【Druid】(七)E-MapReduce 增强型 Druid 入门
文章目录
- 一、前言
- 二、什么是E-MapReduce ?
- 三、E-MapReduce 增强型 Druid 有哪些特性?
- 四、快速入门
- 4.1 背景信息
- 4.2 创建Druid集群
- 4.3 配置集群
- 4.3.1 配置HDFS作为E-MapReduce Druid的deep storage
- 4.3.2 配置OSS作为E-MapReduce Druid的deep storage
- 4.3.3 配置RDS作为E-MapReduce Druid的元数据存储
- 4.3.4 配置组件内存
- 4.4 访问Druid web页面
- 4.5 批量索引
- 4.5.1 与Hadoop集群交互
- 4.5.2 使用Hadoop对批量数据创建索引
- 4.6 实时索引
- 4.7 索引失败问题分析思路
一、前言
通过前面的学习,我们已经对 Apache Druid 有了初步的认识,包括它的原理、架构以及数据结构和数据摄取。接下来就得讲讲咱们阿里云 E-MapReduce (EMR) ,作为构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品,它集成的 Druid 有什么优势呢,我们一起来看看 ( •̀ ω •́ )✧。
本文整理自阿里云产品文档:https://help.aliyun.com/document_detail/72703.html?spm=a2c4g.11186623.6.779.2335145dtUf8dY
二、什么是E-MapReduce ?
E-MapReduce构建于云服务器ECS上,基于开源的Apache Hadoop和Apache Spark,可以方便地使用Hadoop和Spark生态系统中的其他周边系统(例如,Apache Hive、Apache Pig和HBase等)来分析和处理自己的数据。不仅如此,E-MapReduce还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云OSS和RDS等)进行数据传输。
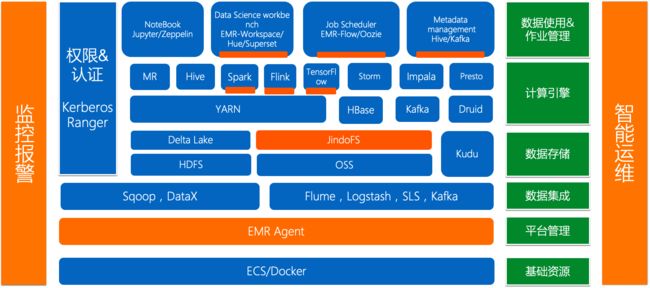
从上图可以看出,E-MapReduce集群是基于Hadoop的生态环境搭建的,可以与阿里云的对象存储服务(OSS)进行无缝数据交换。此外,E-MapReduce集群也可以与云数据库(RDS)等云服务无缝对接,方便您将数据在多个系统之间进行共享和传输,以满足不同业务类型的访问需要。
三、E-MapReduce 增强型 Druid 有哪些特性?
E-MapReduce Druid 基于Apache Druid 做了大量的改进,包括与E-MapReduce和阿里云周边生态的集成、方便的监控与运维支持、易用的产品接口等等,真正做到了即买即用和 7*24 免运维。
E-MapReduce Druid 目前支持的特性如下所示:
- 支持以 OSS 作为 deep storage。
- 支持将 OSS 文件作为批量索引的数据来源。
- 支持从日志服务(Log Service)流式地索引数据(类似于 Kafka),并提供高可靠保证和 exactly-once 语义。
- 支持将元数据存储到 RDS。
- 集成了 Superset 工具。
- 方便地扩容、缩容(缩容针对 task 节点)。
- 丰富的监控指标和告警规则。
- 坏节点迁移。
- 具有高安全性。
- 支持 HA。
四、快速入门
从EMR-3.11.0版本开始,E-MapReduce支持将E-MapReduce Druid作为E-MapReduce的一个集群类型。
4.1 背景信息
将E-MapReduce Druid作为一种单独的集群类型,而不再是在Hadoop集群中增加Druid组件,主要基于以下几方面的考虑:
- E-MapReduce Druid可以完全脱离Hadoop来使用。
- 大数据量情况下,E-MapReduce Druid对内存要求比较高,尤其是Broker节点Historical节点。E-MapReduce Druid本身不受YARN管控 ,在多服务运行时容易发生资源抢夺。
- Hadoop作为基础设施,其规模可以比较大,而E-MapReduce Druid集群可以比较小,两者配合起来工作灵活性更高。
4.2 创建Druid集群
在创建集群时选择Druid集群类型即可,具体创建集群操作请参见创建集群。
说明:在创建E-MapReduce Druid集群时可以勾选YARN和Superset服务,E-MapReduce Druid集群自带的HDFS和YARN仅供测试使用,原因如背景信息所述。对于生产环境,强烈建议您采用专门的Hadoop集群。
4.3 配置集群
4.3.1 配置HDFS作为E-MapReduce Druid的deep storage
对于独立的E-MapReduce Druid集群,如果您需要将索引数据存放在另外一个Hadoop集群的HDFS上,则您首先需要设置两个集群的连通性(请参见下文的与Hadoop集群交互),然后在E-MapReduce Druid配置页面,配置以下两个选项并重启服务即可(配置项位于配置页面的common.runtime)。
- druid.storage.type设置为hdfs。
- druid.storage.storageDirectory:HDFS目录,强烈建议填写完整目录,例如:
hdfs://emr-header-1.cluster-xxxxxxxx:9000/druid/segments。
说明:如果Hadoop集群为HA集群,emr-header-1.cluster-xxxxx:9000需要改成emr-cluster,或者把端口9000改成8020。
4.3.2 配置OSS作为E-MapReduce Druid的deep storage
