利用python编写爬虫程序,从招聘网站上爬取数据,将数据存入到MongoDB数据库中,将存入的数据作一定的数据清洗后做数据分析,最后将分析的结果做数据可视化
教程演示
- 创建爬虫项目
- 编写需要爬取的字段(items.py)
- 编写spider文件(wuyou.py)
- 编写数据库连接(pipelines.py)
- 编写反爬措施(settings.py)
- MongoDB数据库的安装
- 软件下载
- 数据测试
- 本人已经爬取了一部分数据,分享出来供大家测试
- 配置Linux环境
- 在这里本人使用的资源都会发布出来
- 为了方便大家的测试,配置好的虚拟机我也会分享出来
- 启动Hadoop集群
- 数据储存
- 具体要求:将爬取的数据存储到hdfs上。利用flume收集日志
- 1:将mongodb数据库的爬虫数据导入出来存为csv或者txt文件
- flume配置文件
- flume启动命令
- 往监控文件夹丢入爬虫数据文件
- 查看hdfs是否存在数据
- 数据分析和可视化
- 准备
- 本地数据直接导入hdfs
- 导入到hive表里
- 启动hive远程服务
- 建表
- 建表成功
- 查看hive数据库
- 数据导入
- 查看hive数据库qianchengwuyou表
- 数据分析
- 环境关系图
- (1) 分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;
- (2) 分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
- (3) 分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;
- (4) 分析大数据相关岗位几年需求的走向趋势,并做出折线图展示出来;
- 建Hive四张表
- 在MySQL建相同结构的表
- 以上所有文件
- 数据分析和可视化代码
- 到此实训结束,感谢大家观看
- ps:推荐大家使用我的虚拟机进行测试,某些功能如远程连接hive需要特定的jar包,远程连接也要特定的jar包,sqoop也需要jar包
本次演示的是爬取前程无忧网站,因为该网站几乎不存在防爬措施,对爬虫练习十分友好
创建爬虫项目
scrapy startproject qianchengwuyou
cd qianchengwuyou
scrapy genspider wuyou jobs.51job.com
编写需要爬取的字段(items.py)
import scrapy
class QianchengwuyouItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 职位名称
Job_title = scrapy.Field()
# 薪资水平
Pay_level = scrapy.Field()
# 招聘单位
Recruitment_unit = scrapy.Field()
# 工作地点
Workplace = scrapy.Field()
# 工作经验
hands_background = scrapy.Field()
# 学历要求
Education_requirements = scrapy.Field()
# 职位信息(工作内容+任职要求+工作经验)
Career_information = scrapy.Field()
# 关键字:keyword
keyword = scrapy.Field()
# 日期
day = scrapy.Field()
编写spider文件(wuyou.py)
import scrapy
import re
from ..items import QianchengwuyouItem
class WuyouSpider(scrapy.Spider):
name = 'wuyou'
allowed_domains = ['search.51job.com','jobs.51job.com']
start_urls = ['https://search.51job.com/list/000000,000000,0000,00,3,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=1&dibiaoid=0&line=&welfare=']
# for a in range(1,800):
# print('正在爬取第' + str(a) + '页')
# url = ('https://search.51job.com/list/000000,000000,0000,00,3,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=1&dibiaoid=0&line=&welfare=')
# start_urls.append(url)
def parse(self, response):
# 获取全部招聘职位的链接
all_list = response.xpath('//*[@id="resultList"]//div[@class="el"]')
# 获取全部招聘职位下的所有行业(industry)链接
for b in all_list:
all_url = b.xpath('./p/span/a/@href').extract_first()
yield scrapy.Request(
all_url,
callback=self.parse_details
)
print(all_url)
next_url = response.xpath("//*[@id='resultList']//div[@class='p_in']//li/a[text()='下一页']/@href").extract_first()
if next_url is not None:
yield scrapy.Request(
next_url,
callback=self.parse
)
elif next_url is None:
print("爬虫结束!")
# selectors = response.xpath('//div[@class="el"]')
# for selector in selectors:
# # 详细页网址
# post = selector.xpath('./p/span/a/text()').get(default='000 ').replace('\r\n', '')
# day = selector.xpath('./span[4]/text()').get(default='000 ')
# print(post,day)
def parse_details(self, response):
# 获取详情页面数据
print("=" * 100)
print(response.url)
print("正在爬取数据!")
item = QianchengwuyouItem()
# 职位名称
item["Job_title"] = response.xpath("//div[@class='cn']/h1/text()").extract_first()
item["Job_title"] = [i.strip() for i in item["Job_title"]]
item["Job_title"] = [i for i in item["Job_title"] if len(i) > 0]
item["Job_title"] = "".join(item["Job_title"]).replace(",", ",")
# 薪资水平
item["Pay_level"] = response.xpath("//div[@class='cn']/strong/text()").extract_first()
# 招聘单位
item["Recruitment_unit"] = response.xpath("//div[@class='cn']//a[1]/text()").extract_first()
# 工作地点 + 工作经验 + 学历要求....都在//div[@class='cn']/p[2]中
item["Workplace"] = response.xpath("//div[@class='cn']/p[2]/text()[1]").get().replace('\xa0','')
# 工作经验 + 学历要求
item["hands_background"] = response.xpath("//div[@class='cn']/p[2]/text()").extract()
item["hands_background"] = [i.strip() for i in item["hands_background"]]
item["hands_background"] = [i for i in item["hands_background"] if "经验" in i]
item["hands_background"] = " ".join(item["hands_background"]).replace("\xa0", "")
if len(item["hands_background"]) == 0:
item["hands_background"] = "无"
all = response.xpath("//div[@class='cn']/p[2]/text()[2]").get().replace('\xa0','')
# 判断工作经验是否存在
if len(all) >= 4:
item["Education_requirements"] = response.xpath("//div[@class='cn']/p[2]/text()[3]").get().replace('\xa0','')
if len(item["Education_requirements"]) != 2:
item["Education_requirements"] = "无"
elif len(all) < 4:
item["Education_requirements"] = "无"
elif len(all) == 2:
item["Education_requirements"] = all
item["Career_information"] = response.xpath("//div[@class='bmsg job_msg inbox']//text()").extract()
item["Career_information"] = [i.strip() for i in item["Career_information"]]
item["Career_information"] = [i for i in item["Career_information"] if len(i) > 0]
item["Career_information"] = " ".join(item["Career_information"]).replace("\xa0","").replace(",",",")
if (item["Pay_level"]) is None:
item["Pay_level"] = "无"
# 关键字:keyword
item["keyword"] = response.xpath("//div[@class='mt10']//p//a/text()").extract()
# item["keyword"] = [i.strip() for i in item["keyword"]]
item["keyword"] = [i for i in item["keyword"] if len(i) > 0]
item["keyword"] = " ".join(item["keyword"]).replace("\xa0", "").replace(",", ",")
# 日期
item["day"] = response.xpath("//div[@class='cn']/p[2]/@title").get().replace("\xa0","")
riqi = re.findall("(\d+-\d+)发布", response.text)[0]
item["day"] = riqi
yield item
print("数据爬取成功!")
