浅析Okhttp3框架源码
浅析Okhttp3框架源码
- 第一部分 HTTP协议了解
- 一、HTTP协议介绍
- 二、HTTP请求方法
- 三、HTTP状态码
- 四、HTTP请求报文(请求协议)
- 五、HTTP响应报文(响应协议)
- 第二部分 Okhttp请求流程
- 一、Okhttp请求流程图
- 二、Okhttp使用源码解析
- 1、okhttp框架使用前提
- 2、简单使用方式
- 1)同步的HTTP GET方式
- 2)异步的HTTP GET方式
- 第三部分 源码剖析
- 一、OkHttpClient客户端
- 二、Request请求体
- 三、NewCall()方法
- 四、ReallCall类
- 1、同步请求方式execute()
- 1.1)Dispather类
- 2、异步请求方式enqueue(Callback callback)
- 3、getResponseWithInterceptorChain()方法
- 五、拦截器
- 1、retryAndFollowUpInterceptor
- 2、BridgeInterceptor
- 3、CacheInterceptor
- 4、ConnectInterceptor
- 5、CallServerInterceptor
- 第四部分 总结
- 参考资料
文章较长,连续阅读可能会产生疲劳效果,如果时间有限,可以按需读取。
第一部分 HTTP协议了解
在接触okhttp框架时,如果对HTTP协议不太了解,那么可以在本文章的第一部分大致了解下HTTP协议的基本体系和响应请求的流程,希望通过对协议原理的研究,能够在后续使用和加深学习okhttp框架时能够帮助理解和使用。
一、HTTP协议介绍
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。
通过http协议可以达到服务器端和客户端进行通信的目的,由客户端对服务器指定端口进行TCP连接(TCP是相对与UDP较可靠的传输方式),而服务器在端口对客户端的请求进行监听,如果收到请求消息,则会返回一个状态码,以及返回的内容,请求文件,错误消息等。

二、HTTP请求方法
在HTTP中定义了一共8种请求方式来对资源进行访问,其中包括访问方式如下:
| 请求标识 | 标识解释 |
|---|---|
| GET | 向指定的资源发出“显示”请求。 |
| HEAD | 进行指定资源请求,只不过服务器不传回资源的文本部分。 |
| POST | 向指定资源提交数据,请求服务器进行处理。 |
| PUT | 向指定资源位置上传其最新内容 |
| DELETE | 请求服务器删除Request-URI所标识的资源。 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| OPTIONS | 传回该资源所支持的所有HTTP请求方法。 |
| CONNECT | 用于SSL加密服务器的链接(经由非加密的HTTP代理服务器)。 |
- GET提交的数据会放在URL之后,也就是请求行里面,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456.(请求头里面那个content-type做的这种参数形式,后面讲) POST方法是把提交的数据放在HTTP包的请求体中.
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制.
三、HTTP状态码
在进行HTTP的请求时都会得到相对的响应码(也叫状态码),根据这里的状态码可以对这次的请求结果进行第一步的简要分析。
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型:
1xx消息——请求已被服务器接收,继续处理
2xx成功——请求已成功被服务器接收、理解、并接受
3xx重定向——需要后续操作才能完成这一请求
4xx请求错误——请求含有词法错误或者无法被执行
5xx服务器错误——服务器在处理某个正确请求时发生错误

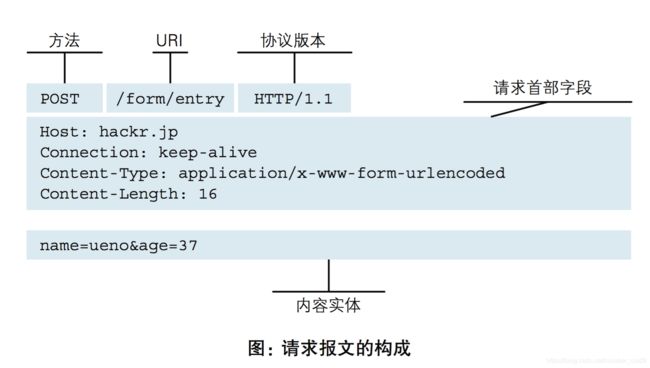
四、HTTP请求报文(请求协议)
请求行由三部分组成:请求方法,请求URI(不包括域名),HTTP协议版本
请求头部由关键字/值对组成,每行一对
Host : 请求的主机名,允许多个域名同处一个IP地址,即虚拟主机
Connection:连接方式,keepalive(告诉WEB服务器或者代理服务器,在完成本次请求的响应后,保持连接,等待本次连接的后续请求)。
Content-Type:发送端发送的实体数据的数据类型。
Content-Length:发送报文内容的长度。
五、HTTP响应报文(响应协议)
状态行也由三部分组成:服务器HTTP协议版本,响应状态码,状态码的文本描述
同样,响应头部由关键字/值对组成,每行一对
Date:表示消息发送的时间,缓存在评估响应的新鲜度时要用到,时间的描述格式由RFC822定义。
Content-Type:响应端发送的实体数据的数据类型。
Content-Length:响应报文内容的长度。

第二部分 Okhttp请求流程
在前置的http了解过后,我们终于进入了okhttp框架的了解和学习,作为目前较主流的网络请求框架,Okhttp的具体请求和响应流程是怎么样的,如何在剖析了解这些请求和响应方式就是第二部分的主要内容了。
一、Okhttp请求流程图
下图为okhttp整体请求Response时的请求流程图:

二、Okhttp使用源码解析
接下来会基于上述的一个请求流程,并依据Okhttp的简单的使用样例进行对Okhttp源码进行解析和了解,尽量达到以下目的:
1、了解Okhttp的基本使用原理。
2、认识OKhttpClient客户端和Request请求体。
3、明白Dispather调度流程。
4、同步和异步请求的流程方式。
1、okhttp框架使用前提
和大部分框架一样,在进行okhttp使用前,需要将okhttp的依赖包进行
导入,如下所示:
implementation 'com.squareup.okhttp3:okhttp:3.10.0'
目前最新版为4.72版本,因为其中的源码采用Kotlin进行编译,为了友好的阅读体验,且二者之间的核心处理流程并没有太大改变后面采用以3.10.0的Java版本作为主要源码剖析版本。其中对于最新的okhttp的地址可以在该Okhttp框架官方链接中进行查看
因为本身属于网络请求,使用在使用时需要在清单文件中添加能够访问网络的权限:
<uses-permission android:name="android.permission.INTERNET"/>
Tips:其中在Android高版本中,如果对不安全的网络地址进行访问可能会产生无法进行非安全链接访问的问题,可以通过尝试如下两种方式解决:
1、将url的链接修改为安全连接,https(http+ssl加密)等
2、在AndroidMainfest中添加以下内容:
android:networkSecurityConfig="@xml/network_security_config"
进行安全配置,其中引用的xml文件配置如下:
<?xml version="1.0" encoding="utf-8"?>
<network-security-config>
<base-config cleartextTrafficPermitted="true" />
</network-security-config>
2、简单使用方式
在接下来对Okhttp框架源码解析之前,会以下面两个例子作为样例讲诉,二者以同步和异步方式作为主要区别。
1)同步的HTTP GET方式
如下需要注意的是,目前主流的链接为https链接,即为在http基础上进行了ssl证书认证,如果直接进行http请求头开始访问的话,会出现401访问错误。
private void SyncHttpGet(){
new Thread(new Runnable() {//因为网络请求都需要在子线程进行,这里新建一个线程
@Override
public void run() {
try {
String urlBaidu = "https://www.baidu.com/";
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build();
