架构基础知识总结1
文章目录
- 一、nginx入门配置篇(初识核心功能)
- 1.1、nginx配置文件结构和核心功能
- 1.1.1、nginx的配置文件结构
- 1.1.2、nginx核心功能
- 1.1.3、nginx实现web功能(http)的核心模块
- 二、linux集群
- 2.1、集群概述
- 2.1.1、单台主机所面临的问题和解决概述
- 2.1.2、集群面临的问题和解决思路
- 2.2、linux集群类型
- 2.3、linux集群系统扩展方式
- 2.4、linux集群的调度方法
- 2.4.1、静态调度算法
- 2.4.2、动态调度算法
- 三、LVS应用
- 3.1、lvs功能的实现
- 3.2、lvs四种集群优点和使用场景
- 3.3、LVS-NAT和LVS-DR的原理和实现举例,LVS-FUN和LVS-FULLNAT简单图解
- 3.3.1、LVS的NAT类型
- 3.3.2、LVS的DR类型
- 3.3.3、LVS的tun类型简单报文图解(隧道)
- 3.3.4、LVS的fullnat类型简单报文图解
感谢和参考:
PS:理论思想和实践实验步骤主要是来自于马哥linux教育的学习,特此感谢,也感谢下面这些博主精彩的博文,从中受益良多,有些比较精彩的部分有摘抄过来。
参考或摘抄博文链接:
http://www.linuxvirtualserver.org/zh/lvs4.html
https://www.cnblogs.com/wangshaojun/p/5149532.html
https://www.jianshu.com/p/2acab9134dbf
http://www.178linux.com/104977
https://www.jianshu.com/p/5184c6564ee2
https://www.jianshu.com/p/298a85b74abf
https://www.ibm.com/developerworks/cn/linux/l-cn-directio/
https://www.cnblogs.com/youngerchina/p/5624462.html
一、nginx入门配置篇(初识核心功能)
1.1、nginx配置文件结构和核心功能
以下几个nginx官方相关的链接可以经常去看看:
nginx 总官方主页地址
nginx 文档的api链接地址(简单的官网)
nginx 的所有模块文档地址入口
nginx 所有变量索引目录
nginx 所有指令索引目录
1.1.1、nginx的配置文件结构
官方地址:http://nginx.org/en/docs/beginners_guide.html
注解:
nginx 由模块组成,模块由配置文件中指定的指令控制。指令被分成两种,包括简单指令和块指令。简单指令由名字和参数组成,名字和参数之间以空格或空白隔开,然后命令结尾以分号结束。块指令格式和简单指令语法差不多,末尾分号去掉后,会使用一组花括号({})引起来。花括号内可以有其他指令包含在内,这个叫做上下文(比如:events,http,server以及location指令都是块指令)。
在任何上下文之外放置在配置文件中的指令都被认为是在上下文中。nginx 分为主配置段(全局配置段),可以支持很多全局配置的指令,相关指令可以参考[nginx全局配置端指令(http://nginx.org/en/docs/ngx_core_module.html)。在主配置段中,可以包含 events块,http块。而server块在http块中,location块在server中。在配置文件中,以"#"开头的都属于注释部分。
主配置文件的配置指令用法总结:
普通指令:directive value [value2 …];
块指令:directive{ … }
所有nginx支持的指令使用说明链接:http://nginx.org/en/docs/dirindex.html
普通指令必须以分号结束;在整个配置文件中,允许智勇配置变量,配置变量主要分以下两类:
(1) 内建变量
有nginx模块引入,可直接使用。所有nginx模块引入的变量使用说明链接:
http://nginx.org/en/docs/varindex.html
(2)自定义变量
由用户使用set命令定义(set variable_name value;),引用变量方式:$variable_name
set除了可以做定义自定义变量,还可以修改内建变量的值。
大概的配置结构:
主配置文件结构如下:
#main block:主配置段,也即全局配置段;
...... #简单指令部分(全局的配置指令)
event {
......
} #事件驱动相关的配置;
http {
......
} #http/https 协议相关的配置段;
mail {
......
} #邮件协议相关配置段,这部分应用很少
stream {
......
} #传输层代理配置段
http协议相关的配置结构:
http {
......
...... #各server的公共配置部分
server {
......
} #每个server用于定义一个虚拟主机
server {
......
listen
server_name
root
alias
location [OPERATOR] URL {
.....
If CONDITION {
......
}
}
}
}
1.1.2、nginx核心功能
核心功能配置部分按照作用分为以下几类:
1、正常运行必备的配置
2、优化性能相关的配置(其实谈不上优化,而就是做参数调整而已,优化这个东西涉及知识点太广)
3、用于调试及定位问题相关的配置
4、事件驱动相关的配置
下面的指令的官方文档链接:http://nginx.org/en/docs/ngx_core_module.html
被nginx官方标识为:Core functionality(核心功能)
- 1、正常运行必备的配置
(1) user指令
语法格式:user username [groupname]
默认值:user nobody nobody;
上下文:main
官网注解:Defines user and group credentials used by worker processes.
If group is omitted, a group whose name equals that of user is used.
自己的注解:定义nginx工作进程启动运行身份的用户属主和属组。一般来说,建议worker是普通用户,比如nginx,www,nobody等等。
如果省略组名,默认组会取和用户名一样的名字。(PS: 涉及nginx处理用户请求,是worker进程来处理的,所以涉及到权限的东西,也是
工作进程运行用户和组的进程安全上下文。)
重点补充:
安全上下文说明。
1、进程以某用户的身份运行,进程就是发起此进程用户的代理,因此以此用户的身份和权限完成所有的操作。
2、权限匹配模型(基本权限,不涉及特殊权限和访问控制列表)
a) 判断进程的属主是否为被访问的文件的属主:如果是,则应用属主的权限,否则接着往下判断;
b) 判断进程的属组是否属于被访问的文件属组:如果是,则应用属组的权限,否则接着往下判断;
c) 如果上述两种情况都没有匹配到权限,则应用other的权限,即文件的其他者;
权限字符表示有两个:r、w和x,分别代表读,写和执行权限;
基本权限相较于文件而言:
r:表示可获取文件的数据;
w:表示可修改文件的数据;
x:表示可将此文件发起运行为进程;
基本权限相对于目录:
r:可使用ls命令获取其下的所有文件列表;
w:可修改此目录下的文件列表,即创建或删除文件;
x:可切换到此目录中,且可使用ls -l来获取所有文件的详细属性信息。
(2) pid指令
语法格式:pid file;
默认值:pid logs/nginx.pid;
上下文:main
官方注解:Defines a file that will store the process ID of the main process.
自己注解:定义用来存储主进程的进程id的文件,或者叫用来指明存储nginx主进程进程号的文件。
可以指定为这种格式便于理解:pid /PATH/TO/PID_FILE #可以是相对路径,也可以是绝对路径。如果是相对路径值,是相对nginx编译安装(不管
是自己源码包编译安装,还是自己根据spec文件制作的rpm包手动使用rpm安装或者是yum调用的nginx官方yum仓库或者第三方yum仓库安装,
yum安装也是安装制作好的rpm包。都可以给nginx的主程序文件传一个选项-V来查看编译选项,其中一个--prefix=path,我们这里的pid指定的如
果是相对目录,就是相对这个选项的path路径) 服务端文件安装根目录。
(3) include指令
语法格式:include file | mask;
默认值:无
上下文:any #任意块或段落中都可以使用该指令
官方注解:Includes another file, or files matching the specified mask, into configuration. Included files should consist of syntactically correct
directives and blocks.
自己注解:包含其他文件或者指定掩码(通配符等,比如*.conf)匹配的文件加入到配置文件中。包含进来的文件中的指令和块的语法要正确。
简单概括一句话:用来指明包含进来的其他配置文件片段;
(4) load_module指令
语法格式:load_module file;
默认值:无
上下文:main
官方注解:Loads a dynamic module.This directive appeared in version 1.9.11.
自己注解:指明要装载的动态模块。比如:load_module " /usr/lib64/nginx/modules/ngx_http_image_filter_module.so";
PS:前提是要装载的模块要编译进来了,而且是支持动态装卸载的模块。nginx是1.9.11版本引入的动态模块,1.9.11以及之后的版本才支持
load_module指令。现在默认epel仓库默认版本已经是nginx-1.10.x,而且官方稳定版本更新到了1.14.x(2019年1月7日确认,最新稳定版本是
1.14.2)。
- 2、性能优化相关的配置
(1) worker_process指令
语法格式:worker_processes number | auto;
默认值:worker_processes 1;
上下文:main
官方注解:Defines the number of worker processes.
The optimal value depends on many factors including (but not limited to) the number of CPU cores, the number of hard disk drives that store
data, and load pattern. When one is in doubt, setting it to the number of available CPU cores would be a good start (the value “auto” will try
to autodetect it).
The auto parameter is supported starting from versions 1.3.8 and 1.2.5.
自己注解:
定义nginx的工作进程的数量。(建议设置为小于或等于当前主机的cpu的物理核心数)
最佳取值取决于居多因素,包括(但不仅限于)CPU的核心数,存取数据的硬盘驱动的数量以及负荷模型等。如果不确定如何设置,设置它的值为
cpu核心数是一个好的开端(如果设置为auto,会尝试去自动检测cpu核心数,并设置为检测的实际值)。
auto参数是在nginx的 1.3.8版本和1.2.5版本引入。
PS:这里设置为大于cpu的核心数没有意义而且反而可能会有副作用,因为本身nginx的IO模型就是一个进程处理可以响应多个请求,如果我
物理服务器性能指标能承受得住,我可以调整单个工作进程响应处理的请求数量。通常建议是物理cpu有几个核心,我们设置的值应该小于或等
于这个核心数的值。为什么不固定设置为1呢,因为为了更好的利用cpu的核心来工作。因为一个nginx工作进程在工作的时候必然是调度在一个
选定的或固定的物理cpu核心上,如果此时系统其他进程负载很小可以忽略不计,那么如果我物理cpu核心数量不止1,其他cpu核心就处于空闲状
态了。什么情况下,至少要小于物理cpu核心数呢?就是系统上除了我们nginx进程之外,还有其他的进程,而且也有生产力,所以这种情况下建
议至少预留一个核心来调度其他进程。如果把这个参数的值设置大于物理cpu核心数,我们都知道nginx的工作进程如果有启动,势必要响应处理
请求,如果对于一个繁忙的web服务器,如果设置的这个参数值大于物理cpu核心数,那么多出来的部分,势必就要做cpu按照时间分片技术调
度,调度就存在资源浪费(有人可能会说,我一台系统不可能不存在除了nginx之外的其他进程。话虽如此,其他进程相较繁忙的nginx的工作进
程,相对占用cpu时间也不会太长,负载可以忽略。但是对于繁忙的工作进程,cpu切换带来开销是挺大的,具体底层比较复杂。如果一定要计
算轻量负载的其他非nginx的进程cpu切换带来的性能影响,可以考虑后边cpu绑定设置)。
(2) worker_cpu_affinity_cpumask指令
语法格式:worker_cpu_affinity cpumask ...;
worker_cpu_affinity auto [cpumask];
默认值:无
上下文:main
官方注解:Binds worker processes to the sets of CPUs. Each CPU set is represented by a bitmask of allowed CPUs. There should be a
separate set defined for each of the worker processes. By default, worker processes are not bound to any specific CPUs.
自己的注解:
将工作进程绑定在CPU集上。每个CPU集由允许的CPU的位掩码所表示。应该为每一个工作进程定义一个单独的集。默认,工作进程不绑定在任
何的cpu上。(绑定只是一种简单的优化逻辑。每一个进程在运行时候都有它自己的数据加载,而为了能够加速这个数据处理过程,我们cpu有设
计1级缓存,2级缓存,3级缓存等。如果把一个进程绑定在cpu上,它的缓存始终会命中。如果不绑定,cpu在做处理进程切换的时候,缓存项可
能就会失效了,因为除了nginx本身的进程之外,还会有系统进程。如果当时工作进程1被分配到了cpu核心1上,工作进程2被分配到了cpu核心2
上,那么这两个cpu就有可能分别缓存了工作进程1和2的数据。当处理nginx进程之外的其他系统进程需要使用cpu的时候,可能会把cpu核心1和
cpu核心2都调度切换,回头再次调度到工作进程1和工作进程2的时候有可能工作进程1被分配到了cpu核心2,工作进程2被分配到了cpu核心1,
这样之前工作进程在cpu的缓存数据势必就失效了。
还有一种比较复杂的设置,比如我系统有4个cpu核心。如果系统上处理nginx,其他进程几乎没有负载,可以实现,把nginx的3个工作进程直接
绑定到4个cpu核心中的3个,然后通过某些技术屏蔽掉这3个绑定的cpu,让它们只给其各自绑定的nginx的工作进程服务,剩下的1个cpu核心,
用于调度系统的其他进程任务。也就是说绑定的3个cpu核心数不再参与系统其他进程的调度任务。这个就是与之前的绑定的区别。不过这个功
能需要系统在启动的时候,单独隔离这3个绑定的cpu,比如麻烦。)
例如:
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
设置工作进程为4个,并分别把每个工作进程绑定到每个分离的cpu上。0001表示第0号cpu(第一个cpu核心),0010表示第1号cpu(第二个cpu核
心),0100表示第2号cpu(第三个cpu核心),1000表示第3号cpu。这里之所以是4为二进制,因为物理cpu核心总共才8个。如果有8核心,位掩码
一共要有8位才对。
例如:
worker_processes 2;
worker_cpu_affinity 0101 1010;
绑定第一个工作进程在CPU0和CPU2上(0101可以拆分为0001和0100),因为有可能多核新是超线程实现的多核。比如我实际只有两颗物理
cpu,而且每颗物理cpu分别有一个核,然后cpu通过超线程技术支持,然每颗物理cpu支持2核,所以这样通过超线程实现的多核cpu(4核)实际真
正的物理核心数应该只有2。
绑定的二个工作进程在CPU1和CPU3上(1010可以拆分为0010和1000).这第二个示例对于适用于超线程。
例如:
worker_processes auto;
worker_cpu_affinity auto;
这种情况,就是工作进程设置的是auto,绑定也支持的是auto。对于一个系统专门只提供nginx业务的,而且其他系统进程负载很轻的情况下,
可以这样做。如果还提供其他业务,比如mysql等,建议不要绑定。
例如:
worker_cpu_affinity auto 01010101;
可选参数mask可以用来限定可以自动绑定的cpu。
(3) worker_priority指令
语法格式:worker_priority number;
默认值:worker_priority 0;
上下文:main
官方注解:Defines the scheduling priority for worker processes like it is done by the nice command: a negative number means higher
priority. Allowed range normally varies from -20 to 20.