编写数据库连接(pipelines.py)
from pymongo import MongoClient
class QianchengwuyouPipeline:
def open_spider(self, spider):
self.db = MongoClient("localhost", 27017).qiancheng # 创建数据库yc
self.collection = self.db.liuli05 # 创建一个集合
def process_item(self, item, spider):
# 添加数据到jingjiren表中
self.collection.insert_one(dict(item))
return item
def close_spider(self, spider):
self.collection.close()
编写反爬措施(settings.py)
BOT_NAME = 'qianchengwuyou'
SPIDER_MODULES = ['qianchengwuyou.spiders']
NEWSPIDER_MODULE = 'qianchengwuyou.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 ' \
'Safari/537.36 Edg/83.0.478.58 '
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
FEED_EXPORT_ENCODING = 'utf-8'
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 1
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# # 启用pipeline
ITEM_PIPELINES = {
'qianchengwuyou.pipelines.QianchengwuyouPipeline':300,
}
如果运行没问题的话,mongosb数据库应该会有数据
MongoDB数据库的安装
软件下载
mongodb:链接: https://pan.baidu.com/s/1Yf_7g4kSY_wvWde78wlzpQ 提取码: f6se
安装教程
数据测试
本人已经爬取了一部分数据,分享出来供大家测试
链接: https://pan.baidu.com/s/1ymL917_etE-5Fn2HBuWHFQ 提取码: 5x5k
配置Linux环境
在这里本人使用的资源都会发布出来
集合:链接: https://pan.baidu.com/s/1KeFcPVKdlWeJHJIT6VemAg 提取码: pk3v
为了方便大家的测试,配置好的虚拟机我也会分享出来
ps:我搭建的完全分布式,共三台电脑,我发布的是主机,另外两台傀儡机大家从主机复制两份就可以了,改主机名和ip地址就可以了
链接: https://pan.baidu.com/s/1sIPW_D0JuvxfXLXJP7hNqQ 提取码: 9hdg
启动Hadoop集群
hadoop01:start-dfs.sh
hadoop02:start-yarn.sh
数据储存
具体要求:将爬取的数据存储到hdfs上。利用flume收集日志
1:将mongodb数据库的爬虫数据导入出来存为csv或者txt文件
如果是csv文件可以用python代码写
import pymongo
import csv
mongo_url = "localhost:27017"
DATABASE = "xxxxx" #数据库名称
TABLE = "xxxx" #集合名(表名)
client = pymongo.MongoClient(mongo_url)
db_des = client[DATABASE]
db_des_table = db_des[TABLE]
# newline='' 的作用是防止结果数据中出现空行,专属于python3
with open(f"{DATABASE}_{TABLE}.csv", "w", newline='',encoding="utf-8") as csvfileWriter:
writer = csv.writer(csvfileWriter)
fieldList = [
"Job_title",
"Pay_level",
"Recruitment_unit",
"Workplace",
"hands_background",
"Education_requirements",
"Career_information",
"keyword",
"day"
]
writer.writerow(fieldList)
allRecordRes = db_des_table.find()
# 写入多行数据
for record in allRecordRes:
# print(f"record = {record}")
recordValueLst = []
for field in fieldList:
if field not in record:
recordValueLst.append("None")
else:
recordValueLst.append(record[field])
try:
writer.writerow(recordValueLst)
except Exception as e:
print(f"write csv exception. e = {e}")
print("数据导出成功!")
