java基础进阶篇(四)------HashMap
文章目录
- 一.前言
- 二.特点和常见问题
- 二.接口定义
- 三.初始化构造函数
- 1.HashMap();
- 2.HashMap(int initialCapacity);
- 3.HashMap(int initialCapacity, float loadFactor);
- 四.HashMap内部结构
- 五.HashMap的存储分析
- 六.HashMap的读取分析
- 七.常用方法
- 1.put(K key, V value)
- 2.putAll(Map m)
- 2.get(Object key)
- 3.size()
- 4.clear()
- 5.isEmpty ()
- 6.remove(Object key)
- 7.values()
- 8.keySet()
- 9.containsKey(Object key)
- 10.containsValue(Object value)
- 八.HashMap 的java8 新特性
- 1.特性
- 2.V replace(K key, V value)
- 3.boolean replace(key, oldValue, newValue)
- 4.void replaceAll(function)
- 5.putIfAbsent(key, value)
- 6.getOrDefault
- 7.merge
- 8.compute()
- 9.compute() 的补充方法
- 1) computeIfAbsent()
- 2) computeIfPresent()
一.前言
HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在。在HashMap中,key-value总是会当做一个整体来处理,系统会根据hash算法来来计算key-value的存储位置,我们总是可以通过key快速地存、取value。
二.特点和常见问题
- 非线程安全
- hashMap的映射不是有序的
- key、value都可以为null
- key 不能重复
二.接口定义
查看源码. HashMap实现了Map接口,继承AbstractMap。
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
三.初始化构造函数
HashMap提供了三个构造函数:
1.HashMap();
构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
* 一个空的构造方法,默认初始化容量16,负载因子0.75
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
负载因子: loadFactor是map的负载因子,要大于0,且是非无穷大的数字.
有这样一个公式:initailCapacity*loadFactor=HashMap的容量.
比如,泛型是String,String 类型的空的HashMap.(泛型: 集合内元素的类型)
HashMap map1 = new HashMap<String,String>();
2.HashMap(int initialCapacity);
构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
比如初始一个容量为5的hashMap集合.
HashMap map2 = new HashMap<String,String>(5);
System.out.println(map2.size());// 输出0, 此时数组容量为5, 但内部元素为0.
3.HashMap(int initialCapacity, float loadFactor);
构造一个带指定初始容量和加载因子的空 HashMap。
默认负载因子是0.75, HashMap提供可修改的负载因子的构造方法.
HashMap map2 = new HashMap<String,String>(5,0.5f);
四.HashMap内部结构
数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式),在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
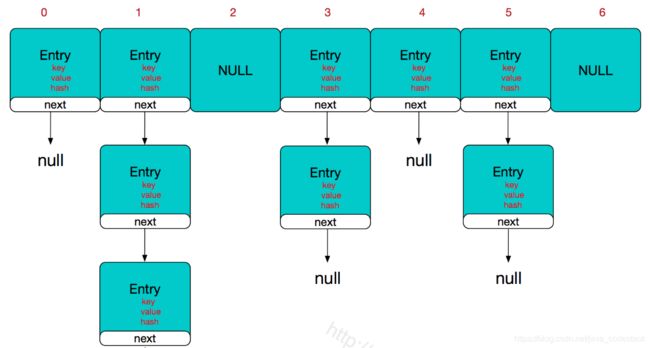
简单概括主干是数组, 每个数组元素内容部是链表.
源码如下:
public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能<0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: "
+ initialCapacity);
//初始容量不能 > 最大容量值,HashMap的最大容量值为2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//负载因子不能 < 0
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: "
+ loadFactor);
// 计算出大于 initialCapacity 的最小的 2 的 n 次方值。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
//设置HashMap的容量极限,当HashMap的容量达到该极限时就会进行扩容操作
threshold = (int) (capacity * loadFactor);
//初始化table数组
table = new Entry[capacity];
init();
}
从源码中可以看出,每次新建一个HashMap时,都会初始化一个table数组。table数组的元素为Entry节点。
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
.......