自己的注解:为工作进程定义调度的优先级,就像由nice执行命令一样。通常我们也说指定worker进程的nice值,设定woker进程优先级:负数
意味着优先级高。允许使用的默认范围为:-20到20。什么场景,这样使用呢?就是当一个业务系统,nginx作为一个比较核心的业务的时候,然
后有其他业务进程会和它竞争资源,可以把nginx的工作进程的进程优先级条高一点。
小技巧:ps如何查看nice值,ps axo comm,pid,psr,ni
例如:
worker_priority -10;
(4) worker_priority指令
语法格式:worker_rlimit_nofile number;
默认值:无
上下文:main
官方注解:Changes the limit on the maximum number of open files (RLIMIT_NOFILE) for worker processes. Used to increase the limit without
restarting the main process.
自己注解:改变所有worker进程所允许打开的最大文件数量限制(即所有worker进程所能够打开的文件上限)。增加这个限制,不需要重启nginx的
管理进程。因为worker进程打开一个连接就需要维持一个套接字,如果worker能够支持的最大并发为1024,就表示需要打开1024个套接字件,
还姑且不说其他文件。如果我们要提高这个值的话,还受制于worker进程对应系统用户所能打开的进程数,否则它无法创建这么多的连接数量。
切记这个是定义所有worker进程所允许打开的最大文件数量。这个值应该大于或等于后面介绍的event块中的worker_connections参数设定的值
与worker_processes设定值。公式:
worker_rlimit_nofile >= worker_processes* worker_connections
- 3、调试、定位问题
(1) daemon指令
语法格式:daemon on | off;
默认值:daemon on;
上下文:main
官方注解:Determines whether nginx should become a daemon. Mainly used during development.
自己注解:是否以守护进程方式运行nginx。
(2) master_process指令
语法格式:master_process on | off;
默认值:master_process on;
上下文:main
官方注解:Determines whether worker processes are started. This directive is intended for nginx developers.
自己注解:是否以master/worker模型运行nginx;
(3) error_log指令
语法格式:error_log file [level];
默认值:error_log logs/error.log error;
上下文:main,http,mail,stream,server,location
官方注解:官方注解比较长,请自行参考:http://nginx.org/en/docs/ngx_core_module.html#error_log
自己注解:这个指令用来配置日志日志记录信息的,是我们常说的错误日志和调试日志。指令的第一个参数file表示用来指明定义一个文件用来
存储日志,可以是一个相对路径也可以是一个绝对路径。指定文件权限要nginx的工作进程用户要对这个文件有读写的权限。从1.7.11版本开始,
error_log可以在stream中用;从1.9.0开始,error_log可以在mail中有。
日志级别可选值有,debug,info,notice,warn,error,crit,alert以及emerg。一般生成环境使用warn或notice就行。
- 4、事件驱动相关的配置
事件驱动相关的配置通常在下面这个语句块中:
events {
......
}
(1) worker_connections指令
语法格式:worker_connections number;
默认值:worker_connections 512;
上下文:events
官方注解:Sets the maximum number of simultaneous connections that can be opened by a worker process.
It should be kept in mind that this number includes all connections (e.g. connections with proxied servers, among others), not only
connections with clients. Another consideration is that the actual number of simultaneous connections cannot exceed the current
limit on the maximum number of open files, which can be changed by worker_rlimit_nofile.
自己注解:设置被单个工作进程(worker process)所能同时打开的最大并发连接数。要牢记一点,这个连接不仅仅只指客户端的连接,而是所有
的连接(比如,被代理服务器的连接也包含在内)。设置这个值的时候还要考虑实际允许并发的连接数不能超过最大的文件打开限制,可以改变
worker_rlimit_nofile这个值来调整。
(2) use指令
语法格式:use method;
默认值:无
上下文:events
官方注解:Specifies the connection processing method to use. There is normally no need to specify it explicitly, because nginx will by default
use the most efficient method。
关于连接处理的方法可以参考:http://nginx.org/en/docs/events.html
自己注解:指明并发连接请求的处理方法。红帽发型版本一般推荐使用epoll,只要linux内核是2.6之后的版本。关于nginx所支持的连接方法说
明,可以参考上面的链接。
(3) accept_mutex指令
语法格式:accept_mutex on | off;
默认值:accept_mutex off;
上下文:events
官方注解:If accept_mutex is enabled, worker processes will accept new connections by turn. Otherwise, all worker processes will be notified
about new connections, and if volume of new connections is low, some of the worker processes may just waste system resources.
There is no need to enable accept_mutex on systems that support the EPOLLEXCLUSIVE flag (1.11.3) or when using reuseport.
Prior to version 1.11.3, the default value was on.
自己注解:处理新的连接请求方法;on意味着由各worker轮流处理请求,off意味着每个新请求的到达都会通知所有的worker进程;这是一种互
斥锁机制。设置启用这种机制,表示起点公平,比如现在有100个请求过来,有启动4个worker进程,每个进程分配25个。如果设置为off,意味着
结果公平,就是来了请求,所有的worker进程会去竞争响应,可想而知,对于比较空闲的工作进程能竞争到的概率就要高一点。所以从大局来
看,所有的工作进程所分配到的请求的数量应该是平均的。从我个人的理解来看,对于繁忙的业务系统,可以开启这个。对于空闲的业务系统或
者说新的连接数很少,如果所有的工作进程都去响应每一次的请求,势必会有一些资源浪费。
1.1.3、nginx实现web功能(http)的核心模块
与http相关的模块文档地址:http://nginx.org/en/docs/
下面部分涉及的指令99%都是来自于http协议功能的核心模块,ngx_http_core_module,部分1到2个不属于此http协议的核心模块功能,会在讲解指令的时候特殊说明。http功能的核心模块官方文档链接为:
http://nginx.org/en/docs/http/ngx_http_core_module.html
本部分配置大概框架:
http {
... ...
server {
...
server_name
root
location [OPERATOR] /uri/ {
...
}
}
server {
...
}
}
说明:从这部分开始,后续讲解的指令由于官方文档涉及全部用法非常复杂,所以后续讲解,不会把官方文档的所有部分都贴
出,只会选取比较重要的部分说明。如果有些没有提到后续又要用,请自行参考官方文档对应功能模块的对应指令的详细用法。
- 1、与套接字相关的配置
(1) server指令
语法:server { ... }
默认值:无
上下文:http
注解:
配置虚拟主机。基于IP和基于主机名的虚拟主机并没有清晰的区别。(主机名最终还是会通过DNS解析成IP,所以并没有大的区别)。在server指
令定义的虚拟主机配置段中,可以使用listen指令指明该虚拟主机接受连接涉及到的所有地址和端口信息。server_name指令用来列出虚拟主机
的所有主机名称。
官方有个说明引导,关于如何配置的:
http://nginx.org/en/docs/http/request_processing.html
(2) listen指令
语法(基于官方精简版):listen port | address[:port] | unix:/PATH/TO/SOCKET_FILE
listen address[:port] [default_server] [ssl] [http2 | spdy] [backlog=number] [rcvbuf=size] [sndbuf=size]
默认值:listen *:80 | *:8000;
上下文:server
default_server:设定默认虚拟主机;
ssl:限制仅能够通过ssl连接提供服务;
backlog=number:后援队列长度;(超过最大并发连接后,排队的队列的长度)
rcvbuf=size:接受缓冲区大小;
sndbuf=size:发送缓冲区大小;
说明:在接收请求的虚拟主机中可以使用address和port指明对应虚拟主机的监听地址和端口或者使用unix套接字用来指明本地通信的一个套接
字文件。可以同时指明address和port或者只给定address或只给定port。其中的address可以是一个主机名。例如:
listen 127.0.0.1:8000;
listen 127.0.0.1;
listen 8000;
listen *:8000;
listen localhost:8000;
#ipv6 ,nginx 0.7.36版本之后可以使用
#UNIX-domain套接字,nginx0.8.21版本之后可以使用,要指明"unix:"前缀
listen unix:/var/run/nginx.sock;
重点:如果只给定了address,默认http协议使用的是80端口,配合ssl后使用的是443。
如果指令address没有给定,如果nginx服务是以管理员权限用户启动(就是nginx的管理进程的启动用户是管理员用户),默认是用*:80,如果
nginx服务是以非管理员权限用户启动,默认是用*:8000。
如果有多个虚拟主机,默认多个虚拟主机都没有指定default_server,那么第一个虚拟主机会作为默认的虚拟主机。如果在启动一个或者多个虚
拟主机中使用了(通常应该只会指定一个,或者把要当作的默认虚拟主机放在第一个) default_server指令,那么这个虚拟主机会作为默认的虚拟
主机。如果给定了ssl参数,表示所有连接请求都应该以SSL模式,即使我指定的监听端口是80,连接也应该以SSL模式工作,比如:
listen 80;
区别于
listen 80 ssl;
有时候为了让HTTP和HTTPS协议都能使用,可以这样指定:
listen 80;
listen 443 ssl;
(3) server_name指令
语法结构:server_name name ...;
默认:server "";
上下文:server
注解:指明虚拟主机的主机名称;后可跟多个由空白字符分隔的字符串;
支持*通配匹配任意长度的任意字符:server_name *.yanhui.com www.yanhui.*
支持~起始的字符做正则表达式模式匹配:server_name ~^www\d+\.yanhui\.com$
匹配机制:
(a) 首先匹配字符串精确的匹配;
(b) 左侧*通配符;
(c) 右侧*通配符;
(d) 正则表达式;
(4) tcp_nodelay指令
语法结构: tcp_nodelay on | off;
默认值: tcp_nodelay on;
上下文: http, server, location
注解:在keepalived模式下的连接是否启用TCP_NODELAY选项。
对于一个要发送的数据,以TCP/IP4层结构来说,在每一层要加上对应的首部。如果要发送的数据的字节数比较小,有可能数据报文的首部的大
小要大于要发送的实际的内容的字节数。这样的一次发送请求,对于开销来说未免有些浪费,有一种思路就是我可以把小的内容先攒着,然后集
中发送,这样就会有一个问题,对于客户端来讲,接受就会有延迟。为什么说nodelay要运行于保持连接模式呢,因为非保持连接模式,客户端
每一次请求连接都是3次握手4次挥手的过程,如果是保持连接,可以一次会话的建立,会有多个请求在一次会话中进行。这个tcp_nodelay启用
后表示,不延迟到达,每一次请求都会及时发送,用户体验方面会好一点,不过每一次及时发送,小资源的报文未免会浪费带宽等资源。
(5) tcp_nopush指令
语法结构:tcp_nopush on | off;
默认值:tcp_nopush off;
上下文:http,server,location
注解:在sendfile模式下,是否启用TCP_CORK选项;启动此选项可以实现的功能:
(a) 响应报文首部和整个文件的起始内容放在一个报文中发送。
(b) 利用完整的报文发送一个文件,不会把文件分开来发送。
使用sendfile机制的话,可以基于内容把文件发过去了,但是应用层首部呢?内核无法生成应用层首部信息(tcp首部可以生成),因为它不理解应
用层协议。比如封装http协议的应用层首部,只有nginx或者httpd才有权限封装。sendfile的机制就是文件内容先发送,然后应用层首部随后到
达。使用tcpnopush,等用户空间的应用层首部发送过来,然后内核打包成一个报文然后发送。sendfile启用的优势是整个文件的内容直接在内
核空间生成封装的内容,而不需要经过用户空间后然后再到内核空间。
(6) sendfile指令
语法结构:sendfile on | off;
默认值:sendfile off;
上下文:http,server,location,if in location
注解:Enables or disables the use of sendfile().
sendfile这个功能已经在多处提到。大概功能就是,外部客户端请求服务端的内容后,请求的内容可能在磁盘上,默认工作模式是从磁盘加载数
据到内核的内存空间(因为对磁盘的操作是特权的操作,只有内核才能完成),然后从内核的内存空间加载到web服务的进程的内存空间。而且以
TCP/IP 4层或者5层模型来看,报文要封装,每一层都要封装一层首部,实现报文的传输和拆解。启动sendfile的好处就在于,除了应用层首部的
报文的封装之外,磁盘加载的文件的内容不会发送给用户空间,而是直接存储在内核空间的内存中,封装成报文发送,对于文件传输内容很大的
情况下,这种sendfile是很大的优化点。(解释可能不够精细,重点在于通俗)
- 2、定义路径相关的配置
(1) root指令
语法结构:root path;
默认值:root html;
上下文:http,server,location,if in location
注解:设置web资源路径映射;用于指明用户请求的url所对应本地文件系统上的文档所在目录路径;
指令的路径参数可以包含变量,有两个变量比较特殊,不能使用,它们是:$document_root和$realpath_root,$document_root表示root或者
alias指令的值,如果访问路径涉及符号链接,会使用符号链接;$realpath_root表示root或alias指令的值,与之前$document_root的区别在于,
如果对应目录中有符号链接,会把真正的链接给出来。
例如:
location /i/ {
root /data/w3;
}
比如我请求/i/top.gif,实际对应文件系统路径的内容为:/data/w3/i/top.gif
(2) location指令
语法结构:location [ = | ~ | ~* | ^~ ] uri { ... }
默认值:
上下文:server,location
注解:根据请求的URI来设置配置属性。location中就是用来做nginx属性设置相关的。在一个server中location配置段可存在多个,用于实现从uri
到文系统的路径映射;nginx会根据用户请求的URI来检查定义的所有的location,并找出一个最佳匹配,而后应用其配置。
=:表示对URI做精确匹配,例如:http://www.yanhui.com/, http://www.yanhui.com/index.html
location = / {
......
}
#上面这种形式,第一个链接可以被匹配,第二个不行,因为第一个是/,第二个是/index.html
~:对URI做正则表达式模式匹配,区分字符大小写;
~*:对URI做正则表达式模式匹配,不区分字符大小写;
^~:对URI的左半部分做匹配检查,不区分字符大小写;
不带符号:匹配起始于此uri的所有的url;
匹配优先级:(从高到低)
=
^~
~和~*是同级
不带符号
官方有个例子比较全面,就直接粘贴过来了:
location = / {
[ configuration A ]
}
location / {
[ configuration B ]
}
location /documents/ {
[ configuration C ]
}
location ^~ /images/ {
[ configuration D ]
}
location ~* \.(gif|jpg|jpeg)$ {
[ configuration E ]
}
The “/” request will match configuration A, the “/index.html” request will match configuration B, the “/documents/document.html” request will
match configuration C, the “/images/1.gif” request will match configuration D, and the “/documents/1.jpg” request will match configuration E.