但是为了后面用flume收集数据则txt文件比较好
txt文件可以用Navicat Premium 15导出
Navicat Premium 15破解软件
链接: https://pan.baidu.com/s/1_SA8xEemn0a5Vvp7CQ870g 提取码: 5fb9 复制这段内容后打开百度网盘手机App,操作更方便哦
flume配置文件
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
# 定义别名
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述/配置源source
a1.sources.r1.type = spooldir
# 设置监控的文件夹
# 扫描文件之后修改文件后缀
a1.sources.r1.spoolDir = /usr/qianchengwuyou
# 上传成功后显示后缀名
a1.sources.r1.fileSuffix = .COMPLETED
# 如论如何 加绝对路径的文件名 默认false
a1.sources.r1.fileHeader = true
# #忽略所有以.tmp结尾的文件,不上传
a1.sources.r1.ignorePattern = ([^ ]*\.tmp)
#开启日志长度截取标志,默认true,开启
a1.sources.tail.interceptors.i2.cutFlag = true
#最大截取字符串长度,整数,尽量控制在2M以内,单位:kb,1M=1024
a1.sources.tail.interceptors.i2.cutMax = 2048
#
# # 描述一下sink 下沉到hdfs
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /Hadoop/flume/%y-%m-%d/%H-%M/
# #上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = pachong
# #是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
# #多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
# #重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
# #是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# #积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 10
# #设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
# #多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 600
# #设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
# #文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0
# #最小冗余数
a1.sinks.k1.hdfs.minBlockReplicas = 1
# # 使用在内存中缓冲事件的通道
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#
# # 将源和接收器绑定到通道
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume启动命令
进入flume安装目录conf文件夹
flume-ng agent -c conf -f 文件名称 -n a1 &
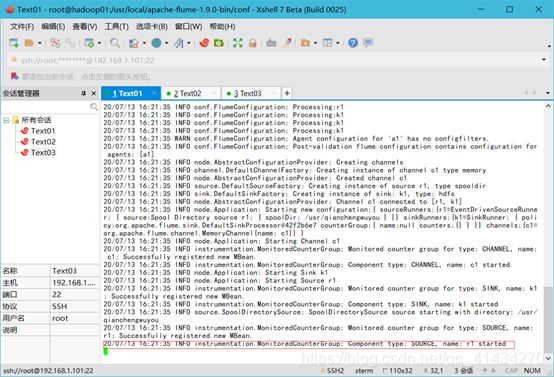
往监控文件夹丢入爬虫数据文件
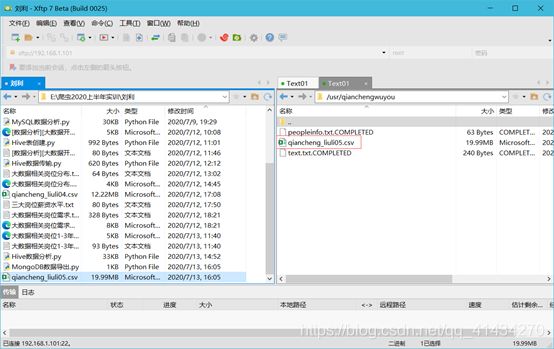
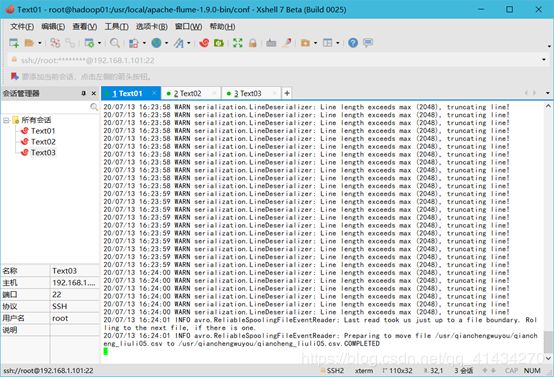
查看hdfs是否存在数据
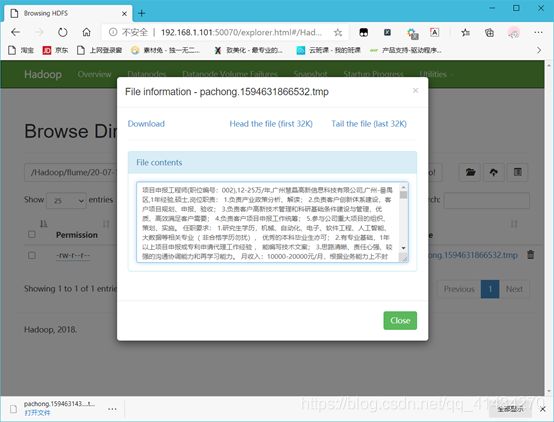
数据分析和可视化
准备
实训要求是用flume传输爬虫数据到hdfs,但是文件名会变换,由于我是用python代码连接hive进行数据分析,导入数据到hive表里也是用代码完成的,所以我是用代码将爬虫数据文件直接传输到hdfs上再导入进hive,原理都是一样的。
本地数据直接导入hdfs
from pyhdfs import HdfsClient
client = HdfsClient(hosts='192.168.1.101:50070', user_name='hadoop')
client.copy_from_local('E:\爬虫2020上半年实训\刘利\qiancheng_liuli05.csv', '/MongoDB/qiancheng_liuli05.csv') # 本地文件绝对路径,HDFS目录必须不存在
print("文件上传成功!")


导入到hive表里
启动hive远程服务
hive --service hiveserver2 &
Ps:此功能需要导入特定的jar方可开启(环境已配置好)
建表
row format delimited fields terminated by ‘,’
规定数据导入时的数据划分以”,”来划分
Tblproperties(“skip.header.line.count”=“1”
如果使用的文件格式为csv,表示跳过第一条数据,因为csv文件的第一条数据是字段名
建表成功
查看hive数据库

数据导入
from impala.dbapi import connect
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='gongjing',
database='mongodb')
try:
cursor = conn.cursor()
sql1 = 'load data inpath "/MongoDB/qiancheng_liuli05.csv" overwrite into table qianchengwuyou'
# sql2 = 'load data inpath "/MongoDB/三大岗位薪资水平.txt" overwrite into table table01'
# sql3 = 'load data inpath "/MongoDB/大数据相关岗位分布.txt" overwrite into table table02'
# sql4 = 'load data inpath "/MongoDB/大数据相关岗位1-3年工作经验薪资水平.txt" overwrite into table table03'
# sql5 = 'load data inpath "/MongoDB/大数据相关岗位需求.txt" overwrite into table table04'
cursor.execute(sql1)
# cursor.execute(sql2)
# cursor.execute(sql3)
# cursor.execute(sql4)
# cursor.execute(sql5)
# commit 修改
conn.commit()
# 关闭游标
cursor.close()
print("数据导入成功!")
except:
print("数据导入失败!")
# 发生错误时回滚
conn.rollback()

查看hive数据库qianchengwuyou表
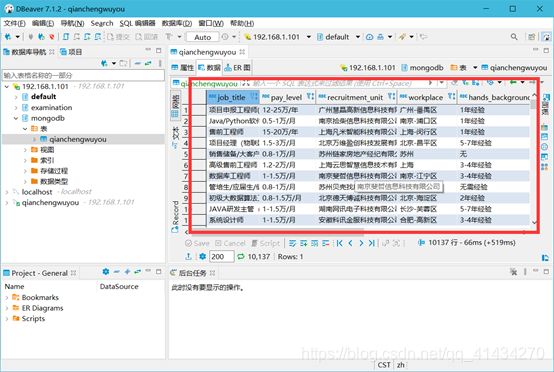
数据导入成功
数据分析
步骤1:创建四张hive表table01,table02,table03,table04用作存放分析结果
步骤2:读取qianchengwuyou表的数据进行数据分析绘图并将分析数据写入txt文件通过前面教程将四张txt文件数据分别导入四张hive表
疑问:为什么不将分析数据直接导入四张对应的表中?