// 创建一个请求体,在请求体中可以设置url,method,body和head,默认method为Get
Response response = okHttpClient.newCall(request).execute(); // 返回实体
if (response.isSuccessful()) { // 判断是否成功(code为2XX)
/**获取返回的数据,可通过response.body().string()获取,默认返回的是utf-8格式;
* string()适用于获取小数据信息,如果返回的数据超过1M,建议使用stream()获取返回的数据,
* 因为string() 方法会将整个文档加载到内存中。*/
System.out.println(response.body().string()); // 打印数据
}else {
System.out.println("Wrong"); // 链接失败
}
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
2)异步的HTTP GET方式
在异步访问中,因为自身会建立一个新的线程,所以这里我们不需要再在一个新的线程里进行网络请求(耗时操作)的处理
private void AsyncHttpGet() {
String urlBaidu = "https://www.baidu.com/";
OkHttpClient okHttpClient = new OkHttpClient(); // 创建OkHttpClient对象
Request request = new Request.Builder().url(urlBaidu).build(); // 创建一个请求
okHttpClient.newCall(request).enqueue(new Callback() { // 回调
public void onResponse(Call call, Response response) throws IOException {
// 请求成功调用,该回调在子线程
System.out.println(response.body().string());
}
public void onFailure(Call call, IOException e) {
// 请求失败调用
System.out.println(e.getMessage());
}
});
}
第三部分 源码剖析
一、OkHttpClient客户端
依据请求流程可知,在使用时,都会在最开始创建一个OkhttpClient对象,这相当于网络请求的客户端,用来和服务器进行连接。下面我们来看下OkhttpClient的源码部分。
下面为初始代码块,在初始代码块中会对一些基本变量的声明和默认协议的配置,协议配置如下:
public class OkHttpClient implements Cloneable, Call.Factory, WebSocket.Factory {
static final List<Protocol> DEFAULT_PROTOCOLS = Util.immutableList(
Protocol.HTTP_2, Protocol.HTTP_1_1);//默认使用Http1.1和Http2协议
static final List<ConnectionSpec> DEFAULT_CONNECTION_SPECS = Util.immutableList(
ConnectionSpec.MODERN_TLS, ConnectionSpec.CLEARTEXT);
//默认情况下,OkHttp将尝试一个moderni_tls连接
......(此处省略)
}
在进行变量声明时,会执行Builder方法,在Builder方法中,利用建造者模式,快速构建一个OkhttpClient客户端所需求的变量内容。
public OkHttpClient() {
this(new Builder());//执行下面的方法,进行初始话构建
}
OkHttpClient(Builder builder) {
this.dispatcher = builder.dispatcher;//调度器,执行请求时的策略
this.proxy = builder.proxy;//代理端口
this.protocols = builder.protocols;//设置OkHttpClient使用的协议,默认为HTTP/2和HTTP/1.1
this.connectionSpecs = builder.connectionSpecs;//TLS版本与连接协议
this.interceptors = Util.immutableList(builder.interceptors);//设置自定义拦截器
this.networkInterceptors = Util.immutableList(builder.networkInterceptors);//设置网络拦截器
this.eventListenerFactory = builder.eventListenerFactory;//设置事件监听器,在请求时的一个流程事件的监听,包括callStrart,dnsStart,dnsEnd等等
this.proxySelector = builder.proxySelector;//设置代理选择策略
this.cookieJar = builder.cookieJar;//设置Cookie处理器,用于从HTTP响应中接收Cookie,并且可以将Cookie提供给即将发起的请求
this.cache = builder.cache;//设置缓存的路径和缓存空间大小,用于读取和写入已缓存的响应信息Response
this.internalCache = builder.internalCache;//设置缓存策略的拦截器
this.socketFactory = builder.socketFactory;//套接字工厂设置,对应http协议
boolean isTLS = false;
for (ConnectionSpec spec : connectionSpecs) {
isTLS = isTLS || spec.isTls();
}//设置是否采用TLS(安全传输层协议,用于在两个通信应用程序之间提供保密性和数据完整性。)
if (builder.sslSocketFactory != null || !isTLS) {
this.sslSocketFactory = builder.sslSocketFactory;//套接字工厂设置,对应https协议
this.certificateChainCleaner = builder.certificateChainCleaner;
} else {
X509TrustManager trustManager = systemDefaultTrustManager();
this.sslSocketFactory = systemDefaultSslSocketFactory(trustManager);
this.certificateChainCleaner = CertificateChainCleaner.get(trustManager);
}
this.hostnameVerifier = builder.hostnameVerifier;//主机名验证
this.certificatePinner = builder.certificatePinner.withCertificateChainCleaner(
certificateChainCleaner);//设置固定证书
this.proxyAuthenticator = builder.proxyAuthenticator;
this.authenticator = builder.authenticator;
this.connectionPool = builder.connectionPool;
this.dns = builder.dns;
this.followSslRedirects = builder.followSslRedirects;//设置是否允许HTTP与HTTPS请求之间互相重定向,默认为true允许
