SurfaceFlinger学习笔记(三)之SurfaceFlinger进程
概述
本系列是基于android Q 即android10
SurfaceFlinger学习笔记(一)应用启动流程
SurfaceFlinger学习笔记(二)之Surface
SurfaceFlinger学习笔记(三)之SurfaceFlinger进程
SurfaceFlinger学习笔记(四)之HWC2
SurfaceFlinger学习笔记(五)之HWUI
SurfaceFlinger学习笔记(六)之View Layout Draw过程分析
android底层用到了许多C++11,参考C++11简介
在Android中,一个窗口用一个Surface描述。多个窗口(窗口不一定都是Activity),需要同时显示,我们就需要将多个窗口进行合并。这就需要显示系统中重量级的服务SurfaceFlinger,Surfaceflinger控制窗口的合成,将多个窗口合并成一个,再送到LCD

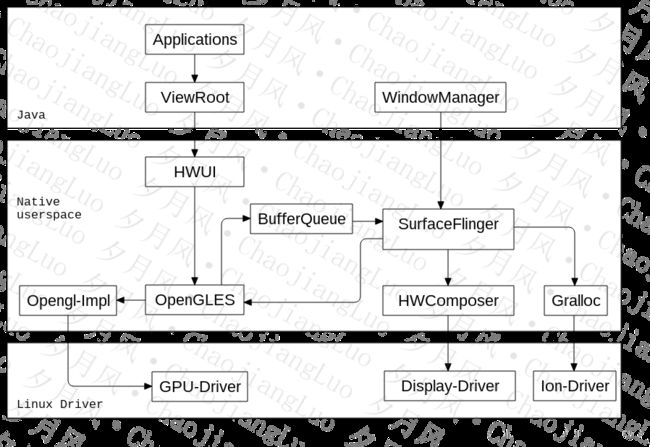
SurfaceFlinger合成,有两种方式,Client和Device。Client就是Client合成完Layer后再将合成后的数据给到HWComposer,HWComposer此时做的工作很少,直接给到Display。Device则是将未合成的Layer,给到硬件合成的设备,合成完后再给到Display
应用启动流程回顾
详细流程参考
SurfaceFlinger学习笔记(一)应用启动流程
SurfaceFlinger学习笔记(二)之Surface和HWUI
- Activity::startActivityForResult调用mInstrumentation.execStartActivity调用ActivityManager.getService().startActivity
- ActivityManagerService::startActivityAsUser调用ActivityStartController.obtainStarter调用ActivityStarter.execute调用ActivityStarter.startActivityMayWait
ActivityStarter.startActivityUnchecked(这个方法里会根据启动标志位和Activity启动模式来决定如何启动一个Activity以及是否要调用deliverNewIntent方法通知Activity有一个Intent试图重新启动它)- ActivityStackSupervisor.resumeFocusedStackTopActivityLocked调用ActivityStack.resumeTopActivityInnerLocked
- 在ActivityStack.resumeTopActivityInnerLocked方法中会去判断是否有Activity处于Resume状态,如果有的话会先让这个Activity执行Pausing过程,然后再执行startSpecificActivityLocked方法启动要启动Activity
栈顶Activity执行onPause方法退出流程
frameworks/base/services/core/java/com/android/server/am/ActivityStack.java
- 在ActivityStack.startPausingLocked方法中通过ClientLifecycleManager的scheduleTransaction方法把PauseActivityItem事件加入到执行计划中,开始栈顶的pausing过程,然后执行ClientTransaction.schedule,ClientTransaction.schedule方法的mClient是一个IApplicationThread类型,ActivityThread的内部类ApplicationThread派生这个接口类并实现了对应的方法。所以直接跳转到ApplicationThread中的scheduleTransaction方法。ActivityThread类中并没有定义scheduleTransaction方法,所以调用的是他父类ClientTransactionHandler的scheduleTransaction方法
- 在ClientTransactionHandler.scheduleTransaction方法中调用了sendMessage方法,这个方法是一个抽象方法,其实现在ClientTransactionHandler派生类的ActivityThread中,ActivityThread.sendMessage方法会把消息发送给内部名字叫H的Handler
- Handler H的实例接收到EXECUTE_TRANSACTION消息后调用TransactionExecutor.execute方法切换Activity状态。TransactionExecutor.execute方法里面先执行Callbacks,然后改变Activity当前的生命周期状态。此处由于没有Callback所以直接跳转executeLifecycleState方法。
- 在executeLifecycleState方法里面,会先去调用TransactionExecutor.cycleToPath执行当前生命周期状态之前的状态,然后执行ActivityLifecycleItem.execute方法。由于是从ON_RESUME状态到ON_PAUSE状态切换,中间没有其他状态,cycleToPath这个情况下没有做什么实质性的事情,直接执行execute方法。前面在ActivityStack.startPausingLocked方法里面scheduleTransaction传递的是PauseActivityItem对象,所以executeLifecycleState方法里调用的execute方法其实是PauseActivityItem.execute方法。
- 在PauseActivityItem.execute方法中调用ActivityThread.handlePauseActivity方法,经过一步步调用来到performPauseActivity方法,在这个方法中会先去判断是否需要调用callActivityOnSaveInstanceState方法来保存临时数据,然后执行Instrumentation.callActivityOnPause方法继续执行pasue流程。
- Instrumentation.callActivityOnPause方法中直接调用Activity.performPause
Activity所在的应用进程启动过程
- ActivityStackSupervisor.startSpecificActivityLocked方法,在这个方法中会去根据进程和线程是否存在判断App是否已经启动,如果已经启动,就会调用realStartActivityLocked方法继续处理。如果没有启动则调用ActivityManagerService.startProcessLocked方法创建新的进程处理。接下来跟踪一下一个新的Activity是如何一步步启动的。
- ActivityManagerService.startProcessLocked方法经过多次跳转最终会通过Process.start方法来为应用创建进程。经过一步步调用,可以发现其最终调用了Zygote并通过socket通信的方式让Zygote进程fork出一个新的进程,并根据传递的”android.app.ActivityThread”字符串,反射出该对象并执行ActivityThread的main方法对其进行初始化
- 在ActivityThread.main方法中对ActivityThread进行了初始化,创建了主线程的Looper对象并调用Looper.loop()方法启动Looper,把自定义Handler类H的对象作为主线程的handler。接下来跳转到ActivityThread.attach方法
- 在ActivityThread.attach方法中,首先会通过ActivityManagerService为这个应用绑定一个Application,然后添加一个垃圾回收观察者,每当系统触发垃圾回收的时候就会在run方法里面去计算应用使用了多少内存,如果超过总量的四分之三就会尝试释放内存。最后,为根View添加config回调接收config变化相关的信息
- 在ActivityManagerService.attachApplication方法中经过多次跳转执行到ActivityStackSupervisor.attachApplicationLocked调用ActivityStackSupervisor.realStartActivityLocked方法。在ActivityStackSupervisor.realStartActivityLocked方法中为ClientTransaction对象添加LaunchActivityItem的callback,然后设置当前的生命周期状态,最后调用ClientLifecycleManager.scheduleTransaction方法执行
- 调用ClientLifecycleManager.scheduleTransaction方法之后具体是如何执行的前面已经分析过了,这里就不再分析了。callback后跳转到LaunchActivityItem.execute,然后执行到ActivityThread.handleLaunchActivity
