Understanding Deep Image Representations by Inverting Them
核心公式:
![]()
This paper proposed an optimisation method to invert
shallow and deep representations based on optimizing an
objective function with gradient descent.
核心:文章提出的是用基于梯度的方法优化一个目标函数来实现浅层和深层表达的反转。
公式含义解释:
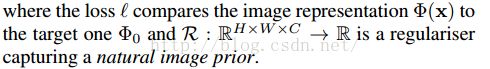


代码理解:invert.nn是核心代码
1、每一次实验参数放入exp{}中,不同实验TVnorm、显示哪层的特征图等参数不相同;
2、net选用caffe-Alex的21层网络,实验参数exp中layer值,决定了选取net从第一层到选取层的训练好的网络weight;
3、compute_feature,计算得到输入原始图像im经过训练好的weigh一层层计算后,得到最后某层的特征图;
4、vl_simplenn(net,x)计算得到输入随机图像x,经过训练好的weigh一层层计算后,得到的每一层的特征图,当然实际使用时选择了最后一层的特征图,需注意,此时net中除了选取的alex_Model的部分层外,另加了custom_layer,用于计算目标函数第一项。该层包含了 nndistance_forward和nndistance_backward,计算的是原始图像im和随机图像x经过n层后得到的特征图的平方差及对应到输入x的每个像素的梯度。
5、目标函数的三项分别计算放入了E各行中,E的最后行为三项和;
6、中间值dr(目标函数梯度)由后两项构成,而随机初始x的更新式为:
x_momentum = opts.momentum * x_momentum- lr * dr - (lr * x0_sigma^2/y0_sigma^2) * res(1).dzdx;
x = x + x_momentum ;则x的更新实则为三项,res(1).dzdx是目标函数第一项带来的梯度值。
代码图像生成:
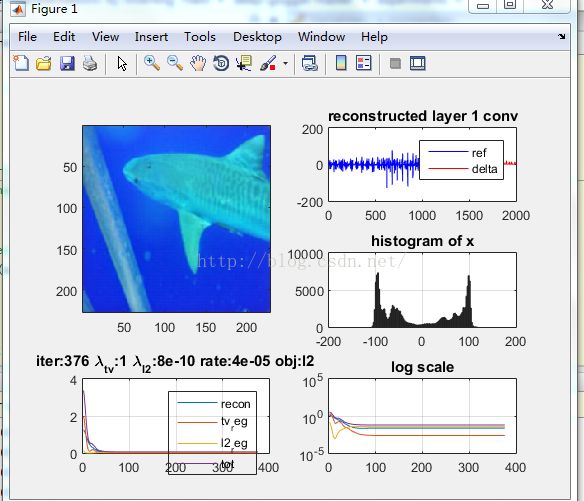
左上图:随机输入x经过目标函数梯度方法迭代后,得到的重构图,随着迭代次数变化;
右上图:蓝色为im输入得到的特征图的值(拉成了向量),红色为随机和im输入分别得到的特征图的差值;
右中:随机输入x的直方图,(x随着迭代而改变);
左下:黑标题为实验该种参数的取值,obj为优化的l2型loss,画的是plot(E),即目标函数三个项分别的值,以及总和值(最后一个线条为total);
右下:对E去semilogy(E)得到的值,画出的图像。
文章思想:
通过目标函数梯度迭代,更新随机输入x,使输入x与原图像im相差最小。这过程中,模型net的weight是不变的,in other words,通过与hog、dsift的浅层表达对比,可以得出cnn模型学习到feature更好。(由某层feature map的差,invert 得到原表达的)
 ans
ans
TVnorm带来的inverse 特征的变化,减少了spikes.

TVnorm不同系数带来的变化。

大的TVnorm带来CNN最后一层iversions的变化。

不同的浅层表达特征采取同样的invert方法的图像。

图6.不同层inversion的显示,TVnorm系数为table3中表现最好的。

相同层不同feature map的inversons(应该是这个意思吧)。看relu7和fc8不同feature map得到目标不同位置和scale的多种copies.

CNN的接收域,从每层的feature中选取小patch进行invert,得到的图。接收域比理论区域明显要小。

CNN网络不同的stream下的图,grp1,grp2,网络不同通道子集下的iversion(Reconstructs images from a subset of feature channels. CNN-A contains in fact two subsets of feature channels which are independent for the first several layers (up to norm2)----A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. InNIPS, 2012.)在norm2之前,一直有着不同通道的特征子集。(还没细看)

CNN模型的多样性,都是mpool5中feature的重构,表明CNN在很深的网络后仍保持了丰富的信息。