this.followRedirects = builder.followRedirects;//设置是否允许请求重定向,默认为true允许;
this.retryOnConnectionFailure = builder.retryOnConnectionFailure;//重连错误
this.connectTimeout = builder.connectTimeout;//设置连接建立的超时时间
this.readTimeout = builder.readTimeout;//设置读数据的超时时间
this.writeTimeout = builder.writeTimeout;//设置写数据的超时时间
this.pingInterval = builder.pingInterval;//ping命令的间隔执行时间
if (interceptors.contains(null)) {
throw new IllegalStateException("Null interceptor: " + interceptors);
}//拦截器是否为空
if (networkInterceptors.contains(null)) {
throw new IllegalStateException("Null network interceptor: " + networkInterceptors);
}//网络拦截器是否为空
}
二、Request请求体
Request请求体作为客户端的信件的载体,其内可以设置请求的方式(GET,POST,HEAD,PUT等八种请求方式),将这个请求体加载到Okhttp的newCall方法内进行call请求,最后得到Reponse响应体,总而言之,在Okhttp中request更像是从客户端发送出去的邮件,邮递员也就是互联网将邮件内容(body),请求方式(method)和请求格式(head)发送给对应的服务器(url),至于响应接收就是Reponse的事了。
接下来,我们来看看Request请求体的Builder源码内容:
public static class Builder {
HttpUrl url;//url链接
String method;//请求方式
Headers.Builder headers;//请求头部,也就是所谓的带参请求
RequestBody body;//请求体,主要内容
Object tag;//用来标识请求
public Builder() {
this.method = "GET";
this.headers = new Headers.Builder();
}//默认的请求方式为GET
Builder(Request request) {
this.url = request.url;
this.method = request.method;
this.body = request.body;
this.tag = request.tag;
this.headers = request.headers.newBuilder();
}//进行这些基本变量的设置
三、NewCall()方法
在Okhttp中通过NewCall()的方法放回ReallCall对象,再在ReallCall对象中进行对同步异步请求的处理。如下为Request的newCall方法,很明显就能发现是继承了Call类,返回的RealCall的一个方法。
@Override public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}
四、ReallCall类
在上述方法的newRealCall(如下所示)中可以发现,其实返回的已经是继承了Call类的ReallCall类,这里进行了一个实例化操作和给call添加了一个事件监听器。
其中ReallCall类在网络请求上的操作,更像是整体请求的最后一步的封装,用来进行异步同步请求,取消请求,拦截器链表创建操作。
private RealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket) {
this.client = client;
this.originalRequest = originalRequest;// 最初的Request
this.forWebSocket = forWebSocket;//是否支持websocket通信
this.retryAndFollowUpInterceptor = new RetryAndFollowUpInterceptor(client, forWebSocket);
}
static RealCall newRealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket) {
// Safely publish the Call instance to the EventListener.
RealCall call = new RealCall(client, originalRequest, forWebSocket);//实例化了一个Reallcall类
call.eventListener = client.eventListenerFactory().create(call);//添加了事件监听器
return call;
}
1、同步请求方式execute()
在同步请求时首先会通过captureCallStackTrace()对调用栈的跟踪捕获,具体作用是给重定向设置一个callStackTrace也就是回溯信息,具体作用这里就不赘述了,同时事件监听器也同时执行callStart方法,这里的CalStart可以自己复写达到输出监听启动CAll流程的效果。
@Override public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();//捕获调用堆栈跟踪
eventListener.callStart(this);//CallStart回调
try {
client.dispatcher().executed(this);//此处请求将进入Dispatcher对象内做相应的调度处理
Response result = getResponseWithInterceptorChain();//返回拦截器的责任链
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
client.dispatcher().finished(this);
}
}
1.1)Dispather类
在之后client会使用调度器dispather()执行异步的请求策略,这里的dispather()方法是返回一个Dispather实例,这个实例在外面构建OkhttpClient的时候其实就已经有了默认构造,dispather()的方法源码如下:
public Dispatcher dispatcher() {
return dispatcher;
}
那么Dispather的作用又是什么呢?其实在整体流程中,Dispther的作用正如它的名字一样,是用来进行一个请求测试的分配调度,这里可能是异步的,也可能是同步的,而异步和同步的调度原理和方式就在Dispather这个类中可以详细看到。
首先在Dispather构建开始,也就是初始化时,会默认设置一下参数,这里参数包括请求数和接口的设置,同时定义了两个双端队列(Deque),一个是异步队列,一个是同步队列,在异步队列中有准备请求的队列和正在运行的队列,这是为了防止同时运行请求的异步线程过多导致内存异常等错误,而同步请求的队列只有一个进行处理。
Deque即双端队列。是一种具有队列和栈的性质的数据结构。双端队列中的元素可以从两端弹出,相比list增加[]运算符重载。
Dispather源码如下:
public final class Dispatcher {
private int maxRequests = 64; //默认同时执行的最大请求数, 可以通过setMaxRequests(int)修改.
private int maxRequestsPerHost = 5;//每个主机默认请求的最大数目, 可以通过setMaxRequestsPerHost(int)修改.
private @Nullable Runnable idleCallback;//调度没有请求任务时的回调.