- 在ActivityThread.performLaunchActivity方法中首先对Activity的ComponentName、ContextImpl、Activity以及Application对象进行了初始化并相互关联,然后设置Activity主题,最后调用Instrumentation.callActivityOnCreate方法。
- 从Instrumentation.callActivityOnCreate方法继续追踪,跳转到Activity.performCreate方法,在这里我们看到了Activity.onCreate方法。
- 至此executeCallbacks执行完毕,开始执行executeLifecycleState方法。先执行cycleToPath方法,生命周期状态是从ON_CREATE状态到ON_RESUME状态,中间有一个ON_START状态,所以会执行ActivityThread.handleStartActivity方法。
10 . 执行完毕cycleToPath,开始执行ResumeActivityItem.execute方法。经过上面的多次跳转最终调用到Activity.onResume方法,Activity启动完毕。
Surface相关的基础知识介绍
- 显示层(Layer)和屏幕组成

- 屏幕位于一个三维坐标系中,其中Z轴从屏幕内指向屏幕外
- 编号为①②③的矩形块叫显示层(Layer)。每一层有自己的属性,例如颜色、透明度、所处屏幕的位置、宽、高等。除了属性之外,每一层还有自己对应的显示内容,也就是需要显示的图像。
- 在Android中,Surface系统工作时,会由SurfaceFlinger对这些按照Z轴排好序的显示层进行图像混合,混合后的图像就是在屏幕上看到的美妙画面了
Surface系统提供了三种属性,一共四种不同的显示层
- 第一种属性是eFXSurfaceNormal属性,大多数的UI界面使用的就是这种属性。它有两种模式:
1)Normal模式,这种模式的数据,是通过前面的mView.draw(canvas)画上去的。这也是绝大多数UI所采用的方式。
2)PushBuffer模式,这种模式对应于视频播放、摄像机摄录/预览等应用场景。以摄像机为例,当摄像机运行时,来自Camera的预览数据直接push到Buffer中,无须应用层自己再去draw了。- 第二种属性是eFXSurfaceBlur属性,这种属性的UI有点朦胧美,看起来很像隔着一层毛玻璃。
- 第三种属性是eFXSurfaceDim属性,这种属性的UI看起来有点暗,好像隔了一层深色玻璃。从视觉上讲,虽然它的UI看起来有点暗,但并不模糊。而eFXSurfaceBlur不仅暗,还有些模糊。
关于Surface系统的显示层属性定义,读者可参考ISurfaceComposer.h
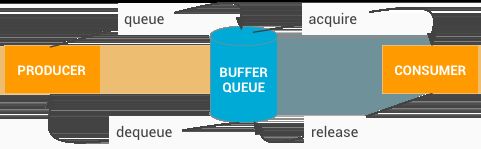
PageFlipping
PageFlipping的中文名叫画面交换,其操作过程如下所示:
- 分配一个能容纳两帧数据的缓冲,前面一个缓冲叫FrontBuffer,后面一个缓冲叫BackBuffer。
- 消费者使用FrontBuffer中的旧数据,而生产者用新数据填充BackBuffer,二者互不干扰。
- 当需要更新显示时,BackBuffer变成FrontBuffer,FrontBuffer变成BackBuffer。如此循环,这样就总能显示最新的内容了。这个过程很像我们平常的翻书动作,所以它被形象地称为PageFlipping。
说白了,PageFlipping其实就是使用了一个只有两个成员的帧缓冲队列,以后在分析数据传输的时候还会见到诸如dequeue和queue的操作
图像混合
Surface系统支持软硬两个层面的图像混合
- 软件层面的混合:例如使用copyBlt进行源数据和目标数据的混合
- 硬件层面的混合:使用Overlay系统提供的接口
无论是硬件还是软件层面,都需将源数据和目标数据进行混合,混合需考虑很多内容,例如源的颜色和目标的颜色叠加后所产生的颜色
copyBlt和Overlay
- copyBlt,从名字上看,是数据拷贝,它也可以由硬件实现,例如现在很多的2D图形加速就是将copyBlt改由硬件来实现,以提高速度的。但不必关心这些,我们只需关心如何调用copyBlt相关的函数进行数据混合即可
- Overlay方法必须有硬件支持才可以,它主要用于视频的输出,例如视频播放、摄像机摄像等,因为视频的内容往往变化很快,所以如改用硬件进行混合效率会更高
应用进程
- 应用进程的SurfaceSession 的创建会调用 JNI,在 JNI 调用 nativeCreate,创建 SurfaceComposerClient 对象, 作为跟 SurfaceFlinger 通信的代理对象
* frameworks/base/core/jni/android_view_SurfaceSession.cpp
static jlong nativeCreate(JNIEnv* env, jclass clazz) {
SurfaceComposerClient* client = new SurfaceComposerClient();
client->incStrong((void*)nativeCreate);
return reinterpret_cast<jlong>(client);
}
* frameworks/native/libs/gui/SurfaceComposerClient.cpp
void SurfaceComposerClient::onFirstRef() {
//getComposerService() 将返回 SF 的 Binder 代理端的 BpSurfaceFlinger 对象
sp<ISurfaceComposer> sf(ComposerService::getComposerService());
if (sf != nullptr && mStatus == NO_INIT) {
sp<ISurfaceComposerClient> conn;
//先调用 SF 的 createConnection()
conn = sf->createConnection();
if (conn != nullptr) {
mClient = conn;
mStatus = NO_ERROR;
}
}
}
ComposerService:
定义:frameworks\native\include\private\gui\ComposerService.h
实现:frameworks\native\libs\gui\SurfaceComposerClient.cpp
作用:通过Singleton,定义单例类,初始化时候调用connectLocked,获取SurfaceFlinger服务代理ISurfaceComposer,并注册死亡通知
SurfaceComposerClient:
定义:frameworks\native\include\gui\SurfaceComposerClient.h
实现:frameworks\native\libs\gui\SurfaceComposerClient.cpp
作用:这个对象会和SurfaceFlinger进行交互,因为SurfaceFlinger派生于SurfaceComposer
通过ComposerService和服务端通信,并通过调用binder的createConnection获取ISurfaceComposerClient
onFirstRef:第一次引用的时候,调用binder的createConnection才真正的建立连接,向服务端创建一个ISurfaceComposerClient类型的mClient,负责和服务端通信
- java层的SurfaceControl在构造时调用jni方法,nativeCreate,传递一个SurfaceSession,然后通过SurfaceSession 获取SurfaceComposerClient,SurfaceSession 的创建会调用 JNI,在 JNI 调用 SurfaceSession.nativeCreate,创建 SurfaceComposerClient 对象, 作为跟 SurfaceFlinger 通信的代理对象,然后调用SurfaceComposerClient.createSurfaceChecked创建一个native层的SurfaceControl
* frameworks/base/core/jni/android_view_SurfaceControl.cpp
static jlong nativeCreate(JNIEnv* env, jclass clazz, jobject sessionObj ...) {
sp<SurfaceComposerClient> client;
if (sessionObj != NULL) {
client = android_view_SurfaceSession_getClient(env, sessionObj);
} else {
client = SurfaceComposerClient::getDefault();//调用内部类DefaultComposerClient创建一个单例SurfaceComposerClient
}
SurfaceControl *parent = reinterpret_cast<SurfaceControl*>(parentObject);
sp<SurfaceControl> surface;
LayerMetadata metadata;
Parcel* parcel = parcelForJavaObject(env, metadataParcel);
if (parcel && !parcel->objectsCount()) {
status_t err = metadata.readFromParcel(parcel);
...