(3) alias指令
语法结构:alias path;
默认值:无
上下文:location
说明:定义路径别名,文档映射的另一种机制;
注意:location中使用root指令和alias指令的意义不同(下面的区别描述不一定精确,但是可以这么理解)
(a) root,给定的路径对应于location中的/uri/左侧的/;
(b)alias,给定的路径对应于location中的/uri/ 右侧的/;
由于这个东西比较重要,我举几个例子:
location /i/ {
alias /data/w3/images/;
#root /data/w3/images/;
}
请求/i/top.gif,文件系统路径对应会去找:/data/w3/images/top.gif
如果把上面的alias换成root,文件系统路径会去找:/data/w3/images/i/top.gif
有一种情况,就是图片资源和其他资源是分目录存储,访问的时候,比如:
location /images/ {
alias /data/w3/images/;
}
请求/images/123.jpg,文件系统路径对应会去找: /data/w3/images/123.jpg。这样就会给人一种误解,两个都有images字符串。所以建议配置成以下这种格式:
location /images/ {
root /data/w3;
}
上面这种情况是定义location后边的path与指令alias指令值的末尾部分一致的时候,建议把alias换成root,并把原本alias的值中与location相同的部分去掉。
(4) index指令
特殊保护说明:属于ngx_http_index_module模块。这里之所以放在这里,是因为这个指令也比较常用。
语法结构:index file ...;
默认值:index index.html;
上下文:http, server, location
官方说明:Defines files that will be used as an index. The last element of the list can be a file with an absolute path.
自己注解:定义默认主页文件,或者叫默认的索引文件。指定参数值可以包含变量,多个参数之间以空白分隔开,参数值列表的最后一个值可以
是一个绝对路径。例如:index index.$geo.html index.0.html /index.html;检测顺序是从左到右的顺序。
(5) error_page指令
语法结构:error_page code ... [=[response]] uri;
默认值:无
上下文:http, server, location, if in location
注解:Defines the URI that will be shown for the specified errors
自定义指定错误先调用显示的页面。比如指定404状态的,自定义500,502,503,504等异常状态显示的错误页面。而且可以指定调用后错误页面
的状态码,可以改成正常的。
(6) try_files指令
语法结构:try_files file ... uri;
try_files file ... =code;
默认值:无
上下文:server,location
说明:按照指定顺序分别检查文件是否存在,并使用找到的第一个文件进行请求处理。检查处理是在当前上下文中进行的。根据root和alias指令
指向的文件系统路径去查找文件。如果要检查目录是否存在,可以在名称的尾部加上左斜线(/)后缀,例如:"$uri/"。如果前边所有的文件都没有被
找到,会以文件参数列表的最后一个参数指向的路径指定的URI来进行重定向。
- 3、定义客户端请求的相关配置
(1) keepalive_timeout指令
语法结构:keepalive_timeout timeout [header_timeout]
默认值:keepalive_timeout 75s;
上下文:http,server,location
注解:如果第一个参数timeout设置为0表示关闭保持连接功能。设置为非0表示启动保持连接。这里和httpd不一样,没有单独的关闭或打开保持
连接的开关按钮。可选参数第二个,可以用来设置相应报文首的"Keep-Alive:timeout=time"的值。在Mozilla 火狐浏览器和Konqueror浏览器可以
识别这个"Keep-Alive: timeout=time";IE浏览器使用自己默认的60s,不受到这个参数控制(没有测试过)。
(2) keepalive_requests指令
语法结构:keepalive_requests number;
默认值:keepalive_requests 100;
上下文:http,server,location
注解:指令从0.8.0版本引入。在一次长连接上所允许请求的资源的最大数量,生产环境就可以使用默认值;
这个参数生效的前提是保持连接功能要开启的。
(3) keepalive_disable指令
语法结构:keepalive_disable none | browser ...;
默认值:keepalive_disable msie6;
上下文:http,server,location
注解:对哪种浏览器禁用长连接;
(4) send_timeout指令
语法结构:send_timeout time;
默认值:send_timeout 60s;
上下文:http,server,location
注解:向客户端发送响应报文的超时时长,此处,是指两次成功的写操作之间的间隔时长;客户端向服务端发送请求报文后,服务端会构建响应
报文给客户端发过去。如果客户端发送请求报文之后,突然离线或者其他原因导致网络异常,收不到服务端的响应报文。这个发送响应报文会有
一个超时时间,这个值就是用来设置这个超时时间。如果客户端在给定的超时时间内收不到响应报文,连接将会被关闭。
(5) client_body_buffer_size指令
语法结构:client_body_buffer_size size;
默认值:client_body_buffer_size 8k|16k;
上下文:http, server, location
注解:用于接收客户端请求报文的body部分的缓冲区大小;
默认,缓存区大小是2倍的内存页(4k)。如果是x86以及其他32位的平台,默认值为8K。如果是x86-64以及其他的64位平台,默认值为16K;超
出此大小时,其将被暂存到磁盘上的由client_body_temp_path指令所定义的位置(存磁盘性能就会受到影响了);
现在一般都是64位的平台。对于论坛或者允许用户上传的业务站点(允许用户上传巨大的内容或者允许用户使用PUT方法上传文件时),而且站点
所在服务器内存允许的话,这个值如果调大会提高站点性能。对于一个电商站点,可能POST方法提交的信息很少,注册提交的信息也很少,使
用默认值16K足以。
(6) client_body_temp_path指令
语法结构:client_body_temp_path path [level1 [level2 [level3]]];
默认值:client_body_temp_path client_body_temp;
上下文:http, server, location
注解:设定用于存储客户端请求报文的body部分的临时存储路径及子目录结构和数量;
请求并发很大,如果每个请求都允许上传资源,这个量级是很大的。所以无法用平面存储的思路,而是采取的分层存储机制。level1表示定义1
级子目录使用的16进制字符数量。1为表示16个1级子目录,2表示256个1级子目录。level2表示二级子目录使用的16进制字符数量。level3表示
3级子目录使用的16进制字符数量。
比如请求为:http://www.yanhui.com/images/default.jpg,对其做md5
执行命令:echo -n 'http://www.yanhui.com/images/day.jp'|md5sum,结果为32位16进制字符:
1abb41e927569466f4bec3575a08f2b6
md5算法为128位,上面32个字符为二进制的16进制表示形式,每个字符可以由4位二进制所表示。
正是这种机制,存储在磁盘上的文件是每一个连接请求的md5值。
比如设置:client_body_temp_path path 1 2 2;
上面案例表示的含义为,使用1位字符表示一级子目录,所以数量为2^4(2^3+2^2+2^1+2^0=15,二进制是1111,由于从0开始,所以结果要加1)=16个。使用2位字符表示二级子目录,也就是每一个一级子目录下面会创建256个二级子目录,所以此时拥有的所有二级子目录数量为
256*16=4096个。使用2位字符表示三级子目录,也就是每一个二级子目录下面会创建256个三级子目录,所以此时拥有的所有三级子目录数量为256*256*16=10485676(百万级别的了)。如果超过百万级别,可以把一级子目录数量设置为256位,所以三级子目录数量为256*256*256= 16777216(1千6百多万了)
以本例为例,临时文件存储可能是:/spool/nginx/client_temp/7/45/f2/ 00000123457
可以这样映射,不止nginx会这样做,其他类似的也会这样做:
16进制的数字;
client_body_temp_path /var/tmp/client_body 2 1 1
1:表示用一位16进制数字表示一级子目录;0-f
2:表示用2位16进程数字表示二级子目录:00-ff
2:表示用2位16进程数字表示三级子目录:00-ff
(7) types_hash_max_size指令
语法结构:types_hash_max_size size;
默认值:types_hash_max_size 1024;
上下文:http,server,location
注解:设置nginx内存中开辟的类型hash表的大小。
资源类型,内容类型(有个文件叫mime.types),nginx为了加速对某些内容的访问,mime.types的内容是直接被转入到内存中的,当客户端请求
一个资源之后,本地加载之后要立即分析这是什么资源类型,要怎么匹配,在内存中就知道这些内容类型了。我们要如何比较呢,难道一个一个
字符的比较吗?并不是,为了效率,内存中存储的是类型hash之后的结果。每次比较的时候,会把内容hash后与之前存储的hash内容做比较,
这种速度是非常快的。在内存中分配多少内存来保存这些hash值,这个types_hash_max_size就是用来定义这个大小。这里单位是否为字节或者项,不太确认,留个疑问,等将来学习深入后给出解答?
关于nginx的设置hash表的说明链接:
http://nginx.org/en/docs/hash.html
- 4、对客户端进行限制的相关配置
(1) limit_rate指令
语法结构:limit_rate rate;
默认值:limit_rate 0;
上下文:http, server, location, if in location
注解:限制响应给客户端的传输速率,单位值bytes/second(字节每秒)。值0表示无限制。这里要注意的是,限制是对每一个请求来限制的,
如果一个客户端同时打开了两个链接,总速率会是限制速率的2倍。也可以使用$limit_rate变量来指定限制的速率,在条件判断中可能用得到。
有个"X-Accel-Limit-Rate"首部值与速率限制相关。
(2) limit_except指令
语法结构:limit_except method ... { ... };
默认值:无
上下文:location
注解:限制客户端使用除了指定方法之外的方法;
支持的方法可以有:GET, HEAD, POST, PUT, DELETE, MKCOL, COPY, MOVE, OPTIONS, PROPFIND, PROPPATCH, LOCK, UNLOCK, 或
PATCH
(在ngx_http_access_http,ngx_http_auth_basic_module,ngx_http_auth_jwt_module模块中还支持其他方法)。GET方法会隐式允许HEAD方法。
案例:
limit_except GET {
allow 192.168.1.0/32;
deny all;
}
除GET和HEAD方法之外的方法,只允许192.168.1.0/32网段中的客户度端来使用,其他网段的客户端都不允许使用。
- 5、文件操作优化的配置
(1) aio指令
语法结构:aio on | off | threads[=poll];
默认值:aio off;
上下文:http, server, location
说明:是否启用aio功能。建议开启,可以减少我们访问文件被阻塞到io上的可能。可以通过threads来指定多少个线程池来配合
使用AIO功能,使用默认值就行。
(2) directio指令
语法结构:directio size | off;
默认值:directio off;
上下文:http, server, location
官方注解:
Enables the use of the O_DIRECT flag (FreeBSD, Linux), the F_NOCACHE flag (macOS), or the directio() function (Solaris), when reading
files that are larger than or equal to the specified size. The directive automatically disables (0.7.15) the use of sendfile for a given request.
It can be useful for serving large files:
directio 4m;
or when using aio on Linux.
当读取文件大于或等于(directio)指定的大小的时候。对于给定的请求,directive会自动关闭sendfile的功能。
这个部分,有人建议不要用。有人建议与aio一起使用,由于本身学术有限,不深入挖掘,待后续深入学习后回来补充。
可以参考:
https://www.cnblogs.com/youngerchina/p/5624462.html
https://yq.aliyun.com/articles/11243
https://www.ibm.com/developerworks/cn/linux/l-cn-directio/
https://blog.csdn.net/zhangxinrun/article/details/6874143
(3) open_file_cache指令
语法结构:open_file_cache off;
默认值:open_file_cache off;
上下文:http, server, location
说明:对于站点有大量文件被频繁范围,可以把文件的元数据信息存储到缓存中。此选项就是控制缓存文件元数据的。nginx可以缓存以下三种
信息:
(1) 文件的描述符,文件大小和最近一次的修改事件;
(2) 打开的目录结构;
(3) 文件查找错误,比如没有找到或者没有权限访问的文件的相关信息等。
该指令支持参数值可以有:max,inactive,off
max:可缓存项上限;这个值不能随意设置,要看自己内存允许不允许。达到上限后会使用LRU算法实现缓存管理;当缓存移除,就是超过这个
值的时候,LRU(the least recently used,最近最少使用)算法会把最近最少使用的缓存项删除。
inactive:缓存项的非活动时长,在此处指定的时长内(默认值60秒)未被命中的或命中的次数少于open_file_cache_min_uses指令所指定的次数
的缓存项即为非活动项;特别说明,非活动项的清理在缓存空间满之前会进行。
off:关闭缓存文件元数据的功能。
(4) open_file_cache_valid指令
语法结构:open_file_cache_valid time;
默认值:open_file_cache_valid 60s;
上下文:http, server, location
注解:缓存项有效性的检查频率;如果又想启用这种缓存的功能,内存空间又不够用,可以把这个检查的频率设置的快一点,即这个时间设置短
一点。
(5) open_file_cache_min_uses指令
语法结构:open_file_cache_min_uses number;
默认值:open_file_cache_min_uses 1;
上下文:http, server, location
注解:在open_file_cache指令的inactive参数指定的时长内,至少应该被命中多少次方可被归类为活动项;
(6) open_file_cache_errors指令
语法结构:open_file_cache_errors on | off;
默认值:open_file_cache_errors off;
上下文:http, server, location
注解:是否缓存查找时发生错误的文件一类的信息。例如第一次请求的文档为/images/hi/a.png,因为hi目录不存在,所以此资源查找失败,这个文件查找失败被缓存下来了。
说明:至于nginx的上面常见配置项涉及的举例,以及nginx的其他非核心模块(比如实现基于用户认证的访问控制,基于ip的
访问控制,nginx的状态页信息,nginx的访问日志控制设置,资源压缩控制、https协议实现、重写实现、防盗链实现等功能
模块),包括nginx的代理功能的实现模块(比如反代http,反代fastcgi),还包括代理4层协议以及负载均衡等功能,会在架构
基础知识总结2中详细注解。
二、linux集群
2.1、集群概述
2.1.1、单台主机所面临的问题和解决概述
不管是多么复杂的集群或者架构,无非都是从单台主机演变而来。单台计算机受限于本地的计算资源和存储资源以及IO资源等。以并发访问服务的模型来举例,单台主机所支持的并发数是有效的,这种有限性不仅仅受限于我们主机的硬件资源,而且还受限于并发服务编程模型当中所实现的机制。如果有基础的人,可能了解过IO模型的select,poll等阻塞的模型以及基于事件驱动模型实现的epoll模型。epoll这种可以实现单进程响应多个用户请求,从而大大解决了所谓的每一个请求都得需要一个进程来响应导致资源消耗比较大的应用场景。
对于磁盘IO来讲,可以使用AIO(异步IO),来让进程的请求发出以后直到对方准备并复制完成数据以后再接管资源,所以在磁盘IO方面又进一步解脱了并发服务编程模型当中的进程所需要承载的任务。即便如此,受限于我们的硬件,软件等资源,单台服务器的响应能力依然是有限的。比如基于httpd的prefork模型,单台主机的并发访问能力支持并发到1000或2000个,以及后边引入的更好的,更新设计的nginx,支持并发服务请求到1万或2万个。但是,一旦并发连接请求依然超过这个数值之后要如何处理,对于我们的应用来讲,无非就是这样的模型或模式,一旦我们的业务需求所依赖到的硬件资源超过我们的硬件资源所承载的能力,我们通常会遵循以下几个思路来考虑:
思路一:
这种思路主要是对机器所处环境或者应用相关的参数做调整;对单台主机的请求做优化。比如增加相关的空间,调整内核中相关的参数、并发连接数、内核内存资源的使用量等。但是内存资源总会有一个限制,也总有耗尽的一刻,一旦资源枯竭,我们也不能通过调整的手段来解决或来获取性能上的提升的之后,那就只有下面的另外两种方案来解决了。
思路二:
这种思路主要是靠提高主机配置或者新增主机来完成;这种思路也有两个方案,分别是:
方案a:换更好性能,更好配置的计算机。比如原来2万块钱一台的主机,现在花20万块钱来买一台更好的替代。应用主机的向上扩展(scale up)。
方案b:如果单台主机的并发处理及响应能力不够或不足以支撑用户请求的时候,如果这些用户请求是可以并行隔离的,彼此间没有什么关系,那就意味着一台主机的压力可以被分散出去,不是一个大请求的很多子任务而是各自都是独立的请求,各自都是独立的需求,那这种情况之下,我们可以把它分隔或分散开来。于是,可以多加一台或多加几台主机来实现,这种应用实现叫做应用主机的向外扩展(scale out)。这种向外扩展的思想是组合多台主机来完成一个任务。这一个任务其实是可以被分隔或分散成许多个任务的任务。所以这种解决方案,就叫做计算机的cluster(群集,集群),表示聚集在一起的一类事物统称为cluster。
2.1.2、集群面临的问题和解决思路
多台主机会把任务分隔或分散出去,这种集群通常称为负载均衡集群,简称LB Cluster(load balancing cluster).
