一阶段课堂笔记——Set接口和Map接口(1)
1.Set接口
1.1存储特点
相对无序存储,不可以存储相同的元素,不能通过下标访问
1.2常用方法
public static void main(String[] args) {
//创建集合
Set names=new HashSet<>();
//1.添加元素
names.add("池子");
names.add("王建国");
names.add("张绍刚");
names.add("李诞");
names.add("李诞");
System.out.println("打印:"+names.toString());
//2.删除
names.remove("王建国");
System.out.println("删除之后" + names.toString());
//3.遍历
//3.1
System.out.println("------------------------");
for (String name : names) {
System.out.println(name);
}
//3.2
System.out.println("-------------------------");
Iterator it=names.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
//4.判断
System.out.println(names.contains("池子"));
} 1.3 Set常用实现类
1.3.1 HashSet
此类实现了Set接口,由哈希表支持,它不保证set的迭代顺序,特别是它不保证该顺序恒久不变。此类允许使用null元素。
存储特点:相对无序存储,不可以存储相同元素(排重),是通过哈希表实现的集合
哈希表的存储结构:jdk1.7之前 数组+链表
jdk1.8 数组+链表+红黑树(总容量>=64 链表长度>=8 自动转为红黑树)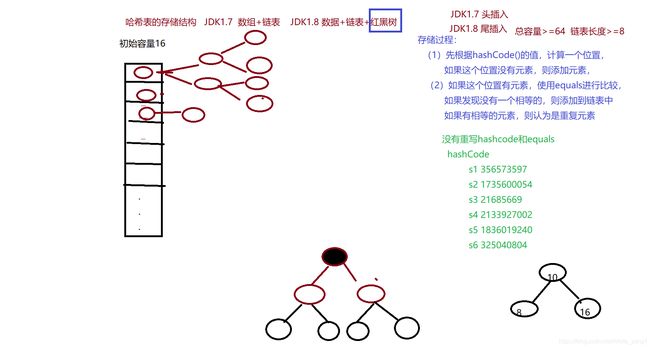
重写hashCode()和equals() 达到排重效果
hashcode是Object中的方法,每个对象的hashCode值是唯一的,可以理解为这个对象在内存中的位置。字符串String的hashCode()是根据内容计算的。
(1)重写hashCode()的原因:如果不重写hashCode,那么每个元素的hashCode值一定不一样,如果有相同的的元素就达不到 排重的效果,也就是说就一定会有重复元素。(注:这里重写返回的是内容的hashCode值)
(2)重写equals()的原因:当一些元素hashCode相同时,说明他们位置相同也就是都要放在一个格里面(如上图),这时就要比 较具体内容,如果不重写equals()那么他们比较的是每个对象的地址,同样达不到排重的效果。
例:重写Student类中的hashCode()和equals()
public class Student{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
name.equals(student.name);
}
@Override
public int hashCode() {
return this.name.hashCode()*13+age;//这里*13是为了让元素分散些避免都挤在一个格
// return Objects.hash(name, age);//idea自带的重写
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}1.3.2 LinkedHashSet
是具有可预知迭代顺序的Set接口的哈希表和链表实现,是HashSet的子类。
存储结构:有序存储,不可以存储相同元素,通过链表实现的有序集合。
排重方法:和HashSet集合排重方法一致。
1.3.3 TreeSet集合
使用元素的自然顺序对元素进行排序,或者根据创建set时提供的Comparator进行排序,具体取决于使用的构造方法。
存储特点:无序存储(添加元素的顺序),不能存储相同元素,通过红黑树实现的集合,可以给元素进行重新排序(在集合中的顺 序)。
例:
(1)使用元素的自然顺序进行排序
public static void main(String[] args) {
TreeSet treeSet = new TreeSet<>();
//1.添加元素
treeSet.add("java");
treeSet.add("php");
treeSet.add("ui");
treeSet.add("html");
treeSet.add("world");
System.out.println("打印" + treeSet.toString());
//2.删除
treeSet.remove("h5");
System.out.println("删除之后" + treeSet.toString());
//3.遍历
System.out.println("------------------------");
Iterator it=treeSet.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
System.out.println("----------降序迭代器-----------");
Iterator dit=treeSet.descendingIterator();
while (dit.hasNext()){
System.out.println(dit.next());
}
} (2)通过继承comparable接口或者创建set时提供的Comparator(自创一个比较器)进行排序
public static void main(String[] args) {
//TreeSet treeSet = new TreeSet<>();
TreeSet treeSet=new TreeSet<>(new Comparator() {
@Override
public int compare(Student o1, Student o2) {
int n1=o1.getName().compareTo(o2.getName());
int n2=o1.getAge()-o2.getAge();
return n1==0?n2:n1;
}
});
Student s1=new Student("Jack",20);
Student s2=new Student("Milk",17);
Student s3=new Student("Jack",50);
Student s4=new Student("Rose",29);
Student s5=new Student("Tom",30);
//1.添加元素
treeSet.add(s1);
treeSet.add(s2);
treeSet.add(s3);
treeSet.add(s4);
treeSet.add(s5);
System.out.println("元素个数:"+treeSet.size());
System.out.println(treeSet.toString());
//2.删除
treeSet.remove(new Student("Jack",50));
System.out.println("删除之后"+treeSet);
//3.遍历
System.out.println("------------------");
Iterator iterator = treeSet.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//判断
System.out.println(treeSet.contains(new Student("Jack",20)));
}