}
status_t err = client->createSurfaceChecked(
String8(name.c_str()), w, h, format, &surface, flags, parent, std::move(metadata));
...
surface->incStrong((void *)nativeCreate);
return reinterpret_cast<jlong>(surface.get());
}
* frameworks/native/libs/gui/SurfaceComposerClient.cpp
void SurfaceComposerClient::onFirstRef() {
sp<ISurfaceComposer> sf(ComposerService::getComposerService());
if (sf != nullptr && mStatus == NO_INIT) {
sp<ISurfaceComposerClient> conn;
conn = sf->createConnection();
if (conn != nullptr) {
mClient = conn;
mStatus = NO_ERROR;
}
}
}
status_t SurfaceComposerClient::createSurfaceChecked(const String8& name, uint32_t w, uint32_t h,PixelFormat format,sp<SurfaceControl>* outSurface, uint32_t flags,SurfaceControl* parent,LayerMetadata metadata) {
...
err = mClient->createSurface(name, w, h, format, flags, parentHandle, std::move(metadata),
&handle, &gbp);
if (err == NO_ERROR) {
*outSurface = new SurfaceControl(this, handle, gbp, true /* owned */);
}
return err;
}
这里和服务端通信的接口有和ISurfaceComposer.createConnection
SurfaceFlinger进程
进程启动:
SurfaceFlinger是一个系统级的服务,Android系统启动的过程中就会启动SurfaceFlinger,通过init.rc配置bin启动,然后调用到main_surfaceflinger的main中,然后通过surfaceflinger::createSurfaceFlinger进入到SurfaceFlingerFactory启动SurfaceFlinger主服务,并调用init
SurfacFlinger进程中主要4个服务:
- startGraphicsAllocatorService主要是启动allocator
- DisplayService,主要负责DisplayEvent的处理,在main_surfaceflinger中启动
- SurfaceFlinger,主要显示相关的,最重要的服务

Client和SurfaceFlinger的关系:

应用端SurfaceComposerClient通过接口ISurfaceComposerClient和SurfaceFlinger的Client建立联系。
服务端创建Client后,把指针返回给应用端,并保存为ISurfaceComposerClient。
应用端通过的ComposerService通过ISurfaceComposer和SurfaceFlinger建立联系。
- SurfaceFlinger初始化流程
- onFirstRef中创建了自己的消息队列mEventQueue,SurfaceFlinger的消息队列
- 启动EventThread,主要是用以处理和分发Vsync。调用mScheduler的createConnection函数创建的,它的名字是"app"
- 初始化了Client合成模式(GPU)合成时,需要用到的RenderEngine
- 初始化HWComposer,注册回调接口registerCallback,HAL会回调一些方法。
- 如果是VR模式,创建mVrFlinger
- 创建mEventControlThread,处理Event事件,如Vsync事件和hotplug事件。
- 初始化显示设备initializeDisplays
* frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::init() {
mAppConnectionHandle = mScheduler->createConnection("app", mPhaseOffsets->getCurrentAppOffset(), resyncCallback, impl::EventThread::InterceptVSyncsCallback());
mSfConnectionHandle = mScheduler->createConnection("sf", mPhaseOffsets->getCurrentSfOffset(), resyncCallback,
[this](nsecs_t timestamp) {
mInterceptor->saveVSyncEvent(timestamp); });
mEventQueue->setEventConnection(mScheduler->getEventConnection(mSfConnectionHandle));
mVsyncModulator.setSchedulerAndHandles(mScheduler.get(), mAppConnectionHandle.get(), mSfConnectionHandle.get());
...
renderEngineFeature |= (useColorManagement ? renderengine::RenderEngine::USE_COLOR_MANAGEMENT : 0);
renderEngineFeature |= (useContextPriority ? renderengine::RenderEngine::USE_HIGH_PRIORITY_CONTEXT : 0);
renderEngineFeature |= (enable_protected_contents(false) ? renderengine::RenderEngine::ENABLE_PROTECTED_CONTEXT : 0);
// TODO(b/77156734): We need to stop casting and use HAL types when possible.
// Sending maxFrameBufferAcquiredBuffers as the cache size is tightly tuned to single-display.
mCompositionEngine->setRenderEngine(
renderengine::RenderEngine::create(static_cast<int32_t>(defaultCompositionPixelFormat),renderEngineFeature, maxFrameBufferAcquiredBuffers));
LOG_ALWAYS_FATAL_IF(mVrFlingerRequestsDisplay, "Starting with vr flinger active is not currently supported.");
mCompositionEngine->setHwComposer(getFactory().createHWComposer(getBE().mHwcServiceName));
mCompositionEngine->getHwComposer().registerCallback(this, getBE().mComposerSequenceId);
// Process any initial hotplug and resulting display changes.
processDisplayHotplugEventsLocked();
..
// initialize our drawing state
mDrawingState = mCurrentState;
// set initial conditions (e.g. unblank default device)
initializeDisplays();
...