/** Executes calls. Created lazily. */
//执行异步请求的线程池,默认是 核心线程为0,最大线程数为Integer.MAX_VALUE,空闲等待为60s.
private @Nullable ExecutorService executorService;
/** Ready async calls in the order they'll be run. */
private final Deque<AsyncCall> readyAsyncCalls = new ArrayDeque<>();//异步请求的执行顺序的队列.
/** Running asynchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<AsyncCall> runningAsyncCalls = new ArrayDeque<>();//运行中的异步请求队列.
/** Running synchronous calls. Includes canceled calls that haven't finished yet. */
private final Deque<RealCall> runningSyncCalls = new ArrayDeque<>();//运行中的同步请求队列.
********此处省略
}
如果没有通过构造方法Dispatcher(ExecutorService executorService) 设置线程池的话,默认就是 核心线程为0,最大线程数为Integer.MAX_VALUE,空闲等待为60s,用SynchronousQueue保存等待任务的线程池。
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
而在该类中的同步请求方法executed()如下所示,是在运行队列中添加call准备处理,当然,会利用synchronized保证添加过程中的线程安全。那么到此为止的话就是在同步中添加到队列的一个过程。
/** Used by {@code Call#execute} to signal it is in-flight. */
synchronized void executed(RealCall call) {
runningSyncCalls.add(call);
}
而对加载到这个队列的call,如果在RellCall内捕获到IO的异常(详情看上面的ReallCall类说明),那么最后会通过如下的finised方法进行任务的结束请求(call)。
/** Used by {@code Call#execute} to signal completion. */
void finished(RealCall call) {
finished(runningSyncCalls, call, false);//传入runningSyncCalls进行执行
}
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
if (promoteCalls) promoteCalls();//这里是异步请求时的算法判断
runningCallsCount = runningCallsCount();//统计所有的call数量
idleCallback = this.idleCallback;
}
2、异步请求方式enqueue(Callback callback)
和同步请求最主要的不同的是异步请求在最后调用的是enqueue的方法。
@Override public void enqueue(Callback responseCallback) {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
client.dispatcher().enqueue(new AsyncCall(responseCallback));//调用enqueue方法
}
通过传进来的callback封装了AsyncCall这个对象,这个对象其实就是一个Runnable,在构建了一个Runnable,AsyncCall之后就直接调用了dispatcher().enqueue这个方法,并将前面创建好的AsyncCall传到这个方法当中。
final class AsyncCall extends NamedRunnable {
private final Callback responseCallback;
AsyncCall(Callback responseCallback) {
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
}
String host() {
return originalRequest.url().host();
}
Request request() {
return originalRequest;
}
RealCall get() {
return RealCall.this;
}
@Override protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();//拦截器责任链返回
if (retryAndFollowUpInterceptor.isCanceled()) {//查看重定向拦截器是否被取消
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {//最后也是进行finished()
client.dispatcher().finished(this);
}
}
}
在enqueue方法中,会对当前的请求数和运行队列中异步请求数量的一个判断,依此来决定该请求是存放在运行队列还是准备队列。
synchronized void enqueue(AsyncCall call) {
if (runningAsyncCalls.size() < maxRequests && runningCallsForHost(call) < maxRequestsPerHost) {
runningAsyncCalls.add(call);//运行队列添加
executorService().execute(call);//通过executorService提交该请求
} else {
readyAsyncCalls.add(call);//准备队列添加
}
}
因为异步请求的特殊性,会在最后的finish()中(详见上述AsnycCall),对这些请求队列进行一个判断和处理,如果运行队列有空,那么就可以将等待队列中的一些请求移到运行队列内,是异步请求双队列转化方式的主要逻辑。
private void promoteCalls() {
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
// 超过可以同时运行的最大请求任务数
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
//获取等待中的任务队列
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
if (runningCallsForHost(call) < maxRequestsPerHost) {
i.remove();
runningAsyncCalls.add(call);
executorService().execute(call);
}//对异步请求方式的处理,从准备队列移到运行队列
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
// 超过同一主机同时运行的最大请求任务数
}
}
3、getResponseWithInterceptorChain()方法
那么无论是同步还是异步方法,都在代码中不约而同的调用了getResponseWithInterceptorChain()方法来返回Response对象,这个方法是在请求分发后都会进行的,首先是将一些拦截器依次加入,包括用户自定义的,框架已经搭建好的,最后通过责任链的返回模式得到最终的响应体,也就是我们这的Response。
责任链处理模式如下:

责任链模式是一个请求有多个对象来处理,这些对象是一条链,但具体由哪个对象来处理,根据条件判断来确定,如果不能处理会传递给该链中的下一个对象,直到有对象处理它为止。
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());//用户自定义的拦截器
interceptors.add(retryAndFollowUpInterceptor);//失败之后自动重链和重定向
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//数据转换,将用户设置的Request转换成网络请求所需要的请求,传到下一个拦截器中,并将下一个拦截器返回的结果转换成RealResponseBody返回给上一个拦截器。
interceptors.add(new CacheInterceptor(client.internalCache()));
//缓存,读取缓存直接返回和更新缓存,并将其下一个拦截器返回的结果返回给上一个拦截器。
interceptors.add(new ConnectInterceptor(client));
//创建一个链接,并将其下一个拦截器返回的结果返回给上一个拦截器
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
//网络拦截器,可用于查询用于连接到网络服务器的IP地址和TLS配置。
}
interceptors.add(new CallServerInterceptor(forWebSocket));
//向服务器请求数据,完成请求,并返回给上一个拦截器。
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
//最后将这些拦截器都传入到RealInterceptorChain,通过chain.proceed()来完成整个请求过程。而这些拦截器中采用的是责任链模式,一个拦截器会去调用下一个拦截器的intercept()或.proceed()来完成最后的请求。
return chain.proceed(originalRequest);
}
具体的责任链的剖析在下述代码,会在最后执行的proceed中将传入的拦截器形成一个个链条,调用下一个拦截器,获取Response,通过对得到的Response进行处理,并将其返回给上一个拦截器。
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException {
if (index >= interceptors.size()) throw new AssertionError();
calls++;
// If we already have a stream, confirm that the incoming request will use it.
