Hadoop开发环境搭建
所需文件:
-
VMWare-workstation-full-12.0.0-2985596.exe(Windows上运行虚拟机);
-
CentOS-6.5-x86_64-minimal.iso(Linux 操作系统);
-
Xshell_5.0.exe(链接Windows与Linux ,在Xshell上进行虚拟机操作);
-
Xftp_4.0.0118.1414638732.exe(内网传输,在Windows与Linux之间传输文件);
-
jdk-7u67-linux-x64.rpm(Linux版,JAVA开发工具);
-
Hadoop-2.6.5.tar.gz;
步骤:
一、安装VMware
二、新建虚拟机
(一) 具体步骤(没提到的请选择默认)
1. 创建步骤上
新建虚拟机->自定义安装->稍后安装操作系统->选择安装Linux操作系统->虚拟机名称可改,位置尽量不放C盘,文件路径不要有空格和中文->选择使用网络地址转换(NET)->最大磁盘大小(GB)可以大于实际内存,输个200左右;选择将虚拟磁盘拆分成多个文件。
2. 创建步骤下
设置完成后回到VMware工作台,这时系统框架搭好,开始导入操作系统:在VMware工作台选择搭好的那台虚拟机,右键选择设置,在硬件栏中找到CD/DVD(IDE),单击进入,如图:
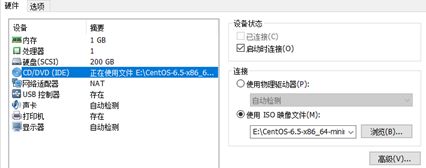
在连接栏中选择使用ISO映像件,点击浏览,将下载好的Linux操作系统ISO文件导入。
3. 进行最初的配置(没提的默认)
开启虚拟机
选择Install or upgrade an existing system
Disc Found栏中选择Skip(跳过)
语言全部选择English
储存类型选择Basic Storage Devices
在Storage Devices Warning栏中选择Yes(如果弹出的话)
Hostname自己取一个,不要有空格和中文
时区(Selected City)选择Shanghai,Asia
Root Password(最高权限用户密码)自己输入
Which type of installation would you like选项卡中选择Create Custom Layout(创建分区,Linux下有三个必须的分区:启动系统用的分区;系统内核用的分区;用户应用的分区)
在Hard Drives中选择Create,在Create Storage选项卡中选择Standard Partition(标准分区)
在Add Partition选项卡中如下图:
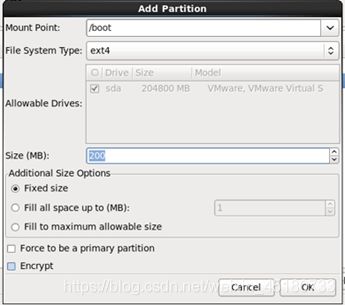

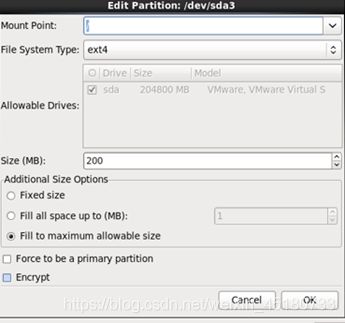
完成后点击next,如果出现Format Warning选项卡,点击Format>>出现Writing storage configuration to disk选项卡(更改储存配置),选择Write change to disk>>一直默认到最后,点击Reboot配置完成。
4.设置IP(配置虚拟机网络)
在VMware工作台中的编辑选项卡下点击虚拟网络编辑器
在虚拟网络编辑器选项卡下查看子网IP(注意这里的IP是虚拟机使用的IP)
在Windows桌面下键入WIN+R,在弹出窗口输入cmd,回车进入DOS命令,敲下ipconfig,查看当前连上外网的适配器的IPv4 地址,并记住。(注意:看的是连上外网的适配器下的IP)
开启虚拟机
登录界面首先输入用户名,这里默认是root,密码是刚才设置的(这里出于保护,不显示你输入的密码,输完Enter就行)
出现[root@xxx ~]# 说明登录成功。(注意Ctrl+Alt鼠标键盘跳出虚拟机)
接下来使用Linux命令,输入vi /etc/sysconfig/network- scripts/ifcfg-eth0 ;进入下图(小技巧:名字输入一半按Tab自动补全):
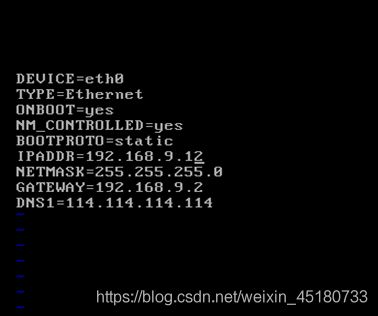
说明:Linux下输入i编辑文档,按Esc退出编辑,再输入:wq保存,输入:!q强制退出。
上图修改如下:

- IPADDR是虚拟机上IP地址,怎么填呢?这里先找到主机的IP(在Windows用DOS命令ipconfig出来的),
假如主机IP是192.168.1.10;前面192.168.1 这三位留下:
IPADDR=192.168.1.X(X取3到255,X不可以全0或全1); - NETMASK(子关掩码,默认255.255.255.0);
- GATEWAY(网关,前三位与虚拟机IP相同,最后一位必须是2)=192.168.1.2;
- DNS1(域名服务器),首先要设置Windows主机下的DNS;
其它内容与上图一样。 - Windows的DNS步骤:
控制面板->网络和 Internet->网络和共享中心->更改适配器设置->选中连接外网的设备->右键选择属性->在网络选项卡下找到Internet协议版本4,双击进入;
选择使用下面的DNS服务器地址,首选DNS服务器改为不常见的IP地址,这里填一个114.114.114.114;
完成后保存,再转到虚拟机内,配置虚拟机DNS1为114.114.114.114(与主机相同)。
编辑完成后,按Esc,再:wq 保存(注意有冒号)。
退出后键入命令service network restart(更新配置),出来全是OK才行。
最后输入ping www.baidu.com 看是否成功,如果不停出现ms(导包时间单位)字样,说明成功,按Crtl+C退出。
之后输入rm -fr /etc/udev/rules.d/70-persistent-net.rules(这行命令是强制删除etc/udev/rules.d目录下的70-persistent-net.rules文件,不删除的话配置的IP、网关和子网掩码等信息就不能生效)。
IP配置完成。
5. 关闭防火墙&Selinux
在虚拟机中键入命令service iptables stop ,完成后再键入命令chkconfig iptables off ,.完成后键入vi /etc/selinux/config进入界面按i 编辑内容,改为SELINUX=disabled;按Esc退出编辑,:wq 保存(冒号别忘了),最后关机。
纯净的Linux系统装完了。
6. 设置快照(快照类似于游戏存档)
在虚拟机工作台最上面一排找一个小图标,名字叫管理此虚拟机的快照,点击它出现下图:

点击拍摄快照,然后确认。
7. 克隆四台虚拟机(克隆的功能就是复制)
继续打开快照,选中快照,点击克隆>>选择现有快照>>选择创建链接克隆>>位置和名称自己取,这里取node1(主机名node1等会要用)>>点击完成。
给node1配置IP:vi /etc/sysconfig/network-scripts/ifcfh-eth0(小技巧:名字输入一半按Tab自动补全)
按i 编辑内容,
这里要改的只有一项IPADDR;四位中的最后一位在3到255间选,这里我选31(192.168.1.31 IP待会要用);
Esc然后:wq保存退出;
输入service network restart 出来全是ok才行,ping www,baidu.com看是否成功。
配置主机名:vi /etc/sysconfig/network
HOSTNAME=node1
Windows的hosts配置:
路径是C:/windows/system32/drivers/etc/hosts ,右键以记事本打开,在最后一行回车,然后输入192.168.1.31 node1(注意左边是虚拟机的IP,右边是虚拟机主机名)
要权限的话有两个办法:1.把hosts 文件拖到桌面,编辑后放回去;2.下载notepad++,用它编辑。
8. 将另外三台按照上面步骤7 克隆,注意IP和主机名不要重名。这里我取名如下:
192.168.1.32 node2
192.168.1.33 node3
192.168.1.34 node4
配置每台虚拟机中的hosts: vi /etc/hosts
按i 编辑内容;
在最后一行回车,然后输入
192.168.1.31 node1
192.168.1.32 node2
192.168.1.33 node3
192.168.1.34 node4
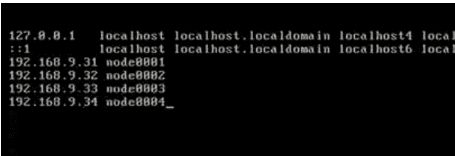
参考下图(四台虚拟机的IP和主机名):
9. 遇到的一些问题
-
注意复制命令时,由于Linux下的输入可能与文档的输入字符串不同,会出错;可以自己敲入。
-
文件路径和主机名不要有空格中文。
-
创建虚拟机问题
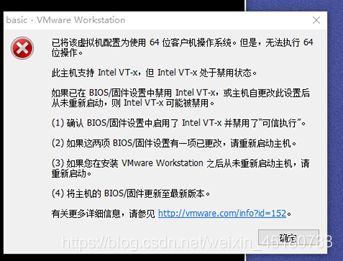
Windows主机下BIOS设置为禁用虚拟机,导致无法使用虚拟机。
Windows开机按DEL,进入BIOS;BIOS中依次选择:Advanced(高级)——CPU Configuration——Secure Virtual Machine,设置为:Enabled(启用)就行了。 -
句柄无效
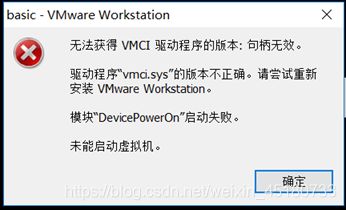
方法1:进入虚拟机目录,找到.vmx结尾的文件,以记事本方式打开,找到 vmci0.present=“TRUE” 一行,将true改为false并保存。
方法2:重装虚拟机。 -
无法打开虚拟机