}
EventThread
EventThread并不是一个线程,它的内部有一个线程,这个线程就是用来处理底层Vsync的接收以及分发的,这个线程是一个死循环,当它没收到事件请求时会通过C++条件变量调用wait陷入等待状态
应用层请求Vsync的过程其实就是通过这个条件变量调用notify唤醒EventThread内部这个线程,然后从mPendingEvents中获取到Vsync信息分发给感兴趣的进程
Scheduler.createConnection
- createConnection这个函数在SurfaceFlinger中调用了两次,一次是创建"app"的Connection,一次是创建"sf"的Connection,我们可以理解为创建两套连接,一套给app使用,一套个surfaceFlinger使用,两套连接的用connectionName以及id进行标识,(id为0,connectionName等于”app“的)与(id为1,connectionName等于”sf“的)
- createConnection函数根据connectionName创建EventThread,根据EventThread创建EventThreadConnection,然后创建ConnectionHandle,根据ConnectionHandle,EventThreadConnection,EventThread最终创建Connection,并以id为key,Connection为value加入到mConnections的map中,最终返回”app“的ConnectionHandle
EventThreadConnection
继承BnDisplayEventConnection,为DisplayEvent的服务端,构造函数中最重要的就是创建了mChannel,mChannel是gui::BitTube类型
EventThreadConnection代表应用层到SurfaceFlinger进程的连接,每一个上层的ViewRootImpl都对应一个EventThreadConnection,因为每个View视图都需要Vsync来开启绘制工作
gui::BitTube
gui::BitTube的构造函数:这里传递的DefaultSize为4kb,定义在DEFAULT_SOCKET_BUFFER_SIZE
BitTube的init函数主要是通过socketpair函数创建一对socket,socketpair()函数用于创建一对无名的、相互连接的socket,如果成功,则返回0,创建好的socket分别是sv[0]和sv[1];否则返回-1
- 这对socket可以用于全双工通信,每一个socket既可以读也可以写。例如,可以往sv[0]中写,从sv[1]中读,或者从sv[1]中写,从sv[0]中读
- 如果往一个socket(如sv[0])中写入后,再从该socket读时会阻塞,只能在另一个socket中(sv[1])上读成功
- 读、写操作可以位于同一个进程,也可以分别位于不同的进程
通过socketpair创建好了一对socket之后,再通过setsockopt对socket进行设置,再调用fcntl函数针对socket描述符提供控制
首先应用层想要绘制UI,则需要向native层注册接收下一个到来的Vsync,注册的过程是通过EventThreadConnection的Bp端最终调用到SurfaceFlinger进程的EventThread的requestNextVsync函数
* frameworks/native/services/surfaceflinger/Scheduler/Scheduler.cpp
sp<Scheduler::ConnectionHandle> Scheduler::createConnection(const char* connectionName, int64_t phaseOffsetNs, ResyncCallback resyncCallback, impl::EventThread::InterceptVSyncsCallback interceptCallback) {
//id从0累加
const int64_t id = sNextId++;
//创建对应connectionName名字的EventThread
std::unique_ptr<EventThread> eventThread = makeEventThread(connectionName,mPrimaryDispSync.get(), phaseOffsetNs, std::move(interceptCallback));
auto eventThreadConnection = createConnectionInternal(eventThread.get(), std::move(resyncCallback));
//创建ConnectionHandle,与id对应
mConnections.emplace(id, std::make_unique<Connection>(new ConnectionHandle(id), eventThreadConnection, std::move(eventThread)));
return mConnections[id]->handle;
}
sp<EventThreadConnection> Scheduler::createConnectionInternal(EventThread* eventThread, ResyncCallback&& resyncCallback) {
//调用EventThread的createEventConnection函数
return eventThread->createEventConnection(std::move(resyncCallback));
}
* frameworks/native/services/surfaceflinger/Scheduler/EventThread.cpp
sp<EventThreadConnection> EventThread::createEventConnection(ResyncCallback resyncCallback) const {
return new EventThreadConnection(const_cast<EventThread*>(this), std::move(resyncCallback));
}
* frameworks/native/libs/gui/BitTube.cpp
void BitTube::init(size_t rcvbuf, size_t sndbuf) {
int sockets[2];
if (socketpair(AF_UNIX, SOCK_SEQPACKET, 0, sockets) == 0) {
size_t size = DEFAULT_SOCKET_BUFFER_SIZE;
setsockopt(sockets[0], SOL_SOCKET, SO_RCVBUF, &rcvbuf, sizeof(rcvbuf));
setsockopt(sockets[1], SOL_SOCKET, SO_SNDBUF, &sndbuf, sizeof(sndbuf));
setsockopt(sockets[0], SOL_SOCKET, SO_SNDBUF, &size, sizeof(size));
setsockopt(sockets[1], SOL_SOCKET, SO_RCVBUF, &size, sizeof(size));
fcntl(sockets[0], F_SETFL, O_NONBLOCK);
fcntl(sockets[1], F_SETFL, O_NONBLOCK);
//建立Fd与socket的关联,很明显这一对sockets一个用来接受消息,一个用来发送消息
//Vsync到来的时候通过mSendFd写入消息,然后app监听mReceiveFd接受消息,就完成了app对Vsync的接收
mReceiveFd.reset(sockets[0]);
mSendFd.reset(sockets[1]);
} else {
mReceiveFd.reset();
}
}
- SurfaceFlinger继承BnSurfaceComposer,即ISurfaceComposer的Bn端。实现了HWC2::ComposerCallback回调,死亡接收DeathRecipient,以及Dump信息PriorityDumper。为SurfaceFlinger服务端。HWC2::ComposerCallback分别对应三种事件类型:热插拔,屏幕刷新,Vsync信号,surfaceflinger实现了这三个回调方法
ComposerCallback大概调用栈为:
hardware->BHwBinder->BnHwComposerCallback::onTransact->BnHwComposerCallback::_hidl_onVsync->ComposerCallbackBridge::onVsync->SurfaceFlinger::onVsyncReceived
* frameworks/native/services/surfaceflinger/SurfaceFlinger.h
class SurfaceFlinger : public BnSurfaceComposer,
public PriorityDumper,
private IBinder::DeathRecipient,
private HWC2::ComposerCallback
{
...
}
* frameworks/native/services/surfaceflinger/DisplayHardware/HWC2.h
class ComposerCallback {
public:
virtual void onHotplugReceived(int32_t sequenceId, hwc2_display_t display, Connection connection) = 0;
virtual void onRefreshReceived(int32_t sequenceId, hwc2_display_t display) = 0;
virtual void onVsyncReceived(int32_t sequenceId, hwc2_display_t display, int64_t timestamp) = 0;
virtual ~ComposerCallback() = default;
};
- SurfaceFlinger.createConnection中new一个Client(即SurfaceComposerClient服务端),Client继承BnSurfaceComposerClient,作为ISurfaceComposerClient的服务端
* frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
sp<ISurfaceComposerClient> SurfaceFlinger::createConnection() {
return initClient(new Client(this));//进而调用client->initCheck();
}
- SurfaceComposerClient::createSurfaceChecked调用mClient->createSurface,进入到服务端Client::createSurface,然后调用到SurfaceFlinger::createLayer根据不同flag调用SurfaceFlingerFactory创建Layer,Layer用于标示一个图层。
SurfaceFlinger为应用程序创建好Layer后,需要统一管理这些Layer对象,因此通过函数addClientLayer将创建的Layer保存到当前State的Z秩序列表layersSortedByZ中,同时将这个Layer所对应的IGraphicBufferProducer本地Binder对象gbp保存到SurfaceFlinger的成员变量mGraphicBufferProducerList中。
除了SurfaceFlinger需要统一管理系统中创建的所有Layer对象外,专门为每个应用程序进程服务的Client也需要统一管理当前应用程序进程所创建的Layer,因此在addClientLayer函数里还会通过Client::attachLayer将创建的Layer和该类对应的handle以键值对的方式保存到Client的成员变量mLayers表中
* frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
status_t SurfaceFlinger::createLayer(const String8& name, const sp<Client>& client, uint32_t w, uint32_t h, PixelFormat format, uint32_t flags, LayerMetadata metadata, sp<IBinder>* handle,
sp<IGraphicBufferProducer>* gbp, const sp<IBinder>& parentHandle, const sp<Layer>& parentLayer) {
...
sp<Layer> layer;
...