if (this.httpCodec != null && !this.connection.supportsUrl(request.url())) {
throw new IllegalStateException("network interceptor " + interceptors.get(index - 1)
+ " must retain the same host and port");
}
// If we already have a stream, confirm that this is the only call to chain.proceed().
if (this.httpCodec != null && calls > 1) {
throw new IllegalStateException("network interceptor " + interceptors.get(index - 1)
+ " must call proceed() exactly once");
}
// Call the next interceptor in the chain.
//核心方法实现 就是创建下一个拦截器链
// 要访问的话,只能从下一个拦截器访问,不能从当前拦截器访问,这就形成了一个拦截器链
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
Interceptor interceptor = interceptors.get(index);
// 根据index获取拦截器
Response response = interceptor.intercept(next);
//再把上面获取到的拦截器链,当做参数传进去,这样就形成了所有拦截器的链条
// Confirm that the next interceptor made its required call to chain.proceed().
if (httpCodec != null && index + 1 < interceptors.size() && next.calls != 1) {
throw new IllegalStateException("network interceptor " + interceptor
+ " must call proceed() exactly once");
}
// Confirm that the intercepted response isn't null.
if (response == null) {
throw new NullPointerException("interceptor " + interceptor + " returned null");
}
if (response.body() == null) {
throw new IllegalStateException(
"interceptor " + interceptor + " returned a response with no body");
}//对响应体为空的判断
return response;
}
五、拦截器
拦截器是OkHttp中提供的一种机制,它可以实现网络监听、请求以及响应重写、请求失败重试,填充头部信息等功能。将request进行完善,最终得到满足需求的一个Response。
整个流程就是OkHttp通过定义许多拦截器一步一步地对Request进行拦截处理(从头至尾),直到请求返回网络数据,后面又倒过来,一步一步地对Response进行拦截处理,最后拦截的结果就是回调给调用者的最终Response。(从尾至头)

1、retryAndFollowUpInterceptor
在重定向中,主要作用是负责请求的重定向操作,用于处理网络请求中,请求失败后的重试机制。首先,会根据客户端请求Request以及OkHttpClient,创建出StreamAllocation,它主要用于管理客户端与服务器之间的连接,同时管理连接池,以及请求成功后的连接释放等操作,在执行StreamAllocation创建时,可以看到根据客户端请求的地址url,还调用了createAddress方法。
进入该方法可以看出,这里返回了一个创建成功的Address,实际上Address就是将客户端请求的网络地址,以及服务器的相关信息,进行了统一的包装,也就是将客户端请求的数据,转换为OkHttp框架中所定义的服务器规范,这样一来,OkHttp框架就可以根据这个规范来与服务器之间进行请求分发了。
// 拦截进行重定向
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Call call = realChain.call();
EventListener eventListener = realChain.eventListener();
// 建立创建Http请求的一些网络组建
StreamAllocation streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(request.url()), call, eventListener, callStackTrace);
this.streamAllocation = streamAllocation;
int followUpCount = 0; // 重定向次数,其中MAX_FOLLOW_UPS默认为20次
Response priorResponse = null;
// 将前一步得到的followUp 赋值给request,重新进入循环
while (true) {
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response;
boolean releaseConnection = true;
try {
// proceed 内部会实现下一个拦截器链的方法 这个在上一篇已经分析过了
// 将前一步得到的followUp不为空进入循环 继续执行下一步 followUp就是request
// 继续执行下一个Interceptor,即BridgeInterceptor
// 进行重定向进行新的请求
response = realChain.proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
// The attempt to connect via a route failed. The request will not have been sent.
// 尝试通过路由进行连接失败,该请求不会被发送
if (!recover(e.getLastConnectException(), streamAllocation, false, request)) {
throw e.getLastConnectException();
}
releaseConnection = false;
continue;
} catch (IOException e) {
// An attempt to communicate with a server failed. The request may have been sent.
boolean requestSendStarted = !(e instanceof ConnectionShutdownException);
if (!recover(e, streamAllocation, requestSendStarted, request)) throw e;
releaseConnection = false;
continue;
} finally {
// We're throwing an unchecked exception. Release any resources.
// 检测到其他未知异常,则释放连接和资源
if (releaseConnection) {
streamAllocation.streamFailed(null);
streamAllocation.release();
}
}
// Attach the prior response if it exists. Such responses never have a body.