E-MapReduce Druid支持以OSS作为deep storage,借助于E-MapReduce的免AccessKey 能力,E-MapReduce Druid不用做AccessKey配置即可访问OSS。由于OSS的访问能力是借助于HDFS的OSS功能实现的,因此在配置时,druid.storage.type需要仍然配置为HDFS。
- druid.storage.type设置为hdfs。
- druid.storage.storageDirectory: (如
oss://emr-druid-cn-hangzhou/segments)
由于OSS访问借助了HDFS,因此您需要选择以下两种方案之一:
- 创建集群的时候选择安装HDFS,系统自动安装好HDFS。
- 在E-MapReduce Druid的配置目录
/etc/ecm/druid-conf/druid/_common/下新建hdfs-site.xml,内容如下,然后将该文件拷贝至所有节点的相同目录下。
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.oss.impl</name>
<value>com.aliyun.fs.oss.nat.NativeOssFileSystem</value>
</property>
<property>
<name>fs.oss.buffer.dirs</name>
<value>file:///mnt/disk1/data,...</value>
</property>
<property>
<name>fs.oss.impl.disable.cache</name>
<value>true</value>
</property>
</configuration>
其中fs.oss.buffer.dirs可以设置多个路径。
4.3.3 配置RDS作为E-MapReduce Druid的元数据存储
默认情况下E-MapReduce Druid利用header-1节点上的本地MySQL数据库作为元数据存储。您也可以配置使用阿里云RDS作为元数据存储。
下面以RDS MySQL版为例演示配置。在具体配置之前,请先确保:
- 已创建RDS MySQL实例。
- 为E-MapReduce Druid访问RDS MySQL创建了单独的账户(不推荐使用root),假设账户名为druid,密码为druidpw。
- 为E-MapReduce Druid元数据创建单独的MySQL数据库,假设数据库名为druiddb。
- 确保账户druid有权限访问druiddb。
在E-MapReduce管理控制台,进入E-MapReduce Druid集群,单击Druid组件,选择配置选项卡,找到common.runtime配置文件。单击自定义配置,添加如下三个配置项:
- druid.metadata.storage.connector.connectURI,值为
jdbc:mysql://rm-xxxxx.mysql.rds.aliyuncs.com:3306/druiddb。 - druid.metadata.storage.connector.user,值为druid。
- druid.metadata.storage.connector.password,值为druidpw。
依次单击右上角的保存、部署配置文件到主机、重启所有组件,配置即可生效。
登录RDS管理控制台,查看druiddb创建表的情况,如果正常,您将会看到一些druid自动创建的表。
4.3.4 配置组件内存
E-MapReduce Druid组件内存设置主要包括两方面:堆内存(通过jvm.config配置)和direct内存(通过jvm.config和runtime.properteis配置)。在创建集群时,E-MapReduce会自动生成一套配置,不过在某些情况下您仍然可能需要自己调整内存配置。
要调整组件内存配置,可以通过E-MapReduce控制台进入到集群组件,在页面上进行操作。
说明 对于 direct 内存,调整时请确保:
-XX:MaxDirectMemorySize >= druid.processing.buffer.sizeBytes * (druid.processing.numMergeBuffers + druid.processing.numThreads + 1)
4.4 访问Druid web页面
E-MapReduce Druid自带三个Web页面:
- Overlord:
http://emr-header-1.cluster-1234:18090,用于查看task运行情况。 - Coordinator:
http://emr-header-1.cluster-1234:18081,用于查看segments存储情况,并设置rule加载和丢弃segments。 - Router(EMR-3.23.0及以上版本):
http://emr-header-1.cluster-1234:18888,也称之为console,是新版Druid的统一入口。
E-MapReduce提供三种方式访问E-MapReduce Druid的Web页面:
- 在集群管理页面,单击访问链接与端口,找到Druid overlord或Druid coordinator链接,单击链接进入。
说明 您可以使用Knox账号访问Druid Web页面,Knox账号创建请参见管理用户,Knox使用请参见Knox 使用说明。
- 通过建立SSH隧道,开启代理浏览器访问。具体操作步骤请参见通过SSH隧道方式访问开源组件Web UI。地址
- 通过公网IP+端口访问,如
http://123.123.123.123:18090(不推荐,请通过安全组设置合理控制公网访问集群权限)。
4.5 批量索引
4.5.1 与Hadoop集群交互