//根据flags参数来创建不同类型的显示层
switch (flags & ISurfaceComposerClient::eFXSurfaceMask) {
case ISurfaceComposerClient::eFXSurfaceBufferQueue:
result = createBufferQueueLayer(client, uniqueName, w, h, flags, std::move(metadata), format, handle, gbp, &layer);
break;
case ISurfaceComposerClient::eFXSurfaceBufferState:
result = createBufferStateLayer(client, uniqueName, w, h, flags, std::move(metadata), handle, &layer);
break;
case ISurfaceComposerClient::eFXSurfaceColor:
...
result = createColorLayer(client, uniqueName, w, h, flags, std::move(metadata), handle, &layer);
break;
case ISurfaceComposerClient::eFXSurfaceContainer:
...
result = createContainerLayer(client, uniqueName, w, h, flags, std::move(metadata),handle, &layer);
break;
default:
result = BAD_VALUE;
break;
}
...
//调用addClientLayer将创建的Layer添加到相关的数据结构中
result = addClientLayer(client, *handle, *gbp, layer, parentHandle, parentLayer,
addToCurrentState);
...
mInterceptor->saveSurfaceCreation(layer);
...
}
status_t SurfaceFlinger::createBufferQueueLayer(const sp<Client>& client, const String8& name, uint32_t w, uint32_t h, uint32_t flags,
LayerMetadata metadata, PixelFormat& format, sp<IBinder>* handle, sp<IGraphicBufferProducer>* gbp, sp<Layer>* outLayer) {
...
sp<BufferQueueLayer> layer = getFactory().createBufferQueueLayer(LayerCreationArgs(this, client, name, w, h, flags, std::move(metadata)));
status_t err = layer->setDefaultBufferProperties(w, h, format);
if (err == NO_ERROR) {
*handle = layer->getHandle();
*gbp = layer->getProducer();
*outLayer = layer;
}
return err;
}
status_t SurfaceFlinger::addClientLayer(const sp<Client>& client, const sp<IBinder>& handle,
const sp<IGraphicBufferProducer>& gbc, const sp<Layer>& lbc,
const sp<IBinder>& parentHandle,
const sp<Layer>& parentLayer, bool addToCurrentState) {
// add this layer to the current state list
{
Mutex::Autolock _l(mStateLock);
sp<Layer> parent;
if (parentHandle != nullptr) {
parent = fromHandle(parentHandle);
if (parent == nullptr) {
return NAME_NOT_FOUND;
}
} else {
parent = parentLayer;
}
if (mNumLayers >= MAX_LAYERS) {//size_t MAX_LAYERS = 4096;
return NO_MEMORY;
}
mLayersByLocalBinderToken.emplace(handle->localBinder(), lbc);
if (parent == nullptr && addToCurrentState) {
mCurrentState.layersSortedByZ.add(lbc);
}
...
if (gbc != nullptr) {
mGraphicBufferProducerList.insert(IInterface::asBinder(gbc).get());
...
}
mLayersAdded = true;
}
client->attachLayer(handle, lbc);
return NO_ERROR;
}
* frameworks/native/services/surfaceflinger/Client.cpp
void Client::attachLayer(const sp<IBinder>& handle, const sp<Layer>& layer)
{
Mutex::Autolock _l(mLock);
mLayers.add(handle, layer);
}
- 下面看BufferQueueLayer 、BufferStateLayer继承自BufferLayer,ContainerLayer 、ColorLayer 继承自Layer,BufferLayer继承Layer
下面看BufferQueueLayer,在onFirstRef函数中调用BufferQueue::createBufferQueue创建BufferQueue,并在在Layer的构造中,进行mCurrentState的初始化并调用SurfaceFlinger::onLayerCreated使mNumLayers加1,关于BufferQueue的详细介绍请参考下文BufferQueue部分
BufferQueueLayer继承BufferLayerConsumer::ContentsChangedListener,实现FrameAvailableListener::onFrameAvailable、FrameAvailableListener::onFrameReplaced、ContentsChangedListener::onSidebandStreamChanged
- IGraphicBufferProducer
IGraphicBufferProducer就是“填充”buffer空间的人,通常情况下是应用程序。因为应用程序不断地刷新UI,从而将产生的显示数据源源不断地写到buffer中。当IGraphicBufferProducer需要使用一块buffer时,它首先会向中介BufferQueue发起dequeueBuffer申请,然后才能对指定的buffer进行操作。此时buffer就只属于IGraphicBufferProducer一个人的了,它可以对buffer进行任何必要的操作,而IGraphicBufferConsumer此刻绝不能操作这块buffer。当IGraphicBufferProducer认为一块buffer已经写入完成后,它进一步调用queueBuffer函数。从字面上看这个函数是“入列”的意思,形象地表达了buffer此时的操作,把buffer归还到BufferQueue的队列中。一旦queue成功后,buffer的owner也就随之改变为BufferQueue了- IGraphicBufferConsumer
IGraphicBufferConsumer是与IGraphicBufferProducer相对应的,它的操作同样受到BufferQueue的管控。当一块buffer已经就绪后,IGraphicBufferConsumer就可以开始工作了

* frameworks/native/libs/gui/include/gui/ConsumerBase.h
struct FrameAvailableListener : public virtual RefBase {
// See IConsumerListener::onFrame{Available,Replaced}
virtual void onFrameAvailable(const BufferItem& item) = 0;
virtual void onFrameReplaced(const BufferItem& /* item */) {}
};
* frameworks/native/services/surfaceflinger/Layer.cpp
Layer::Layer(const LayerCreationArgs& args) : mFlinger(args.flinger), mName(args.name),
mClientRef(args.client), mWindowType(args.metadata.getInt32(METADATA_WINDOW_TYPE, 0)) {
...//mCurrentState初始化
mCurrentState.metadata = args.metadata;
// drawing state & current state are identical
mDrawingState = mCurrentState;
...
mSchedulerLayerHandle = mFlinger->mScheduler->registerLayer(mName.c_str(), mWindowType);
mFlinger->onLayerCreated();
}
* frameworks/native/services/surfaceflinger/BufferQueueLayer.cpp
void BufferQueueLayer::onFirstRef() {
BufferLayer::onFirstRef();
// Creates a custom BufferQueue for SurfaceFlingerConsumer to use
sp<IGraphicBufferProducer> producer;
sp<IGraphicBufferConsumer> consumer;
BufferQueue::createBufferQueue(&producer, &consumer, true);
mProducer = new MonitoredProducer(producer, mFlinger, this);
{
// Grab the SF state lock during this since it's the only safe way to access RenderEngine
Mutex::Autolock lock(mFlinger->mStateLock);
mConsumer = new BufferLayerConsumer(consumer, mFlinger->getRenderEngine(), mTextureName, this);
}
...
