
return maxSpeed;
}
public void setMaxSpeed(int maxSpeed) {
this.maxSpeed = maxSpeed;
}
@Override
public String toString() {
return "Car [brand=" + brand + ", maxSpeed=" + maxSpeed + "]";
}
}
class CloneTest {
public static void main(String[] args) {
try {
Person p1 = new Person("Hao LUO", 33, new Car("Benz", 300));
Person p2 = MyUtil.clone(p1); // 深度克隆
p2.getCar().setBrand("BYD");
// 修改克隆的 Person 对象 p2 关联的汽车对象的品牌属性
// 原来的 Person 对象 p1 关联的汽车不会受到任何影响
// 因为在克隆 Person 对象时其关联的汽车对象也被克隆了
System.out.println(p1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
注意:基于序列化和反序列化实现的克隆不仅仅是深度克隆,更重要的是通过泛型限定,可以检查出要克隆的对象是否支持序列化,这项检查是编译器完成的,不是在运行时抛出异常,这种是方案明显优于使用 Object 类的 clone方法克隆对象。让问题在编译的时候暴露出来总是好过把问题留到运行时。
6. 什么是 java 序列化,如何实现 java 序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
序列化的实现:将需要被序列化的类实现 Serializable 接口,该接口没有需要实现的方法,implements Serializable 只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个 ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream 对象的 writeObject(Object obj)方法就可以将参数为 obj 的对象写出(即保存其状态),要恢复的话则用输入流。
七、Java 的集合
1. HashMap 排序题,上机题。
已知一个 HashMap
注意:要做出这道题必须对集合的体系结构非常的熟悉。HashMap 本身就是不可排序的,但是该道题偏偏让给HashMap 排序,那我们就得想在 API 中有没有这样的 Map 结构是有序的,LinkedHashMap,对的,就是他,他是Map 结构,也是链表结构,有序的,更可喜的是他是 HashMap 的子类,我们返回 LinkedHashMap
但凡是对集合的操作,我们应该保持一个原则就是能用 JDK 中的 API 就有 JDK 中的 API,比如排序算法我们不应该去用冒泡或者选择,而是首先想到用 Collections 集合工具类。
public class HashMapTest {
public static void main(String[] args) {
HashMap<Integer, User> users = new HashMap<>();
users.put(1, new User("张三", 25));
users.put(3, new User("李四", 22));
users.put(2, new User("王五", 28));
System.out.println(users);
HashMap<Integer,User> sortHashMap = sortHashMap(users);
System.out.println(sortHashMap);
/**
* 控制台输出内容
* {1=User [name=张三, age=25], 2=User [name=王五, age=28], 3=User [name=李四, age=22]}
{2=User [name=王五, age=28], 1=User [name=张三, age=25], 3=User [name=李四, age=22]}
*/
}
public static HashMap<Integer, User> sortHashMap(HashMap<Integer, User> map) {
// 首先拿到 map 的键值对集合
Set<Entry<Integer, User>> entrySet = map.entrySet();
// 将 set 集合转为 List 集合,为什么,为了使用工具类的排序方法
List<Entry<Integer, User>> list = new ArrayList<Entry<Integer, User>>(entrySet);
// 使用 Collections 集合工具类对 list 进行排序,排序规则使用匿名内部类来实现
Collections.sort(list, new Comparator<Entry<Integer, User>>() {
@Override
public int compare(Entry<Integer, User> o1, Entry<Integer, User> o2) {
//按照要求根据 User 的 age 的倒序进行排
return o2.getValue().getAge()-o1.getValue().getAge();
}
});
//创建一个新的有序的 HashMap 子类的集合
LinkedHashMap<Integer, User> linkedHashMap = new LinkedHashMap<Integer, User>();
//将 List 中的数据存储在 LinkedHashMap 中
for(Entry<Integer, User> entry : list){
linkedHashMap.put(entry.getKey(), entry.getValue());
}
//返回结果
return linkedHashMap;
}
}
2. 集合的安全性问题
请问 ArrayList、HashSet、HashMap 是线程安全的吗?如果不是我想要线程安全的集合怎么办?