}
其中Entry为HashMap的内部类,它包含了键key、值value、下一个节点next,以及hash值,这是非常重要的,正是由于Entry才构成了table数组的项为链表。
随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
五.HashMap的存储分析
源码如下:
public V put(K key, V value) {
//当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
if (key == null)
return putForNullKey(value);
//计算key的hash值
int hash = hash(key.hashCode()); ------(1)
//计算key hash 值在 table 数组中的位置
int i = indexFor(hash, table.length); ------(2)
//从i出开始迭代 e,找到 key 保存的位置
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//判断该条链上是否有hash值相同的(key相同)
//若存在相同,则直接覆盖value,返回旧value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value; //旧值 = 新值
e.value = value;
e.recordAccess(this);
return oldValue; //返回旧值
}
}
//修改次数增加1
modCount++;
//将key、value添加至i位置处
addEntry(hash, key, value, i);
return null;
}
分析下源码中保存数据的过程为:
首先判断key是否为null,若为null,则直接调用putForNullKey方法。
若不为空则先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。
若table在该处没有元素,则直接保存。
HashMap中不存在相同的Key, 先看迭代处。此处迭代原因就是为了防止存在相同的key值,若发现两个hash值(key)相同时,HashMap的处理方式是用新value替换旧value,这里并没有处理key,这就解释了HashMap中没有两个相同的key。
再来分析下添加一个新key-value 的内部实现:
void addEntry(int hash, K key, V value, int bucketIndex) {
//获取bucketIndex处的Entry
Entry<K, V> e = table[bucketIndex];
//将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
//若HashMap中元素的个数超过极限了,则容量扩大两倍
if (size++ >= threshold)
resize(2 * table.length);
}
这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了
六.HashMap的读取分析
相对于HashMap的存而言,取就显得比较简单了。通过key的hash值找到在table数组中的索引处的Entry,然后返回该key对应的value即可。
public V get(Object key) {
// 若为null,调用getForNullKey方法返回相对应的value
if (key == null)
return getForNullKey();
// 根据该 key 的 hashCode 值计算它的 hash 码
int hash = hash(key.hashCode());
// 取出 table 数组中指定索引处的值
for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
//若搜索的key与查找的key相同,则返回相对应的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
能够根据key快速的取到value除了和HashMap的数据结构密不可分外,还和Entry有莫大的关系,在前面就提到过,HashMap在存储过程中并没有将key,value分开来存储,而是当做一个整体key-value来处理的,这个整体就是Entry对象。同时value也只相当于key的附属而已。在存储的过程中,系统根据key的hashcode来决定Entry在table数组中的存储位置,在取的过程中同样根据key的hashcode取出相对应的Entry对象。
七.常用方法
1.put(K key, V value)
将键(key)/值(value)映射存放到Map集合中。若key已经存在,则更新替换掉旧值.
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("key1", "val01");
map1.put("key2", "val02");
System.out.println(map1.get("key1"));
System.out.println(map1.get("b"));
map1.put("key1", "updated");
System.out.println(map1.get("key1"));
输出结果
val01
null
updated
2.putAll(Map m)
合并集合,把参数集合中的元素合并到原来集合中, 若参数集合中的key 与原来集合中有重复, 则更新覆盖原来集合对应key 的value.
// 两个map具有不同的key
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "A");
HashMap<String, String> map2 = new HashMap<String, String>();
map2.put("2", "B");
map2.put("3", "C");
map1.putAll(map2);
System.out.println(map1);
// 两个map具有重复的key
HashMap<String, String> map3 = new HashMap<String, String>();
map3.put("1", "A");
HashMap<String, String> map4 = new HashMap<String, String>();
map4.put("1", "B");
map4.put("3", "C");
map3.putAll(map4);
System.out.println(map3);
输出结果:
{1=A, 2=B, 3=C}
{1=B, 3=C}
2.get(Object key)
返回指定键所映射的值,没有该key对应的值则返回 null。
HashMap<String,String> map2=new HashMap<String,String>();
map2.put("key1","val01");
map2.put("key2", "val02");
System.out.println(map2.get("key1"));
System.out.println(map2.get("key2"));
输出结果:
val01
val02
3.size()
返回Map集合中数据数量。
HashMap<String,String> map2=new HashMap<String,String>();
map2.put("key1","val01");
map2.put("key2", "val02");
System.out.println(map2.size());
输出结果:
2
4.clear()
清空Map集合
HashMap<String,String> map3=new HashMap<String,String>();
map3.put("key1","val01");
map3.put("key2", "val02");
System.out.println(map3.size());
map3.clear();
System.out.println(map3.size());
输出结果:
2
0
5.isEmpty ()
判断Map集合中是否有数据,如果没有则返回true,否则返回false; 观察源码,仅判断元素个数是否为0, 不能判断null.
