Java 爬虫入门(网易云音乐和知乎实例)
最近公司赶项目,过上了996的生活,周日还要陪老婆,实在没时间静下来写点东西,于是导致了swift编写2048的第三篇迟迟没有开工,在此说声抱歉,尽量抽时间在这周末补出来。
首先来介绍下爬虫的作用,爬虫主要用于大批量抓取网站中我们所需数据,其实就是模拟出http请求,之后解析分析所得的数据获取我们需要的信息的这么一个过程。
由于网上已经有很多现成的爬虫框架了,这里就不重复造轮子了,先给大家说一下原理,大家可以自己尝试写一个,至于具体实现这篇只带来一个框架的使用实例,让大家可以根据例子快速写出所需的爬虫。
爬虫的关键在于分析我们所需要的数据,分析的越透彻,就可以写出效率越高的爬虫,比如我们需要爬出网易云音乐中播放量超过七百万的歌单,那么首先我们要找到网易云音乐的歌单页面,页面如下:
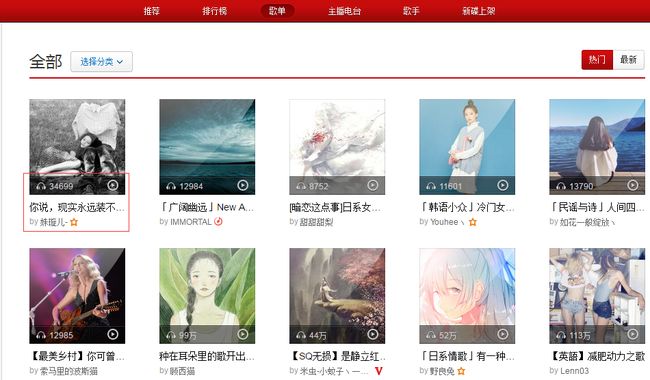
我们所需元素为:歌单名称、歌单链接、歌单播放量,可以看到页面中这几个元素都是有的,那么接下来我们就可以直接通过HttpClient的get方法抓取这个页面,url:http://music.163.com/discover/playlist,抓取之后分析两点:
- 每一个歌单区域,每个歌单区域都是一个
- 标签,我们取出
- 标签中的播放量,判断是否大于七百万,大于则放入我们的结果集中。
- 下面的翻页按钮区域,抓取翻页按钮区域里的url,加入我们的任务队列中,我们的线程会持续从队列中获取url来进行抓取并分析,并执行步骤1
分析过程做完了,接下来我们来看下技术实现,这里就不具体写代码了,因为前面说过本篇不重复造轮子,只会介绍一个用现有框架做的实例,放在后面,这里先介绍下实现方式,大家可以自己尝试下。
- 首先我们需要一个任务队列,队列中存放需要处理的url
- 创建一个线程池,从任务队列中获取url并进行分析,如果队列为空就等待
- 线程池取到url后模拟请求(HttpClient、jodd的HttpRequest等均可,看自己选择),获取返回数据
- 对返回数据进行正则匹配,匹配到需继续分析的url则将其放入队列中,并执行唤醒线程操作
- 匹配到我们所需数据则加入结果集,可写文件可存库也可直接输出,看自己需要。
这样就大概完成了一个爬虫的核心部分,这里需要注意的一点是第四步需做一定的去重工作,可以减少总请求的数量,提高效率。
接下来看一个具体框架的实例,这里使用的是国内的黄亿华先生共享的webmagic框架,其主页地址为:http://webmagic.io/。
接下来来看一个具体实例,这里我要抓取知乎旅行话题下关注量超过3万,且内容中包含5次以上“吃”字的。那么首先我们打开旅行页:
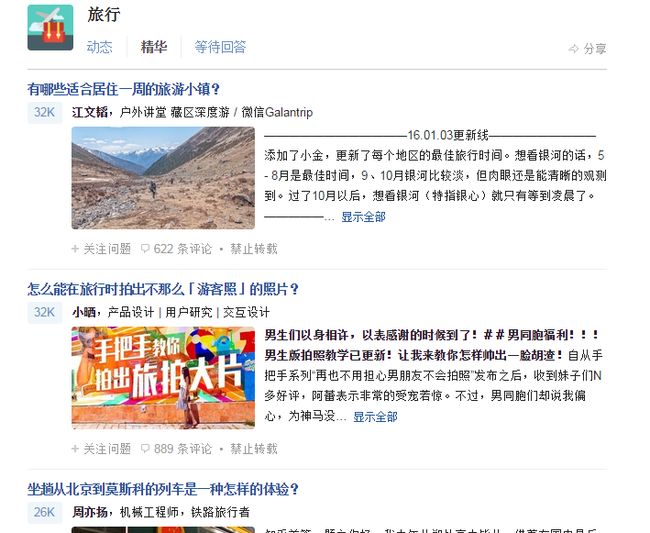
可以看到,本页有很多的问题,但是没有问题的关注数,那么我们点开一个问题看下问题页:
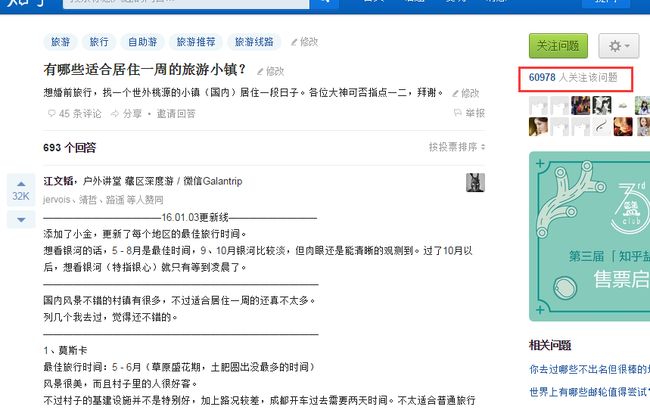
可以看到,右边红框中有我们需要的关注数这个信息,chrome下F12查看网页源码,分析出里面的dom结构,可以得到如下思路:
- 请求https://www.zhihu.com/topic/19551556/top-answers,分析其中信息
- 匹配正则为https://www.zhihu.com/topic/19551556/top-answers\?page=\d+ 的页面即为知乎当前话题精选目录的每个列表页,其中的page为页数
- 匹配正则为https://www.zhihu.com/question/\d+ 的页面则为具体的问题页
- 在具体的问题页中获取到关注数量,判断是否大于30000,大于则继续取该问题的body块中的内容,匹配其中包含多少“吃”字,如果大于5条则将结果保存。
接下来看具体每一步的实现:
一:新建maven工程,添加maven依赖
这一步不多介绍,这里贴出pom.xml中的配置。当然如果你不使用maven,可以到http://webmagic.io/ 中下载现有的jar包。
us.codecraft
webmagic-core
0.5.3
us.codecraft
webmagic-extension
0.5.3
org.slf4j
slf4j-log4j12
1.7.21
com.google.guava
guava
19.0
其中的webmagic-core和webmagic-extension就是黄亿华先生共享的webmagic框架,下面俩依赖是webmagic框架中需要依赖的外部依赖包,当然如果是自己下的jar包,后面两个jar包也要加到自己的工程目录中
二:编写具体实现
由于这里用的现有框架,所以实现代码很简单,就一个类:
package org.white.spider;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 知乎爬虫
* @author mr. white