// 构建响应体,这个响应体的body为空
if (priorResponse != null) {
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder()
.body(null)
.build())
.build();
}
Request followUp = followUpRequest(response, streamAllocation.route());
// followUp 就是followUpRequest方法经过检测返回的Request
if (followUp == null) {
if (!forWebSocket) {//是否为WebSocket协议,是的话就释放这个网络组件对象
streamAllocation.release();
}
return response;// 如果Request为空 则return response;
}
// 当网络请求失败后,会在这个拦截其中重新发起
closeQuietly(response.body());
if (++followUpCount > MAX_FOLLOW_UPS) {
streamAllocation.release();// 当超过次数的时候这里就会释放这个网络组件对象
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
if (followUp.body() instanceof UnrepeatableRequestBody) {
streamAllocation.release();
throw new HttpRetryException("Cannot retry streamed HTTP body", response.code());
}
if (!sameConnection(response, followUp.url())) {
streamAllocation.release();
streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(followUp.url()), call, eventListener, callStackTrace);
this.streamAllocation = streamAllocation;
} else if (streamAllocation.codec() != null) {
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
}
request = followUp;// 把重定向的请求赋值给request,以便再次进入循环执行
priorResponse = response;
}
}
其中重定向功能默认是开启的,可以选择关闭,然后去实现自己的重定向功能
new OkHttpClient.Builder()
.followRedirects(false) //禁制OkHttp的重定向操作,我们自己处理重定向
.followSslRedirects(false)//https的重定向也自己处理
2、BridgeInterceptor
在桥拦截器中可以明显的发现,在这个拦截器中对request和response进行了一个合理有效的规范,这个规范包括将请求添加上一些必要的请求格式,比如内容类型,将这些必需的请求进行内部的封装,这样就可以在对Request进行简单的设置就能达到请求规范的原则,同理,将Response进行规范可用化也是桥拦截器重要的功能。
其中在Gzip解压部分,当 transparentGzip 为 true ,表示请求设置的 Accept-Encoding 是 支持gzip 压缩的,意思就是告知服务器客户端是支持 gzip 压缩的,然后再判断服务器的响应头 Content-Encoding 是否也是 GZIP 压缩的,意思就是响应体内容是否是经过 GZIP 压缩的,如果都成立的条件下,那么它会将 Resposonse.body().source() 的输入流 BufferedSource 转化为 GzipSource 类型,这样的目的就是让调用者在使用 Response.body().string() 获取响应内容时就是以解压的方式进行读取流数据。
Gzip是用于UNⅨ系统的文件压缩。我们在Linux中经常会用到后缀为.gz的文件,它们就是GZIP格式的。现今已经成为Internet 上使用非常普遍的一种数据压缩格式,或者说一种文件格式。
@Override public Response intercept(Chain chain) throws IOException {
Request userRequest = chain.request();
Request.Builder requestBuilder = userRequest.newBuilder();
RequestBody body = userRequest.body();
//对请求头的补充
if (body != null) {
MediaType contentType = body.contentType();
if (contentType != null) {
requestBuilder.header("Content-Type", contentType.toString());
}
//定义网络文件的类型和网页的编码,如果未指定 ContentType,默认为[TEXT]/[HTML]
long contentLength = body.contentLength();
if (contentLength != -1) {
requestBuilder.header("Content-Length", Long.toString(contentLength));
//表示的是请求体内容的长度。
requestBuilder.removeHeader("Transfer-Encoding");
} else {
requestBuilder.header("Transfer-Encoding", "chunked");
//Transfer-Encoding值为 chunked 表示请求体的内容大小是未知的
requestBuilder.removeHeader("Content-Length");
}
}
if (userRequest.header("Host") == null) {
requestBuilder.header("Host", hostHeader(userRequest.url(), false));
}
//Host 请求的 url 的主机
if (userRequest.header("Connection") == null) {
requestBuilder.header("Connection", "Keep-Alive");
}
//Connection 默认就是 "Keep-Alive",就是一个 TCP 连接之后不会关闭,保持连接状态。
// If we add an "Accept-Encoding: gzip" header field we're responsible for also decompressing
// the transfer stream.
//默认是 GZIP 压缩的
//Accept-Encoding : 就是告诉服务器客户端能够接受的数据编码类型,OKHTTP 默认就是 GZIP 类型。
boolean transparentGzip = false;
if (userRequest.header("Accept-Encoding") == null && userRequest.header("Range") == null) {
//标记请求支持 GZIP 压缩
transparentGzip = true;
requestBuilder.header("Accept-Encoding", "gzip");
}
//Accept-Encoding 默认是 "gzip" 告诉服务器客户端支持 gzip 编码的响应
//cookie 头的添加
List<Cookie> cookies = cookieJar.loadForRequest(userRequest.url());
if (!cookies.isEmpty()) {
requestBuilder.header("Cookie", cookieHeader(cookies));
}
//Cookie 当请求设置了 Cookie 那么就是添加 Cookie 这个请求头。
if (userRequest.header("User-Agent") == null) {
requestBuilder.header("User-Agent", Version.userAgent());
}
//User-Agent "okhttp/3.4.1" 这个值根据 OKHTTP 的版本不一样而不一样,它表示客户端 的信息。
//发送网络请求
Response networkResponse = chain.proceed(requestBuilder.build());
HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers());
Response.Builder responseBuilder = networkResponse.newBuilder()
.request(userRequest);
if (transparentGzip
&& "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding"))
&& HttpHeaders.hasBody(networkResponse)) {
//当服务器返回的数据是 GZIP 压缩的,那么客户端就有责任去进行解压操作
GzipSource responseBody = new GzipSource(networkResponse.body().source());
//转为GzipSource类行,对返回的response进行解压
Headers strippedHeaders = networkResponse.headers().newBuilder()
.removeAll("Content-Encoding")
.removeAll("Content-Length")
.build();
//移除请求头Content-Encoding和Content-Length
responseBuilder.headers(strippedHeaders);
String contentType = networkResponse.header("Content-Type");
responseBuilder.body(new RealResponseBody(contentType, -1L, Okio.buffer(responseBody)));
}
return responseBuilder.build();
}
3、CacheInterceptor
首先介绍下http缓存,在http缓存中,目前分为两种,一种强制缓存,一种对比缓存,强制缓存生效时直接使用以前的请求结果,无需发起网络请求。对比缓存生效时,无论怎样都会发起网络请求,如果请求结果未改变,服务端会返回304,但不会返回数据,数据从缓存中取,如果改变了会返回数据。
Tips:对方法是POST,PATCH,PUT,DELETE,MOVE的请求,将缓存清除掉,这些是不应该被缓存的。然后明确了一点,只有GET方法才会被缓存。而真正的缓存写入到文件是通过一个叫Entry的辅助类来的。具体源码可以自行查看CacheRequest的put方法。
@Override public Response intercept(Chain chain) throws IOException {
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
CacheStrategy strategy = new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
//CacheStrategy,就是由它来决定采用何种缓存规则的。okhttp为每一个请求都记录了一个Strategy。
//所谓的决定策略,其实就是决定是否要重新发起网络请求
//包括:没有对应的缓存结果;https请求却没有握手信息;不允许缓存的请求(包括一些特殊状态码以及Header中明确禁止缓存)。
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
if (cache != null) {
cache.trackResponse(strategy);
}
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
// If we're forbidden from using the network and the cache is insufficient, fail.
