数据是如何请求的(网络抓包)
引言
抓包(Packet Capture)就是对网络传输中发送与接收的数据包进行截获、重发、编辑、转存等操作。
在开发网络爬虫中,给定 URL,开发者必须知道数据是怎么向服务器发送请求的,以及请求后服务器返回的数据是什么。只有知道这些,开发者才能在程序中提交 URL,获取到后台所返回的数据,进而解析想要的字段内容。所以说,抓包分析是爬虫必不可少的技能之一,也是爬虫开发的起点。举个简单的案例,爬取京东某一商品的评论数据,则需要该商品的地址:https://item.jd.com/3749095.html。我们在浏览器上打开该地址发现存在商品评论内容。如下图所示:
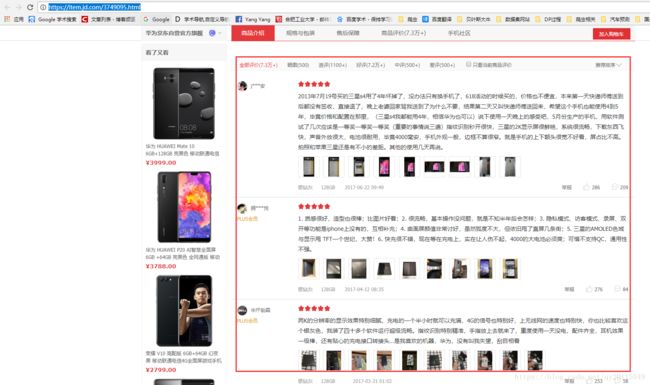
但在编写网络爬虫时,发现直接请求该地址获取的 HTML 内容中,却不存在该评论的信息。这就是不抓包直接开发网络爬虫,可能导致的后果。实际上,通过网络抓包,便很容易能够发现,后台返回评论的地址并不是该地址(https://item.jd.com/3749095.html),而是其他地址,读者可以在浏览器中打开如下地址,便可以发现评论数据的内容。
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv15201&productId=3749095&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
抓包分析
网络抓包涉及到 HTTP 方面的内容,为此首先介绍下 HTTP。
什么是 HTTP
HTTP 协议(Hyper Text Transfer Protocol,超文本传输协议)是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。该协议是 Web 系统最核心的内容,是 Web 服务器和客户端(浏览器)之间进行传输的规则,而网络爬虫实际上是通过模拟浏览器的方式获取服务器数据。
通过 HTTP 协议传递的内容包括 HTML 文件、图片、视频以及其他查询数据。其工作流程如下:
- 建立链接,通过 URL 的方式。
- 浏览器向服务器发送请求,通常请求的方法有 POST 以及 GET。
- 服务器接收到浏览器的 HTTP 请求后,将返回应答,并向浏览器发送数据。这一阶段涉及到和数据库的交互,从服务器的数据库抽取数据。具体返回的内容包括:状态码(基于状态码可以判断响应状态)、头信息、正文(如 HTML 文件、JSON 文件等)。
- 释放链接。


关于响应状态码,我已在第二课中介绍过了。在此介绍一下请求头信息包括的内容。例如,下面的内容是我请求百度获得的请求头信息:
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9
Cache-Control:max-age=0
Connection:keep-alive
Cookie:xxxxxxxx(这里 Cookie:xxxxxxxx太长,我就去掉了)
Host:www.baidu.com
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36
在下表中,我例举了这些请求头的含义:
| 请求头 | 说明 |
|---|---|
| Accept | 浏览器可以接受的媒体类型(MIME),如 text/html 代表可以接受 HTML 文档, *代表接受任何类型。 |
| Accept-Encoding | 浏览器声明自己接受的编码方法,通常指定压缩方法 ,是否支持压缩,支持什么格式的压缩 。 |
| Accept-Language | 浏览器可接受的语言,zh-CN,zh;q=0.9 表示浏览器支持的语言分别是中文和简体中文,优先支持简体中文。 |
| Cache-Control | 指定请求和响应遵循的缓存机制。 |
| Connection | 表示是否需要持久连接,HTTP 1.1 默认进行持久连接。 |
| Cookie | HTTP 请求发送时,会把保存在该请求域名下的所有 Cookie 值一起发送给 Web 服务器。 |
| Host | 指定请求的服务器的域名和端口号。 |
| Upgrade-Insecure-Requests | 浏览器自动升级请求(HTTP 和 HTTPS 之间)。 |
| User-Agent | 用户代理,是一个特殊字符串头,使得服务器能够识别客户端使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。 |
基于浏览器实现抓包实战
多数浏览器,都可以用来抓包。在此,以谷歌浏览器为例进行实战操作,请求的页面是新浪的新闻搜索。按照如下操作便可完成抓包分析.
1. 在浏览器上点击鼠标右键,点击检查。