public boolean isEmpty() {
return size == 0;
}
6.remove(Object key)
删除Map集合中键为key的数据并返回其所对应value值。
HashMap<String,String> map4=new HashMap<String,String>();
map4.put("key1","val01");
map4.put("key2", "val02");
System.out.println(map4.remove("key1"));
System.out.println(map4.size());
输出结果:
val01
1
7.values()
返回Map集合中所有value组成的以Collection数据类型格式数据。
HashMap<String,String> map4=new HashMap<String,String>();
map4.put("key1","val01");
map4.put("key2", "val02");
System.out.println(map4.values());
输出结果:
[val01, val02]
8.keySet()
返回Map集合中所有key组成的Set集合
HashMap<String,String> map4=new HashMap<String,String>();
map4.put("key1","val01");
map4.put("key2", "val02");
System.out.println(map4.keySet());
输出结果:
[key1, key2]
9.containsKey(Object key)
判断集合中是否包含指定键,包含返回 true,否则返回false.
HashMap<String,String> map4=new HashMap<String,String>();
map4.put("key1","val01");
map4.put("key2", "val02");
System.out.println(map4.containsKey("key1"));
System.out.println(map4.containsKey("key3"));
输出结果:
true
false
10.containsValue(Object value)
判断集合中是否包含指定值,包含返回 true,否则返回false。
HashMap<String,String> map4=new HashMap<String,String>();
map4.put("key1","val01");
map4.put("key2", "val02");
System.out.println(map4.containsValue("val01"));
System.out.println(map4.containsValue("val03"));
输出结果:
true
false
八.HashMap 的java8 新特性
1.特性
-
非线程安全
-
hashMap的映射不是有序的
-
key、value都可以为null
HashMap<String, String> map1 = new HashMap<String, String>(); map1.put(null, null); System.out.println(map1);
输出结果:
{null=null}
2.V replace(K key, V value)
替换指定key 的value, 并返回替换前的value.
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "a");
map1.put("2", "b");
map1.put("3", "c");
System.out.println(map1);
System.out.println(map1.replace("1", "aReplace"));
System.out.println(map1);
输出结果
{1=a, 2=b, 3=c}
a
3.boolean replace(key, oldValue, newValue)
用newValue 替换指定key 的oldValue; 当key 不存在 | 对应key的value 和oldValue 不相等 则返回false;
源码如下:
@Override
public boolean replace(K key, V oldValue, V newValue) {
Node<K,V> e; V v;
if ((e = getNode(hash(key), key)) != null &&
((v = e.value) == oldValue || (v != null && v.equals(oldValue)))) {
e.value = newValue;
afterNodeAccess(e);
return true;
}
return false;
}
例子:
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "a");
map1.put("2", "b");
map1.put("3", "c");
// key 不存在
System.out.println(map1.replace("4", "bb", "newValue"));
// 参数oldValue 和对应key 的值不相等
System.out.println(map1.replace("2", "bb", "newValue"));
System.out.println(map1);
// 条件满足
System.out.println(map1.replace("2", "b", "newValue"));
System.out.println(map1);
输出结果:
false
false
{1=a, 2=b, 3=c}
true
{1=a, 2=newValue, 3=c}
4.void replaceAll(function)
function, java8的流式写法, 个人感觉个replaceAll 没一毛钱关系, function由我们自定义的.
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "a");
map1.put("2", "b");
map1.put("3", "c");
map1.replaceAll((k,v) -> {
System.out.println(k);
System.out.println(v);
return null;
});
(k,v) k v 对应HashMap 中的key 和value. 内部是一次遍历操作.