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
//这种情况说明从缓存策略上来说强制缓存生效,应该直接取上次缓存结果,但由于未知原因缓存的结果没有了或者上次返回就没有,这里直接返回了失败的Response
// If we don't need the network, we're done.
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
//这种情况下,强制缓存生效,这里对Response的cacheResponse的body做了置空处理。
Response networkResponse = null;
try {
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
//强制缓存不生效,说明此时应该使用对比缓存,需要从服务端取数据
// If we have a cache response too, then we're doing a conditional get.
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
//按照对比缓存规则,取完之后应该判断是否返回304,如果是应该使用缓存结果
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
//剩下的情况就是缓存完全失效了,这个时候应该利用刚才网络请求的结果
if (cache != null) {
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response, networkRequest)) {
// Offer this request to the cache.
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
if (HttpMethod.invalidatesCache(networkRequest.method())) {
try {
cache.remove(networkRequest);
} catch (IOException ignored) {
// The cache cannot be written.
}
}
}
return response;
}
4、ConnectInterceptor
ConnectInterceptor拦截器的主要作用是用来打开与服务器的连接connection,正式开启了网络请求,而这里的连接也主要是通过连接池获取的。然后将连接传入到下一个拦截器中。
@Override public Response intercept(Chain chain) throws IOException {
//从拦截器链里得到StreamAllocation对象
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
////通过streamAllocation ,newStream,这个里面会创建连接等一系列的操作
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
//获取realConnetion
RealConnection connection = streamAllocation.connection();
//执行下一个拦截器,也就是最后一个拦截器
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
在上述源码中会发现多了一个StreamAllocation类,这个类其实在第一次调用拦截器的时候就创建了,在里面会传入三个参数,连接池(connectionPool()),地址类(request.url()),调用堆栈跟踪相关(callStackTrace)
streamAllocation = new StreamAllocation(
client.connectionPool(), createAddress(request.url()), callStackTrace);
在StreamAllocation构造函数中,主要是把这个三个参数保存为内部变量,供后面使用,还有一个就是同时创建了一个线路选择器,让后面可以进行线路选择。
this.routeSelector = new RouteSelector(address, routeDatabase());
之后在newStream中会通过findHealthyConnection()方法获得一个健康可用的连接,而这里的连接如果进行深入了解会发现是存在于RealConnection线程池的一个连接(具体方法在findHealthyConnection-> RealConnection findConnection源码中可以查看)
public HttpCodec newStream(
OkHttpClient client, Interceptor.Chain chain, boolean doExtensiveHealthChecks) {
int connectTimeout = chain.connectTimeoutMillis();//获取设置的连接超时时间
int readTimeout = chain.readTimeoutMillis();//读写超时的时间
int writeTimeout = chain.writeTimeoutMillis();
int pingIntervalMillis = client.pingIntervalMillis();//ping命令间隔时间
boolean connectionRetryEnabled = client.retryOnConnectionFailure();//否进行重连
try {
// 获取健康可用的连接
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, pingIntervalMillis, connectionRetryEnabled, doExtensiveHealthChecks);
//通过resultConnection初始化,对请求以及结果 编解码的类(分http 1.1 和http 2.0)
// 这里主要是初始化,在后面一个拦截器才用到这相关的东西。
HttpCodec resultCodec = resultConnection.newCodec(client, chain, this);
synchronized (connectionPool) {
codec = resultCodec;
return resultCodec;
}
} catch (IOException e) {
throw new RouteException(e);
}
}
5、CallServerInterceptor
其实在进行CallServerInterceptor拦截器之前还有一个网络拦截器networkInterceptors,这个是可以通过我们自定义进行实现以下功能的,包括
1、能操作中间响应,例如重定向和重试。
2、发生网络短路的缓存响应时,不被调用。
3、观察将通过网络传输的数据。
4、可以获取到携带请求的connection
那么作为最后一个拦截器,CallServerInterceptor的主要作用就是向服务器发送请求,最终返回response。其中在该拦截器中的HttpCodec对象中的source、Sink对象是来对向服务器发送和接收状态行或实体内容,进行些状态码判断、从而完成对Response对象的构建,再返回到上一级拦截器做处理。
其执行流程如下:
1、获取request、httpCodec等对象。
2、通过httpCodec发送状态行和头部数据到服务端。
3、判断是否是有请求实体的请求,如果是,判断当前是否有设置Expect: 100-continue请求头。
4、往流中写入请求实体内容。
5、读取服务器返回的头部信息、状态码等,构建responseBuilder对象并返回。
6、通过responseBuilder对象来构建response对象。
7、判断当前状态码,如果是100,则重新请求一次,得到response对象。
8、给Response对象设置body。
9、判断是否需要断开连接。
@Override public Response intercept(Chain chain) throws IOException {
// 获取对象
RealInterceptorChain realChain = (RealInterceptorChain) chain;
HttpCodec httpCodec = realChain.httpStream();
StreamAllocation streamAllocation = realChain.streamAllocation();
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
long sentRequestMillis = System.currentTimeMillis();
// 发送状态行和头部数据到服务端
realChain.eventListener().requestHeadersStart(realChain.call());
httpCodec.writeRequestHeaders(request);
realChain.eventListener().requestHeadersEnd(realChain.call(), request);
Response.Builder responseBuilder = null;
// 判断是否有请求实体的请求(不是GET请求)
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) {
// If there's a "Expect: 100-continue" header on the request, wait for a "HTTP/1.1 100
// Continue" response before transmitting the request body. If we don't get that, return
// what we did get (such as a 4xx response) without ever transmitting the request body.