}
* frameworks/native/libs/gui/BufferQueue.cpp
void BufferQueue::createBufferQueue(sp<IGraphicBufferProducer>* outProducer, sp<IGraphicBufferConsumer>* outConsumer, bool consumerIsSurfaceFlinger) {
...
sp<BufferQueueCore> core(new BufferQueueCore());
LOG_ALWAYS_FATAL_IF(core == nullptr, "BufferQueue: failed to create BufferQueueCore");
sp<IGraphicBufferProducer> producer(new BufferQueueProducer(core, consumerIsSurfaceFlinger));
LOG_ALWAYS_FATAL_IF(producer == nullptr, "BufferQueue: failed to create BufferQueueProducer");
sp<IGraphicBufferConsumer> consumer(new BufferQueueConsumer(core));
LOG_ALWAYS_FATAL_IF(consumer == nullptr,"BufferQueue: failed to create BufferQueueConsumer");
*outProducer = producer;
*outConsumer = consumer;
}
BufferQueue
可以认为BufferQueue是一个服务中心,IGraphicBufferProducer和IGraphicBufferConsumer
所需要使用的buffer必须要通过它来管理。比如说当IGraphicBufferProducer想要获取一个buffer时,它不能越过BufferQueue直接与IGraphicBufferConsumer进行联系,反之亦然。
创建流程
通过BufferQueue的createBufferQueue,首先创建了一个BufferQueueCore,这个是BufferQueue的核心,然后创建了一个BufferQueueProducer和一个BufferQueueConsumer,注意Producer和Consumer都持有BufferQueueCore的引用。
BufferQueue创建完后,BufferQueueLayer又对BufferQueueCore中的Producer和Consume进行封装。分别创建了MonitoredProducer和BufferLayerConsumer
- BufferLayerConsumer的mConsumer,为消费流程
- setConsumerUsageBits,设置Consumer的usage
- setContentsChangedListener,这种内容改变的监听,注意这里传的是this指针,因为BufferQueueLayer实现了两个接口
- setName,设置Consumer 名
- BufferLayerConsumer继承ConsumerBase,在ConsumerBase的构造函数中,给BufferQueue设置了监听,这样Consumer和BufferQueue,就算是连上了,这里BufferQueueLayer实现了BufferLayerConsumer的ContentsChangedListener,在BufferQueueLayer的onFirstRef中,这个Listener被设置给了BufferLayerConsumer,然后BufferLayerConsumer调用父类setFrameAvailableListener
- ConsumerBase自身实现ConsumerListener中构造的Listener,通过代理ProxyConsumerListener,在connect时传给了BufferQueueConsumer
BufferQueueLayer实现的ContentsChangedListener被保存在ConsumerBase中mFrameAvailableListener。而ConsumerBase实现的ConsumerListener,被传到BufferQueueConsumer,保存在BufferQueueCore的mConsumerListener中
Listener的通知路线
- Producer生产完后,会通过BufferQueueCore中的mConsumerListener通知ConsumerBase
- ConsumerBase,接受到BufferQueueConsumer的通知,再通过BufferQueueLayer传下来的信使mFrameAvailableListener,通知BufferQueueLayer。
- BufferQueueLayer接受到通知后,就可以去消费生产完的Buffer了
* frameworks/native/libs/gui/ConsumerBase.cpp
ConsumerBase::ConsumerBase(const sp<IGraphicBufferConsumer>& bufferQueue, bool controlledByApp) : mAbandoned(false),mConsumer(bufferQueue),mPrevFinalReleaseFence(Fence::NO_FENCE) {
...
wp<ConsumerListener> listener = static_cast<ConsumerListener*>(this);
sp<IConsumerListener> proxy = new BufferQueue::ProxyConsumerListener(listener);
status_t err = mConsumer->consumerConnect(proxy, controlledByApp);
if (err != NO_ERROR) {
CB_LOGE("ConsumerBase: error connecting to BufferQueue: %s (%d)",
strerror(-err), err);
} else {
mConsumer->setConsumerName(mName);
}
}
* frameworks/native/libs/gui/BufferQueueConsumer.cpp
status_t BufferQueueConsumer::connect(
const sp<IConsumerListener>& consumerListener, bool controlledByApp) {
...
mCore->mConsumerListener = consumerListener;
mCore->mConsumerControlledByApp = controlledByApp;
return NO_ERROR;
}
- MonitoredProducer.mProducer
- 主要调用setMaxDequeuedBufferCount
根据系统的属性,设置Producer最多可以申请多少个Buffer,默认是3个;如果配置了属性ro.sf.disable_triple_buffer为true,那就只能用2个
MonitoredProducer继承BnGraphicBufferProducer,是对BufferQueueProducer的封装,其目的,就是Producer销毁时,能通知SurfaceFlinger。这就是取名Monitored的愿意。余下的,MonitoredProducer构造时候传入producer为BufferQueueProducer,所以很多接口都是直接调对应的BufferQueueProducer的实现
在MonitoredProducer析构函数中,post一个消息到SurfaceFlinger的主线程中。通知SurFaceFlinger Producer已经销毁,SurfaceFlinger 会将销毁的Producer从mGraphicBufferProducerList中删掉
* frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
SurfaceFlinger::SurfaceFlinger(Factory& factory) : SurfaceFlinger(factory, SkipInitialization) {
property_get("ro.sf.disable_triple_buffer", value, "0");
mLayerTripleBufferingDisabled = atoi(value);
ALOGI_IF(mLayerTripleBufferingDisabled, "Disabling Triple Buffering");
}

- 一个Layer对应一个BufferQueue,一个BufferQueue中有多个Buffer,一般是2个或者3个。
- 一个Layer有一个Producer,一个Consumer
- 结合前面的分析,一个Surface和一个Layer也是一一对应的,和窗口也是一一对应的
可见,BufferQueue就是两个连接纽带,连接着Producer和Consumer
BnGraphicBufferConsumer
继承BnGraphicBufferConsumer
BufferQueueProducer
继承BnGraphicBufferProducer
- dequeueBuffer流程
在SurfaceFlinger学习笔记(二)之Surface和HWUI的Surface Draw流程中lockCanvas时进而调用到Surface::lock,进而调用到Surface::dequeueBuffer
Producer通常是指应用程序,应用程序不断刷新UI,把产生的显示数据写到buffer中,当Producer需要一块buffer时,先向BufferQueue发起dequeue申请,然后才能对指定的缓冲区进行填充操作。当填充完成后,通过调用queueBuffer把这个buffer入队到Bufferqueue中,由BufferQueueCore通知consumer有可以消费的buffer了
先看BufferQueueCore重要成员含义
* frameworks/native/libs/gui/include/gui/BufferQueueCore.h
class BufferQueueCore : public virtual RefBase {
...
BufferQueueDefs::SlotsType mSlots;
// mQueue is a FIFO of queued buffers used in synchronous mode.
Fifo mQueue;
// mFreeSlots contains all of the slots which are FREE and do not currently
// have a buffer attached.
std::set<int> mFreeSlots;
// mFreeBuffers contains all of the slots which are FREE and currently have
// a buffer attached.
std::list<int> mFreeBuffers;
// mUnusedSlots contains all slots that are currently unused. They should be
// free and not have a buffer attached.
std::list<int> mUnusedSlots;
// mActiveBuffers contains all slots which have a non-FREE buffer attached.
std::set<int> mActiveBuffers;
...