输出结果:
1a2b3c
5.putIfAbsent(key, value)
如果传入的key 已经存在, 则返回存在key 的value, 不进行更新替换value;
如果传入的key 不存在, 则和put 作用相同, 添加新的key 和value; 并且固定返回null;
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "a");
map1.put("2", "b");
map1.put("3", "c");
System.out.println("执行前: " + map1);
// 1.key不存在
System.out.println(map1.putIfAbsent("4", "d"));
// 2.key存在, value不同
System.out.println(map1.putIfAbsent("1", "aa"));
System.out.println("执行后: " + map1);
输出结果:
执行前: {1=a, 2=b, 3=c}
null
a
执行后: {1=a, 2=b, 3=c, 4=d}
6.getOrDefault
作用是根据传入的key 获取value; 若Map 中没有这个key 则返回指定的defaultValue; 若有,则相当于get方法.
源码如下, 内部采用三元运算符进行判断key 是否存在决定返回的value.
@Override
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? defaultValue : e.value;
}
比如:
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "a");
map1.put("2", "b");
map1.put("3", "c");
System.out.println(map1.getOrDefault("4", "d"));
System.out.println(map1.getOrDefault("1", "a"));
输出结果:
d
a
7.merge
如果key存在,则执行lambda表达式,并将表达式的值更新到对应的key 中. 表达式入参为oldVal和newVal(neVal即merge()的第二个参数)。表达式返回最终put的val。如果key不存在,则直接putnewVal.
比如:
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "a");
map1.put("2", "b");
map1.put("3", "c");
String retVal = map1.merge("1", "A", (oldVal, newVal) -> oldVal + newVal);
System.out.println(retVal);
System.out.println(map1);
输出结果:
aA
{1=aA, 2=b, 3=c}
作用等同于下段代码(JDK1.7以前版本)
if(map.containsKey(k)) {
map.put(k, map.get(k) + newVal);
} else {
map.put(k, newVal);
}
源码如下, 解释见注释部分.
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
// 删除无关代码
int hash = hash(key);
Node<K,V>[] tab; Node<K,V> first; int n, i;
int binCount = 0;
TreeNode<K,V> t = null;
Node<K,V> old = null; // 该key原来的节点对象
if (size > threshold || (tab = table) == null ||
(n = tab.length) == 0) //第一个if,判断是否需要扩容
n = (tab = resize()).length;
if ((first = tab[i = (n - 1) & hash]) != null) {
// 第二个if,取出old Node对象
// 继续省略
}
if (old != null) {// 第三个if,如果 old Node 存在
V v;
if (old.value != null)
// 如果old存在,执行lambda,算出新的val并写入old Node后返回。
v = remappingFunction.apply(old.value, value);
else
v = value;
if (v != null) {
old.value = v;
afterNodeAccess(old);
}
else
removeNode(hash, key, null, false, true);
return v;
}
if (value != null) {
//如果old不存在且传入的newVal不为null,则put新的kv
if (t != null)
t.putTreeVal(this, tab, hash, key, value);
else {
tab[i] = newNode(hash, key, value, first);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
}
// 省略
}
return value;
}
8.compute()
根据已知的 k v 算出新的v并put。如果无此key,那么oldVal为null,lambda中涉及到oldVal的计算会报空指针。源码和merge大同小异,就不放了。
HashMap<String, String> map1 = new HashMap<String, String>();
map1.put("1", "a");
map1.put("2", "b");
map1.put("3", "c");
String retVal = map1.compute("1", (key, oldVal) -> oldVal + "AAA");
System.out.println(retVal);
System.out.println(map1);
输出结果:
aAAA
{1=aAAA, 2=b, 3=c}
和merge 方法相比, 功能类似, 区别在于传入的参数不同;
9.compute() 的补充方法
1) computeIfAbsent()
当key不存在时,才compute[见8]. 类似compute ,故偷个懒不作例子了
2) computeIfPresent()
当key存在时,才compute[见8].类似compute ,故偷个懒不作例子了