您在创建E-MapReduce Druid集群时如果勾选了HDFS和YARN(自带Hadoop集群),那么系统将会自动为您配置好与HDFS和YARN的交互,您无需做额外操作。下面的介绍是配置独立E-MapReduce Druid集群与独立Hadoop集群之间交互,这里假设E-MapReduce Druid集群cluster id 为1234,Hadoop集群cluster id为5678。另外请严格按照指导进行操作,如果操作不当,集群可能就不会按照预期工作。
对于与非安全独立Hadoop集群交互,请按照如下操作进行:
-
确保集群间能够通信(两个集群在一个安全组下,或两个集群在不同安全组,但两个安全组之间配置了访问规则)。
-
在E-MapReduce Druid集群的每个节点的指定路径下,放置一份Hadoop集群中
/etc/ecm/hadoop-conf路径下的core-site.xml、hdfs-site.xml、yarn-site.xml、 mapred-site.xml文件。 这些文件在E-MapReduce Druid集群节点上放置的路径与E-MapReduce集群的版本有关,详情说明如下:- EMR-3.23.0及以上版本:
/etc/ecm/druid-conf/druid/cluster/_common - EMR-3.23.0以下版本:
/etc/ecm/druid-conf/druid/_common
- EMR-3.23.0及以上版本:
说明 如果创建集群时选了自带Hadoop,则在上述目录下会有几个软链接指向自带Hadoop的配置,请先移除这些软链接。
- 将Hadoop集群的hosts写入到E-MapReduce Druid集群的hosts列表中,注意Hadoop集群的hostname应采用长名形式,如emr-header-1.cluster-xxxxxxxx,且最好将Hadoop的hosts放在本集群hosts之后,例如:
...
10.157.*.* emr-as.cn-hangzhou.aliyuncs.com
10.157.*.* eas.cn-hangzhou.emr.aliyuncs.com
192.168.*.* emr-worker-1.cluster-1234 emr-worker-1 emr-header-2.cluster-1234 emr-header-2 iZbp1h9g7boqo9x23qb****
192.168.*.* emr-worker-2.cluster-1234 emr-worker-2 emr-header-3.cluster-1234 emr-header-3 iZbp1eaa5819tkjx55y****
192.168.*.* emr-header-1.cluster-1234 emr-header-1 iZbp1e3zwuvnmakmsje****
--以下为hadoop集群的hosts信息
192.168.*.* emr-worker-1.cluster-5678 emr-header-2.cluster-5678 iZbp195rj7zvx8qar4f****
192.168.*.* emr-worker-2.cluster-5678 emr-header-3.cluster-5678 iZbp15vy2rsxoegki4q****
192.168.*.* emr-header-1.cluster-5678 iZbp10tx4egw3wfnh5o****
对于安全Hadoop集群,请按如下操作进行:
-
确保集群间能够通信(两个集群在一个安全组下,或两个集群在不同安全组,但两个安全组之间配置了访问规则)。
-
在E-MapReduce Druid集群的每个节点的指定路径下,放置一份Hadoop集群
/etc/ecm/hadoop-conf路径下的core-site.xml、hdfs-site.xml、yarn-site.xml、 mapred-site.xml文件,并修改core-site.xml中hadoop.security.authentication.use.has为false。
其中,core-site.xml、hdfs-site.xml、yarn-site.xml、 mapred-site.xml文件在E-MapReduce Druid集群节点上放置的路径与E-MapReduce集群的版本有关,详情说明如下:- EMR-3.23.0 及以上版本:/etc/ecm/druid-conf/druid/cluster/_common
- EMR-3.23.0 以下版本:/etc/ecm/druid-conf/druid/_common
其中,hadoop.security.authentication.use.has是一个客户端配置,目的是让用户能够使用AccessKey进行认证。如果使用Kerberos认证方式,则需要disable该配置。
- 将Hadoop集群的hosts写入到E-MapReduce Druid集群每个节点的hosts列表中,注意Hadoop集群的hostname应采用长名形式,如emr-header-1.cluster-xxxxxxxx,且最好将Hadoop的hosts放在本集群hosts之后。
- 设置两个集群间的Kerberos跨域互信,详情请参见跨域互信。
- 在Hadoop集群的所有节点下都创建一个本地druid账户(useradd -m -g hadoop druid),或者设置 druid.auth.authenticator.kerberos.authToLocal(具体预发规则请参见Druid-Kerberos)创建Kerberos账户到本地账户的映射规则。推荐第一种做法,操作简便不易出错。
说明 默认在安全Hadoop集群中,所有Hadoop命令必须运行在一个本地的账户中,该本地账户需要与principal的name部分同名。YARN也支持将一个principal映射至本地一个账户,即上文第二种做法。