我们考虑考虑一个主要的问题,当我们把用户的请求给分散开来的时候,看上去是一件容易的事,我们可能一直假设有一个前提,这多个请求或者我们要处理的事情可以被分散或者分割成许多小请求来处理。对于我们的web服务来讲,的的确确每个请求都是独立的,这没有问题。对于我们其他的服务,比如openssh,mysql等等也没有问题,每一次的请求都是一个独立的可分割的请求。事实上也是能够分散的。
-
问题1引入
但是这里会有一个问题,如果说分散用户请求容易而且没有问题或者这个问题容易解决。但是要考虑另一个问题,有些应用是需要追踪用户的状态信息的,比如现在各种的动态的站点,一个电商站点或者其他类似站点,一个用户在我们的站点浏览了哪些网页或者浏览了哪些商品,在用户下次来访问时,我们期望在那个栏上显示用户已浏览的商品。还有用户向购物车添加了哪些商品,希望在用户刷新以后或者用户重新登录或者用户隔几分钟或者隔很长时间以后再来访问的时候,用户要依然能看到用户此前加入购物车中的商品。有些人可能会好奇,这种问题还是一个问题吗,这个居然会成为问题吗,答案是会成为一个问题; -
用户session
对于只有单台服务器时,一般来讲,我们动态应用程序,比如像jsp或php,它们是需要去追踪用户身份。追踪完以后,能够把每一个用户加入到当前主机上的活动,通过一个内存中的记录信息-(会话),来记录它,这个通常称为用户的session,是一个很小的数据结构,它里面记录了一个用户在此站点上所作出的活动,比如像浏览的商品,加入购物车中的商品,收藏的商品等等,都应该予以记录的。从而能使得,当用户向购物车中加入多个商品并点击付款的时候,这个商品还都在这台主机之上,这没有任何问题,因为我们只有单台主机。
如果这个事情被分散或分隔到多台主机了,问题所在呢。http请求,即便我们使用长连接,它的有效时长通常也只不过是几十秒的时间,当用户第一次发出请求的,碰巧我们给它分散到了第一台主机之上,过了几分钟以后,用户才看完整个商品,看完之后,用户决定要加入购物车之后,依然在这台主机之上,这是OK的。再过了几分钟,观看另外一件商品的时候,很有可能,这个用户的请求被分发给另外一台主机的,之所以如此,我们刚才说明http协议本身是无状态的,而第二,我们有多台主机的集群是需要把每一个用户的请求分散到多台不同的主机之上去的,那么这个用户的身份将难以被追踪。所以即便请求本身可以被分割成多个任务,那么来自于同一个用户的多个请求是依然有可能需要被服务器追踪识别才可以。这是现代站点所面临的必然问题。这也只是其中的问题之一。 -
问题2引入
再想一个问题,有经验或者有自己测试过的人可能曾经部署wordpress了,如果部署过wordpress,假设第一个站点使用的是wordpress,现在面临请求难以在单台主机上处理,于是分散到第二台主机之上,第二台主机之上也有一个wordpress。wordpress是允许用户上传图片的,这个图片上传之后保存在什么地方呢。一般来讲,在wordpress里面有一个upload这样的一个路径,用来专门保存用户上传的图片资源并在于本地生成一个URL,作为它的单一访问路径资源获取节点。想象一下,如果用户第一次登录的时候,被分发到第一台主机之上,并上传了图片。第二次再次请求查看这么一个文章时,它的请求却被分发到第二台主机之上,那么他的信息还有吗?很显然,信息就没了。所以你会发现,即便我们的请求是分离的,但是对于我们的业务本身来讲,考虑到我们的请求是允许写操作的,那么很有可能某一次的用户请求的写会被某个服务器本地所承载,这样就会导致同集群中的承载同类任务的其他节点获取不到这样的请求了或者无法提供此种资源,那么这依然会是一个问题。那么怎么解决?我们只能用多台服务器都通同时访问到的共享机制来解决,比如nis中的实现访问,NFS,CIFS。 -
问题2解决分析
可以让两个wordpress对应的上传(图片)资源的目录路径是一个挂载的共享的后端的NFS或CIFS存储,那么因此用户通过第一台服务器上传的,通过第二台服务器也可以看到。这是一种解决思路。还有一种解决思路,假设有多个用户请求,虽然说每一个请求都可以孤立,可以隔离开来,但是考虑到同一个用户的请求,我们可以需要反复被追踪被识别,我们应该实现的是,对同一个用户的请求,我们始终给它发往同一个主机。对于同一个用户请求发往同一个主机,但是还是那句话,这最终只能解决用户自己上传的内容被自己看到。当其他的用户被分配到另外一个主机之上,那么另外的用户就看不到用户发的帖子,会造成有一部分用户看得见,一部分用户看不见。为了避免这个问题,共享存储也依然是必须的。 -
其他问题引入和解决:
对于我们的wordpress来讲,它所需要存储的数据不只有我们上传的图片,我们上传的文章中的那些标题,正文的文字放哪儿去了呢,一般是存在mysql或mariadb这样的db中去了,而这个db是不是应该是某一台主机本地的呢,如果是依然面临我们刚才上文所说的那个问题。用户发这个文章,图片的问题解决了。当用户被分配到第二服务器,图片的问题解决了,用户却看不到之前用户发的文章。因为按照这个设想,文章内容被存在第一台服务器的数据库当中的。好在,数据库本来就是用来提供数据共享存储服务的,因此对于访问的文章的标题,正文等,也应该被放在一个共享的存储当中,这个共享存储设备,就是我们的数据库管理系统。 -
图片问题
好像对于一个图片,我们重来都没有做过或者想不通怎么做,才能把它存储到我们这个数据库管理系统当中,能不能做呢。可以这样实现,存图片的二进制编码,问题是存进去之后如何取出来呢,更何况的很多查看图片的工具,它没办法去联系数据库。 -
数据的组织方式
通俗来讲,数据的组织方式有以下三种:
(1) 结构化的
(2) 半结构化的
(3) 非结构化的
结构化数据:
一般而言,对于结构化的并要求数据强一致的数据,它们通常放在关系型数据库并支持事务的存储引擎上,例如mariadb的innodb存储引擎。那么,如果是存储文件的,比如图片,MP3等音乐文件,我们一般把它们放在文件系统的结构之上,它们一定是文件系统结构而不能被进一步抽象成为所谓的数据管理模型自己专有的结构;
半结构化的数据:
半结构化的数据,一般放在noSQL中或文件系统之上。比如json格式的数据,通常被组织成document storage(文档存储),比如ELK中的Elasticsearch ,它是一个著名的分布式的document storage(文档存储),它们基于json格式去组织格式。json是一种著名的轻量化的半结构化数据的存储逻辑。
非结构化的数据,就不说了。
-
web服务的三个层面
突然发现,按照上面分析提到的,这样会多了许多需求。这个需求以web服务来讲,它分散于三个层面:
第一:
用户的活动信息,自己的活动信息。在这个层面上,多台主机如果都能够处理用户需要的话,一个用户的活动在第一台主机上活动一部分,在另外一台主机上活动一部分,那么我们的服务器将可能很难完全或完整的追踪一个用户的活动信息或整体活动信息。比如他浏览了哪些网页,他加入到购物车中的商品有哪些等等;
第二:
如果服务器允许写操作,它不仅仅能浏览网页,还能发起交易,付款等。比如我们提到的文章类的站点,比如wordpress,用户有可能是需要发表文章的,文章中可能还要插入图片的,对于这种应用,它所带来的不关是交易本身了,甚至可能是生成我们服务上所展示的内容的或者所展示的页面的。那么对于这种需求来讲,我们如果允许用户上传时,存储在服务器主机的单台服务器的主机本地,势必会导致用户通过其他主机看不到,不关是无法追踪用户活动的问题了。连请求的同一个内容,你只能在不同的服务器上所看见,那么这样的负载均衡事实上 是不成立的。服务器不一样,均衡到不同的主机之上能得到的是不同的内容,这事实上对于用户来讲是有失公允的。那么后两个问题,我们已经有了简单解决方案,比如如果允许用户写操作,文件类的内容可以放在共享的存储NFS或者CIFS之上。如果是所谓的结构化的数据,我们可以把它放在mariadb这样的关系型数据库存储系统之上。 -
cookie解决思路的引入
上面分析的过程,我们之前提到的第一个问题还没有解决。刚才说过了,用户的活动身份行为怎么处理。第一个用户在第一台服务器上浏览了网页,用户的活动行为是临时产生,也通常是临时有效,不会永久有效,而且这种活动行为也不会生成网页数据本身,只是作为一个简单的活动评判或者叫用户行为的追踪。一般来讲,我们不可能把它存储在文件系统之上或者关系型数据库当中。因此,既然如此,每一台服务器是如何追踪用户身份呢? 我们可以基于cookie机制来追踪。
一个用户第一次来访问我们的服务器的时候,比如把它分发到第一台服务器上,这个服务器会给它生成一个随机的,唯一的ID,并把它发给客户端。客户端会把它保存在浏览器的缓存路径下或者存储路径下。这个内容会保存在一个文件中,这个文件有它的适用范围,比如它只适用于访问某个域名下的哪一个URL时来使用。通常还有它的有效期,这就叫用户的cookie。那么用户随后再一次的访问这个服务器或者这个域名时,都会加上这个身份,都会自动带上这么一个数据。所以服务器一看到它带上这个数据,就会识别这个用户的身份了。但是,只识别它的身份,它还不能追踪用户的活动。比如用户在当前服务器上浏览过多少商品,如何追踪? -
胖cookie和瘦cookie
传统方式,每一个用户在每一个站点上访问的所有行为,都一 一被记录在这个cookie文件中,当客户端本地保存,而后客户端每一次访问的时候,都会带着这个信息去服务端。这是一种胖cookie机制(fat cookie)。但是fat cookie会有很大的风险,我们的单台主机之上,都有所谓的打着各种名义的或者以安全为名的软件程序,它拥有你整个系统的最高控制权限,它可以轻易的扫描你的浏览器下的每一个cookie上的所有数据,从而获知用户的访问行为。所以说胖cookie这种机制有可能会泄露用户的隐私的。而且更重要的是,有些站点不希望去泄露用户的隐私。比如某东的站点不希望用户浏览商品的行为被某宝的软件获取了,很显然,对于大家来讲可能是一种损失。因此,他们也不期望把这种用户的行为记录到客户端,避免别人来获取到这些信息。因此现在都不再基于胖cookie来实现,而是每一个cookie仅用于追中用户的身份。
对于用户的所有的行为,在站点上,对应站点应用程序的进程的内部,都会有自己的内存使用空间。会在这个进程的内存空间的区域中为每一个用户分配一个数据结构,通常是hash类型的。每一个用户在当前站点上做了什么样的访问行为,它都会有一个单独的数据记录位置。这里记录用户的访问,并且记录了是哪一个用户的访问,它会和你cookie的值所绑定一起。所以用户此后再访问,只要带来了cookie,我们识别了这个用户,就会把这个用户关联到对应的数据结构的数据记录之上,这个数据记录,通常叫做session,服务端的session,服务端的会话。那么,对于一个繁忙的站点来讲,服务端的session可能会很多个。比如3千个并发可能是10万个用户发起的,那么这里有可能需要记录10万个session。 -
session 以及session的解决方案
这样一来,用户第一请求,被分配到第一台服务器上,session中记录了用户的行为,这个session数据保存在第一台服务器上,那么用户再请求,如果被分发到第二台服务器上,那么他的session信息就没了。第二台服务器上是没有这个用户的配置相关的这些数据的。虽然你能看见那个网页,看见那个商品,我们也能够往购物车中加入,但是此前你加入的那个行为却追踪不到了。这对于用户来讲,可能会觉得莫名其妙,这对于负载均衡来讲,这种机制就成为有状态的了。我们需要去追踪并记住用户的状态。这个该如何解决呢?一般而言,这种记录会有三种方式。
(1) 方法一,session粘性(会话粘性)
做用户绑定,只要来自于同一个用户的访问,始终发给同一台服务器,不往其他服务器上发。但是DNS好像没有这种能力,DNS的A记录是一个域名对应一条记录,并且是轮循发送的。对于同一个域名来讲,如果有多条A记录,它是没办法始终把同一个用户的请求绑定到某台主机之上,但有些是可以实现。那么该如何识别一个请求是来自于同一个用户呢,有两个方案。
方案一,根据网络层的IP地址来识别,只要来源的IP都相同,我们就当这是同一个用户;
方案二,对于web服务来讲,可以使用cookie来识别,用户的请求中隐含了cookie,只要他的请求是明文的,我们就能看到他的cookie,甚至是密文的也没关系,在负载均衡器上,我们可以卸载ssl请求,也能做到看见那个cookie。只要cookie是同一个,我们就可以当作它是同一个用户的请求。
简单的可以分析一下,方案二控制更加精准。对于方案一而言,对于有过网络基础的人可能知道,SNAT是网络源地址转换。对于大部分公司请求互联网,可能都是通过同一个ip地址去请求访问互联网,但是我们服务器端如果基于方案一来判断用户,就只能把它识别成同一个用户,事实上,压根不是同一个用户。如果我们能基于cookie来识别的话,无论你的源IP是什么,只要你的cookie不同,都被识别成不同的用户。所以方案二的粒度更加精细更加精准了。不管怎么来讲,这种方法都叫做会话粘性,由于实现把一个会话绑定在一个主机之上的的实现方式。
但是这个方法(session 粘性) 有一个缺陷,如果把一个用户的请求始终绑定到一台主机之上就意味着一组会话在单独一台服务器上了,一旦这个服务器挂了,除非做了会话持久,等我们的服务器启动,这个用户还能访问,这可能是3或5分钟之后的事情了,这个用户的请求并不能够通过被分发到其他主机之上以解决用户等待的问题,那么这依然会是一个比较大的缺陷,于是就有了方法二来实现;
(2)方法二, session复制集群(会话复制集群)
每一个主机的内存中都维持一组会话信息。那么,每一个服务器的本地会话信息都传给其他服务器一份,那么集群中的每一台服务器就都拥有一个完整的会话。可以把两台服务器构建成一个会话集群,从而让每一台主机的每一个本地的会话都传递给同集群中的其他主机。这个时候都不用绑定用户身份了,主机可以随意被调度,随意被轮询。这里依然会有一个很重大的问题,每一台服务器都保存了整个集群中所有会话的信息。假设你集群有10万个用户访问,每一台服务器上都要保存10万个session,这得需要多大的资源空间,更重要的是,如果你的服务器本身很繁忙,session会经常因为用户的活动行为而被更新,大量的session信息会在集群中传来传去,那么服务器的带宽就消耗的差不多了,如果有专用接口了的话,服务器的资源也会被消耗的差不多。所以这种方法不适用于太大规模的集群。因为这个方法二,有缺陷,所以有来方法三;
(3) 方法三,共享存储(session server,会话服务器)
每一台服务器所生成的session不保存在自己的内存空间而保存在一个内存服务器中。为什么不保存在自己的内存空间中而保存在内存服务器,是因为要考虑到性能的问题。内存存储服务器能够实现基于内存向其他服务器提供所谓的存储功能,所以每一台服务器上的进程需要保存会话和使用会话时,都到这个内存存储服务器上去获取,每一次更新也都给你更新到这个内存存储服务上去。那么,大家访问的是同一组内存存储服务器,所得到的内容都应该是一样的。这个机制叫session server,session服务器。
PS:上面每一个环节可能解决起来很爽快,但是每一个节点都可能事关全局。比如我们的文件节点挂了,得不到图片数据;mysql挂了,通过任何一个服务器都得不到这个存储的数据;session也一样。通常把这些事关全局的,一台主机,一个服务,一个节点,一个事物故障会导致整个集群服务不可用的硬节点称作为单点故障所在(Single Point Of Failure,SPoF).既然是单点故障,我们就要对它做其他的解决方案。
2.2、linux集群类型
-
何为集群?