2. 点击上图中的 Network,并在 Network 中勾选 Preserve log(即保存日志)。

3. 在该网页的搜索框中填入想要搜索的关键字,例如“金融”,并点击搜索按钮。可以看到页面进行了跳转,并产生一系列的响应内容。
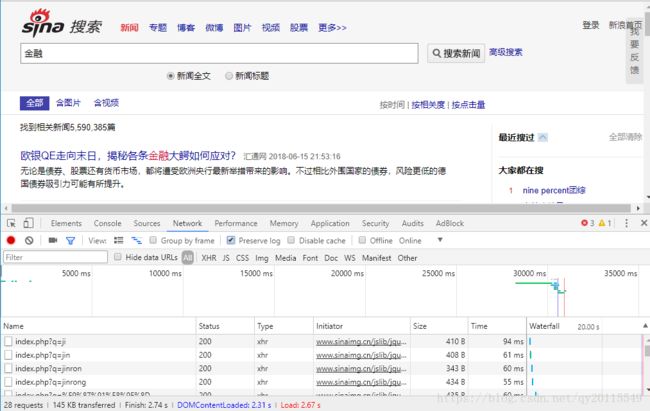
4. 找到我们想要数据(新闻标题,新闻地址等)对应的日志。从这里我们便可以看到真实的请求地址、请求的方式、头信息等内容。
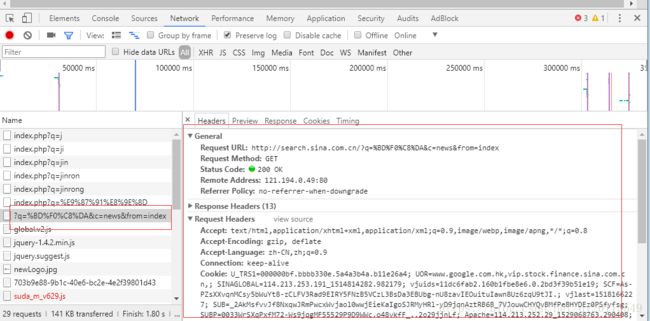
可以看到搜索金融(对金融进行了编码 %BD%F0%C8%DA),真实向后台发送请求的地址为:
Request URL:http://search.sina.com.cn/?q=%BD%F0%C8%DA&c=news&from=index
5. 点击 Response 便可以看到响应的内容(HTML、JSON、XML 等)。针对不同的内容,在 Java 中可以选用不同的工具进行数据的解析操作。

抓包使用情境
编写网络爬虫的起点都是网络抓包,但对很多初学者而言,由于其不了解抓包,而直接去请求一个 URL (如引言介绍的京东案例),进而可能导致无法找到自己所要的数据。在此,我对抓包的使用情境做以下说明:
- 当直接请求 URL 能够获得数据时,可以不用进行抓包,直接使用程序请求数据并解析数据;
- 直接用程序请求 URL 无法找到所要数据时,需要进行网络抓包分析;
- 存在表单请求的,需要进行网络抓包,例如需要登录之后才能获取的数据(需要输入用户名和密码);
- 需要在程序中,输入头信息等内容的,需要网络抓包分析。例如一些网站设置了防爬措施,通过在程序中加载抓包获取的头信息,可以将爬虫更好地伪装成浏览器,这种方法往往可以躲避简单的防爬策略。
其他抓包工具的推荐
-
Fiddler:常用的抓包工具之一,能够记录客户端和服务器之间的所有 HTTP/HTTPS 请求,可以针对特定的 HTTP/HTTPS 请求,分析请求数据、设置断点、调试 Web 应用、修改请求的数据,甚至可以修改服务器返回的数据。具体使用方法,读者可以参考博文《Fiddler 的详细介绍》 。
-
Wireshark:一款非常强大的抓包工具,可以截取各种网络封包,显示网络封包的详细信息。但在处理 HTTP/HTTPS,基本的浏览器抓包或 Fiddler 抓包就够了,如果处理 ARP/TCP/UDP/CIMP 时,使用 Wireshark。
-
Postman:是 Google 开发的一款功能强大的网页调试与发送网页 HTTP/HTTPS 请求,并能运行测试用例工具(既有谷歌插件又有桌面软件)。在 Postman 中输入浏览器抓包的内容,便可以模拟请求。我主要使用此工具测试需要表单请求的页面(例如需要登录获取数据的页面)。

参考内容
- HTTP 响应头和请求头信息对照表
- HTTP 技术文档
- 《Wireshark 数据包分析实战详解》一书