- 重启Druid服务。
4.5.2 使用Hadoop对批量数据创建索引
E-MapReduce Druid自带了一个名为wikiticker的例子,位于${DRUID_HOME}/quickstart/tutorial下面(${DRUID_HOME}默认为/usr/lib/druid-current)。wikiticker文件(wikiticker-2015-09-12-sampled.json.gz)的每一行是一条记录,每条记录是个json对象。其格式如下所示:
{
"time": "2015-09-12T00:46:58.771Z",
"channel": "#en.wikipedia",
"cityName": null,
"comment": "added project",
"countryIsoCode": null,
"countryName": null,
"isAnonymous": false,
"isMinor": false,
"isNew": false,
"isRobot": false,
"isUnpatrolled": false,
"metroCode": null,
"namespace": "Talk",
"page": "Talk:Oswald Tilghman",
"regionIsoCode": null,
"regionName": null,
"user": "GELongstreet",
"delta": 36,
"added": 36,
"deleted": 0
}
使用Hadoop对批量数据创建索引,请按照如下步骤进行操作:
- 将该压缩文件解压,并放置于HDFS的一个目录下(如
hdfs://emr-header-1.cluster-5678:9000/druid)。 在Hadoop集群上执行如下命令。
### 如果是在独立Hadoop集群上进行操作,做好两个集群互信之后需要拷贝一个 druid.keytab到Hadoop集群再kinit。
kinit -kt /etc/ecm/druid-conf/druid.keytab druid
###
hdfs dfs -mkdir hdfs://emr-header-1.cluster-5678:9000/druid
hdfs dfs -put ${DRUID_HOME}/quickstart/tutorial/wikiticker-2015-09-12-sampled.json hdfs://emr-header-1.cluster-5678:9000/druid
对于安全集群执行 HDFS 命令前先修改/etc/ecm/hadoop-conf/core-site.xml中hadoop.security.authentication.use.has为false。
请确保已经在Hadoop集群每个节点上创建名为druid的Linux账户。
- 准备一个数据索引任务文件
${DRUID_HOME}/quickstart/tutorial/wikiticker-index.json,如下所示:
{
"type" : "index_hadoop",
"spec" : {
"ioConfig" : {
"type" : "hadoop",
"inputSpec" : {
"type" : "static",
"paths" : "hdfs://emr-header-1.cluster-5678:9000/druid/wikiticker-2015-09-12-sampled.json"
}
},
"dataSchema" : {
"dataSource" : "wikiticker",
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "day",
"queryGranularity" : "none",
"intervals" : ["2015-09-12/2015-09-13"]
},
"parser" : {
"type" : "hadoopyString",
"parseSpec" : {
"format" : "json",
"dimensionsSpec" : {
"dimensions" : [
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user"
]
},
"timestampSpec" : {
"format" : "auto",
"column" : "time"
}
}
},
"metricsSpec" : [
{
"name" : "count",
"type" : "count"
},
{
"name" : "added",
"type" : "longSum",
"fieldName" : "added"
},
{
"name" : "deleted",
"type" : "longSum",
"fieldName" : "deleted"
},
{
"name" : "delta",
"type" : "longSum",
"fieldName" : "delta"
},
{
"name" : "user_unique",
"type" : "hyperUnique",
"fieldName" : "user"
}
]
},
"tuningConfig" : {
"type" : "hadoop",
"partitionsSpec" : {
"type" : "hashed",
"targetPartitionSize" : 5000000
},
"jobProperties" : {
"mapreduce.job.classloader": "true"
}
}
},
"hadoopDependencyCoordinates": ["org.apache.hadoop:hadoop-client:2.8.5"]
