Interspeech 2017论文总结
今年的interspeech2017有两个section是关于情感的: Emotion Recognition 和 Emotion Modeling,共有12篇文章,best paper 提名的是关于多任务学习的文章。今年的interspeech主要是以多任务学习为主,占据了半壁江山。其余为一篇利用对抗自编码做压缩;一篇端到端;一篇离散转回归问题求解;一篇对话中的情感识别;一篇探讨不同的CNN对于问题的影响;一篇GMM用于情感识别的文章【没有仔细看】;
首先对所有论文进行总结,可以看出多任务学习是今年的主流
多任务文章【利用不同任务之间的相关性,提示系统性能】

Attention + 多任务【离散和连续标签都预测】
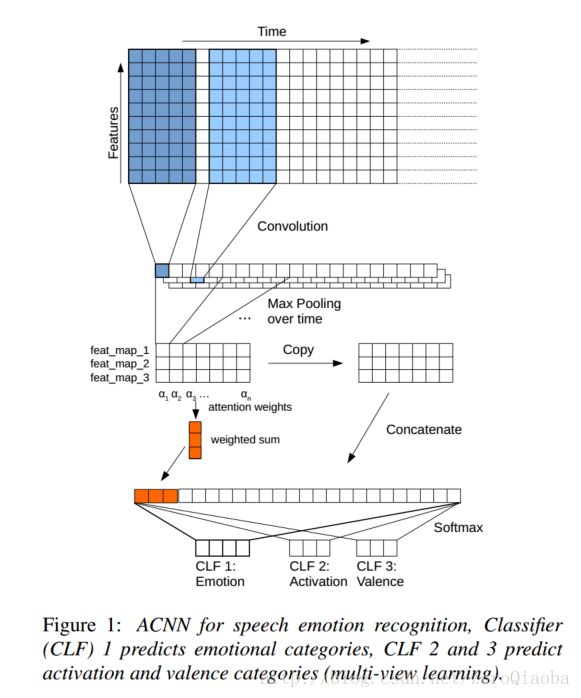
模型结构没什么好说的,这种可以清晰看见感受野的绘图方式,还是值得学习的。
输入:音频特征,用openSMILE提取;输入帧级别的特征,没有统计方程。【作者认为原始波形会使得模型输入维度太高,容易过拟合,因此不用raw wave 端到端的方法】
输出:多任务,连续+离散 多任务学习。
数据库: IEMOCAP,得到目前state-of-art的结果,63.85%
目标:分类,使得平均准确率最高。

这是best paper候选文章。作者提出了多任务学习,将三个任务一起训练。并加入主次任务,体现在loss上面。主要观点:主任务和次任务有相关性。【feature work: GAN+多任务??】【多任务体现在多输出上面】
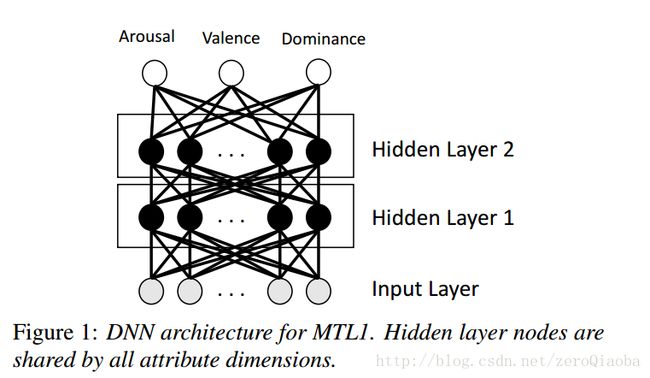
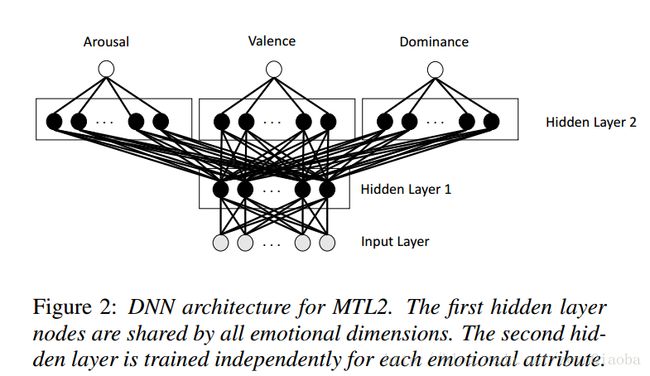
特征:6373 维度 Interspeech 2013特征。
数据集:MSP-PADCAST【自己收集】, USC-IEMOCAP,MSP-IMPROV
模型:MTL2好于MTL1
损失函数:训练过程中,是使得目标CCC最大,两个次任务来辅助主任务取得好成绩。
 】
】

