【强化学习】值函数强化学习-DQN、DDQN和Dueling DQN算法公式推导分析
一、值函数估计方法引入
在值函数估计方法中,我们希望拟合一个价值模型用来估计每个状态动作对的累积回报。其代价函数可以写为
L = 1 2 ∑ a ∑ s ( Q ( s , a ) − Q ( s , a ; θ ) ) 2 L=\frac{1}{2}\sum_{a}\sum_{s}(Q(s,a)-Q(s,a;\theta))^2 L=21a∑s∑(Q(s,a)−Q(s,a;θ))2
其中 Q ( s , a ) Q(s,a) Q(s,a)为真实的累积回报的值函数, Q ( s , a ; θ ) Q(s,a;\theta) Q(s,a;θ)为价值模型估计的累积回报,我们希望了两者的差最小。采用梯度下降法可得参数的更新公式为
θ t + 1 = θ t + α [ Q ( s t , a t ) − Q ( s t , a t ; θ ) ] ∇ Q ( s t , a t ) \theta_{t+1}=\theta_t+\alpha[Q(s_t,a_t)-Q(s_t,a_t;\theta)]\nabla Q(s_t,a_t) θt+1=θt+α[Q(st,at)−Q(st,at;θ)]∇Q(st,at)
通常采用TD方法对真实的 Q ( s t , a t ) Q(s_t,a_t) Q(st,at)进行估计,最终参数更新公式为
θ t + 1 = θ t + α [ r ( s t , a t ) + Q ( s t + 1 , a t + 1 ; θ t ) − Q ( s t , a t ; θ t ) ] ∇ Q ( s t , a t ) \theta_{t+1}=\theta_t+\alpha[r(s_t,a_t)+Q(s_{t+1},a_{t+1};\theta_t)-Q(s_t,a_t;\theta_t)]\nabla Q(s_t,a_t) θt+1=θt+α[r(st,at)+Q(st+1,at+1;θt)−Q(st,at;θt)]∇Q(st,at)
其中可以定义TD-error为
δ t = r ( s t , a t ) + Q ( s t + 1 , a t + 1 ; θ t ) − Q ( s t , a t ; θ t ) \delta_t = r(s_t,a_t)+Q(s_{t+1},a_{t+1};\theta_t)-Q(s_t,a_t;\theta_t) δt=r(st,at)+Q(st+1,at+1;θt)−Q(st,at;θt)
二、DQN
DQN是DeepMind在Nature上发表的第一篇论文《Human-level Control through Deep Reinforcement Learning》。本算法核心为两个创新点,即经验回放与设立单独的目标网络。
首先简单介绍一个Qlearning,Qlearning的两个核心为异策略和时间差分。
异策略:是指执行的策略和要评估的策略不是同一个策略,通常使用 ε − g r e e d y \varepsilon-greedy ε−greedy策略。
时间差分:是指利用时间差分目标来更新当前状态动作值函数。TD目标可以写为 r t + γ max a Q ( s t + 1 , a ) r_t+\gamma \max_{a}Q(s_{t+1},a) rt+γmaxaQ(st+1,a).