重装虚拟机,路径与文件名不要有中文和空格!! -
执行service network restart时的问题

可能原因1:前面的/etc/sysconfig/network-scripts/ifcfh-eth0没有可能配对。
vi /etc/sysconfig/network-scripts/ifcfh-eth0进入,看是否DEVICE=eth0 。
可能原因2:没有删除etc/udev/rules.d目录下的70-persistent-net.rules文件
命令:rm -fr /etc/udev/rules.d/70-persistent-net.rules -
内存不足
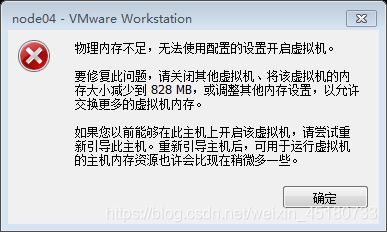
修改分配的虚拟机内存:
在VMware工作台找到创建的虚拟机,右键选择设置,在硬件栏中将内存调到512M。 -
配置文件错误
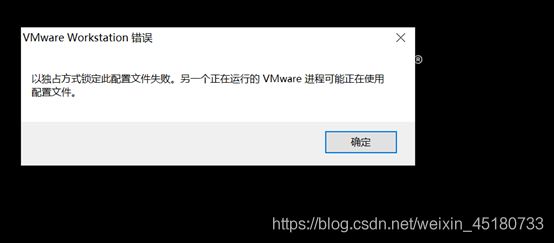
方法1:Windows下打开任务处理器(Ctrl + Alt + Delete),结束所有VMware进程,重启Windows。
方法2:删除虚拟机系统目录下的三个以.lck结尾的文件夹; windows下DOS命令窗口输入netsh winsock reset(重置网络配置),重启电脑。
三、Hapdoop伪分布安装
说明(Linux下三种安装文件):
.rpm: 相当于Windows内的.exe文件
.tar解压安装
.yum
(一)安装Xshell,连接虚拟机:
步骤:文件>>新建>>名称为虚拟机主机名,主机那一栏填虚拟机IP>>点击确定。
安装Xftp4.exe;然后在Xshell里按下图点击:
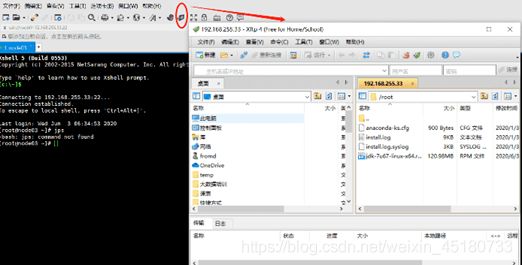
找到要传输的文件,右键选择传输。
(二)配置
1. 传输
通过XShell把Windows中的文件Jdk.rpm上传输到虚拟机,
在虚拟机中键入命令rpm -I jdk-7u67-linux-x64.rpm (安装JDK)。
2. 编辑
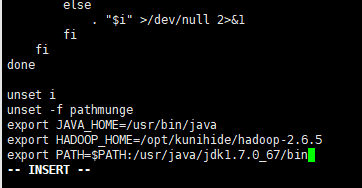
输入vi + /etc/profile 按i进入编辑,
修改命令为export JAVA_HOME=/usr/bin/java
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin
按Esc退出编辑:wq保存退出,输入source /etc/profile回车更新。
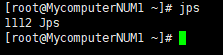
3. 验证
输入jps回车
4. 免秘钥
在家目录下(~是家目录,按cd 回车进入),输入ll -a ,看看有没有.ssh文件,若无,则先输入ssh localhost,登录完成后输入exit(退出登录)。
输入ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa ;(这是密钥生成器以dsa的方式生成密钥,放入家目录的.ssh/id_dsa中)。
输入cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys ,(把id_dsa.pub追加到authorized_keys)。
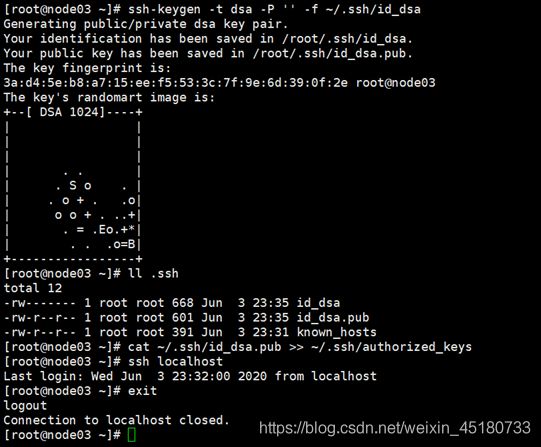
5. 验证
先后输入ssh localhost 验证 (别忘了exit)和ssh node1 验证(node1是主机名,别忘了exit)。
(三)安装Hadoop2.6.5
1. 用Xshell传输hadoop.tar文件
在虚拟机中敲入tar xf hadoop-2.6.5.tar.gz -C /opt/qweqwe (注:-C的C 是大写,qweqwe可以自己改,这行的命令是将hadoop 安装到qweqwe文件夹下);
然后cd /opt/qweqwe/hadoop-2.6.5查看是否安装好,没有报错说明成功。
2. 配置
(1)要想在任意目录下启动hadoop,就要在配置文件里做些修改。
输入vi + /etc/profile 按i进入编辑
修改
export JAVA_HOME=/usr/bin/java
export HADOOP_HOME=/opt/qweqwe/hadoop-2.6.5(这里的qweqwe是自己取过的)
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
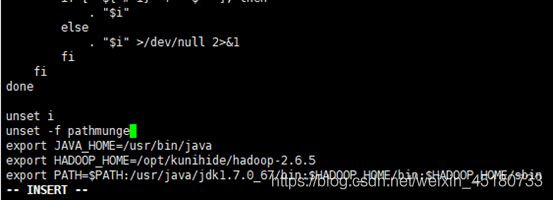
输入hd按Tab键可以联想出hdfs;输入start-d按Tab键可以联想出start-dfs.;就表示配置成功了。
(2)修改hadoop配置文件信息
输入:cd /opt/qweqwe/hadoop-2.6.5/etc/hadoop(这里的qweqwe是自己取过的)
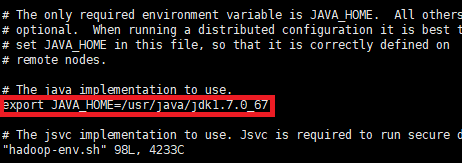
vi hadoop-env.sh
vi mapred-env.sh
vi yarn-env.sh
依次输入上面三个语句,把这三个文件里的JAVA_HOME都改成绝对路径/usr/java/jdk1.7.0_67。