我们都看过上面那些集合的源码(如果没有那就看看吧),每个方法都没有加锁,显然都是线程不安全的。话又说过来如果他们安全了也就没第二问了。
在集合中 Vector 和 HashTable 倒是线程安全的。你打开源码会发现其实就是把各自核心方法添加上了synchronized 关键字。
Collections 工具类提供了相关的 API,可以让上面那 3 个不安全的集合变为安全的。
Collections.synchronizedCollection(c)
Collections.synchronizedList(list)
Collections.synchronizedMap(m)
Collections.synchronizedSet(s)
上面几个函数都有对应的返回值类型,传入什么类型返回什么类型。打开源码其实实现原理非常简单,就是将集合的核心方法添加上了 synchronized 关键字。
3. ArrayList 内部用什么实现的?
(回答这样的问题,不要只回答个皮毛,可以再介绍一下 ArrayList 内部是如何实现数组的增加和删除的,因为数组在创建的时候长度是固定的,那么就有个问题我们往 ArrayList 中不断的添加对象,它是如何管理这些数组呢?)
ArrayList 内部是用 Object[]实现的。接下来我们分别分析 ArrayList 的构造、add、remove、clear 方法的实现原理。
一、构造函数
(1)空参构造
/**
* Constructs a new {@code ArrayList} instance with zero initial capacity.
*/
public ArrayList() {
array = EmptyArray.OBJECT;
}
array 是一个 Object[]类型。当我们 new 一个空参构造时系统调用了 EmptyArray.OBJECT 属性,EmptyArray 仅仅是一个系统的类库,该类源码如下:
public final class EmptyArray {
private EmptyArray() {}
public static final boolean[] BOOLEAN = new boolean[0];
public static final byte[] BYTE = new byte[0];
public static final char[] CHAR = new char[0];
public static final double[] DOUBLE = new double[0];
public static final int[] INT = new int[0];
public static final Class<?>[] CLASS = new Class[0];
public static final Object[] OBJECT = new Object[0];
public static final String[] STRING = new String[0];
public static final Throwable[] THROWABLE = new Throwable[0];
public static final StackTraceElement[] STACK_TRACE_ELEMENT = new StackTraceElement[0];
}
也就是说当我们 new 一个空参 ArrayList 的时候,系统内部使用了一个 new Object[0]数组。
(2)带参构造 1
/**
* Constructs a new instance of {@code ArrayList} with the specified
* initial capacity.
*
* @param capacity
* the initial capacity of this {@code ArrayList}.
*/
public ArrayList(int capacity) {
if (capacity < 0) {
throw new IllegalArgumentException("capacity < 0: " + capacity);
}
array = (capacity == 0 ? EmptyArray.OBJECT : new Object[capacity]);
}
该构造函数传入一个 int 值,该值作为数组的长度值。如果该值小于 0,则抛出一个运行时异常。如果等于 0,则使用一个空数组,如果大于 0,则创建一个长度为该值的新数组。
(3)带参构造 2
/**
* Constructs a new instance of {@code ArrayList} containing the elements of
* the specified collection.
*
* @param collection
* the collection of elements to add.
*/
public ArrayList(Collection<? extends E> collection) {
if (collection == null) {
throw new NullPointerException("collection == null");
}
Object[] a = collection.toArray();
if (a.getClass() != Object[].class) {
Object[] newArray = new Object[a.length];
System.arraycopy(a, 0, newArray, 0, a.length);
a = newArray;
}
array = a;
size = a.length;
}
如果调用构造函数的时候传入了一个 Collection 的子类,那么先判断该集合是否为 null,为 null 则抛出空指针异常。如果不是则将该集合转换为数组 a,然后将该数组赋值为成员变量 array,将该数组的长度作为成员变量 size。这里面它先判断 a.getClass 是否等于 Object[].class,其实一般都是相等的,我也暂时没想明白为什么多加了这个判断,toArray 方法是 Collection 接口定义的,因此其所有的子类都有这样的方法,list 集合的 toArray 和 Set 集合的 toArray返回的都是 Object[]数组。
二、add 方法
add 方法有两个重载,这里只研究最简单的那个。
/**
* Adds the specified object at the end of this {@code ArrayList}.
