【PYTHON3学习】常用内置模块urllib学习总结
1 urllib
提供了一系列用于操作URL的功能
1.1 简单爬虫
1.引入请求模块——from urllib import request
2.打开网页——request.urlopen()
3.读取网页——read
此处以https://www.douban.com为例子
from urllib import request
with request.urlopen('https://www.douban.com') as f:
data=f.read() #二进制流文件
with open('./douban.html','wb') as fw:
f.write(data)
此时查看该文件,就可以看到爬取的网页。
1.2 urlopen入门
1.2.1 查看urlopen()参数如下
>>> from inspect import signature
>>> signature(request.urlopen)
<Signature (url, data=None, timeout=<object object at 0x000002066EEE7D80>, *, cafile=None, capath=None, cadefault=False, context=None)>
常用参数
url:目标资源在网络中的位置。【URL字符串,Request对象】data:data用来指明发往服务器请求中的额外的参数信息(如:在线翻译,在线答题等提交的内容),data默认是None,此时以GET方式发送请求;当用户给出data参数的时候,改为POST方式发送请求。timeout:访问超时时间
1.2.2 timeout
from urllib import request
from urllib import error
import socket
try:
response=request.urlopen('http://www.baidu.com',timeout=0.00001)
except error.URLError as e:
if isinstance(e.reason,socket.timeout):
print('Time out')
1.2.3查看response的类型
>>>response=request.urlopen('http://www.baidu.com')
>>> type(response)
它主要包含的方法有 read() 、 readinto() 、getheader(name) 、 getheaders() 、 fileno() 等函数和 msg 、 version 、 status 、 reason 、 debuglevel 、 closed 等属性
>>> response.msg
'OK'
>>> response.status
200
>>> response.reason
'OK'
>>> response.debuglevel
0
>>> print(response.getheaders())
[('Bdpagetype', '1'), ('Bdqid', '0xb50d24190031d5a7'), ('Cache-Control', 'private'), ('Content-Type', 'text/html'), ...
>>> print(response.getheader('Cache-Control'))
private
1.3 urllib常用方法
| 方法 | 作用 |
|---|---|
| info() | 返回网页的当前环境有关信息 |
| getcode() | 返回网页状态码,若为200则正确,若为其他则错误 |
| geturl() | 返回网页的url |
| urllib.request.quote() | 对网址进行编码 |
| urllib.request.unquote() | 对网址进行解码 |
代码实例:
>>>from urllib import request
>>>response=request.urlopen('http://www.baidu.com')
>>> response.info()
<http.client.HTTPMessage object at 0x000002067168FF48>
>>> response.getcode()
200
>>> response.geturl()
'https://www.baidu.com'
>>> request.quote('https://www.baidu.com')
'https%3A//www.baidu.com'
>>> request.unquote('https%3A//www.baidu.com')
'https://www.baidu.com'
2 模拟浏览器发送GET请求
此时就需要Request对象——通过往Request对象中添加HTTP头,可将请求伪装成浏览器:
如果要进行客户端与服务器端之间的消息传递,我们可以使用HTTP协议请求进行。
在本节内容中介绍两种常用的请求:Get和Post。先来看一下Get请求。
Get请求,通过URL网址传递信息。我们可以把数据直接放在URL中,从而得到想要的信息。
以豆瓣搜索为例子。
当我们用豆瓣搜索罪恶都市时,发现有q=罪恶都市字段
事实上,q为搜索关键字段,故通过get请求+往request对象添加HTTP头,就可以自动使用百度搜索
```python
from urllib import request
url='https://www.douban.com/search?q='
key=request.quote('罪恶都市') #由于字段含有中文,需要编码
url_all=url+key
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'}
req=request.Request(url_all,headers=header)
with request.urlopen(req) as f: #爬去网页
data=f.read()
with open('./dbsearch.html','wb') as fw:#写入文件
fw.write(data)
运行结果
![]()
2.1 Request对象
>>> signature(request.Request)
<Signature (url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)>
Request实例,除了必须要有 url参数之外,还可以设置另外两个参数:
-
data:如果是GET请求,data(默认空),如果是POST请求,需要加上data参数,伴随 url 提交的数据。 -
headers(默认空):是一个字典,包含了需要发送的HTTP报头的键值对。
2.2 如何伪装成浏览器?
要伪装成浏览器,必须往Request对象中以dict方式添加头部信息,其中’User-Agent’尤为重要。
在写爬虫时,如果不加header参数,当前网站就会把你当成爬虫,然后禁止你访问,加入headers可以有效的避免。
那么就有如下两个问题:
- 如何添加头部信息?
- 在定义
Request对象时,便添加头部信息 - 使用
request.add_header()往Request对象添加头部信息(request.get_header()可获取头部信息)
- 在定义
- User-Agent如何获得?
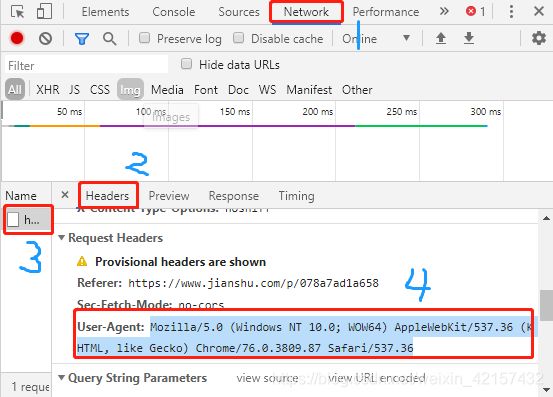
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU 类型、浏览器及版本、浏览器渲染引擎、浏览器语言、浏览器插件等。
标准格式为: 浏览器标识 (操作系统标识; 加密等级标识; 浏览器语言) 渲染引擎标识 版本信息
步骤:打开浏览器——F12——network——选择任一项——headers——查找User-Agent
3 POST——模拟微博登陆
from urllib import request, parse
print('Login to weibo.cn...')
email = input('Email or PhonNumber: ') # 用户输入登录的邮箱名
passwd = input('Password: ') # 用户输入登录的密码
login_data = parse.urlencode([ # 登录数据,用dict类型储存,parse.urlencode将dict转为url参数
('username', email),
('password', passwd),
('entry', 'mweibo'),
('client_id', ''),
('savestate', '1'),
('ec', ''),
('pagerefer', 'https://passport.weibo.cn/signin/welcome?entry=mweibo&r=http%3A%2F%2Fm.weibo.cn%2F')
])
req = request.Request('https://passport.weibo.cn/sso/login')
req.add_header('Origin', 'https://passport.weibo.cn')
req.add_header('User-Agent', 'Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25')
req.add_header('Referer', 'https://passport.weibo.cn/signin/login?entry=mweibo&res=wel&wm=3349&r=http%3A%2F%2Fm.weibo.cn%2F')
with request.urlopen(req, data=login_data.encode('utf-8')) as f:
print('Status:', f.status, f.reason) # 返回页面执行的状态
for k, v in f.getheaders(): # 得到HTTP相应的头和JSON数据
print('%s: %s' % (k, v))
print('Data:', f.read().decode('utf-8')) # 得到页面信息
此处还未搞懂头部信息关键词和对应的值。
4.小结
简单来说,urllib模块提供操作URL的功能,上述知识入门后,可通过utllib实现简单爬虫。
深入了解还待后续学习,感谢你的阅读