容器(一)
一、泛型Generics
开发中需要时刻和数据打交道,如何组织这些数据是我们编程中重要的内容。 我们一般通过“容器”来容纳和管理数据。那什么是“容器”呢?生活中的容器不难理解,是用来容纳物体的,如锅碗瓢盆、箱子和包等。程序中的“容器”也有类似的功能,就是用来容纳和管理数据。
事实上,数组就是一种容器,可以在其中放置对象或基本类型数据。
数组的优势:是一种简单的线性序列,可以快速地访问数组元素,效率高。如果从效率和类型检查的角度讲,数组是最好的。
数组的劣势:不灵活。容量需要事先定义好,不能随着需求的变化而扩容。比如:我们在一个用户管理系统中,要把今天注册的所有用户取出来,那么这样的用户有多少个?我们在写程序时是无法确定的。因此,在这里就不能使用数组。
基于数组并不能满足我们对于“管理和组织数据的需求”,所以我们需要一种更强大、更灵活、容量随时可扩的容器来装载我们的对象。 这就是我们今天要学习的容器,也叫集合(Collection)。以下是容器的接口层次结构图:
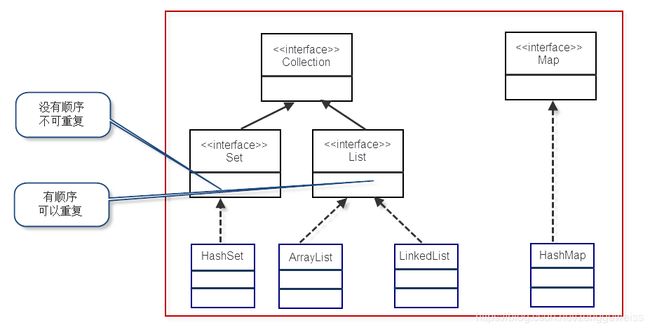
为了能够更好的学习容器,我们首先要先来学习一个概念:泛型。
泛型是JDK1.5以后增加的,它可以帮助我们建立类型安全的集合。在使用了泛型的集合中,遍历时不必进行强制类型转换。JDK提供了支持泛型的编译器,将运行时的类型检查提前到了编译时执行,提高了代码可读性和安全性。
泛型的本质就是“数据类型的参数化”。 我们可以把“泛型”理解为数据类型的一个占位符(形式参数),即告诉编译器,在调用泛型时必须传入实际类型。
1、自定义泛型
我们可以在类的声明处增加泛型列表,如:
此处,字符可以是任何标识符,一般采用这3个字母。
【示例1-1】泛型类的声明
class MyCollection {// E:表示泛型;
Object[] objs = new Object[5];
public E get(int index) {// E:表示泛型;
return (E) objs[index];
}
public void set(E e, int index) {// E:表示泛型;
objs[index] = e;
}
}
泛型E像一个占位符一样表示“未知的某个数据类型”,我们在真正调用的时候传入这个“数据类型”。
【示例1-2】泛型类的应用
public class TestGenerics {
public static void main(String[] args) {
// 这里的”String”就是实际传入的数据类型;
MyCollection mc = new MyCollection();
mc.set("aaa", 0);
mc.set("bbb", 1);
String str = mc.get(1); //加了泛型,直接返回String类型,不用强制转换;
System.out.println(str);
}
}
2、容器中使用泛型
容器相关类都定义了泛型,我们在开发和工作中,在使用容器类时都要使用泛型。这样,在容器的存储数据、读取数据时都避免了大量的类型判断,非常便捷。
【示例1-3】泛型类的在集合中的使用
public class Test {
public static void main(String[] args) {
// 以下代码中List、Set、Map、Iterator都是与容器相关的接口;
List list = new ArrayList();
Set mans = new HashSet();
Map maps = new HashMap();
Iterator iterator = mans.iterator();
}
}
通过阅读源码,我们发现Collection、List、Set、Map、Iterator接口都定义了泛型,如下图所示:

因此,我们在使用这些接口及其实现类时,都要使用泛型。
雷区:
我们只是强烈建议使用泛型。事实上,不使用编译器也不会报错!