*
* @param object
* the object to add.
* @return always true
*/
@Override public boolean add(E object) {
Object[] a = array;
int s = size;
if (s == a.length) {
Object[] newArray = new Object[s +
(s < (MIN_CAPACITY_INCREMENT / 2) ?
MIN_CAPACITY_INCREMENT : s >> 1)];
System.arraycopy(a, 0, newArray, 0, s);
array = a = newArray;
}
a[s] = object;
size = s + 1;
modCount++;
return true;
}
1、首先将成员变量 array 赋值给局部变量 a,将成员变量 size 赋值给局部变量 s。
2、判断集合的长度 s 是否等于数组的长度(如果集合的长度已经等于数组的长度了,说明数组已经满了,该重新分配新数组了),重新分配数组的时候需要计算新分配内存的空间大小,如果当前的长度小于MIN_CAPACITY_INCREMENT/2(这个常量值是 12,除以 2 就是 6,也就是如果当前集合长度小于 6)则分配 12 个长度,如果集合长度大于 6 则分配当前长度 s 的一半长度。这里面用到了三元运算符和位运算,s >> 1,意思就是将s 往右移 1 位,相当于 s=s/2,只不过位运算是效率最高的运算。
3、将新添加的 object 对象作为数组的 a[s]个元素。
4、修改集合长度 size 为 s+1
5、modCotun++,该变量是父类中声明的,用于记录集合修改的次数,记录集合修改的次数是为了防止在用迭代器迭代集合时避免并发修改异常,或者说用于判断是否出现并发修改异常的。
6、return true,这个返回值意义不大,因为一直返回 true,除非报了一个运行时异常。
三、remove 方法
remove 方法有两个重载,我们只研究 remove(int index)方法。
/**
* Removes the object at the specified location from this list.
*
* @param index
* the index of the object to remove.
* @return the removed object.
* @throws IndexOutOfBoundsException
* when {@code location < 0 || location >= size()}
*/
@Override public E remove(int index) {
Object[] a = array;
int s = size;
if (index >= s) {
throwIndexOutOfBoundsException(index, s);
}
@SuppressWarnings("unchecked")
E result = (E) a[index];
System.arraycopy(a, index + 1, a, index, --s - index);
a[s] = null; // Prevent memory leak
size = s;
modCount++;
return result;
}
1、先将成员变量 array 和 size 赋值给局部变量 a 和 s。
2、判断形参 index 是否大于等于集合的长度,如果成了则抛出运行时异常
3、获取数组中脚标为 index 的对象 result,该对象作为方法的返回值
4、调用 System 的 arraycopy 函数,拷贝原理如下图所示。

5、接下来就是很重要的一个工作,因为删除了一个元素,而且集合整体向前移动了一位,因此需要将集合最后一个元素设置为 null,否则就可能内存泄露。
6、重新给成员变量 array 和 size 赋值
7、记录修改次数
8、返回删除的元素(让用户再看最后一眼)
四、clear 方法
/**
* Removes all elements from this {@code ArrayList}, leaving it empty.
*
* @see #isEmpty
* @see #size
*/
@Override public void clear() {
if (size != 0) {
Arrays.fill(array, 0, size, null);
size = 0;
modCount++;
}
}
如果集合长度不等于 0,则将所有数组的值都设置为 null,然后将成员变量 size 设置为 0 即可,最后让修改记录加 1。
4. 并发集合和普通集合如何区别?