将LSTM应用到多任务学习。(LSTM-MTL)。 [测试结果:它所谓的cross-corpus,就是简单的把不同的数据库整合起来,把所有的数据直接拿过来用,留下一部分用来做测试] 【仍然是多输出】

数据库:比较全面的数据库【总共有5个数据库】,有四种情感类别。【AIBO,IEMOCAP数据量比较大】

特征:传统语音特征,F0, voice probability, zero-crossing-rate, l2 dimension MFCC with energy and their first time derivatives, totaling 32 features.
模型:比较了DNN-MTL 和 LSTM-MTL
多任务:gender和natural,emotion
可视化:T-SNE
迁移学习

Progressive Neural Networks这个方法用于IEMOCAP and MSP-IMPROV两个数据库上。多任务体现在:1 训练了gender模型,speaker模型,将其迁移到情感预测上;2 在一个数据库上训练,再迁移到另一个数据库上。【任务的迁移;数据库的迁移】

Progressive Neural Networks借鉴的是2016/9/7 Deepmind的文章,它提出了一种迁移学习的方法,认为他们的方法,更适合多任务学习和迁移学习,减轻了遗忘。【因为每一个target task 的前几层都与source target相连】
这篇Interspeech文章就是比较了三种模型的搭建方法:1 只有目标任务的数据,训练一个DNN网络;2 finetuning; 3 Progressive Neural Network.
本文实现了利用gender模型和speaker模型,迁移到情感模型上去。
对抗自编码

这篇文章就是对抗自编码在IEMOCAP上的应用。主要考察了多种降维方式,以降低情感数据的维度。主要借鉴了2016/5/25的Goodfellow关于Adversarial Autoencoders的文章。下图列举了有label和无label两种模型训练的示意图。
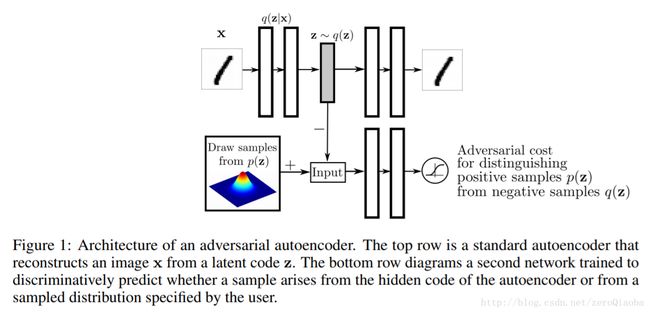

本文有两个实验,用code vector做分类;用AAE做数据增强。AAE降维方式比一般的降维方式要好。降到2维仍然有很好的区分能力。
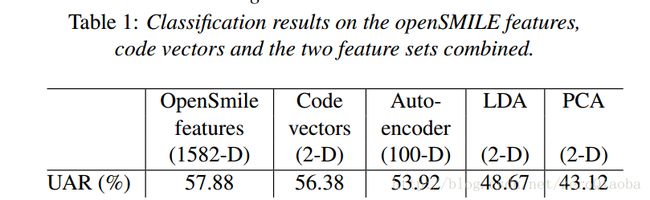
作者认为,以后可以考虑frame level features,而不是utterance level features【utterance level features就是加上统计回归方程的特征】。但是本文整体还是应用性质。
端到端