通俗来讲,为计算机集合,为解决某个特定问题组合起来形成的单个系统。也可以理解为集群(cluster)表示聚集在一起的一类事物统称。 -
linux集群类型?
(1) 负载均衡集群
负载均衡集群的英文表示为 Load Balancing,简称为LB。所以我们通常会把负载均衡集群叫做LB集群或者LB cluster。LB 集群主要提供和节点个数成正比的负载能力,这种集群很适合提供大访问量的Web服务。负载均衡集群往往也具有一定的高可用性特点。
常见硬件实现有:F5 Big-IP,Citrix Netscaler,A10等;
常见软件实现有:LVS,nginx,haproxy,ats,perlbal,pound等;
(2) 高可用集群
高可用集群的英文表示为High Availiablity ,简称HA。所以我们通常会把负载均衡集群叫做HA集群或HA cluster。HA集群一般是指当集群中有某个节点失效的情况下,其上的任务会自动转移到其他正常的节点上。还指可以将集群中的某节点进行离线维护再上线,该过程并不影响整个集群的运行。设计思想就是要最大限度地减少服务中断时间。
高可用集群一般是通过系统的可靠性(reliability)和系统的可维护性(maintainability)来衡量的。通常用平均无故障时间(MTTF)来衡量系统的可靠性,用平均维护时间(MTTR)来衡量系统的可维护性。因此,一个高可用集群服务可以这样来定义:
A=MTBF/(MTBF+MTTR)
公式涉及的结果和简称说明:
MTTF(Average fault-free time):平均无故障时间;
MTBF(Mean Time Between Failure):平均故障间隔时间;
MTTR(Mean Time to Repair):平均恢复时间;
A表示这个结果,A的值在区间(0,1)之间。几乎不可能有值为1的集群,而且如果值为0,集群将无任何意义。
(0,1):90%, 95%, 99%, 99.5%, 99.9%, 99.99%, 99.999%, 99.9999%
一般高可用集群的标准有如下几种:
99%:表示 一年不在线时间不超过87小时;
99.9% :表示一年不在线时间不超过8.7小时;
99.99%: 表示一年不在线时间不超过1小时;
99.999% :表示一年不在线时间不超过3-5分钟;
大部分的集群,多数控制在3个9或者4个9。
(3) 高性能集群
高性能集群英文为High Performance,简称为HP集群或HP cluster。比如使用超级计算机或超算计算机这样的应用。利用分布式系统来组织(包括分布式存储和分布式计算)。这一类一般是科学研究或者极大规模才用得到,我们这里了解一下即可。
2.3、linux集群系统扩展方式
linux集群系统扩展的两个大的方向分为纵向扩展和横向扩展:
Scale UP:纵向扩展或者叫向上扩展(用性能更好的主机),在我们第一章的概述部分就有提到这个概念;
Scale Out:横向扩展或者叫向外扩展(组合多台主机来完成单个任务,将任务分散处理,简单地说就是加机器),在我们第一章的概述部分就有提到这个概念;
PS:一般互联网企业都是通过横向扩展的思路来解决问题,当然也可能有部分解决思路是使用的第一种。我们上面一小节中提到的高性能集群就是上述的第一种扩展。
2.4、linux集群的调度方法
2.4.1、静态调度算法
静态调度算法,仅根据算法本身进行调度。包括:
(1) 轮询(RR)
轮询(roundrobin),简单来说就是调度器将外部请求轮流分配到集群中的节点中;
(2) 加权轮询(WRR)
加权轮询(Weighted RR),调度器根据事先设置的权重来分配外部请求到集群中的节点。
(3) 原地址哈希(SH)
原地址哈希(Source Hashing),主要是实现会话粘性(session sticky),是基于原IP地址哈希。将来自于同一个IP地址的请求始终发往第一次挑中的后端real server(RS),从而实现会话绑定。
(4) 目标地址哈希(DH)
目标地址哈希(Destination Hashing),将发往同一个目标地址的请求始终转发至第一次挑中的RS,典型使用场景是正向代理缓存场景中的负载均衡.
2.4.2、动态调度算法
动态调度算法,主要根据每后端real server 当前的负载状态及调度算法进行调度。
(1) 最少连接(least connections,LC)
调度器通过“最少连接”调度算法动态的将网络请求调度到已经建立连接最少的服务器上,如果集群的真实服务器具有相近的系统性能,采用“最小连接”调度算法可以更好地均衡负载。负载满足以下公式:
Overhead=activeconns*256+inactiveconns
(2) 加权最少连接(Weighted least connections,WLC)
在集群系统中的服务器性能差异较大的情况下,调度器采用加权最小连接的调度算法来优化负载均衡,具有较高权值的服务器将承受较大比例的活动负载连接。负载满足以下公式:
Overhead=(activeconns*256+inactiveconns)/weight
(3) 最短延迟调度(Shortest Expection Delay,SED)
在WCL的基础上改进,Overhead=(ACTIVE+1)*256/加权,不再考虑非活动状态,把当前处于活动状态的数目+1来实现,数目最小的接受下次请求,+1的目的是为为了考虑加权的时候,非活动连接过多的缺陷,当权限过大的时候,会导致空闲服务器一直处于无连接的状态。负载满足以下公式:
Overhead=(activeconns+1)*256/weight
(4) 用不排队/最少队列调度(Never Queue,NQ)
无需列队,如果有台real server的连接数为0,就直接就分配过去,不需要进行sed运算,保证不会有一个主机很空闲,在SED的基础上不论增加几个,第二次一定调度到下一台real server,不考虑非活动连接,才会用NQ,SED要考虑活动状态连接,对于DNS的UDP不需要考虑非活动连接,而http的处于保持状态就需要考虑非活动连接给服务器的压力。
(5) 基于局部的最少连接(Locality-Based Least connections,LBLC)
基于局部性的最少连接调度算法是针对目标IP地址的负载均衡,目前主要运行在Cache集群系统。该算法根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用而且没有超载,将请求发送到该服务器,若该服务器不存在,或者该服务器超载且有服务器处于一半的工作负载,则用最少连接的原则选出一个可用的服务器,将请求发送到该服务器。
(6) 带复制的基于局部性最少连接(LBLC with Replication)
带复制性的基于局部性最少连接调度算法也是针对目标IP地址的负载均衡,目前主要用在Cache集群系统。它和LBLC算法不同的是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP到一台服务器的映射,该算法根据一请求的目标IP地址找出该目标IP地址对应的服务器组,按照最小连接原则服务器组中选一台服务器,若服务器没有超载,将请求发送到该服务器,若服务器超载,则按照最小连接原则从这个集群中选出一台服务器,将该服务器加到服务组中,将请求发送到该服务器,同时当该组服务器有一段时间没有被修改,将最忙的服务器从服务组删除,以降低复制的程度。
三、LVS应用
3.1、lvs功能的实现
lvs是附加在netfilter的input钩子上的一段程序实现,简单理解就是工作在INPUT链上,lvs的工作也是基于规则来实现的,由ipvsadm工具来配置策略或规则。下图是基于之前iptables框架图的几个工作链的实现逻辑,然后配合上lvs部分。由于netfilter的过滤功能要经过INPUT链,所以lvs和这个是冲突的,比如你把通过INPUT链的报文先通过INPUT链上的规则DROP掉后,lvs上定义的集群服务规则是无法有效工作的,一般如果要想使用lvs,不会配合netfilter防火墙的过滤功能。

图上标记含义:
a:PREROUTING链或prerouting钩子
b:INPUT链或input钩子
c:FORWARD链或forward钩子
d:INPUT或input钩子
e:POSTROUTING或postrouting钩子
x:路由标志;
y:路由标志;
L:lvs程序附加处理;
-
lvs的ipvs和ipvsadm:
lvs的实现逻辑由两部分组成,一个是ipvs,一个是ipvsadm。其中ipvs是工作于内核空间的netfilter的input钩子之上的框架,而ipvsadm是用户空间的命令行工具,规则管理器,用于管理集群服务及real server。 -
ipvsadm命令行工具用法
ipvsadm用法:
ipvsadm主要管理两类事务,一类是集群服务,一类是集群服务上的realserver;
先定义集群服务,也就是虚拟(集群)服务,以后我们就叫集群服务。然后支持对这个添加的集群服务删、改以及
查询,而且集群服务可以定义多个。
先定义了集群服务,然后我们可以在集群服务的基础上新增各real server,然后可以对对应集群服务增、删、
改、查各realserver。
[yanhui@director ~]$ sudo ipvsadm --help
ipvsadm v1.27 2008/5/15 (compiled with popt and IPVS v1.2.1)
Usage:
ipvsadm -A|E -t|u|f service-address [-s scheduler] [-p [timeout]] [-M netmask] [--pe persistence_engine] [-b sched-flags]
ipvsadm -D -t|u|f service-address
ipvsadm -C
ipvsadm -R
ipvsadm -S [-n]
ipvsadm -a|e -t|u|f service-address -r server-address [options]
ipvsadm -d -t|u|f service-address -r server-address
ipvsadm -L|l [options]
ipvsadm -Z [-t|u|f service-address]
ipvsadm --set tcp tcpfin udp
ipvsadm --start-daemon state [--mcast-interface interface] [--syncid sid]
ipvsadm --stop-daemon state
ipvsadm -h
Commands: #命令
Either long or short options are allowed.
--add-service -A add virtual service with options,#新增一个集群服务
--edit-service -E edit virtual service with options,#修改一个集群服务
--delete-service -D delete virtual service,#删除一个集群服务
--clear -C clear the whole table #清空所有
--restore -R restore rules from stdin #从标准输入中恢复(集群)规则,可以利用bash重定向特性把一个保存了集群规则的文件加载到内存中
--save -S save rules to stdout #保存(集群)规则到标准输出,可以利用bash重定向特性写入到一个文件
--add-server -a add real server with options #新增real server
--edit-server -e edit real server with options #修改real server
--delete-server -d delete real server #删除real server
--list -L|-l list the table #查看集群服务和查看real server
--zero -Z zero counters in a service or all services
--set tcp tcpfin udp set connection timeout values
--start-daemon start connection sync daemon
--stop-daemon stop connection sync daemon
--help -h display this help message
Options: #选项
--tcp-service -t service-address service-address is host[:port] #定义tcp协议集群服务或real server的服务地址(host加端口);
--udp-service -u service-address service-address is host[:port] #定义udpp协议集群服务或real server的服务地址(host加端口);
--fwmark-service -f fwmark fwmark is an integer greater than zero #防火墙标记,它是一个大于0的整数;
--ipv6 -6 fwmark entry uses IPv6
--scheduler -s scheduler one of rr|wrr|lc|wlc|lblc|lblcr|dh|sh|sed|nq, #定义集群服务的调度方法。rr轮询;wrr加权轮询。
the default scheduler is wlc.