并发集合常见的有 ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque 等。并发集合位 于 java.util.concurrent 包下,是 jdk1.5 之后才有的。
在 java 中有普通集合、同步(线程安全)的集合、并发集合。普通集合通常性能最高,但是不保证多线程的安全性和并发的可靠性。线程安全集合仅仅是给集合添加了 synchronized 同步锁,严重牺牲了性能,而且对并发的效率就更低了,并发集合则通过复杂的策略不仅保证了多线程的安全又提高的并发时的效率。
参考阅读:
ConcurrentHashMap 是线程安全的 HashMap 的实现,默认构造同样有 initialCapacity 和 loadFactor 属性,不过还多了一个 concurrencyLevel 属性,三属性默认值分别为 16、0.75 及 16。其内部使用锁分段技术,维持这锁Segment 的数组,在 Segment 数组中又存放着 Entity[]数组,内部 hash 算法将数据较均匀分布在不同锁中。
put 操作:并没有在此方法上加上 synchronized,首先对 key.hashcode 进行 hash 操作,得到 key 的 hash 值。hash操作的算法和 map也不同,根据此 hash 值计算并获取其对应的数组中的 Segment对象(继承自ReentrantLock),接着调用此 Segment 对象的 put 方法来完成当前操作。
ConcurrentHashMap 基于 concurrencyLevel 划分出了多个 Segment 来对 key-value 进行存储,从而避免每次 put 操作都得锁住整个数组。在默认的情况下,最佳情况下可允许 16 个线程并发无阻塞的操作集合对象,尽可能地减少并发时的阻塞现象。
推荐博客
5. List 的三个子类的特点
ArrayList 底层结构是数组,底层查询快,增删慢。
LinkedList 底层结构是链表型的,增删快,查询慢。
voctor 底层结构是数组 线程安全的,增删慢,查询慢。
6. List 和 Map、Set 的区别
6.1 结构特点
List 和 Set 是存储单列数据的集合,Map 是存储键和值这样的双列数据的集合;List 中存储的数据是有顺序,并且允许重复;Map 中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重复的,Set 中存储的数据是无序的,且不允许有重复,但元素在集合中的位置由元素的 hashcode 决定,位置是固定的(Set 集合根据 hashcode 来进行数据的存储,所以位置是固定的,但是位置不是用户可以控制的,所以对于用户来说 set 中的元素还是无序的);
6.2 实现类
List 接口有三个实现类(LinkedList:基于链表实现,链表内存是散乱的,每一个元素存储本身内存地址的同时还存储下一个元素的地址。链表增删快,查找慢;ArrayList:基于数组实现,非线程安全的,效率高,便于索引,但不便于插入删除;Vector:基于数组实现,线程安全的,效率低)。
Map 接口有三个实现类(HashMap:基于 hash 表的 Map 接口实现,非线程安全,高效,支持 null 值和 null键;HashTable:线程安全,低效,不支持 null 值和 null 键;LinkedHashMap:是 HashMap 的一个子类,保存了记录的插入顺序;SortMap 接口:TreeMap,能够把它保存的记录根据键排序,默认是键值的升序排序)。
Set 接口有两个实现类(HashSet:底层是由 HashMap 实现,不允许集合中有重复的值,使用该方式时需要重写 equals()和 hashCode()方法;LinkedHashSet:继承与 HashSet,同时又基于 LinkedHashMap 来进行实现,底层使用的是 LinkedHashMp)。
6.3 区别
List 集合中对象按照索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象,例如通过list.get(i)方法来获取集合中的元素;Map 中的每一个元素包含一个键和一个值,成对出现,键对象不可以重复,值对象可以重复;Set 集合中的对象不按照特定的方式排序,并且没有重复对象,但它的实现类能对集合中的对象按照特定的方式排序,例如 TreeSet 类,可以按照默认顺序,也可以通过实现 Java.util.Comparator接口来自定义排序方式。
7. HashMap 和 HashTable 有什么区别?
HashMap 是线程不安全的,HashMap 是一个接口,是 Map 的一个子接口,是将键映射到值得对象,不允许键值重复,允许空键和空值;由于非线程安全,HashMap 的效率要较 HashTable 的效率高一些.
HashTable 是线程安全的一个集合,不允许 null 值作为一个 key 值或者 Value 值;
HashTable 是 sychronize,多个线程访问时不需要自己为它的方法实现同步,而 HashMap 在被多个线程访问的时候需要自己为它的方法实现同步;
8. 数组和链表分别比较适合用于什么场景,为什么?