DQN是在Qlearning的基础上做了如下修改:
1.DQN利用深度卷积神经网络逼近值函数。
采用CNN逼近值函数,网络结构为3个卷基层,2个全连接层。
2.DQN利用了经验回放训练强化学习模型。
在训练神经网络时,假设训练数据是独立同分布的,但是强化学习数据采集过程中的数据是具有关联性的,利用这些时序关联的数据训练时,神经网络无法稳定,利用经验回放打破了数据间的关联性。在强化学习的过程中,智能体将数据保存到一个数据库中,再利用均匀随机采样的方法从数据库中抽取数据,然后利用抽取到的数据训练神经网络。
3.DQN独立设置了目标网络来单独处理时间差分算法中的TD误差。
目标网络的作用于经验回放一致,都是为了打破训练数据之间的时序关联性。Qlearning中的参数更新公式如下
θ t + 1 = θ t + α [ r + γ max a ′ Q ( s ′ , a ′ ; θ ) − Q ( s , a ; θ ) ] ∇ Q ( s , a ; θ ) \theta_{t+1}=\theta_{t}+\alpha[r+\gamma \max_{a'}Q(s',a';\theta)-Q(s,a;\theta)]\nabla Q(s,a;\theta) θt+1=θt+α[r+γa′maxQ(s′,a′;θ)−Q(s,a;θ)]∇Q(s,a;θ)
其中,TD目标 r + γ max a ′ Q ( s ′ , a ′ ; θ ) r+\gamma \max_{a'}Q(s',a';\theta) r+γmaxa′Q(s′,a′;θ)在计算时用到了网络参数 θ \theta θ。
在DQN算法出现之前,更新神经网络参数时,计算TD目标的动作值函数所用的网络参数 θ \theta θ与梯度计算中要逼近的值函数所用的网络参数相同,这样就容易导致数据间存在关联性,从而使得训练不稳定。为了解决关联性问题,TD目标计算时使用一个参数 θ − \theta^- θ−,计算并更新动作值函数逼近的网络使用另一个参数 θ \theta θ,在训练过程中,动作值函数逼近网络的参数 θ \theta θ每一步更新一次,TD目标计算网络的参数 θ − \theta^- θ−每个固定步数更新一次。值函数更新变为如下形式
θ t + 1 = θ t + α [ r + γ max a ′ Q ( s ′ , a ′ ; θ − ) − Q ( s , a ; θ ) ] ∇ Q ( s , a ; θ ) \theta_{t+1}=\theta_{t}+\alpha[r+\gamma \max_{a'}Q(s',a';\theta^-)-Q(s,a;\theta)]\nabla Q(s,a;\theta) θt+1=θt+α[r+γa′maxQ(s′,a′;θ−)−Q(s,a;θ)]∇Q(s,a;θ)
伪代码如下所示

三、DDQN
DQN无法解决Qlearning的固有缺点——过估计。过估计是指估计的值函数比真实的值函数偏大,如果过估计在所有状态都是均匀的,那么根据贪心策略,依然能够找到值函数最大的动作,但是往往过估计在各个状态不是均匀的,因此过估计会影响到策略决策,从而导致获取的不是最优策略。
过估计的产生的原因是在参数更新或值函数迭代过程中采用的max操作导致的
Q ( s t , a t ) = Q ( s t , a t ) + α [ r t + γ max a Q ( s t + 1 , a ) − Q ( s t , a t ) ] θ t + 1 = θ t + α [ R t + 1 + γ max a Q ( S t + 1 , a ; θ t ) − Q ( S t , A t ; θ t ) ] ∇ θ t Q ( S t , A t ; θ t ) Q(s_t,a_t)=Q(s_t,a_t)+\alpha[r_t + \gamma \max_a Q(s_{t+1},a)-Q(s_t,a_t)]\\ \theta_{t+1} = \theta_{t} + \alpha[R_{t+1}+\gamma \max_{a}Q(S_{t+1},a;\theta_t)-Q(S_t,A_t;\theta_t)]\nabla_{\theta_t}Q(S_t,A_t;\theta_t) Q(st,at)=Q(st,at)+α[rt+γamaxQ(st+1,a)−Q(st,at)]θt+1=θt+α[Rt+1+γamaxQ(St+1,a;θt)−Q(St,At;θt)]∇θtQ(St,At;θt)
DDQN就是用来解决过估计的问题。其核心思想是将TD目标的动作选择和TD目标的动作评估分别用不用的值函数来实现。
a. 动作选择
在Qlearning中TD目标的动作选择是在下一个状态 S t + 1 S_{t+1} St+1处选使状态动作值函数最大的动作 max a Q ( S t + 1 , a ; θ t ) \max_{a} Q(S_{t+1},a;\theta_t) maxaQ(St+1,a;θt)。