}
说明
spec.ioConfig.type设置为hadoop。
spec.ioConfig.inputSpec.paths为输入文件路径。
tuningConfig.type为hadoop。
tuningConfig.jobProperties设置了mapreduce job的classloader。
hadoopDependencyCoordinates 制定了hadoop client的版本。
- 在E-MapReduce Druid集群上运行批量索引命令
cd ${DRUID_HOME}
curl --negotiate -u:druid -b ~/cookies -c ~/cookies -XPOST -H 'Content-Type:application/json' -d @quickstart/tutorial/wikiticker-index.json http://emr-header-1.cluster-1234:18090/druid/indexer/v1/task
其中 -negotiate、-u、-b、-c等选项是针对安全E-MapReduce Druid集群的。Overlord的端口默认为18090。
- 查看作业运行情况
在浏览器访问http://emr-header-1.cluster-1234:18090/console.html查看作业运行情况
- 根据Druid语法查询数据
Druid有自己的查询语法。请准备一个描述您如何查询json格式的查询文件,如下所示为对wikiticker数据的一个top N查询(${DRUID_HOME}/quickstart/tutorial/wikiticker-top-pages.json):
{
"queryType" : "topN",
"dataSource" : "wikiticker",
"intervals" : ["2015-09-12/2015-09-13"],
"granularity" : "all",
"dimension" : "page",
"metric" : "edits",
"threshold" : 25,
"aggregations" : [
{
"type" : "longSum",
"name" : "edits",
"fieldName" : "count"
}
]
}
在命令行界面运行下面的命令即可看到查询结果。
cd ${DRUID_HOME}
curl --negotiate -u:druid -b ~/cookies -c ~/cookies -XPOST -H 'Content-Type:application/json' -d @quickstart/tutorial/wikiticker-top-pages.json 'http://emr-header-1.cluster-1234:18082/druid/v2/?pretty'
4.6 实时索引
对于数据从Kafka集群实时到E-MapReduce Druid集群进行索引,我们推荐使用Kafka Indexing Service扩展,提供了高可靠保证,支持exactly-once语义。关于Druid Kafka Indexing Service 实时消费Kafka数据具体步骤,请参见Kafka Indexing Service。
如果您的数据实时打到了阿里云日志服务(SLS),并想用E-MapReduce Druid实时索引这部分数据,我们提供了SLS Indexing Service扩展。使用SLS Indexing Service避免了您额外建立并维护Kafka集群的开销。SLS Indexing Service的作用与Kafka Indexing Service相同,也提供高可靠保证和 Exactly-Once语义。在这里,您完全可以把SLS当成一个Kafka来使用。详情请参见 SLS-Indexing-Service。
Kafka Indexing Service和SLS Indexing Service是类似的,都使用拉的方式从数据源拉取数据到E-MapReduce Druid集群,并提供高可靠保证和 exactly-once语义。
4.7 索引失败问题分析思路
当发现索引失败时,一般遵循如下排错思路:
- 对于批量索引
- 如果curl直接返回错误,或者不返回,检查一下输入文件格式,或者curl加上 -v 参数,观察REST API的返回情况。
- 在Overlord页面观察作业执行情况,如果失败,查看页面上的logs。
- 在很多情况下并没有生成logs,如果是Hadoop作业,打开YARN页面查看是否有索引作业生成,并查看作业执行log。
- 如果上述情况都没有定位到错误,需要登录到E-MapReduce Druid集群,查看Overlord的执行日志(位于/mnt/disk1/log/druid/overlord-emr-header-1.cluster-xxxx.log),如果是HA集群,查看您提交作业的那个Overlord。
- 如果作业已经被提交到Middlemanager,但是从Middlemanager返回了失败,则需要从Overlord中查 看作业提交到了那个worker,并登录到相应的worker,查看Middlemanager的日志(位于/mnt/disk1/log/druid/middleManager-emr-header-1.cluster-xxxx.log)。
- 对于Kafka Indexing Service和SLS Indexing Service
- 首先查看Overlord的Web页面:http://emr-header-1:18090, 查看Supervisor的运行状态,检查payload是否合理。
- 查看失败task的log。
- 如果不能从task log定位出失败原因,则需要从Overlord log排查问题。