数组应用场景:数据比较少;经常做的运算是按序号访问数据元素;数组更容易实现,任何高级语言都支持;构建的线性表较稳定。
链表应用场景:对线性表的长度或者规模难以估计;频繁做插入删除操作;构建动态性比较强的线性表。
9. Java 中 ArrayList 和 Linkedlist 区别?
ArrayList 和 Vector 使用了数组的实现,可以认为 ArrayList 或者 Vector 封装了对内部数组的操作,比如向数组中添加,删除,插入新的元素或者数据的扩展和重定向。
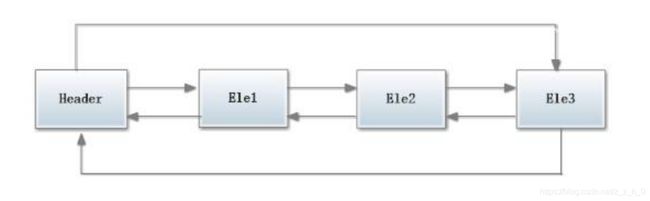
LinkedList 使用了循环双向链表数据结构。与基于数组的 ArrayList 相比,这是两种截然不同的实现技术,这也决定了它们将适用于完全不同的工作场景。
LinkedList 链表由一系列表项连接而成。一个表项总是包含 3 个部分:元素内容,前驱表和后驱表,如图所示:

在下图展示了一个包含 3 个元素的 LinkedList 的各个表项间的连接关系。在 JDK 的实现中,无论 LikedList 是否为空,链表内部都有一个 header 表项,它既表示链表的开始,也表示链表的结尾。表项 header 的后驱表项便是链表中第一个元素,表项 header 的前驱表项便是链表中最后一个元素。
10. List a=new ArrayList()和 ArrayList a =new ArrayList()的区别?
List list = new ArrayList();这句创建了一个 ArrayList 的对象后把上溯到了 List。此时它是一个 List 对象了,有些ArrayList 有但是 List 没有的属性和方法,它就不能再用了。而 ArrayList list=new ArrayList();创建一对象则保留了ArrayList 的所有属性。 所以需要用到 ArrayList 独有的方法的时候不能用前者。实例代码如下:
List list = new ArrayList();
ArrayList arrayList = new ArrayList();
list.trimToSize(); //错误,没有该方法。
arrayList.trimToSize(); //ArrayList 里有该方法。
11. 要对集合更新操作时,ArrayList 和 LinkedList 哪个更适合?
1.ArrayList 是实现了基于动态数组的数据结构,LinkedList 基于链表的数据结构。
2.如果集合数据是对于集合随机访问 get 和 set,ArrayList 绝对优于 LinkedList,因为 LinkedList 要移动指针。
3.如果集合数据是对于集合新增和删除操作 add 和 remove,LinedList 比较占优势,因为 ArrayList 要移动数据。
ArrayList 和 LinkedList 是两个集合类,用于存储一系列的对象引(references)。例如我们可以用 ArrayList 来存储一系列的 String 或者 Integer。那 么 ArrayList 和 LinkedList 在性能上有什么差别呢?什么时候应该用 ArrayList什么时候又该用 LinkedList 呢?