端到端,语谱图+神经网络[详细介绍了怎么提取语谱图]【单单语谱图是不够的,还在去噪方面讨论】

主要工作:探讨不同模型结构,如何应对有噪声的语音
数据库:IEMOCAP
去噪:认为语音的短时谐波信号比较自然,假设情感状态保存在有声音的部分,利用开源的pitch detector提起pitch,利用谐波滤波器得到modified log-power-spectra。
CNN卷积

这篇文章,认为扩大感受野和输出更加平滑的预测值, 对于CCC很重要。[Dilated convolution network] and [Down/up network]。测试了两种卷积模型:

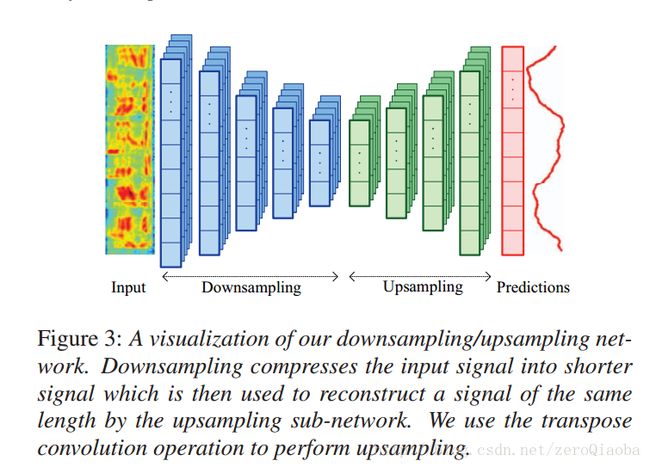
Dilated convolution network: 扩大感受野
Down/up network: 扩大感受野,平滑曲线
数据库:AVEC2016的RECOLA
评价指标:CCC和RMSE
连续离散化预测

离散化连续预测的标签【保持连续性很关键】,详细信息请查看之前的一篇博客

数据集:RECOLA AVEC2016数据库,数据每40ms标注一次;官方的评价指标是CCC,RMSE
特征:40维度log Mel features。窗长25ms,移动10ms。级联4帧特征,得到160维度向量,感受时长为40ms,和标准相同。最后加上z-normalization。【CCC和RMSE是根据对应位置的值计算得到的,不是连续的两个曲线计算,而是对应位置的采样点计算得到】
方法:
- 【1】 标签离散化
对所有的曲线做k-mean量化处理。发现离散化后,CCC和RMSE相差不大。

- 【2】 BLSTM-RNN训练
这里的多任务只是不同参数建模结果的合并【叫做多任务有点问题】
目标函数:最小化CCE,实际上就是T个任务交叉熵的和。每个任务又有F个帧,每一帧和目标计算交叉熵

在交叉熵的基础上,增加了一个C(y, l)。使得目标值和正确的label相距越远,损失越大。
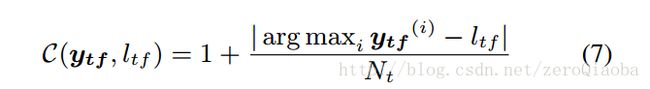
优化 CCE要更加稳定。【??感觉就是加速收敛】
- 【3】 Emotion decoding (借鉴seq2seq的解码方式,使得模型预测结果更加连续)
为了利用概率值,得到更加平滑的曲线,采用两阶段HMM.[2014年文章],但是我没有看懂
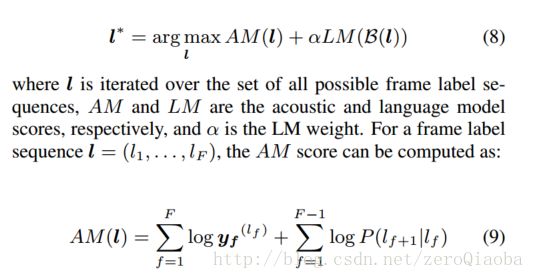
朴素贝叶斯考虑维度空间的距离信息