--pe engine alternate persistence engine may be sip,
not set by default.
--persistent -p [timeout] persistent service #设置持久连接超时时长
--netmask -M netmask persistent granularity mask
--real-server -r server-address server-address is host (and port)
--gatewaying -g gatewaying (direct routing) (default) 默认值。表示dr类型(gateway)。
--ipip -i ipip encapsulation (tunneling) ipip,tun类型
--masquerading -m masquerading (NAT) 地址伪装,nat类型
--weight -w weight capacity of real server #设置rs服务器的权重值
--u-threshold -x uthreshold upper threshold of connections
--l-threshold -y lthreshold lower threshold of connections
--mcast-interface interface multicast interface for connection sync
--syncid sid syncid for connection sync (default=255)
--connection -c output of current IPVS connections #输出当前IPVS的活动链接状态
--timeout output of timeout (tcp tcpfin udp)
--daemon output of daemon information
--stats output of statistics information #输出统计数据
--rate output of rate information #显示速率数据
--exact expand numbers (display exact values) #精确显示计数器的值
--thresholds output of thresholds information
--persistent-conn output of persistent connection info
--nosort disable sorting output of service/server entries
--sort does nothing, for backwards compatibility
--ops -o one-packet scheduling
--numeric -n numeric output of addresses and ports #数字格式显示地址和端口,不会反解(反解ip会解析成主机名,ip会解析成协议或服务)
--sched-flags -b flags scheduler flags (comma-separated)
内核中已经编译进来ipvs的功能模块,简单查看一下:
[yanhui@director ~]$ ls -l /boot/config-3.10.0-229.el7.x86_64
-rw-r--r--. 1 root root 123838 Mar 6 2015 /boot/config-3.10.0-229.el7.x86_64
[yanhui@director ~]$ grep -i 'ipvs' -C 5 /boot/config-3.10.0-229.el7.x86_64
......省略
CONFIG_NETFILTER_XT_MATCH_IPVS=m
......省略
# IPVS transport protocol load balancing support #IPVS支持的协议
#
CONFIG_IP_VS_PROTO_TCP=y
CONFIG_IP_VS_PROTO_UDP=y
CONFIG_IP_VS_PROTO_AH_ESP=y
CONFIG_IP_VS_PROTO_ESP=y
CONFIG_IP_VS_PROTO_AH=y
CONFIG_IP_VS_PROTO_SCTP=y
#
# IPVS scheduler #IPVS调度方法
#
CONFIG_IP_VS_RR=m
CONFIG_IP_VS_WRR=m
CONFIG_IP_VS_LC=m
CONFIG_IP_VS_WLC=m
--
CONFIG_IP_VS_SH=m
CONFIG_IP_VS_SED=m
CONFIG_IP_VS_NQ=m
#
# IPVS SH scheduler
#
CONFIG_IP_VS_SH_TAB_BITS=8
#
# IPVS application helper
#
CONFIG_IP_VS_FTP=m
CONFIG_IP_VS_NFCT=y
CONFIG_IP_VS_PE_SIP=m
在要模拟成director主机上安装ipvsadm即可:
[yanhui@director ~]$ sudo yum info ipvsadm
Loaded plugins: fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.cn99.com
* epel: mirrors.tuna.tsinghua.edu.cn
* extras: mirrors.shu.edu.cn
* updates: centos.ustc.edu.cn
Installed Packages
Name : ipvsadm
Arch : x86_64
Version : 1.27
Release : 7.el7
Size : 75 k
Repo : installed #我这里是已经安装了的
From repo : base
Summary : Utility to administer the Linux Virtual Server
URL : https://kernel.org/pub/linux/utils/kernel/ipvsadm/
License : GPLv2+
Description : ipvsadm is used to setup, maintain, and inspect the virtual server
: table in the Linux kernel. The Linux Virtual Server can be used to
: build scalable network services based on a cluster of two or more
: nodes. The active node of the cluster redirects service requests to a
: collection of server hosts that will actually perform the
: services. Supported Features include:
: - two transport layer (layer-4) protocols (TCP and UDP)
: - three packet-forwarding methods (NAT, tunneling, and direct routing)
: - eight load balancing algorithms (round robin, weighted round robin,
: least-connection, weighted least-connection, locality-based
: least-connection, locality-based least-connection with
: replication, destination-hashing, and source-hashing)
如果没有安装,执行yum安装以下即可:
sudo yum install ipvsadm
3.2、lvs四种集群优点和使用场景
为了更好的理解lvs集群,需要了解一下关键的术语:
vs:Virtual Server, Director, Dispatcher, Balancer。调度器,负载均衡器,分发器或者叫虚拟服务器;
rs:Real Server, upstream server, backend server。真实服务器、负载均衡服务器,后端服务器
CIP:Client IP, VIP: Virtual serve IP, RIP: Real server IP, DIP: Director IP。客户端IP,虚拟IP,真实IP,调度器IP。
CIP <--> VIP == DIP <--> RIP
请求客户端ip,我们叫客户端主机,客户端主机的接口叫客户端ip(简称CIP);
虚拟服务器面向客户端一侧的接口叫虚拟服务器ip(简称VIP)。Director主机用于与后端主机通信的,
此时,它就扮演了一个调度器,面向RS一侧的接口叫调度器ip(简称DIP);
每一个Real Server的IP简称RIP。
如图所示:
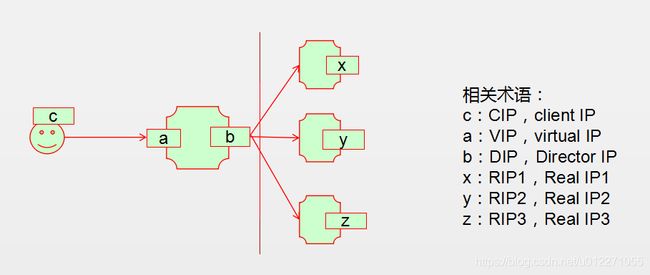
lvs集群的可以分为以下四类:(比较重要,要能通俗讲解)
lvs-nat:修改请求报文的目标IP(和目标端口);多目标IP的DNAT;
lvs-dr:操纵封装新的MAC地址;(不会修改请求报文的源IP,目标IP,源端口以及目标端口)
lvs-tun:在原请求IP报文之外新加一个IP首部;(原来的一级源IP,目标IP。现在加了一级,实现了两级IP首部,这种叫基于IP来运载IP,所以和隧道很相似,所以叫隧道模型)
lvs-fullnat:修改请求报文的源和目标IP(以及源端口和目标端口);
如果按照请求报文和响应报文经过director分类:
-
请求报文和响应报文都经过Director
lvs-nat和lvs-fullnat
lvs-nat:关键要点,RIP的网关要指向DIP;
lvs-fullnat:关键要点,RIP和DIP未必在同一个网络,但是要能通信; -
请求报文要经过Director,但响应报文由RS直接发往client
lvs-dr和lvs-tun
lvs-dr:关键要点,通过封装新的MAC首部实现,通过MAC网络转发;
lvs-tun:关键要点,通过在原IP报文之外封装新的IP报文实现转发,支持远距离通信。
(1) lvs-nat
特性:
多目标IP的DNAT,通过将请求报文中的目标地址和目标端口修改为某挑出的RS的RIP和PORT实现转发
(1)RIP和DIP必须在同一个IP网络,且应该使用私网地址;RS的网关要指向DIP;
(2)请求报文和响应报文都必须经由Director转发;Director易于成为系统瓶颈;(请求报文通过以GET方法居多
所以请求报文一般很小。但是响应报文要附带请求的数据,所以会很大)
(3)支持端口映射,可修改请求报文的目标PORT;
(4)vs必须是Linux系统,rs可以是任意系统;
优点:配置简单,且节省IP。只需要在调度器上配置一个公网IP即可。支持端口映射,即用户请求的端口和RS端
口可以不一致;
缺点:所有请求和响应都要经由调度器,并发量大时会成为集群瓶颈。一般后端RS节点保持在10-20个(没有实际
测试过,具体不知道。对于超大并发的场景,lvs的nat模型结构可想而知前段调度器压力);
使用场景:由于配置简单,节省IP的特点,一般用在并发量不大的中小企业。
(2) lvs-dr
Direct Routing,直接路由;
通过为请求报文重新封装一个MAC首部进行转发,源MAC是DIP所在的接口的MAC,目标MAC是某挑选出的RS的RIP所在接口的MAC地址;源IP/PORT,以及目标IP/PORT均保持不变(不支持端口映射);
Director和各RS都得配置使用VIP;
(1) 确保前端路由器将目标IP为VIP的请求报文发往Director:
(a) 在前端网关做静态绑定;(不适用)
(b) 在RS上使用arptables;
(c) 在RS上修改内核参数以限制arp通告及应答级别;
arp_announce
arp_ignore
(2) RS的RIP可以使用私网地址,也可以是公网地址;RIP与DIP在同一IP网络;RIP的网关不能指向DIP,以确保响应报文不会经由Director;
(3) RS跟Director要在同一个物理网络(要基于MAC地址进行报文转发,所以不能经过路由器,经过交换机可以);
(4) 请求报文要经由Director,但响应不能经由Director,而是由RS直接发往Client;
(5) 不支持端口映射;
优点:RS处理完请求后是直接响应给客户主机的,不会经由调度器,从而大大减轻了调度器的负担,增加了集群
的并发请求处理量;
缺点:配置较复杂,需要在所有RS上配置VIP并修改内核参数。DR类型是通过重新封装请求报文的包头文件的
MAC地址来实现转发的,所以调度器和RS只能在一个局域网内(无法实现后端的RS异地灾备)。DR类型相对于NAT类型需要消耗更多的公网IP;
使用场景:并发量非常大的情况下会用到此类型,DR模型的并发处理量能达到硬件级别的能力。
(3) lvs-tun
lvs-tun:
转发方式:不修改请求报文的IP首部(源IP为CIP,目标IP为VIP),而是在原IP报文之外再封装一个IP首部(源IP是DIP,目标IP是RIP),将报文发往挑选出的目标RS;RS直接响应给客户端(源IP是VIP,目标IP是CIP);
(1) DIP, VIP, RIP都应该是公网地址;
(2) RS的网关不能,也不可能指向DIP;
(3) 请求报文要经由Director,但响应不能经由Director;
(4) 不支持端口映射;
(5) RS的OS得支持隧道功能;
优点:解决了DR类型下RS与调度器必须在同一局域网的限制;
缺点:配置繁琐,应用场景少;而且由于要额外给请求报文封装一层IP报文,所以对于请求报文携带较多数据
的场景(虽然这种场景少,但是也不是没有。比如请求向数据库写入一大串字符串),会导致请求报文大小超过
MTU默认大小。会有巨型帧的概念(指有效负载超过IEEE 802.3标准所限制的1500字节的以太网帧),有巨型
帧会导致每一次请求报文会被切片,造成效率不高的问题。
使用场景:如果环境要求DIP与RIP不在同一物理网络(如灾备)时,就需要用到lvs-tun模型。
(4) lvs-fullnat
通过同时修改请求报文的源IP地址和目标IP地址进行转发;
CIP <--> DIP
VIP <--> RIP
(1) VIP是公网地址,RIP和DIP是私网地址,且通常不在同一IP网络;因此,RIP的网关一般不会指向DIP;
(2) RS收到的请求报文源地址是DIP,因此,只能响应给DIP;但Director还要将其发往Client;
(3) 请求和响应报文都经由Director;
(4) 支持端口映射;
优点:相比于NAT的局域网,FULLNAT是相对于没有那么局限,它是限制在内网中的。对于运维比较方便。
(解决了lvs-tun类型的笨重,因为做异地灾备的还是挺少的。一般是在大的办公大楼,不同机房。)也支持端口
映射。
缺点:请求报文和响应报文都要经过director,director压力过大。
配置复杂。而且还不是LVS标准类型,如果要用。还要有自定义的能力,比如打补丁等。
而且ipvsadm也不支持这种类型,要自己写工具实现。
使用场景:人比较少,肯投了的场景。(俗称人少钱多)
注意:此类型默认不支持。要想时要此功能,要编译内核打补丁,比较复杂。属于理论类型,
没有能力一般实现不了。没有被收录进LVS官方标准类型。
3.3、LVS-NAT和LVS-DR的原理和实现举例,LVS-FUN和LVS-FULLNAT简单图解
3.3.1、LVS的NAT类型
LVS的NAT类型满足以下概要说明概要说明的特点:
实现:多目标IP的DNAT,通过将请求报文中的目标地址和目标端口修改为某挑出的RS的RIP和PORT实现转发;
(1) RIP和DIP必须在同一个IP网络,且应该使用私网地址;RS的网关要指向DIP;
(2) 请求报文和响应报文都必须经由Director转发;Director易于成为系统瓶颈;
(3) 支持端口映射,可修改请求报文的目标PORT;
(4) vs必须是Linux系统,rs可以是任意系统;
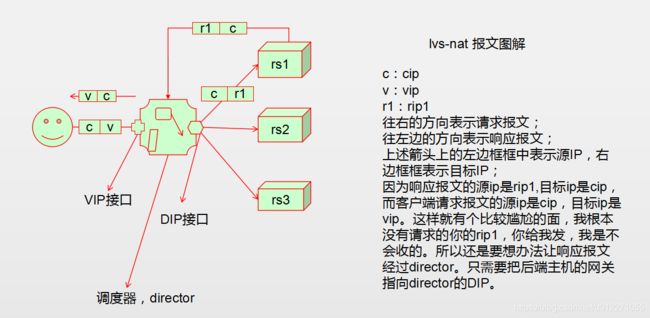
lvs-nat模式的请求报文和响应报文图解:
工作逻辑简述:
lvs的nat模型有点类似于之前iptables中讲到的DNAT(目标地址转换),和DNAT几乎一样。
不同的是,LVS的nat模型中后端主机有多个,而且实现方式不在iptables的PREROUTING链上,而是在iptables
的INPUT链上(所以要想用lvs,就不能用到iptables的INPUT链的功能)。当用户请求达到时,在INPUT链上的规则
监控到了这个集群服务,会把请求报文的目标IP改成后端某一个被挑选出来的主机的RIP地址。并强行把报文送
到POSTROUTING链上后离开本机,然后到对应的RS上去了。
不管后端调度的是哪一台RS,客户端发往VIP的请求报文,收到的都是VIP的响应报文。这种节奏不能变。如上
图解请求报文的目标ip被改变了,而响应报文的源IP被改变了。请求报文的目标IP是如何改的,此前说的DNAT,是需要我们手动指定要修改的目标IP。有了LVS之后,请求报文到底被发往哪一个后端主机,我们自己是不能定
义的,是由调度器根据调度算法从后端多个可用的RIP中挑选出来的,而非固定的。这种被挑选就是通过调度算
法来控制的。
VIP应该是一个公网地址。DIP应该是一个私网地址。各后端主机为了达到隐藏的目的,要和DIP一样,都应该是
一个私网地址。而且为了让响应报文的源IP是VIP,必须要把各后端的RIP的网关指向DIP。
实验环境说明:
客户端主机:172.16.0.88
调度器主机:
VIP:172.16.0.61
DIP:192.168.10.254
后端主机1:192.168.10.11
后端主机2:192.168.10.12
虚拟机环境说明:172.16.0.0/16网段是我家庭网络的桥接网段。我要把这个网段模拟成外网环境,实际并不是。
为了减少实验难度,就让客户端主机和调度器主机在同一个网络。实际应用场景,VIP和CIP都是真实的外网环
境,而且CIP请求VIP可能要经过层层路由而到达。后端主机的RIP是一个仅主机模式的接口,它们的网关配置
指向了调度器的DIP(192.168.10.254)。调度器要想中转报文,要开启防火墙的核心转发功能。
调度器的yum仓库可用epel和base,而且可以指向互联网,所以这个没必要说,它自己的时钟同步指向互联网。
通过chronyd来同步。它自己本身也是一个时钟服务器,可以被后端的RS同步使用。
各RS的时钟不同指向DIP,通过chronyd来同步。
调度器主机上有安装ipvsadm软件包,这个用来编写lvs规则用的。然后防火墙演示lvs的nat模式没有开启。默认我
关闭来selinux,firewalld。iptables策略就算INPUT有规则,也无法功能。
RS上安装了nginx,httpd,telnet-server等服务器,为的的演示需要。为了需要,我给它们挂载来光盘,然后配置
了yum指向自己配置的光盘。
实验环境图:

实验环境简单查看:
#director有两块网卡,eno16777736是VIP,eno33554984是DIP
[yanhui@director ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.61 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:febb:6862 prefixlen 64 scopeid 0x20
ether 00:0c:29:bb:68:62 txqueuelen 1000 (Ethernet)
RX packets 1506671 bytes 1072035825 (1022.3 MiB)
RX errors 0 dropped 11 overruns 0 frame 0
TX packets 997524 bytes 88755408 (84.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eno33554984: flags=4163 mtu 1500
inet 192.168.10.254 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::20c:29ff:febb:686c prefixlen 64 scopeid 0x20
ether 00:0c:29:bb:68:6c txqueuelen 1000 (Ethernet)
RX packets 41 bytes 5420 (5.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 25 bytes 1818 (1.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 149 bytes 13112 (12.8 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 149 bytes 13112 (12.8 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