一.时间复杂度
首先一点关键的是,ArrayList 的内部实现是基于基础的对象数组的,因此,它使用 get 方法访问列表中的任意一个元素时(random access),它的速度要比 LinkedList 快。LinkedList 中的 get 方法是按照顺序从列表的一端开始检查,直到另外一端。对 LinkedList 而言,访问列表中的某个指定元素没有更快的方法了。
假设我们有一个很大的列表,它里面的元素已经排好序了,这个列表可能是 ArrayList 类型的也可能是 LinkedList类型的,现在我们对这个列表来进行二分查找(binary search),比较列表是 ArrayList 和 LinkedList 时的查询速度,
看下面的程序:
public class TestList{
public static final int N=50000; //50000 个数
public static List values; //要查找的集合
//放入 50000 个数给 value;
static{
Integer vals[]=new Integer[N];
Random r=new Random();
for(int i=0,currval=0;i<N;i++)...{
vals=new Integer(currval);
currval+=r.nextInt(100)+1;
}
values=Arrays.asList(vals);
}
//通过二分查找法查找
static long timeList(List lst){
long start=System.currentTimeMillis();
for(int i=0;i<N;i++)...{
int index=Collections.binarySearch(lst, values.get(i));
if(index!=i)
System.out.println("***错误***");
}
return System.currentTimeMillis()-start;
}
public static void main(String args[])...{
System.out.println("ArrayList 消耗时间:"+timeList(new ArrayList(values)));
System.out.println("LinkedList 消耗时间:"+timeList(new LinkedList(values)));
}
}
得到的输出是:
ArrayList 消耗时间:15
LinkedList 消耗时间:2596
这个结果不是固定的,但是基本上 ArrayList 的时间要明显小于 LinkedList 的时间。因此在这种情况下不宜用LinkedList。二分查找法使用的随机访问(random access)策略,而 LinkedList 是不支持快速的随机访问的。对一个LinkedList 做随机访问所消耗的时间与这个 list 的大小是成比例的。而相应的,在 ArrayList 中进行随机访问所消耗的时间是固定的。
这是否表明 ArrayList 总是比 LinkedList 性能要好呢?这并不一定,在某些情况下 LinkedList 的表现要优于ArrayList,有些算法在 LinkedList 中实现 时效率更高。比方说,利用 Collections.reverse 方法对列表进行反转时,其性能就要好些。看这样一个例子,加入我们有一个列表,要对其进行大量的插入和删除操作,在这种情况下 LinkedList就是一个较好的选择。请看如下一个极端的例子,我们重复的在一个列表的开端插入一个元素:
import java.util.*;
public class ListDemo {
static final int N=50000;
static long timeList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<N;i++)
list.add(0, o);
return System.currentTimeMillis()-start;
}
public static void main(String[] args) {
System.out.println("ArrayList 耗时:"+timeList(new ArrayList()));
System.out.println("LinkedList 耗时:"+timeList(new LinkedList()));
}
}
这时我的输出结果是
ArrayList 耗时:2463
LinkedList 耗时:15
二.空间复杂度
在 LinkedList 中有一个私有的内部类,定义如下:
private static class Entry {
Object element;
Entry next;
Entry previous;
}
每个 Entry 对象 reference 列表 中的一个元素,同时还有在 LinkedList 中它的上一个元素和下一个元素。一个有 1000 个元素的 LinkedList 对象将有 1000 个链接在一起 的 Entry 对象,每个对象都对应于列表中的一个元素。这样的话,在一个 LinkedList 结构中将有一个很大的空间开销,因为它要存储这 1000 个 Entity 对象的相关信息。
ArrayList 使用一个内置的数组来存 储元素,这个数组的起始容量是 10.当数组需要增长时,新的容量按如下公式获得:新容量=(旧容量*3)/2+1,也就是说每一次容量大概会增长 50%。 这就意味着,如果你有一个包含大量元素的 ArrayList 对象,那么最终将有很大的空间会被浪费掉,这个浪费是由 ArrayList 的工作方式本身造成 的。如果没有足够的空间来存放新的元素,数组将不得不被重新进行分配以便能够增加新的元素。对数组进行重新分配,将会导致性能急剧下降。如果我们知道一个 ArrayList 将会有多少个元素,我们可以通过构造方法来指定容量。我们还可以通过 trimToSize 方法在 ArrayList 分配完毕之后去掉浪 费掉的空间。