回答:因为python连接hive的模块主要有两个pyhive和impyla两个,这里不推荐前者,因为pyhive模块的依赖包有一个是sasl包是python3.8不支持的而且必须还要一个c++编译器,很麻烦,impyla安装就很轻松,但是无论是哪个模块,虽然都能将数据远程导入hive表,但是很慢很慢的那种,我第一次要不是因为还能点击电脑都以为电脑死机了。
环境关系图

箭头表示数据的反向
可以看出python能读取hive数据但是不能向hive插入数据,太慢
所以我的思路就是python将分析结果保存到本地文件txt里,上传到hdfs上再导入的相应的表里
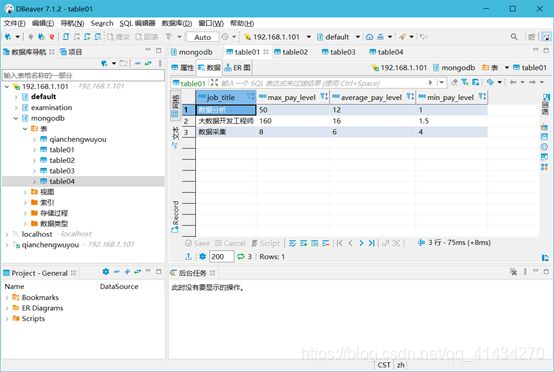
(1) 分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来;


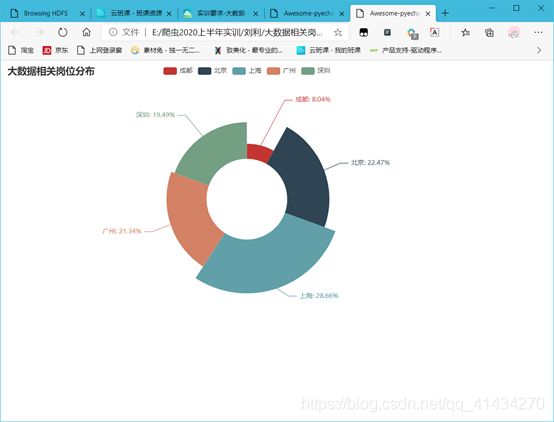
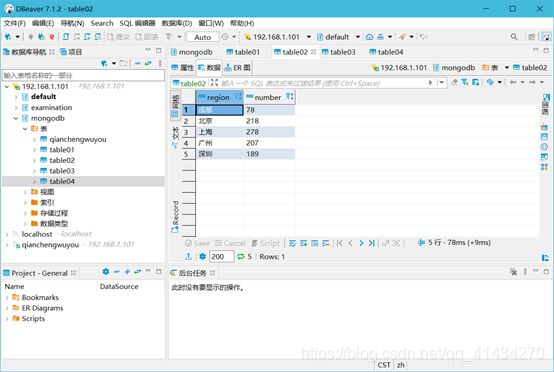
(2) 分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数,并做饼图将结果展示出来。
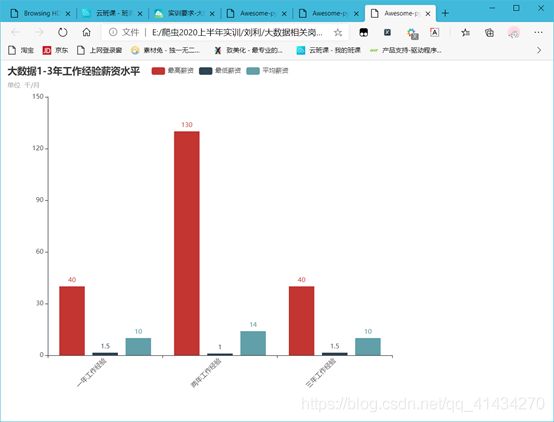
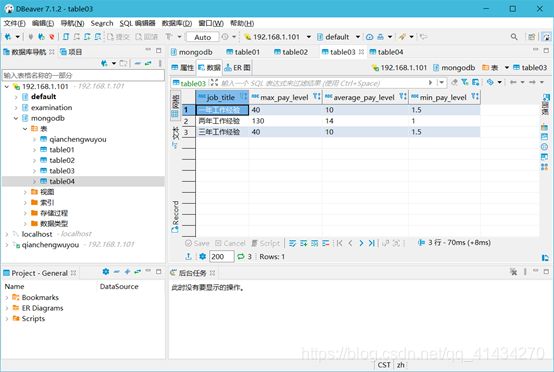
(3) 分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资),并做出条形图展示出来;

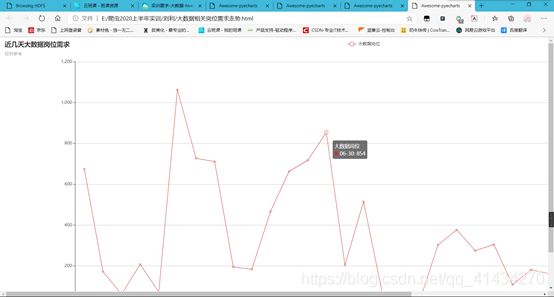
(4) 分析大数据相关岗位几年需求的走向趋势,并做出折线图展示出来;
建Hive四张表

查看数据库
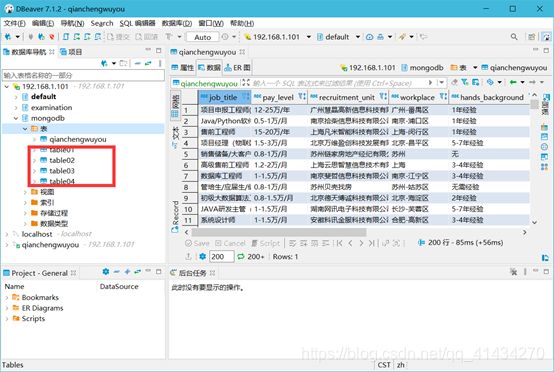
导入对应数据

在MySQL建相同结构的表
使用sqoop导入数据
启动zookeeper
zkServer.sh start
sqoop命令
sqoop export --connect jdbc:mysql://192.168.1.101:3306/qianchengwuyou --username root --password gongjing --table table01 --export-dir /usr/local/apache-hive-2.3.7-bin/warehouse/mongodb.db/table01 --input-fields-terminated-by ','
sqoop export --connect jdbc:mysql://192.168.1.101:3306/qianchengwuyou --username root --password gongjing --table table02 --export-dir /usr/local/apache-hive-2.3.7-bin/warehouse/mongodb.db/table02 --input-fields-terminated-by ','
sqoop export --connect jdbc:mysql://192.168.1.101:3306/qianchengwuyou --username root --password gongjing --table table03 --export-dir /usr/local/apache-hive-2.3.7-bin/warehouse/mongodb.db/table03 --input-fields-terminated-by ','
sqoop export --connect jdbc:mysql://192.168.1.101:3306/qianchengwuyou --username root --password gongjing --table table04 --export-dir /usr/local/apache-hive-2.3.7-bin/warehouse/mongodb.db/table04 --input-fields-terminated-by ','

以上所有文件
链接: https://pan.baidu.com/s/1n40D952JbuZ8xuHKEXSBFw 提取码: 2cd7 复制这段内容后打开百度网盘手机App,操作更方便哦
数据分析和可视化代码
import pymysql
import pymongo
import csv
import re
from pyhdfs import HdfsClient
from impala.dbapi import connect
from numpy import *
from pyecharts.charts import Bar, Pie, WordCloud,Line # bar:条形图绘制模块,pie:饼图绘制模块,wordcloud:词云图绘制模块
from pyecharts.render import make_snapshot # 绘图模块
from snapshot_phantomjs import snapshot
from pyecharts import options as opts, options
# pyecharts模块的详细使用教程和实例网址:http://pyecharts.org/#/
class HadoopDemo(object):
# 导出mongodb数据库的爬虫数据
def Data_export(self):
# 初始化数据库
mongo_url = "localhost:27017"
DATABASE = "qiancheng"
TABLE = "liuli03"
client = pymongo.MongoClient(mongo_url)
db_des = client[DATABASE]
db_des_table = db_des[TABLE]
# 将数据写入到CSV文件中
# 如果直接从mongod booster导出, 一旦有部分出现字段缺失,那么会出现结果错位的问题
# newline='' 的作用是防止结果数据中出现空行,专属于python3
with open(f"{DATABASE}_{TABLE}.csv", "w", newline='', encoding="utf-8") as csvfileWriter:
writer = csv.writer(csvfileWriter)
# 先写列名
# 写第一行,字段名
fieldList = [
"Job_title",
"Pay_level",
"Recruitment_unit",
"Workplace",
"hands_background",
"Education_requirements",
"Career_information",
"keyword",