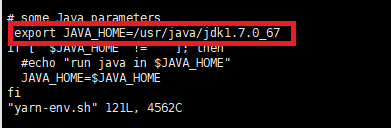
(3)配置
输入vi core-site.xml
在里面的
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
</property>
注意:里面的node1是虚拟机主机名。
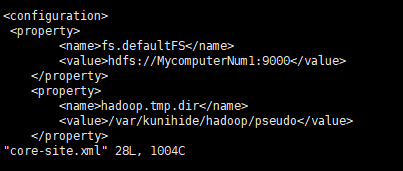
(4)配置slaves文件
输入vi slaves进入,将内容改为node1 (自己的虚拟机主机名)。
(5)格式化hdfs
输入hdfs namenode -format (只能格式化一次,再次启动集群不要执行,否则clusterID变了)。
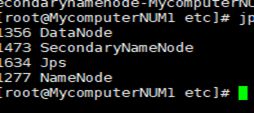
(6)启动集群
start-dfs.sh>>输入jps验证出现类似下图说明成功:
(7)浏览器显示
在Windows的浏览器里输入node1:50070(node1是 虚拟机主机名,别用360浏览器!)
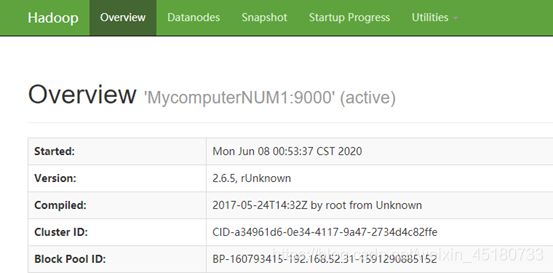

在虚拟机中
- .创建目录:
hdfs dfs -mkdir -p /user/root
- 上传文件:
hdfs dfs -put 500miles.txt /user/root

500miles.txt在windows上创一个,名字可以改,内容可以打一段英文上去,通过Xshell传入虚拟机。
3. Hadoop伪分布式下运行wordcount
(1)在hdfs里建立输入目录和输出目录
hdfs dfs -mkdir -p /data/input
hdfs dfs -mkdir -p /data/output

(2)将要统计数据的文件上传到输入目录并查看
hdfs dfs -put 500miles.txt /data/input
hdfs dfs -ls /data/input

(3)进入MapReduce目录
cd /opt/qweqwe/hadoop-2.6.5/share/hadoop/mapreduce/ (qweqwe是自己上面建的)
(4)在MapReduce下运行wordcount
hadoop jar Hadoop-mapreduce-examples-2.6.5.jar wordcount /data/input /data/output/result
语句说明:wordcount是MapReduce包中一个类。作用是将/data/input中的文件放到/data/output/result中并计算大小。
(5)查看运行结果
hdfs dfs -ls /data/output/result
hafs dfs -cat /data/output/result/part-r-00000
(6)查看log
cd /opt/qweqwe/hadoop-2.6.5/logs
tail -100 hadoop-root-datanode-node1.log
(7) 停止集群
stop-dfs.sh (关闭集群,到这一步hadoop配置完成)
(四)遇到的一些问题
- 连接

- 如果浏览器出现无法访问,这里陈列可能的几种原因:
一 windows或Linux防火墙没关,
一 hosts没配好,
一 浏览器拦截。 - jps问题
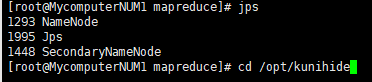
少了datanode,或者其它的,查看log最后一百行。
cd /opt/qweqwe/hadoop-2.6.5/logs
tail -100 hadoop-root-datanode-node1.log