二、Collection接口
Collection 表示一组对象,它是集中、收集的意思。Collection接口的两个子接口是List、Set接口。
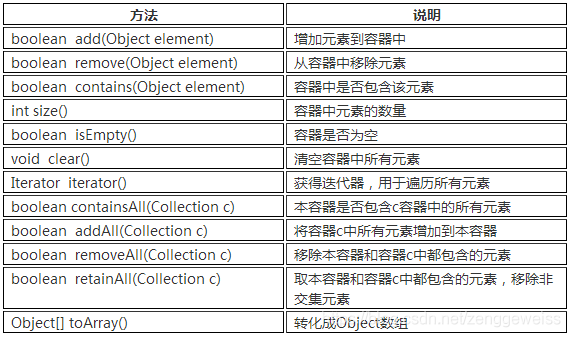
由于List、Set是Collection的子接口,意味着所有List、Set的实现类都有上面的方法。我们下一节中,通过ArrayList实现类来测试上面的方法。
三、List接口
1、List特点和常用方法
List是有序、可重复的容器。
有序:List中每个元素都有索引标记。可以根据元素的索引标记(在List中的位置)访问元素,从而精确控制这些元素。
可重复:List允许加入重复的元素。更确切地讲,List通常允许满足 e1.equals(e2) 的元素重复加入容器。
除了Collection接口中的方法,List多了一些跟顺序(索引)有关的方法,参见下表:
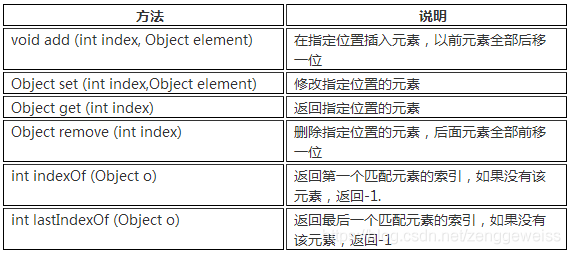
List接口常用的实现类有3个:ArrayList、LinkedList和Vector。
【示例3-1】List的常用方法
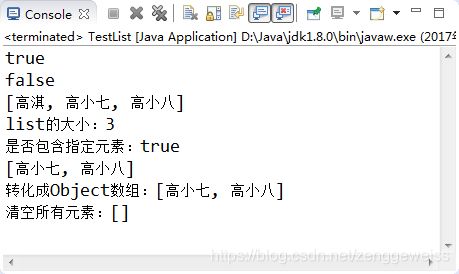
public class TestList {
/**
* 测试add/remove/size/isEmpty/contains/clear/toArrays等方法
*/
public static void test01() {
List list = new ArrayList();
System.out.println(list.isEmpty()); // true,容器里面没有元素
list.add("高淇");
System.out.println(list.isEmpty()); // false,容器里面有元素
list.add("高小七");
list.add("高小八");
System.out.println(list);
System.out.println("list的大小:" + list.size());
System.out.println("是否包含指定元素:" + list.contains("高小七"));
list.remove("高淇");
System.out.println(list);
Object[] objs = list.toArray();
System.out.println("转化成Object数组:" + Arrays.toString(objs));
list.clear();
System.out.println("清空所有元素:" + list);
}
public static void main(String[] args) {
test01();
}
}
执行结果如图3-1所示:
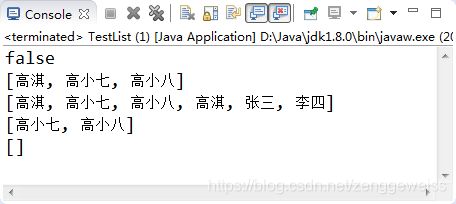
【示例3-2】两个List之间的元素处理
public class TestList {
public static void main(String[] args) {
test02();
}
/**
* 测试两个容器之间元素处理
*/
public static void test02() {
List list = new ArrayList();
list.add("高淇");
list.add("高小七");
list.add("高小八");
List list2 = new ArrayList();
list2.add("高淇");
list2.add("张三");
list2.add("李四");
System.out.println(list.containsAll(list2)); //false list是否包含list2中所有元素
System.out.println(list);
list.addAll(list2); //将list2中所有元素都添加到list中
System.out.println(list);
list.removeAll(list2); //从list中删除同时在list和list2中存在的元素
System.out.println(list);
