一、准备工作:
1、找3台以上的主机(因为HDFS文件系统中保存的文件的blocak在datanode中至少要有3份或3份以上的备份,备份不能放于同一个机架上,更不能放于同一台主机上),我这里使用的是4台,分别是hadoop1、hadoop2、hadoop3和hadoop4。
2、安装每台主机的基本环境:linux CentOS6.5 64x系统,启动每台主机的系统,配置好网络和主机名《====》ip的映射。
配置网络的文件在:/etc/sysconfig/network-scripts/ifcfg-eth0文件中

注:每一台主机都要配置,但是IP不能重复。
主机名与IP的映射文件在:/etc/hosts文件中

3、关闭每台主机的防火墙。注:必须关闭,千万不能忘记,我已经在这个上面吃亏很多次了。
Command:service iptables stop
4、同步每台主机的时间,这里使用的是上海交通大学网络中心NTP服务器来同步时间。
Command:ntpdate ntp.sjtu.edu.cn
二、安装并配置zookeeper服务器:这里将主机名为hadoop1、hadoop2和hadoop3的主机定为zookeeper服务器。
1、在hadoop1中安装zookeeper。自己从zookeeper官方网站上下载,我这里使用的是zookeeper-3.4.6,安装步骤不在这里详解了。
2、使用vim 编辑器修改zookeeper安装目录中conf下的zoo_sample.cfg文件,即zookeeper的配置文件。vim是vi编辑器的升级版,可自行安装,使用vi也可以。
Command:vi /root/zookeeper-3.4.6/conf/zoo_sample.cfg

3、在zoo_sample.cfg文件的末尾添加:

4、通过网络拷贝命令将hadoop1上的zookeeper安装目录拷贝到hadoop2和hadoop3的相同目录下:
Command: scp /root/zookeeper-3.4.6 root@hadoop2:/root/ scp /root/zookeeper-3.4.6 root@hadoop3:/root/
5、为各zookeeper服务器主机创建/home/zk_data目录
Command:
mkdir /home/zk_data
6、为各zookeeper服务器配置myid文件,myid这个文件是不存在的,使用vim编辑器编辑保存后会自动创建该文件,该文件的内容为上述配置文件中为其zookeeper服务器在server.x=hadoopx:2888:3888中server后面的x代表的id,编辑保存即可。每台zookeeper服务器主机都要配置。
Command:
vim /home/zk_data/myid

7、启动3台zookeeper服务器
Command:
/root/zookeeper-3.4.6/bin/zkServer.sh start
8、到zookeeper安装目录的父目录中查看日志文件,看是否启动成功
三、配置HDFS中的namenode、JN,这里将hadoop1和hadoop4定为namenode,将hadoop1-3定为JN。
1、在hadoop1主机中安装hadoop,我这里安装的是hadoop-2.5.1。
2、修改hadoop1配置文件中hdfs-site.cfg文件 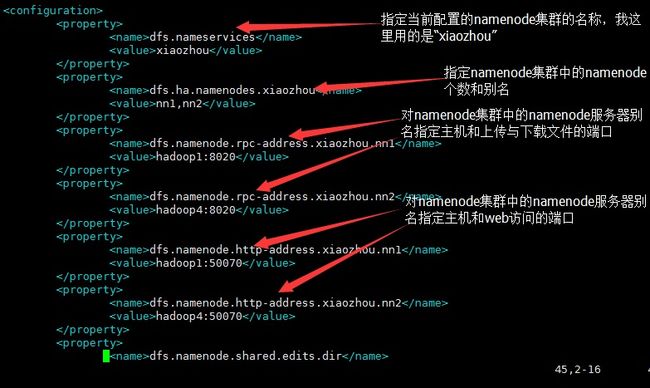

3、修改hadoop1配置文件中core-site.cfg文件

4、通过网络拷贝命令将hadoop1中hadoop的安装目录拷贝到另外三台机器中。
Command: scp /root/hadoop-2.5.1 root@hadoop2:/root/ scp /root/hadoop-2.5.1 root@hadoop3:/root/ scp /root/hadoop-2.5.1 root@hadoop4:/root/
5、启动hadoop1-3主机中的JN
Command:
/root/hadoop-2.5.1/sbin/hadoop-daemon.sh start journalnode
6、初始化主机hadoop1中的hadoop
Command:
/root/hadoop-2.5.1/bin/hdfs namenode -format
7、在hadoop1中执行:
Command:
/root/hadoop-2.5.1/sbin/hadoop-daemon.sh start namenode
8、在hadoop4中执行:
Command:
/root/hadoop-2.5.1/bin/hdfs namenode -bootstrapStandby
9、关闭hadoop1的namenode
Command:
/root/hadoop-2.5.1/sbin/hadoop-daemon.sh stop namenode
10、在ZK中创建znode来存储automatic Failover的数据,在hadoop1中执行:
Command: /root/hadoop-2.5.1/bin/hdfs zkfc -formatZK
11、从hadoop1启动namenode
Command:
/root/hadoop-2.5.1/sbin/start-dfs.sh