"day"
]
writer.writerow(fieldList)
allRecordRes = db_des_table.find()
# 写入多行数据
for record in allRecordRes:
print(f"record = {record}")
recordValueLst = []
for field in fieldList:
if field not in record:
recordValueLst.append("None")
else:
recordValueLst.append(record[field])
try:
writer.writerow(recordValueLst)
except Exception as e:
print(f"write csv exception. e = {e}")
print("数据导出成功")
# client = HdfsClient(hosts='192.168.1.101:50070', user_name='hadoop')
# client.copy_from_local('E:\爬虫2020上半年实训\刘利\qiancheng_liuli05.csv', '/MongoDB/qiancheng_liuli05.csv') # 本地文件绝对路径,HDFS目录必须不存在
# print("文件上传成功!")
# 将数据导入hive表里
def Data_import(self):
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='gongjing',
database='mongodb')
cursor = conn.cursor()
sql = 'load data inpath "/MongoDB/三大岗位薪资水平.txt" overwrite into table table01'
cursor.execute(sql)
# commit 修改
conn.commit()
# 关闭游标
cursor.close()
print("数据导入成功!")
def Create_table_hive(self):
# hive数据表创建
from impala.dbapi import connect
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='gongjing',
database='mongodb')
cursor = conn.cursor()
def table(self):
print("创建qianchengwuyou表用作爬虫数据存放")
# 创建qianchengwuyou表用作爬虫数据存放
sql01 = '''create table qianchengwuyou(
Job_title varchar(100),
Pay_level varchar(100),
Recruitment_unit varchar(100),
Workplace varchar(100),
hands_background varchar(100),
Education_requirements varchar(100),
Career_information varchar(10000),
keyword varchar(1000),
day varchar(100))
row format delimited fields terminated by ','
tblproperties("skip.header.line.count"="1")'''
cursor.execute(sql01)
print("建表成功!")
def table01(self):
print("创建table01表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资")
# 创建table01表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资
sql01 = '''create table table01(
job_title varchar(100),
max_pay_level varchar(100),
average_pay_level varchar(100),
min_pay_level varchar(100))
row format delimited fields terminated by ',' '''
cursor.execute(sql01)
print("table01表建表成功!")
def table02(self):
print("创建table02表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数")
# 创建table02表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数
sql01 = '''create table table02(
region varchar(100),
number varchar(100))
row format delimited fields terminated by ',' '''
cursor.execute(sql01)
print("table02表建表成功!")
def table03(self):
print("创建table03表用作分析大数据相关岗位1 - 3年工作经验的薪资水平(平均工资、最高工资、最低工资)")
# 创建table03表用作分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资)
sql01 = '''create table table03(
hands_background varchar(100),
max_pay_level varchar(100),
average_pay_level varchar(100),
min_pay_level varchar(100))
row format delimited fields terminated by ',' '''
cursor.execute(sql01)
print("table03表建表成功!")
def table04(self):
print("创建table04表用作分析大数据相关岗位几年需求的走向趋势")
# 创建table04表用作分析大数据相关岗位近几天需求的走向趋势
sql01 = '''create table table04(
data varchar(100),
number varchar(100))
row format delimited fields terminated by ',' '''
cursor.execute(sql01)
print("table04表建表成功!")