三.总结
ArrayList 和 LinkedList 在性能上各有优缺点,都有各自所适用的地方,总的说来可以描述如下:
1.对 ArrayList 和 LinkedList 而言,在列表末尾增加一个元素所花的开销都是固定的。对 ArrayList 而言,主要是在内部数组中增加一项,指向所添加的元素,偶 尔可能会导致对数组重新进行分配;而对 LinkedList 而言,这个开销是统一的,分配一个内部 Entry 对象。
2.在 ArrayList 的中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动;而在 LinkedList 的中间插入或删除一个元素的开销是固定的。
3.LinkedList 不支持高效的随机元素访问。
4.ArrayList 的空间浪费主要体现在在 list 列表的结尾预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗相当的空间可以这样说:当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList 会提供比较好的性能;当你的操作是在一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用 LinkedList 了。
12. 请用两个队列模拟堆栈结构
两个队列模拟一个堆栈,队列是先进先出,而堆栈是先进后出。模拟如下
队列 a 和 b
(1)入栈:a 队列为空,b 为空。例:则将”a,b,c,d,e”需要入栈的元素先放 a 中,a 进栈为”a,b,c,d,e”
(2)出栈:a 队列目前的元素为”a,b,c,d,e”。将 a 队列依次加入 Arraylist 集合 a 中。以倒序的方法,将 a 中的集合取出,放入 b 队列中,再将 b 队列出列。代码如下:
public static void main(String[] args) {
Queue<String> queue = new LinkedList<String>(); //a 队列
Queue<String> queue2=new LinkedList<String>(); //b 队列
ArrayList<String> a=new ArrayList<String>(); //arrylist 集合是中间参数
//往 a 队列添加元素
queue.offer("a");
queue.offer("b");
queue.offer("c");
queue.offer("d");
queue.offer("e");
System.out.print("进栈:");
//a 队列依次加入 list 集合之中
for(String q : queue){
a.add(q);
System.out.print(q);
}
//以倒序的方法取出(a 队列依次加入 list 集合)之中的值,加入 b 对列
for(int i=a.size()-1;i>=0;i--){
queue2.offer(a.get(i));
}
//打印出栈队列
System.out.println("");
System.out.print("出栈:");
for(String q : queue2){
System.out.print(q);
}
}
打印结果为(遵循栈模式先进后出):
进栈:a b c d e
出栈:e d c b a
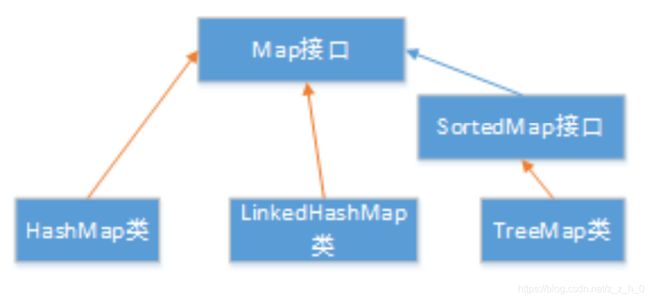
13. Collection 和 Map 的集成体系
Collection:
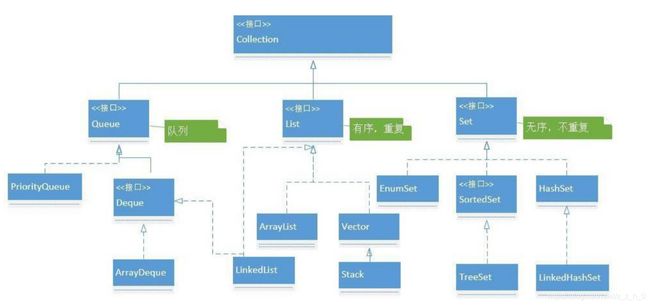
Map:
14. Map 中的 key 和 value 可以为 null 么?
HashMap 对象的 key、value 值均可为 null。
HahTable 对象的 key、value 值均不可为 null。
且两者的的 key 值均不能重复,若添加 key 相同的键值对,后面的 value 会自动覆盖前面的 value,但不会报错。
测试代码如下:
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<String, String>();//HashMap 对象
Map<String, String> tableMap = new Hashtable<String, String>();//HashTable 对象
map.put(null, null);
System.out.println("hashMap 的[key]和[value]均可以为 null:" + map.get(null));
try {
tableMap.put(null, "3");
System.out.println(tableMap.get(null));
} catch (Exception e) {
System.out.println("【ERROR】:hashTable 的[key]不能为 null");
}
try {
tableMap.put("3", null);
System.out.println(tableMap.get("3"));
} catch (Exception e) {
System.out.println("【ERROR】:hashTable 的[value]不能为 null");
}
}
}
运行结果:
hashMap 的[key]和[value]均可以为 null:null
【ERROR】:hashTable 的[key]不能为 null
【ERROR】:hashTable 的[value]不能为 null
Java程序员面试题(一)JavaSE基础 - 下
注:
内容截取自:黑马程序员Java面试宝典
仅供学习使用