}
- mSlots 是Buffer序号的一个数组,Producer端的mSlots也是这个mSlots,Consumer端是mSlots也是里的mSlots的引用。它可实现Buffer在Producer和Consumer之间转移,而不需要真正的在Binder间去传输一个GraphicBuffer。初始状态时为空,当requestBuffer流程执行时,将去为对应的Buffer序号,分配真正的Buffer。可以理解为mSlots是BufferQueue中实际流转起来的Buffer
mSlots = mFreeBuffers + mActiveBuffers
NUM_BUFFER_SLOTS = mUnusedSlots + mFreeSlots + mFreeBuffers + mActiveBuffers- mQueue
mQueue是一个先进先出的Vector,是同步模式下使用。里面就是处于QUEUED状态的Buffer- mFreeSlots
mFreeSlots包含所有是FREE状态,且还没有分配Buffer的,Buffer序号集合。刚开始时,mFreeSlots被初始化为MaxBufferCount个Buffer序号集合,dequeueBuffer的时候,将先从这个集合中获取。但是消费者消费完成,释放的Buffer并不返回到这个队列中,而是返回到mFreeBuffers中- mFreeBuffers
mFreeBuffers包含的是所有FREE状态,且已经分配Buffer的,Buffer序号的结合。消费者消费完成,释放的Buffer并不返回到这个队列中,而是返回到mFreeBuffers中- mUnusedSlots
mUnusedSlots和mFreeSlots有些相似,只是mFreeSlots会被用到,而mUnusedSlots中的Buffer序号不会用到。也就是,总的Buffer序号NUM_BUFFER_SLOTS中,除去MaxBufferCount个mFreeSlots,剩余的集合- mActiveBuffers
mActiveBuffers包含所有非FREE状态的Buffer。也就是包含了DEQUEUED,QUEUED,ACQUIRED以及SHARED这几个状态的。
status_t Surface::lock( ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds)
{
...
if (!mConnectedToCpu) {
int err = Surface::connect(NATIVE_WINDOW_API_CPU);
...
// we're intending to do software rendering from this point
setUsage(GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN);
}
ANativeWindowBuffer* out;
int fenceFd = -1;
//下面的dequeueBuffer将取出一个空闲缓冲
status_t err = dequeueBuffer(&out, &fenceFd);
if (err == NO_ERROR) {
sp<GraphicBuffer> backBuffer(GraphicBuffer::getSelf(out));
....
//mPostedBuffer是上一次绘画时使用的Buffer,也就是现在的frontBuffer
const sp<GraphicBuffer>& frontBuffer(mPostedBuffer);
...
if (canCopyBack) {
// copy the area that is invalid and not repainted this round
const Region copyback(mDirtyRegion.subtract(newDirtyRegion));
if (!copyback.isEmpty()) {
//把frontBuffer中的数据拷贝到BackBuffer中
copyBlt(backBuffer, frontBuffer, copyback, &fenceFd);
}
} else {
...
}
...
//调用GraphicBuffer的lock得到一块内存,内存地址被赋值给了vaddr,
//后续的作画将在这块内存上展开
status_t res = backBuffer->lockAsync(
GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN,
newDirtyRegion.bounds(), &vaddr, fenceFd);
...
}
return err;
}
准备阶段:
在准备阶段,主要是处理,前面的设置的参数需求,对Buffer大小的需求,格式和usage的需求。这过程是被锁mMutex锁住的。这里的mSharedBufferMode是一种特殊的模式,是上层应用请求的,专门给特殊的应用使用的,主要是VR应用。因为VR应用要求低延时,BufferQueue采用的交换用的Buffer多了,延迟增加。为了降低延迟,设计了这个共享buffer的模式,Producer和Consumer共用一个Buffer。应用绘制完成后,直接给到Consumer进行显示。
这里的mSlots为BufferSlot 的结构体定义在Surface.h中
struct BufferSlot {
sp<GraphicBuffer> buffer;
Region dirtyRegion;
};
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
...
{
Mutex::Autolock lock(mMutex);
...
if (mSharedBufferMode && mAutoRefresh && mSharedBufferSlot !=
BufferItem::INVALID_BUFFER_SLOT) {
...
}
} // Drop the lock so that we can still touch the Surface while blocking in IGBP::dequeueBuffer
...
}
实际dequeue阶段
dequeue是通过mGraphicBufferProducer来完成的。dequeueBuffer参数就是我们需要的大小的需求,格式和usage参数。dequeue回来的就是buf,并不是具体的Buffer,而是Buffer的序号。
* frameworks/native/libs/gui/Surface.cpp
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
...
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps : nullptr);
...
}
实际dequeue阶段–BufferQueueProducer
found是Buffer的序号,这里采用while循环的去等待可用的Buffer,如果有Free的Buffer,将Buffer从mSlots中获取出来GraphicBuffer。如果获取到的Buffer和我们需要的Buffer宽高,属性等不满足。而Producer又不允许分配buffer,我们就将它释放掉,重新获取一个。直到找到我们需要的Buffer
实际dequeue阶段–BufferQueueProducer::waitForFreeSlotThenRelock
BufferQueueProducer::waitForFreeSlotThenRelock中mSlots是总的;这里的mActiveBuffers是活跃的,不包含free的状态的。这里先找出来有多少个buffer是已经处于dequeued状态的dequeuedCount;多少个是处于acquired状态的。dequeued状态就是被应用拿去绘制去了,acquired状态就是buffer被消费者拿去合成显示去了
BufferQueueCore::mQueue是一个FIFO的队列应用绘制完成后,queue到BufferQueue中,其实就是queue到这个队列里面。tooManyBuffers表示应用已经绘制完成了,但是一直没有被消费,处于queued状态的buffer超过了maxBufferCount数,这个时候不能再分配,如果分配就会造成内存紧张。
我们这里的caller是Dequeue,getFreeBufferLocked和getFreeSlotLocked又引出BufferQueueCore的两个队列。mFreeBuffers和mFreeSlots。我们说过,这里的队列是Buffer的序号,mFreeBuffers表示Buffer是Free的,这个序号对应的Buffer已经被分配出来了,只是现在没有被使用。而mFreeSlots表示,序号是Free的,这些序号还没有被用过,说明对应的是没有Buffer,Buffer还没有分配。如果找不到,found还是为INVALID_BUFFER_SLOT。没有关系,如果是tooManyBuffers太多,或是INVALID_BUFFER_SLOT,将再试一次tryAgain
eglDisplay用以创建EGLSyncKHR。eglFence同步Buffer,上一个使用者使用完成后,将signal出来。outFence的值就是eglFence,共享buffer没有fence。如果是共享的buffer,将found保存下来,以后就一直用这个 buffer了
status_t BufferQueueProducer::dequeueBuffer(int* outSlot, sp<android::Fence>* outFence,
uint32_t width, uint32_t height, PixelFormat format,
uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
int found = BufferItem::INVALID_BUFFER_SLOT;
while (found == BufferItem::INVALID_BUFFER_SLOT) {
status_t status = waitForFreeSlotThenRelock(FreeSlotCaller::Dequeue, lock, &found);
...
const sp<GraphicBuffer>& buffer(mSlots[found].mGraphicBuffer);
// If we are not allowed to allocate new buffers,
// waitForFreeSlotThenRelock must have returned a slot containing a
// buffer. If this buffer would require reallocation to meet the
// requested attributes, we free it and attempt to get another one.
if (!mCore->mAllowAllocation) {
if (buffer->needsReallocation(width, height, format, BQ_LAYER_COUNT, usage)) {
...
continue;
}
}
}
}
status_t BufferQueueProducer::waitForFreeSlotThenRelock(FreeSlotCaller caller,
int* found) const {
...