后端RS1:rip1是eno16777736,其ip为192.168.10.11,网关指向DIP,192.168.10.254
[yanhui@rs1 ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 192.168.10.11 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::20c:29ff:fe18:8676 prefixlen 64 scopeid 0x20
ether 00:0c:29:18:86:76 txqueuelen 1000 (Ethernet)
RX packets 532600 bytes 52940708 (50.4 MiB)
RX errors 0 dropped 11 overruns 0 frame 0
TX packets 770085 bytes 567926043 (541.6 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 83 bytes 5282 (5.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 83 bytes 5282 (5.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[yanhui@rs1 ~]$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.10.254 0.0.0.0 UG 100 0 0 eno16777736
192.168.10.0 0.0.0.0 255.255.255.0 U 100 0 0 eno16777736
后端RS2:rip2是eno16777736,其ip为192.168.10.12,网关指向DIP,192.168.10.254
[yanhui@rs2 ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 192.168.10.12 netmask 255.255.255.0 broadcast 192.168.10.255
inet6 fe80::20c:29ff:fe99:19a4 prefixlen 64 scopeid 0x20
ether 00:0c:29:99:19:a4 txqueuelen 1000 (Ethernet)
RX packets 536180 bytes 53205796 (50.7 MiB)
RX errors 0 dropped 11 overruns 0 frame 0
TX packets 771806 bytes 568494213 (542.1 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 85 bytes 5414 (5.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 85 bytes 5414 (5.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
配置RS1上nginx的测试访问站点文件:
[yanhui@rs1 ~]$ sudo vim /usr/share/nginx/html/test1.html
[yanhui@rs1 ~]$ cat /usr/share/nginx/html/test1.html
RS1,192.168.10.11
[yanhui@rs1 ~]$ sudo systemctl start nginx.service
[yanhui@rs1 ~]$ ps aux|grep nginx
root 8868 0.0 0.9 124976 2116 ? Ss 00:18 0:00 nginx: master process /usr/sbin/nginx
nginx 8869 0.0 1.3 125364 3144 ? S 00:18 0:00 nginx: worker process
配置RS2上nginx的测试访问站点文件:
[yanhui@rs2 ~]$ sudo vim /usr/share/nginx/html/test1.html
[yanhui@rs2 ~]$ cat /usr/share/nginx/html/test1.html
RS2,192.168.10.12
[yanhui@rs2 ~]$ sudo systemctl start nginx.service
[yanhui@rs2 ~]$ ps aux|grep nginx
root 8763 0.0 0.9 124976 2112 ? Ss 00:18 0:00 nginx: master process /usr/sbin/nginx
nginx 8764 0.0 1.3 125364 3140 ? S 00:18 0:00 nginx: worker process
yanhui 8766 0.0 0.4 112640 960 pts/1 S+ 00:18 0:00 grep --color=auto nginx
先在调度器上简单访问一下:
[yanhui@director ~]$ curl http://192.168.10.11/test1.html
RS1,192.168.10.11
[yanhui@director ~]$ curl http://192.168.10.12/test1.html
RS2,192.168.10.12
#vs,rs1,rs2要时间同步,没有误差。可以自行配置实现。这里就省略啦。简单看看时间是同步的:
[yanhui@director ~]$ date
Tue Jan 15 00:23:13 CST 2019
[yanhui@rs1 ~]$ date
Tue Jan 15 00:23:18 CST 2019
[yanhui@rs2 ~]$ date
Tue Jan 15 00:23:23 CST 2019
#打开调度器的服务器核心转发功能
[yanhui@director ~]$ sudo sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
[yanhui@director ~]$ cat /proc/sys/net/ipv4/ip_forward
1
配置集群服务1(把tcp协议的80端口定义为一个集群服务,然后使用轮询调度方法):
[yanhui@director ~]$ sudo ipvsadm -A -t 172.16.0.61:80 -s rr
[yanhui@director ~]$ sudo ipvsadm -Ln #-L要在-n前边,不能使用-nL组合
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.61:80 rr
向刚才定义的tcp的80端口的集群服务添加后端real server:
[yanhui@director ~]$ sudo ipvsadm -a -t 172.16.0.61:80 -r 192.168.10.11 -m
[yanhui@director ~]$ sudo ipvsadm -a -t 172.16.0.61:80 -r 192.168.10.12 -m
[yanhui@director ~]$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.61:80 rr
-> 192.168.10.11:80 Masq 1 0 0
-> 192.168.10.12:80 Masq 1 0 0
客户端上测试集群访问:
#如果不能访问,请确认一下你Director主机的核心转发功能是否有开启
[yanhui@host11 ~]$ for i in {1..10};do
> curl http://172.16.0.61/test1.html
> done
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
#可以仔细观察上面的集群服务器响应主机的结果,是按照后端主机轮询的方式响应的
修改后端被调度主机的权重值:
[yanhui@director ~]$ sudo ipvsadm -e -t 172.16.0.61:80 -r 192.168.10.11 -m -w 2
[yanhui@director ~]$ sudo ipvsadm -e -t 172.16.0.61:80 -r 192.168.10.12 -m -w 3
[yanhui@director ~]$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.61:80 rr
-> 192.168.10.11:80 Masq 2 0 0
-> 192.168.10.12:80 Masq 3 0 0
#默认轮询rr调度方法,后端主机的权重即使不一样,也没有效果,现在我们还要把集群服务的调度方法修改成wrr
修改集群服务的调度方法为加权轮询:
[yanhui@director ~]$ sudo ipvsadm -E -t 172.16.0.61:80 -s wrr
[yanhui@director ~]$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.61:80 wrr
-> 192.168.10.11:80 Masq 2 0 0
-> 192.168.10.12:80 Masq 3 0 0
客户端测试集群访问情况:
[yanhui@host11 ~]$ for i in {1..10};do curl http://172.16.0.61/test1.html; done
RS2,192.168.10.12
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
[yanhui@host11 ~]$ for i in {1..10};do curl http://172.16.0.61/test1.html; done
RS2,192.168.10.12
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS2,192.168.10.12
RS1,192.168.10.11
RS2,192.168.10.12
RS1,192.168.10.11
#从结果来看,虽然不是一直3比1,但是有个规则,先2:1,然后1:1,然后2:1,然后1:1,如此反复。总结果就是
3:2
让一个后端RS不再接受请求的方式有两种:设置它的权重为0;把它从集群中删除或移除;
(1) 设置权重为0就是修改
[yanhui@director ~]$ sudo ipvsadm -e -t 172.16.0.61:80 -r 192.168.10.11 -m -w 0
[yanhui@director ~]$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.61:80 wrr
-> 192.168.10.11:80 Masq 0 0 0
-> 192.168.10.12:80 Masq 3 0 0
测试客户端访问结果:
[yanhui@host11 ~]$ for i in {1..10};do curl http://172.16.0.61/test1.html; done
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
RS2,192.168.10.12
(2) 从集群服务中移除RS
[yanhui@director ~]$ sudo ipvsadm -d -t 172.16.0.61:80 -r 192.168.10.11
[yanhui@director ~]$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.61:80 wrr
-> 192.168.10.12:80 Masq 3 0 30
#其他的就不演示了。LVS负载均衡集群服务中有后端RS异常,集群服务本身不能做到移除这个RS,还是会调度
请求到异常的后端主机上去。此时,就需要借助其他辅助程序来配合使用,而实际使用场景中,Director要做高可
用集群,有些高可用集群实现程序本身就支持这种后端RS监控状态监测机制,可以实现把后端异常的主机移除,
修复后可以自动上线等等。
3.3.2、LVS的DR类型
LVS的DR类型满足以下概要说明的特点:
Direct Routing,直接路由;
通过为请求报文重新封装一个MAC首部进行转发,源MAC是DIP所在的接口的MAC,目标MAC是某挑选出的RS
的RIP所在接口的MAC地址;源IP/PORT,以及目标IP/PORT均保持不变;
Director和各RS都得配置使用VIP;
(1) 确保前端路由器将目标IP为VIP的请求报文发往Director:
(a) 在前端网关做静态绑定;
(b) 在RS上使用arptables;
(c) 在RS上修改内核参数以限制arp通告及应答级别;
arp_announce
arp_ignore
(2) RS的RIP可以使用私网地址,也可以是公网地址;RIP与DIP在同一IP网络;RIP的网关不能指向DIP,以确保响应报文不会经由Director;
(3) RS跟Director要在同一个物理网络;
(4) 请求报文要经由Director,但响应不能经由Director,而是由RS直接发往Client;
lvs-dr模式的请求报文和响应报文的图解:


实验环境说明:
客户端主机:172.16.0.88
调度器主机:
VIP:172.16.0.61
DIP:192.168.10.254(假设这个ip我们就不禁止,就当做内网ip)
后端主机1:172.16.0.62。lo网卡接口地址别名(lo:0)上配置来vip,为了是先让交换机丢过来的请求报文经过lo接
口;为了是让从RS出去的响应报文的原地址是lo:0上的VIP。因为linux内核有个特点,先经过那个网卡的报文,
出去的报文的原地址就是谁。(还要通过arptables或者通过内核参数,控制lo:0接口的arp广播和arp广播通告)
后端主机2:172.16.0.63。lo网卡接口地址别名(lo:0)上配置了vip;为了是先让交换机丢过来的请求报文经过lo接口;
虚拟机环境说明:172.16.0.0/16网段是我家庭网络的桥接网段。假设这个网段是模拟的外网网段。
调度器的yum仓库可用epel和base,而且可以指向互联网,所以这个没必要说,它自己的时钟同步指向互联网。
通过chronyd来同步。它自己本身也是一个时钟服务器,可以被后端的RS同步使用。
各RS的时钟不同指向DIP,通过chronyd来同步。
调度器主机上有安装ipvsadm软件包,这个用来编写lvs规则用的。然后防火墙演示lvs的nat模式没有开启。默认我
关闭来selinux,firewalld。iptables策略就算INPUT有规则,也无法功能。
RS上安装了nginx,httpd,telnet-server等服务器,为的的演示需要。
解决地址冲突配置说明:
dr模型中,各主机上均需要配置VIP,解决地址冲突的方式有三种:
(1) 在前端网关做静态绑定;(不适合)
(2) 在各RS使用arptables;(需要额外安装和使用arptables,可以实现)
(3) 在各RS修改内核参数,来限制arp响应和通告的级别;(可以实现,较第二种方法简单)
限制响应级别:arp_ignore
0:默认值,表示可使用本地任意接口上配置的任意地址进行响应;
1: 仅在请求的目标IP配置在本地主机的接收到请求报文接口上时,才给予响应;
限制通告级别:arp_announce
0:默认值,把本机上的所有接口的所有信息向每个接口上的网络进行通告;
1:尽量避免向非直接连接网络进行通告;
2:必须避免向非本网络通告;

通告和响应简述:
假设A主机有三个网络接口,分别是B,C,D。B所在网络为2.1,C所在网络为3.1,D所在网络为1.1。
默认主机A的行为,在网络领域有一个通告和响应的概念。B,C,D三个网络接口都对应一个MAC,假设
分别为B-MAC,C-MAC,D-MAC。与D直连网络是1.0,其中网络中一个一个主机是s1,对应ip是1.2,mac是
s1-mac。与B直连网络是2.0,其中网络中一个主机是s2,对应ip是2.3,mac是s2-mac.C直连的网络是3.0,对应
网络中有一个主机是s3,对应ip是3.2。
默认行为是A主机会通告给1.0网络,2.0网络,3.0网络,它的三个接口B,C,D的信息,包括IP和MAC地址。
D的直连网络是1.0,B的直连网络是2.0,C的直连网络是3.0.由于这种默认行为,如果有一天有台2.2的机器去请
求D接口,并告知,我需要和2.3主机通信,请告诉我2.3主机的MAC地址,经过arp广播后,A主机会告知它自己
B接口,并知道B接口所在网络的s2主机的mac地址的,这种属于arp响应,每个接口所在网络都知道A主机的三个
接口的信息,这个是A主机默认通告行为促成。
实验环境简单配置:
(1) director初始状态:(相比nat,这里只需要一个接口,如果是配置VIP,可以配置一个别名即可)
[yanhui@director ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.61 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:febb:6862 prefixlen 64 scopeid 0x20
ether 00:0c:29:bb:68:62 txqueuelen 1000 (Ethernet)
RX packets 84368 bytes 60108647 (57.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 55860 bytes 4974867 (4.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(2) RS1初始状态(还未配置lo:0的vip地址)
[yanhui@rs1 ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.62 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:fe18:8676 prefixlen 64 scopeid 0x20
ether 00:0c:29:18:86:76 txqueuelen 1000 (Ethernet)
RX packets 52285 bytes 9958142 (9.4 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 58891 bytes 36026131 (34.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 42 bytes 2792 (2.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 42 bytes 2792 (2.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
(3) RS2初始状态(还未配置lo:0的vip地址)
[yanhui@rs2 ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.63 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:fe99:19a4 prefixlen 64 scopeid 0x20
ether 00:0c:29:99:19:a4 txqueuelen 1000 (Ethernet)
RX packets 55280 bytes 10185276 (9.7 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 60633 bytes 36617412 (34.9 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 49 bytes 3376 (3.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 3376 (3.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
PS:时间,yum仓库,实验服务我就不说了,这些都是基础,还有配置主页什么的,也不提供了。
简单看看:
RS1站点的测试的静态资源和测试的动态资源:
[yanhui@rs1 ~]$ cat /var/www/html/phpinfo.php
RS1
[yanhui@rs1 ~]$ cat /var/www/html/test1.html
RS1,172.16.0.62
RS2的httpd站点的测试的静态资源和测试的动态资源:(为了看出效果,这里有意把资源内容定义不一样,实际
生产应用要一样的)
[yanhui@rs2 ~]$ cat /var/www/html/phpinfo.php
RS2
[yanhui@rs2 ~]$ cat /var/www/html/test1.html
RS2,172.16.0.63
配置arp通告和arp响应的简单查看:
[yanhui@rs2 ~]$ ls -l /proc/sys/net/ipv4/conf/
total 0
dr-xr-xr-x 1 root root 0 Jan 12 23:43 all