# table(self)
# table01(self)
# table02(self)
table03(self)
# table04(self)
# commit 修改
conn.commit()
# 关闭游标
cursor.close()
def Create_table_mysql(self):
print("连接MySQL数据库创建hive对应表")
# 连接数据库
conn = pymysql.connect(
host='192.168.1.101', # 主机名
port=3306, # 端口号(默认的)
user='root', # 用户名
passwd='gongjing', # 密码
db='qianchengwuyou', # 数据库名
charset='utf8', # 这里设置编码是为了输出中文
)
cursor = conn.cursor()
def table01(self):
print("创建table01表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的最高工资、平均工资、最低工资")
# 创建table01表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资
sql01 = '''create table table01(
job_title varchar(100),
max_pay_level varchar(100),
average_pay_level varchar(100),
min_pay_level varchar(100))'''
cursor.execute(sql01)
print("table01表建表成功!")
def table02(self):
print("创建table02表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数")
# 创建table02表用作分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数
sql01 = '''create table table02(
region varchar(100),
number varchar(100))'''
cursor.execute(sql01)
print("table02表建表成功!")
def table03(self):
print("创建table03表用作分析大数据相关岗位1 - 3年工作经验的薪资水平(最高工资、平均工资、最低工资)")
# 创建table03表用作分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资)
sql01 = '''create table table03(
hands_background varchar(100),
max_pay_level varchar(100),
average_pay_level varchar(100),
min_pay_level varchar(100))'''
cursor.execute(sql01)
print("table03表建表成功!")
def table04(self):
print("创建table04表用作分析大数据相关岗位几年需求的走向趋势")
# 创建table04表用作分析大数据相关岗位近几天需求的走向趋势
sql01 = '''create table table04(
data varchar(100),
number varchar(100))'''
cursor.execute(sql01)
print("table04表建表成功!")
# commit 修改
table01(self)
table02(self)
table03(self)
table04(self)
conn.commit()
# 关闭游标
cursor.close()
print(" ")
def Pay_level01(self):
# 分析“数据分析”、“大数据开发工程师”、“数据采集”等岗位的平均工资、最高工资、最低工资,并作条形图将结果展示出来
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='gongjing',
database='mongodb')
cursor = conn.cursor()
# 最低工资
all_min_salary_list = []
# 最高工资
all_max_salary_list = []
# 平均工资
all_average_salary_list = []
# 岗位c
all_addr_list = []
# 求出数据分析相关岗位的平均工资、最高工资、最低工资
def shujufenxi(self):
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql01 = "select Pay_level from qianchengwuyou where Job_title like '%数据分析%' and Pay_level like '%/%'" #.format(Job)
cursor.execute(sql01)
results = cursor.fetchall()
for i in results:
# 拆分列表获取关键数据
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '数据分析'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
# print(min_salary_list)
all_max_salary_list.append(listmax)
# print(max_salary_list)
all_average_salary_list.append(listaverage)
# print(average_salary_list)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
# 把分析结果写入三大岗位薪资水平.txt文件
file = open('大数据三大相关岗位薪资水平.txt','w',encoding='utf-8')
file.write('{},{},{},{}'.format(listjob,listmax,listaverage,listmin))
file.write('\n')
file.close()
# 关闭游标
conn.commit()
# 求出大数据开发工程师相关岗位的平均工资、最高工资、最低工资
def dashujukaifagongchengshi(self):
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql = "select Pay_level from qianchengwuyou where Job_title like '%大数据开发工程师%' and Pay_level like '%/%'" # .format(Job)
cursor.execute(sql)
results = cursor.fetchall()
for i in results:
# 拆分列表获取关键数据
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '大数据开发工程师'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
# print(min_salary_list)
all_max_salary_list.append(listmax)
# print(max_salary_list)
all_average_salary_list.append(listaverage)
# print(average_salary_list)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
# 把分析结果写入三大岗位薪资水平.txt文件
file = open('大数据三大相关岗位薪资水平.txt', 'a+', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
conn.commit()
# 求出数据采集相关岗位的平均工资、最高工资、最低工资
def shujucaiji(self):
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql = "select Pay_level from qianchengwuyou where Job_title like '%数据采集%' and Pay_level like '%/%'" # .format(Job)
cursor.execute(sql)
results = cursor.fetchall()
for i in results:
# 拆分列表获取关键数据
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '数据采集'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
# print(min_salary_list)
all_max_salary_list.append(listmax)
# print(max_salary_list)
all_average_salary_list.append(listaverage)
# print(average_salary_list)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
# 把分析结果写入三大岗位薪资水平.txt文件
file = open('大数据三大相关岗位薪资水平.txt', 'a+', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
# cursor.close()
conn.commit()
shujufenxi(self)
dashujukaifagongchengshi(self)
shujucaiji(self)
# 关闭游标
cursor.close()
conn.commit()
bar = Bar(