这篇文章,考虑emotion-pair,同时将维度空间的距离信息考虑进去。
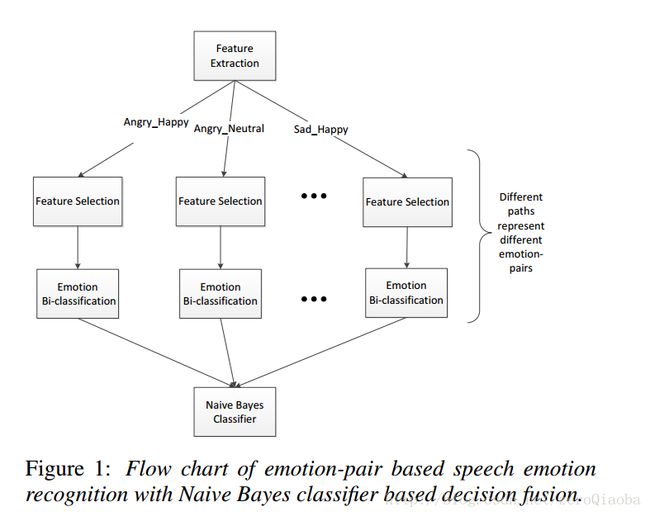
数据集:IEMOCAP
特征: Interspeech 2009, total 384 dimension features
特征选择: z-normalization,主要认为不同说话人的average characteristic of neural utterances差异不大。归一化可以排除多个说话人的影响。然后用binary logistic regression作特征选择。每一个子任务【emotion-pair】特征维数不一样。
Naïve Bayes classifier特征融合:将额外的空间维度信息考虑进去。
缺点:只是考虑了属于哪一类,但是没有考虑计算出来的二分类概率。

多说人情感识别

这篇文章的内容比较简单,做的是基于多人对话之间的相互关系进行情感识别。也是说:前一个说话人的情感和当前说话人的情感有相关性。当前说话人之前的情感和现在的情感也有相关性。

数据集:IEMOCAP
Utterance 模型: attention based sequence to sequence model
最后总结一下情感识别的数据集,音频特征,发展趋势
数据库

特征

发展趋势

参考文章:
[1] Sahu, Saurabh et al. “Adversarial Auto-encoders for Speech Based Emotion Recognition.” (2017).
[2] Dang, Ting et al. “An Investigation of Emotion Prediction Uncertainty Using Gaussian Mixture Regression.” (2017).
[3] Neumann, Michael and Ngoc Thang Vu. “Attentive Convolutional Neural Network based Speech Emotion Recognition: A Study on the Impact of Input Features, Signal Length, and Acted Speech.” CoRR abs/1706.00612 (2017).
[4] Khorram, Soheil et al. “Capturing Long-term Temporal Dependencies with Convolutional Networks for Continuous Emotion Recognition.” CoRR abs/1708.07050 (2017).
[5] Le, Duc et al. “Discretized Continuous Speech Emotion Recognition with Multi-Task Deep Recurrent Neural Network.” (2017).
[6] Satt, Aharon et al. “Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms.” (2017).
[7] Zhang, Ruo et al. “Interaction and Transition Model for Speech Emotion Recognition in Dialogue.” (2017).
[8] Parthasarathy, Srinivas and Carlos Busso. “Jointly Predicting Arousal, Valence and Dominance with Multi-Task Learning.” (2017).
[9] Gideon, John et al. “Progressive Neural Networks for Transfer Learning in Emotion Recognition.” CoRR abs/1706.03256 (2017).
[10] Ma, Xi et al. “Speech Emotion Recognition with Emotion-Pair based Framework Considering Emotion Distribution Information in Dimensional Emotion Space.” (2017).
[11] Kim, Jaebok et al. “Towards Speech Emotion Recognition “in the wild” using Aggregated Corpora and Deep Multi-Task Learning.” CoRR abs/1708.03920 (2017).
[12] Chasaide, Ailbhe Ní et al. “Voice-to-Affect Mapping: Inferences on Language Voice Baseline Settings.” (2017).
[13] Rusu, Andrei A. et al. “Progressive Neural Networks.” CoRR abs/1606.04671 (2016).
[14] Rusu, Andrei A. et al. “Progressive Neural Networks.” CoRR abs/1606.04671 (2016).
[15] Lee, Jinkyu and Ivan Tashev. “High-level feature representation using recurrent neural network for speech emotion recognition.” INTERSPEECH (2015).