* @version v 0.1 ZhihuTravelProcessor.java
* @Date 2016/4/19 20:55
*/
public class ZhihuTravelProcessor implements PageProcessor {
private static final String FOCUS_BEGIN_STR = " ";
private static final String FOCUS_END_STR = " 人关注该问题";
private Site site = Site.me().setCycleRetryTimes(5).setRetryTimes(5)
.setSleepTime(500).setTimeOut(3 * 60 * 1000)
.setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0")
.addHeader("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.addHeader("Accept-Language", "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3").setCharset("UTF-8");
private static Map eatMap = new HashMap();
public void process(Page page) {
page.addTargetRequests(
page.getHtml().links().regex("(https://www.zhihu.com/topic/19551556/top-answers\\?page=\\d+)").all());
page.addTargetRequests(page.getHtml().links().regex("(https://www.zhihu.com/question/\\d+)").all());
if (page.getUrl().regex("(https://www.zhihu.com/question/\\d+)").match()) {
List playCountList = page.getHtml()
.xpath("//div[@class='zm-side-section-inner zg-gray-normal']/html()").all();
if (playCountList.size() == 1) {
String focusStr = playCountList.get(0);
long focus = Long.parseLong(focusStr.substring(
focusStr.indexOf(FOCUS_BEGIN_STR) + FOCUS_BEGIN_STR.length(), focusStr.indexOf(FOCUS_END_STR)));
if (focus > 30000) {
List eatList = page.getHtml()
.xpath("//div[@class='zm-item-rich-text js-collapse-body']/html()").regex("吃").all();
List titleList = page.getHtml().xpath("//title/html()").all();
if (eatList.size() > 5) {
eatMap.put(page.getUrl().toString(), titleList.get(0));
}
}
}
}
}
public static void main(String[] args) {
Spider.create(new ZhihuTravelProcessor()).addUrl("https://www.zhihu.com/topic/19551556/top-answers").thread(5)
.run();
System.out.println("====================================total===================================");
for (String s : eatMap.keySet()) {
System.out.println("title:" + eatMap.get(s));
System.out.println("href:" + s);
}
}
public Site getSite() {
return site;
}
}
上述就是具体实现,都很简单,这里就不具体解释了,大家可以自己写了跑一下看看,其中关于webmagic的东西可以参考文档:http://webmagic.io/docs/zh/ 里面写的很详细。
今天就到这里了,大家有什么问题欢迎提出。
我的博客:blog.scarlettbai.com
我的公众号:读书健身编程