init_opts=opts.InitOpts(width="1000px", height="800px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="大数据三大相关岗位薪资水平", subtitle="单位 千/月"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 45}),
)
bar.add_xaxis(all_addr_list)
bar.add_yaxis("最高薪资", all_max_salary_list)
bar.add_yaxis("最低薪资", all_min_salary_list)
bar.add_yaxis("平均薪资", all_average_salary_list)
bar.render("大数据三大相关岗位薪资水平.html")
print("大数据三大相关岗位薪资水平.html文件")
# 分析“数据分析”、“大数据开发工程师”、“数据采集”等大数据相关岗位在成都、北京、上海、广州、深圳的岗位数
def Job_distribution(self):
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='gongjing',
database='mongodb')
chengdu_num = 0
beijing_num = 0
shanghai_num = 0
guangzhou_num = 0
shenzhen_num = 0
cursor = conn.cursor()
sql = "select Job_title,Workplace from qianchengwuyou where Job_title like '%数据%'"
cursor.execute(sql)
results = cursor.fetchall()
# print(results)
for i in results:
# print(i[1])
Workplace = i[1].split("-")[0]
if "成都" in Workplace:
chengdu_num += 1
elif "北京" in i[1]:
beijing_num += 1
elif "上海" in i[1]:
shanghai_num += 1
elif "广州" in i[1]:
guangzhou_num += 1
elif "深圳" in i[1]:
shenzhen_num += 1
data = [("成都", str(chengdu_num)), ("北京", str(beijing_num)), ("上海", str(shanghai_num)), ("广州", str(guangzhou_num)),
("深圳", str(shenzhen_num))]
print(data)
# 关闭游标
cursor.close()
conn.commit()
# 将分析结果写入大数据相关岗位分布.txt
fw = open('大数据相关岗位分布.txt', 'w',encoding='utf-8')
for line in data:
for i in line:
fw.write(i)
fw.write(',')
fw.write('\n')
fw.close()
# 创建图表对象
pie = Pie()
# 关联数据
pie.add(
# 设置系列名称
series_name="大数据相关岗位地区分布",
# 设置需要展示的数据
data_pair=data,
# 设置圆环空心部分和数据显示部分的比例
radius=["30%", "70%"],
# 设置饼是不规则的
rosetype="radius"
)
# 设置数据显示的格式
pie.set_series_opts(label_opts=options.LabelOpts(formatter="{b}: {d}%"))
# 设置图表的标题
pie.set_global_opts(title_opts=options.TitleOpts(title="大数据相关岗位分布"))
# 数据渲染
pie.render('大数据相关岗位分布.html')
print("大数据相关岗位分布.html")
# 分析大数据相关岗位1-3年工作经验的薪资水平(平均工资、最高工资、最低工资)
def Pay_level02(self):
# 最低工资
all_min_salary_list = []
# 最高工资
all_max_salary_list = []
# 平均工资
all_average_salary_list = []
# 经验
all_addr_list = []
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='gongjing',
database='mongodb')
cursor = conn.cursor()
# 一年工作经验
def yinian(self):
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql = "select Pay_level from qianchengwuyou where (hands_background LIKE '%1-%' or hands_background LIKE '%1年%') and Job_title like '%大数据%' and Pay_level like '%/%'"
cursor.execute(sql)
results = cursor.fetchall()
# print(results)
for i in results:
# 拆分列表获取关键数据
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '一年工作经验'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
all_max_salary_list.append(listmax)
all_average_salary_list.append(listaverage)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
file = open('大数据相关岗位1-3年工作经验薪资水平.txt', 'w', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
# 两年工作经验
def liangnian(self):
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql = "select Pay_level from qianchengwuyou where (hands_background LIKE '%2-%' or hands_background LIKE '%2年%') and Job_title like '%大数据%' and Pay_level like '%/%'"
cursor.execute(sql)
results = cursor.fetchall()
for i in results:
# 拆分列表获取关键数据
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '两年工作经验'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
all_max_salary_list.append(listmax)
all_average_salary_list.append(listaverage)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
file = open('大数据相关岗位1-3年工作经验薪资水平.txt', 'a+', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
# 关闭游标
# cursor.close()
# 三年工作经验
def sannian(self):
# 最低工资
min_salary_list = []
# 最高工资
max_salary_list = []
# 平均工资
average_salary_list = []
sql = "select Pay_level from qianchengwuyou where (hands_background LIKE '%1-%' or hands_background LIKE '%1年%') and Job_title like '%大数据%' and Pay_level like '%/%'"
cursor.execute(sql)
results = cursor.fetchall()
for i in results:
# 拆分列表获取关键数据
if "万/月" in i[0]:
wan_yue = re.findall(r"(.*)万/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10
num_2 = eval(num_list[1]) * 10
i = str(num_1) + "-" + str(num_2) + "千/月"
elif "万/年" in i[0]:
wan_yue = re.findall(r"(.*)万/年", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0]) * 10 / 12
num_2 = eval(num_list[1]) * 10 / 12
i = str(int(num_1)) + "-" + str(int(num_2)) + "千/月"
elif "千/月" in i[0]:
wan_yue = re.findall(r"(.*)千/月", i[0])[0]
num_list = wan_yue.split("-")
num_1 = eval(num_list[0])
num_2 = eval(num_list[1])
i = str(num_1) + "-" + str(num_2) + "千/月"
else:
continue
min_salary = i.split("-")[0]
max_salary = re.findall(r'([\d+\.]+)', (i.split("-")[1]))[0]
average_salary = "{:.1f}".format((float(min_salary) + float(max_salary)) / 2)
# 将获取的数据分别写入
min_salary_list.append(eval(min_salary))