list.retainAll(list2); //取list和list2的交集
System.out.println(list);
}
}
执行结果如图3-2所示:
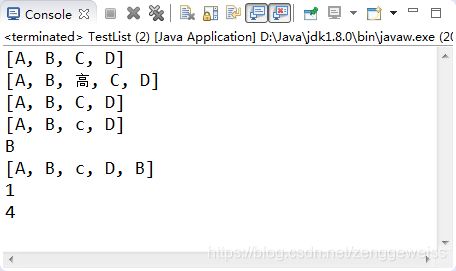
【示例3-3】List中操作索引的常用方法
public class TestList {
public static void main(String[] args) {
test03();
}
/**
* 测试List中关于索引操作的方法
*/
public static void test03() {
List list = new ArrayList();
list.add("A");
list.add("B");
list.add("C");
list.add("D");
System.out.println(list); // [A, B, C, D]
list.add(2, "高");
System.out.println(list); // [A, B, 高, C, D]
list.remove(2);
System.out.println(list); // [A, B, C, D]
list.set(2, "c");
System.out.println(list); // [A, B, c, D]
System.out.println(list.get(1)); // 返回:B
list.add("B");
System.out.println(list); // [A, B, c, D, B]
System.out.println(list.indexOf("B")); // 1 从头到尾找到第一个"B"
System.out.println(list.lastIndexOf("B")); // 4 从尾到头找到第一个"B"
}
}
执行结果如图3-3所示:
2、ArrayList特点和底层实现
ArrayList底层是用数组实现的存储。 特点:查询效率高,增删效率低,线程不安全。我们一般使用它。查看源码:
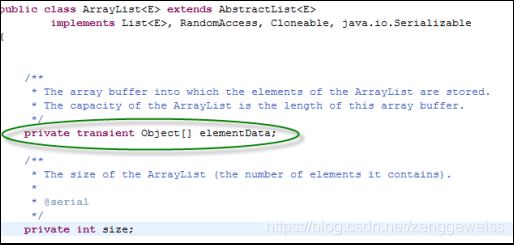
我们可以看出ArrayList底层使用Object数组来存储元素数据。所有的方法,都围绕这个核心的Object数组来开展。
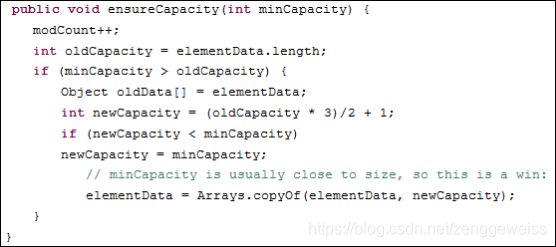
我们知道,数组长度是有限的,而ArrayList是可以存放任意数量的对象,长度不受限制,那么它是怎么实现的呢?本质上就是通过定义新的更大的数组,将旧数组中的内容拷贝到新数组,来实现扩容。 ArrayList的Object数组初始化长度为10,如果我们存储满了这个数组,需要存储第11个对象,就会定义新的长度更大的数组,并将原数组内容和新的元素一起加入到新数组中,源码如下:
3、LinkedList特点和底层实现
LinkedList底层用双向链表实现的存储。特点:查询效率低,增删效率高,线程不安全。
双向链表也叫双链表,是链表的一种,它的每个数据节点中都有两个指针,分别指向前一个节点和后一个节点。 所以,从双向链表中的任意一个节点开始,都可以很方便地找到所有节点。
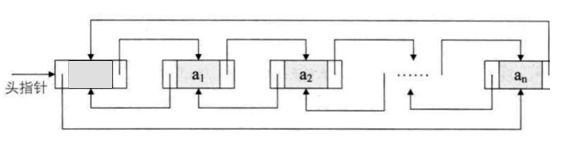
每个节点都应该有3部分内容:
class Node {
Node previous; //前一个节点
Object element; //本节点保存的数据
Node next; //后一个节点
}
我们查看LinkedList的源码,可以看到里面包含了双向链表的相关代码:

注意事项:
entry在英文中表示“进入、词条、条目”的意思。在计算机英语中一般表示“项、条目”的含义。
4、Vector向量
Vector底层是用数组实现的List,相关的方法都加了同步检查,因此“线程安全,效率低”。 比如,indexOf方法就增加了synchronized同步标记。

老鸟建议:
如何选用ArrayList、LinkedList、Vector?
1. 需要线程安全时,用Vector。
2. 不存在线程安全问题时,并且查找较多用ArrayList(一般使用它)。
3. 不存在线程安全问题时,增加或删除元素较多用LinkedList。