b. 动作评估
动作评估是指选出了下一个状态的最优动作 a t + 1 ∗ a_{t+1}^* at+1∗,来构造TD目标 Q ( S t + 1 , a t + 1 ∗ ; θ t ) Q(S_{t+1},a_{t+1}^*;\theta_t) Q(St+1,at+1∗;θt)。
DDQN是分别用不同的值函数进行动作的选择与评估。其更新公式如下所示
Y t D o u b l e Q = R t + 1 + γ Q ( S t + 1 , a r g m a x a Q ( S t + 1 , a ; θ t ) ; θ t ′ ) Y_t^{\rm {DoubleQ}} = R_{t+1} + \gamma Q(S_{t+1}, argmax_{a} Q(S_{t+1},a;\theta_t);\theta_t') YtDoubleQ=Rt+1+γQ(St+1,argmaxaQ(St+1,a;θt);θt′)
由上式可以看出,动作的选择采用 θ \theta θ网络, a ∗ = a r g m a x a Q ( S t + 1 , a ; θ t ) a^*=argmax_{a} Q(S_{t+1},a;\theta_t) a∗=argmaxaQ(St+1,a;θt)。动作的评估采用 θ ′ \theta' θ′, Y t D o u b l e Q = R t + 1 + γ Q ( S t + 1 , a ∗ ; θ t ′ ) Y_t^{\rm {DoubleQ}}=R_{t+1}+\gamma Q(S_{t+1},a^*;\theta_t') YtDoubleQ=Rt+1+γQ(St+1,a∗;θt′)
c. 优先回放
DQN核心在于目标网络与经验回放。DDQN的核心在于改进了max动作选择操作,解决了过估计问题。
经验回放时,利用均匀采样并不是高效利用数据的方式,因为智能体经历过的所有数据对于智能体的学习并非具有同等重要的意义。智能体在某个状态的学习效率可能比其余状态要高,优先回放打破了均匀采样,赋予学习效率高的状态更大的采样权重。
理想情况下学习效率越高,采样权重应该越大。一个量化定义的方式是,TD偏差 δ \delta δ越大,说明该状态处的值函数与TD目标的差距越大,智能体的更新量越大,因此该出的学习效率越高。我们设样本i处的TD偏差为 δ i \delta_i δi,则该样本处的采样概率为
P ( i ) = p i α ∑ k p k α P(i)=\frac{p_i^\alpha}{\sum_k p_k^\alpha} P(i)=∑kpkαpiα
其中, p i α p_i^{\alpha} piα是由TD偏差 δ i \delta_i δi决定。通常有两种方式,第一种为 p i = ∣ δ i ∣ + ε p_i=|\delta_i|+\varepsilon pi=∣δi∣+ε。第二种方式为 p i = 1 r a n k ( i ) p_i=\frac{1}{\rm {rank}(i)} pi=rank(i)1,其中 r a n k ( i ) \rm {rank} (i) rank(i)为 δ i \delta_i δi的排序。
当我们采用优先回放的概率分布采样时,动作值函数的估计是一个有偏估计,因为采样分布跟动作值函数的分布是两个完全不同的分布,为了矫正这个偏差,我们通常乘以一个重要性采样系数 ω i = ( 1 N ⋅ 1 P ( i ) ) β \omega_i=(\frac{1}{N}\cdot \frac{1}{P(i)})^\beta ωi=(N1⋅P(i)1)β。具有优先回放的DDQN伪代码如下:

四、Dueling DQN
将每个动作状态值函数拆分为状态值函数 V ( s ) V(s) V(s)加上优势函数 A ( s , a ) A(s,a) A(s,a).
Q ( s , a ; θ , α , β ) = V ( s ; θ , β ) + A ( s , a ; θ , α ) Q(s,a;\theta,\alpha,\beta)=V(s;\theta,\beta)+A(s,a;\theta,\alpha) Q(s,a;θ,α,β)=V(s;θ,β)+A(s,a;θ,α)
使用该方法是因为,在某些状态 s t s_t st,无论做什么动作 a t a_t at,对下一个状态 s t + 1 s_{t+1} st+1都没多大影响,当前状态动作函数也与当前动作选择不太相关。在这种情况下,dueling DQN更适用,比DQN学习更快,收敛效果更好。
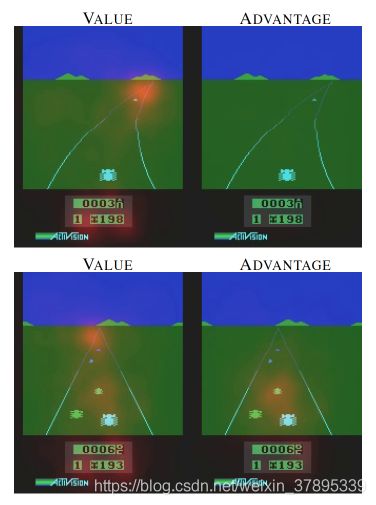
红色部分表示对 Q ( s , a ) Q(s,a) Q(s,a)的影响,可以看出状态值函数更关注地平线附近的障碍,优势函数更关注当前位置附近的障碍。
实现过程
- 可以给神经网络输入S,A输出Q(s,a)。也可以输入S,输出各个动作的Q(s,a)