max_salary_list.append(eval(max_salary))
average_salary_list.append(eval(average_salary))
listjob = '三年工作经验'
listmin = min(min_salary_list)
listmax = max(max_salary_list)
listaverage = int(mean(average_salary_list))
all_min_salary_list.append(listmin)
all_max_salary_list.append(listmax)
all_average_salary_list.append(listaverage)
all_addr_list.append(listjob)
print(listjob, listmin, listaverage, listmax)
file = open('大数据相关岗位1-3年工作经验薪资水平.txt', 'a+', encoding='utf-8')
file.write('{},{},{},{}'.format(listjob, listmax, listaverage, listmin))
file.write('\n')
file.close()
yinian(self)
liangnian(self)
sannian(self)
bar = Bar(
init_opts=opts.InitOpts(width="800px", height="600px"),
)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="大数据1-3年工作经验薪资水平", subtitle="单位 千/月"),
xaxis_opts=opts.AxisOpts(axislabel_opts={"rotate": 45}),
)
bar.add_xaxis(all_addr_list)
bar.add_yaxis("最高薪资", all_max_salary_list)
bar.add_yaxis("最低薪资", all_min_salary_list)
bar.add_yaxis("平均薪资", all_average_salary_list)
bar.render("大数据相关岗位1-3年工作经验薪资水平.html")
# commit 修改
conn.commit()
# 关闭游标
cursor.close()
print("大数据相关岗位1-3年工作经验的薪资水平.html")
# 分析大数据相关岗位几年需求的走向趋势
def Demand_trend(self):
a = []
num = 0
conn = connect(host='192.168.1.101',
port=10000,
auth_mechanism='LDAP',
user='root',
password='gongjing',
database='mongodb')
cursor = conn.cursor()
sql = "select day from qianchengwuyou where day like '%-%'"
cursor.execute(sql)
results = cursor.fetchall()
for i in results:
a.append(i[0])
num += 1
a.sort(reverse=True)
print(a)
print(num)
dict = {}
date = []
number = []
for key in a:
dict[key] = dict.get(key, 0) + 1
print(dict)
for key in dict.keys():
date.append(key)
# print(key)
for value in dict.values():
number.append(value)
file = open('大数据相关岗位需求.txt', 'w', encoding='utf-8')
for key, value in dict.items():
value = str(value)
file.write(key + ',')
file.write(value + '\n')
file.close()
(
Line(init_opts=opts.InitOpts(width="2000px", height="800px"))
.set_global_opts(
title_opts=opts.TitleOpts(title="近几天大数据岗位需求", subtitle="仅供参考"),
tooltip_opts=opts.TooltipOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.add_xaxis(xaxis_data=date)
.add_yaxis(
series_name="大数据岗位",
y_axis=number,
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
)
.render("大数据相关岗位需求走势.html")
)
print("大数据相关岗位需求走势.html")
if __name__ == "__main__":
hadoop = HadoopDemo()
# 要测试哪个功能把注释去掉就可以
# print("导出mongodb数据库中的爬虫数据并导入hdfs")
# hadoop.Data_export()
# hadoop.Data_import()
# print("创建hive表")
# hadoop.Create_table_hive()
# print("创建和hive表相同结构的MySQL表")
# hadoop.Create_table_mysql()
# print("分析大数据三大相关岗位的薪资水平")
# hadoop.Pay_level01()
# print("分析大数据岗位的分布情况")
# hadoop.Job_distribution()
# print("分析1-3年工作经验的薪资水平")
# hadoop.Pay_level02()
# print("分析近几天大数据岗位需求")
# hadoop.Demand_trend()
ps:本代码只在本人环境下运行成功,如有错误,肯定不是我的问题
附上一张pip 模块包图
因为安装某些模块需要依赖包,否则会报错
httptools 0.1.1
hyperlink 19.0.0
idna 2.9
imageio 2.8.0
impala 0.2
impyla 0.16.2
incremental 17.5.0
ipykernel 5.3.0
ipython 7.16.1
ipython-genutils 0.2.0
jedi 0.17.1
jieba 0.42.1
Jinja2 2.11.2
json5 0.9.5
jsonschema 3.2.0
jupyter-client 6.1.3
jupyter-core 4.6.3
jupyter-pip 0.3.1
jupyterlab 2.1.5
jupyterlab-server 1.1.5
kiwisolver 1.2.0
lxml 4.5.1
MarkupSafe 1.1.1
matplotlib 3.2.2
mistune 0.8.4
Naked 0.1.31
nbconvert 5.6.1
nbformat 5.0.7
notebook 6.0.3
numpy 1.19.0
packaging 20.4
pandas 1.0.5
pandocfilters 1.4.2
paramiko 2.7.1
parsel 1.6.0
parso 0.7.0
phantomjs 1.3.0
pickleshare 0.7.5
Pillow 7.1.2
pip 20.1.1
plotly 4.8.2
ply 3.11
prettytable 0.7.2
prometheus-client 0.8.0
prompt-toolkit 3.0.5
Protego 0.1.16
pure-sasl 0.6.2
py4j 0.10.9
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycparser 2.20
PyDispatcher 2.0.5
pyecharts 1.7.1
Pygments 2.6.1
PyHamcrest 2.0.2
PyHDFS 0.3.1
PyHive 0.6.2
pymongo 3.10.1
PyMySQL 0.9.3
PyNaCl 1.4.0
pyOpenSSL 19.1.0
pyparsing 2.4.7
pyrsistent 0.16.0
pyspark 3.0.0
python-dateutil 2.8.1
pytz 2020.1
pywin32 228
pywinpty 0.5.7
PyYAML 5.3.1
pyzmq 19.0.1
queuelib 1.5.0
requests 2.23.0
retrying 1.3.3
scal 1.0.0
Scrapy 2.1.0
Send2Trash 1.5.0
service-identity 18.1.0
setuptools 49.1.0
shellescape 3.8.1
simplejson 3.17.0
six 1.15.0
snapshot-phantomjs 0.0.3
soupsieve 2.0.1
sqlparse 0.3.1
terminado 0.8.3
testpath 0.4.4
thrift 0.9.3
thrift-sasl 0.2.1
thriftpy 0.3.9
thriftpy2 0.4.11
tornado 6.0.4
traitlets 4.3.3
Twisted 20.3.0
Unit 0.2.2
urllib3 1.25.9
w3lib 1.22.0
wcwidth 0.2.5
webencodings 0.5.1
wheel 0.34.2
wordcloud 1.7.0
zope.interface 5.1.0
到此实训结束,感谢大家观看
ps:推荐大家使用我的虚拟机进行测试,某些功能如远程连接hive需要特定的jar包,远程连接也要特定的jar包,sqoop也需要jar包
链接: https://pan.baidu.com/s/1MfXSx5qIjQfC9nXDaRvrCg 提取码: qg5g
不确定全不全,也不知道放在哪里。忘了qwq