// 如果头部信息添加了"Expect: 100-continue",这个请求头字段的作用是在发送RequestBody前向服务器确认是否接受RequestBody,如果服务器不接受也就没有发送的必要了。
// 有这个字段,相当于一次简单的握手操作,会等待拿到服务器返回的ResponseHeaders之后再继续,如果服务器接收RequestBody,会返回null。
if ("100-continue".equalsIgnoreCase(request.header("Expect"))) {
httpCodec.flushRequest();
realChain.eventListener().responseHeadersStart(realChain.call());
// 服务器返回
responseBuilder = httpCodec.readResponseHeaders(true);
}
// 服务器同意接收,开始向流中写入RequestBody
if (responseBuilder == null) {
// Write the request body if the "Expect: 100-continue" expectation was met.
realChain.eventListener().requestBodyStart(realChain.call());
long contentLength = request.body().contentLength();
CountingSink requestBodyOut =
new CountingSink(httpCodec.createRequestBody(request, contentLength));
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
// 向流写入数据
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
realChain.eventListener()
.requestBodyEnd(realChain.call(), requestBodyOut.successfulCount);
} else if (!connection.isMultiplexed()) {
// If the "Expect: 100-continue" expectation wasn't met, prevent the HTTP/1 connection
// from being reused. Otherwise we're still obligated to transmit the request body to
// leave the connection in a consistent state.
streamAllocation.noNewStreams();
}
}
//httpCpdec完成请求
httpCodec.finishRequest();
// 读取头部信息、状态码等
if (responseBuilder == null) {
realChain.eventListener().responseHeadersStart(realChain.call());
responseBuilder = httpCodec.readResponseHeaders(false);
}
// 构建Response, 写入原请求,握手情况,请求时间,得到的响应时间
Response response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
// 返回的状态码
int code = response.code();
if (code == 100) {
//如果状态码为100,那就再请求一次
// server sent a 100-continue even though we did not request one.
// try again to read the actual response
responseBuilder = httpCodec.readResponseHeaders(false);
response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
code = response.code();
}
realChain.eventListener()
.responseHeadersEnd(realChain.call(), response);
if (forWebSocket && code == 101) {
// Connection is upgrading, but we need to ensure interceptors see a non-null response body.
// 如果状态码为101,设置一个空的Body
response = response.newBuilder()
.body(Util.EMPTY_RESPONSE)
.build();
} else {
// 读取Body信息
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
}
// 如果设置了连接关闭,则断开连接
if ("close".equalsIgnoreCase(response.request().header("Connection"))
|| "close".equalsIgnoreCase(response.header("Connection"))) {
streamAllocation.noNewStreams();
}
//HTTP 204(no content) 代表响应报文中包含若干首部和一个状态行,但是没有实体的主体内容。
//HTTP 205(reset content) 表示响应执行成功,重置页面(Form表单),方便用户下次输入
//这里做了同样的处理,就是抛出协议异常。
if ((code == 204 || code == 205) && response.body().contentLength() > 0) {
throw new ProtocolException(
"HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
}
return response;
}
第四部分 总结
那么到此为止其实已经完成了对repose响应体的一个获取,本篇文章的主要内容是用于对框架源码的原理进行浅要的分析,通过框架的一个使用流程我们进行跟踪式的访问解析,当然因为只是浅要分析,所以在较深层的源码结构中,文章内部只是一笔带过,有兴趣的可以自行了解。
参考资料
OkHttp之Dispatcher
https://blog.csdn.net/lxk_1993/article/details/101449342
OkHttp之getResponseWithInterceptorChain
https://blog.csdn.net/nihaomabmt/article/details/88187205
OkHttp拦截器链源码解读
https://www.jianshu.com/p/1181f48d6dcf
OKhttp源码解析详解系列
https://www.jianshu.com/p/d98be38a6d3f
OkHttp3
https://www.jianshu.com/p/0acb2d787125
_JW的拦截器分析系列
https://blog.csdn.net/qq_21612413/article/details/88356726
OkHttp框架的RetryAndFollowUpInterceptor请求重定向源码解析
https://blog.csdn.net/qq_15274383/article/details/73729801
HTTP协议超级详解
https://www.cnblogs.com/an-wen/p/11180076.html