dr-xr-xr-x 1 root root 0 Jan 14 01:15 default
dr-xr-xr-x 1 root root 0 Jan 14 01:15 eno16777736
dr-xr-xr-x 1 root root 0 Jan 12 23:43 lo
#all表示所有,lo和eno16777736表示指定单个接口。
这里有个实现禁止通告和响应的功能以及配置lo:0接口vip地址的功能的bash脚本;
[yanhui@rs1 ~]$ pwd
/home/yanhui
[yanhui@rs1 ~]$ ls -l nomal_setparam.sh
-rw-r--r-- 1 root root 795 Jan 12 23:58 nomal_setparam.sh
[yanhui@rs1 ~]$ cat nomal_setparam.sh
#! /bin/bash
vip=172.16.0.199
mask=255.255.255.255 #为了让它自己和自己在一个网络,也只广播给自己,所以这样定义
iface='lo:0'
case $1 in
start)
echo 1 | sudo tee /proc/sys/net/ipv4/conf/all/arp_ignore
echo 1 | sudo tee /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 | sudo tee /proc/sys/net/ipv4/conf/all/arp_announce
echo 2 | sudo tee /proc/sys/net/ipv4/conf/lo/arp_announce
ifconfig $iface $vip netmask $mask broadcast $vip up
route add -host $vip dev $iface
;;
stop)
ifconfig $iface down
echo 0 | sudo tee /proc/sys/net/ipv4/conf/all/arp_ignore
echo 0 | sudo tee /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 0 | sudo tee /proc/sys/net/ipv4/conf/all/arp_announce
echo 0 | sudo tee /proc/sys/net/ipv4/conf/lo/arp_announce
;;
*)
echo "Usage: $(basename $0) start|stop"
exit 1
;;
esac
RS1上执行这个脚本:
[yanhui@rs1 ~]$ sudo bash nomal_setparam.sh start
1
1
2
2
[yanhui@rs1 ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.62 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:fe18:8676 prefixlen 64 scopeid 0x20
ether 00:0c:29:18:86:76 txqueuelen 1000 (Ethernet)
RX packets 56198 bytes 10306939 (9.8 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 64372 bytes 40006574 (38.1 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 42 bytes 2792 (2.7 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 42 bytes 2792 (2.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo:0: flags=73 mtu 65536
inet 172.16.0.199 netmask 255.255.255.255
loop txqueuelen 0 (Local Loopback)
[yanhui@rs1 ~]$ cat /proc/sys/net/ipv4/conf/{all,lo}/{arp_announce,arp_ignore}
2
1
2
1
RS2上执行这个脚本:
[yanhui@rs2 ~]$ sudo bash nomal_setparam.sh start
1
1
2
2
[yanhui@rs2 ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.63 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:fe99:19a4 prefixlen 64 scopeid 0x20
ether 00:0c:29:99:19:a4 txqueuelen 1000 (Ethernet)
RX packets 59542 bytes 10566445 (10.0 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 66675 bytes 40996952 (39.0 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 49 bytes 3376 (3.2 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 49 bytes 3376 (3.2 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo:0: flags=73 mtu 65536
inet 172.16.0.199 netmask 255.255.255.255
loop txqueuelen 0 (Local Loopback)
[yanhui@rs2 ~]$ cat /proc/sys/net/ipv4/conf/{all,lo}/{arp_announce,arp_ignore}
2
1
2
1
#为了让报文先从RS的lo:0进来,我们需要给每个后端的RS添加一个主机路由条目,下面是单独执行的过程。
如果集成到了脚本中,就可以忽略了,我上面给的脚本集成了,这里只是简单演示添加和删除路由。
我执行脚本后有添加上这个主机路由,然后为了演示,特意删除了的。
RS1:
[yanhui@rs1 ~]$ sudo route del -host 172.16.0.199 #纯粹为了演示增删路由
[yanhui@rs1 ~]$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.0.1 0.0.0.0 UG 100 0 0 eno16777736
172.16.0.0 0.0.0.0 255.255.0.0 U 100 0 0 eno16777736
[yanhui@rs1 ~]$ sudo route add -host 172.16.0.199 dev lo:0
[yanhui@rs1 ~]$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.0.1 0.0.0.0 UG 100 0 0 eno16777736
172.16.0.0 0.0.0.0 255.255.0.0 U 100 0 0 eno16777736
172.16.0.199 0.0.0.0 255.255.255.255 UH 0 0 0 lo
RS2:
[yanhui@rs2 ~]$ sudo route del -host 172.16.0.199
[yanhui@rs2 ~]$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.0.1 0.0.0.0 UG 100 0 0 eno16777736
172.16.0.0 0.0.0.0 255.255.0.0 U 100 0 0 eno16777736
[yanhui@rs2 ~]$ sudo route add -host 172.16.0.199 dev lo:0
[yanhui@rs2 ~]$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.16.0.1 0.0.0.0 UG 100 0 0 eno16777736
172.16.0.0 0.0.0.0 255.255.0.0 U 100 0 0 eno16777736
172.16.0.199 0.0.0.0 255.255.255.255 UH 0 0 0 lo
RS1启动httpd服务:
[yanhui@rs1 ~]$ sudo systemctl start httpd.service
[yanhui@rs1 ~]$ ps aux|grep httpd
root 5529 1.2 6.1 404100 14012 ? Ss 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5531 0.0 3.3 404232 7744 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5532 0.0 3.3 404232 7744 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5533 0.0 3.3 404232 7744 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5534 0.0 3.3 404232 7744 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5535 0.0 3.3 404232 7744 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
yanhui 5537 0.0 0.4 112640 956 pts/0 R+ 01:30 0:00 grep --color=auto httpd
RS2启动httpd服务:
[yanhui@rs2 ~]$ sudo systemctl start httpd.service
[yanhui@rs2 ~]$ ps aux|grep httpd
root 5481 2.0 6.1 404100 14012 ? Ss 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5483 0.0 3.3 404232 7740 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5484 0.0 3.3 404232 7740 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5485 0.0 3.3 404232 7740 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5486 0.0 2.9 404232 6760 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
apache 5487 0.0 3.2 404232 7508 ? S 01:30 0:00 /usr/sbin/httpd -DFOREGROUND
yanhui 5489 0.0 0.4 112640 960 pts/0 S+ 01:30 0:00 grep --color=auto httpd
在前端主机(director主机)上直接请求测试一下这两台RS的RIP接口的80访问情况:
[yanhui@director ~]$ curl http://172.16.0.62/test1.html
RS1,172.16.0.62
[yanhui@director ~]$ curl http://172.16.0.63/test1.html
RS2,172.16.0.63
[yanhui@director ~]$ curl -I http://172.16.0.62/phpinfo.php
HTTP/1.1 200 OK
Date: Sun, 13 Jan 2019 17:32:04 GMT
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/5.4.16
X-Powered-By: PHP/5.4.16
Content-Type: text/html; charset=UTF-8
[yanhui@director ~]$ curl -I http://172.16.0.63/phpinfo.php
HTTP/1.1 200 OK
Date: Sun, 13 Jan 2019 17:32:15 GMT
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/5.4.16
X-Powered-By: PHP/5.4.16
Content-Type: text/html; charset=UTF-8
在Director上配置VIP地址(172.16.0.199),因为要通过物理网卡eno16777736接进来请求报文,并通过物理网卡
转发报文给交换机。所以VIP也要配置到物理网卡上,我们可以配置网卡别名来实现:
[yanhui@director ~]$ sudo ifconfig eno16777736:0 172.16.0.199 netmask 255.255.255.255 broadcast 172.16.0.199 up
[yanhui@director ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.61 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:febb:6862 prefixlen 64 scopeid 0x20
ether 00:0c:29:bb:68:62 txqueuelen 1000 (Ethernet)
RX packets 113955 bytes 80856593 (77.1 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 76000 bytes 6823007 (6.5 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eno16777736:0: flags=4163 mtu 1500
inet 172.16.0.199 netmask 255.255.255.255 broadcast 172.16.0.199
ether 00:0c:29:bb:68:62 txqueuelen 1000 (Ethernet)
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
集群定义和测试:
#确认一下ipvsadm工具是否有安装:
[yanhui@director ~]$ rpm -q ipvsadm
ipvsadm-1.27-7.el7.x86_64
#定义集群(集群调度方法为轮询 rr)
[yanhui@director ~]$ sudo ipvsadm -A -t 172.16.0.199:80 -s rr
[yanhui@director ~]$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.199:80 rr
FWM 3 rr
-> 127.0.0.1:80 Route 1 0 0
#添加后端主机(-g是默认类型dr的选项。)
[yanhui@director ~]$ sudo ipvsadm -a -t 172.16.0.199:80 -r 172.16.0.62 -g
[yanhui@director ~]$ sudo ipvsadm -a -t 172.16.0.199:80 -r 172.16.0.63 -g
[yanhui@director ~]$ sudo ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.0.199:80 rr
-> 172.16.0.62:80 Route 1 0 0
-> 172.16.0.63:80 Route 1 0 0
FWM 3 rr
-> 127.0.0.1:80 Route 1 0 0
客户端环境:
[yanhui@host11 ~]$ ifconfig
eno16777736: flags=4163 mtu 1500
inet 172.16.0.88 netmask 255.255.0.0 broadcast 172.16.255.255
inet6 fe80::20c:29ff:feae:a6bf prefixlen 64 scopeid 0x20
ether 00:0c:29:ae:a6:bf txqueuelen 1000 (Ethernet)
RX packets 70376 bytes 8727803 (8.3 MiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 92011 bytes 8177456 (7.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 0 (Local Loopback)
RX packets 35 bytes 2486 (2.4 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 35 bytes 2486 (2.4 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
访问测试集群:(结果是否符合轮询,要简单核对一下)
[yanhui@host11 ~]$ for i in {1..10};do
> curl http://172.16.0.199/test1.html
> done
RS2,172.16.0.63
RS1,172.16.0.62
RS2,172.16.0.63
RS1,172.16.0.62
RS2,172.16.0.63
RS1,172.16.0.62
RS2,172.16.0.63
RS1,172.16.0.62
RS2,172.16.0.63
RS1,172.16.0.62
关于动态资源,可以在浏览器上简单测试一下。,我可以用curl -I选项简单测试两次:
[yanhui@host11 ~]$ curl -I http://172.16.0.199/phpinfo.php
HTTP/1.1 200 OK
Date: Sun, 13 Jan 2019 17:43:14 GMT
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/5.4.16
X-Powered-By: PHP/5.4.16
Content-Type: text/html; charset=UTF-8
[yanhui@host11 ~]$ curl -I http://172.16.0.199/phpinfo.php
HTTP/1.1 200 OK
Date: Sun, 13 Jan 2019 17:43:14 GMT
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/5.4.16
X-Powered-By: PHP/5.4.16
Content-Type: text/html; charset=UTF-8


可以看看172.16.0.199的mac地址是否为Director的VIP:
[yanhui@host11 ~]$ arp -a
director (172.16.0.61) at 00:0c:29:bb:68:62 [ether] on eno16777736
? (172.16.0.14) at d4:81:d7:87:2f:21 [ether] on eno16777736
www.yanhui.com (172.16.0.199) at 00:0c:29:bb:68:62 [ether] on eno16777736
? (172.16.0.62) at 00:0c:29:18:86:76 [ether] on eno16777736
? (172.16.0.63) at 00:0c:29:99:19:a4 [ether] on eno16777736
? (172.16.0.1) at dc:fe:18:b4:bc:79 [ether] on eno16777736
[yanhui@director ~]$ ifconfig eno16777736:0
eno16777736:0: flags=4163
inet 172.16.0.199 netmask 255.255.255.255 broadcast 172.16.0.199
ether 00:0c:29:bb:68:62 txqueuelen 1000 (Ethernet)
#可以看出广播的172.16.0.199的mac地址是Director的物理接口别名网卡en016777736:0的mac地址。
3.3.3、LVS的tun类型简单报文图解(隧道)

3.3.4、LVS的fullnat类型简单报文图解