// ①step1
int dequeuedCount = 0;
int acquiredCount = 0;
for (int s : mCore->mActiveBuffers) {
if (mSlots[s].mBufferState.isDequeued()) {
++dequeuedCount;
}
if (mSlots[s].mBufferState.isAcquired()) {
++acquiredCount;
}
}
...
//②step2
*found = BufferQueueCore::INVALID_BUFFER_SLOT;
// If we disconnect and reconnect quickly, we can be in a state where
// our slots are empty but we have many buffers in the queue. This can
// cause us to run out of memory if we outrun the consumer. Wait here if
// it looks like we have too many buffers queued up.
const int maxBufferCount = mCore->getMaxBufferCountLocked();
bool tooManyBuffers = mCore->mQueue.size()> static_cast<size_t>(maxBufferCount);
if (tooManyBuffers) {
BQ_LOGV("%s: queue size is %zu, waiting", callerString,
mCore->mQueue.size());
} else {
// If in shared buffer mode and a shared buffer exists, always
// return it.
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot !=
BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = mCore->mSharedBufferSlot;
} else {
if (caller == FreeSlotCaller::Dequeue) {
// If we're calling this from dequeue, prefer free buffers
int slot = getFreeBufferLocked();
if (slot != BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = slot;
} else if (mCore->mAllowAllocation) {
*found = getFreeSlotLocked();
}
} else {
// If we're calling this from attach, prefer free slots
int slot = getFreeSlotLocked();
if (slot != BufferQueueCore::INVALID_BUFFER_SLOT) {
*found = slot;
} else {
*found = getFreeBufferLocked();
}
}
}
}
...
//③step
eglDisplay = mSlots[found].mEglDisplay;
eglFence = mSlots[found].mEglFence;
// Don't return a fence in shared buffer mode, except for the first
// frame.
*outFence = (mCore->mSharedBufferMode &&
mCore->mSharedBufferSlot == found) ?
Fence::NO_FENCE : mSlots[found].mFence;
mSlots[found].mEglFence = EGL_NO_SYNC_KHR;
mSlots[found].mFence = Fence::NO_FENCE;
// If shared buffer mode has just been enabled, cache the slot of the
// first buffer that is dequeued and mark it as the shared buffer.
if (mCore->mSharedBufferMode && mCore->mSharedBufferSlot ==
BufferQueueCore::INVALID_BUFFER_SLOT) {
mCore->mSharedBufferSlot = found;
mSlots[found].mBufferState.mShared = true;
}
}
dequeue后的处理阶段
- 拿到Buffer后,首先是timestamp的处理,记录一下dequeue的时间。
- 从Surface的mSlots中根据buffer序号,取出GraphicsBuffer gbuf。如果gbuf没有,或者需要重新分配,再次通过BufferQueuerProducer的requestBuffer来完成。
- 最后是fenceFd的获取,根据Buffer的Fence,dup获得。
前面BufferQueuerProducer去dequeueBuffer时,只拿回了buffer的序号,并没有GraphicBuffer过来。GraphicBuffer是通过这里的requestBuffer去获取到的。获取到后就直接保存在Surface的mSlots中,后续就不用再去request了。需要主要的是,这里并不是拷贝GraphicBuffer的内容,BufferQueue 是不会复制Buffer内容的;采用的是共享Buffer,Buffer基本都是通过句柄handle进行传递
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
... ...
if ((result & IGraphicBufferProducer::BUFFER_NEEDS_REALLOCATION) || gbuf == nullptr) {
if (mReportRemovedBuffers && (gbuf != nullptr)) {
mRemovedBuffers.push_back(gbuf);
}
result = mGraphicBufferProducer->requestBuffer(buf, &gbuf);
if (result != NO_ERROR) {
ALOGE("dequeueBuffer: IGraphicBufferProducer::requestBuffer failed: %d", result);
mGraphicBufferProducer->cancelBuffer(buf, fence);
return result;
}
}
...
}
status_t BufferQueueProducer::requestBuffer(int slot, sp<GraphicBuffer>* buf) {
ATRACE_CALL();
BQ_LOGV("requestBuffer: slot %d", slot);
Mutex::Autolock lock(mCore->mMutex);
... ...
mSlots[slot].mRequestBufferCalled = true;
*buf = mSlots[slot].mGraphicBuffer;
return NO_ERROR;
}
requestBuffer需要传一个GraphicBuffer,Bp端通过REQUEST_BUFFER transact到Bn端,Bp端new一个GraphicBuffer,再将Bn端的GraphicBuffer 读过来,构成Bp端的Bufer。到达到这个目的,GraphicBuffer需要继承Flattenable,能够将GraphicBuffer序列化和反序列化,以实现Binder的传输

class BpGraphicBufferProducer : public BpInterface<IGraphicBufferProducer>
{
public:
...
virtual status_t requestBuffer(int bufferIdx, sp<GraphicBuffer>* buf) {
Parcel data, reply;
data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
data.writeInt32(bufferIdx);
status_t result =remote()->transact(REQUEST_BUFFER, data, &reply);
if (result != NO_ERROR) {
return result;
}
bool nonNull = reply.readInt32();
if (nonNull) {
*buf = new GraphicBuffer();
result = reply.read(**buf);
if(result != NO_ERROR) {
(*buf).clear();
return result;
}
}
result = reply.readInt32();
return result;
}
- unlockCanvasAndPost时调用Surface::unlockAndPost
status_t Surface::unlockAndPost()
{
...
int fd = -1;
status_t err = mLockedBuffer->unlockAsync(&fd);
err = queueBuffer(mLockedBuffer.get(), fd);
....
mPostedBuffer = mLockedBuffer;
mLockedBuffer = nullptr;
return err;
}
- flippedRegion,Opengl里面采用是坐标系是左下为远点,而Graphic&Display子系统中采用左上为远点,所以这里需要做一下倒转。另外,受transform的影响,这里也需要统一一下。
- SurfaceDamage,受损区域,表示Surface也就是Buffer的那些个区域被更新了。支持部分更新
int Surface::queueBuffer(android_native_buffer_t* buffer, int fenceFd) {
...
//getSlotFromBufferLocked,dequeue时,根据buffer序号取Buffer;
//queue时,是根据Buffer去找序号,根据Buffer的handle去找的
int i = getSlotFromBufferLocked(buffer);
//mCrop,用以剪切Buffer的,mCrop不能超过buffer的大小
//也就是说,我们的buffer可以只显示一部分
Rect crop(Rect::EMPTY_RECT);
mCrop.intersect(Rect(buffer->width, buffer->height), &crop);
...
//QueueBufferInput其实就是对Buffer的描述的封装,通过QueueBufferInput能在Binder中进行传输
IGraphicBufferProducer::QueueBufferInput input(timestamp, isAutoTimestamp,
static_cast<android_dataspace>(mDataSpace), crop, mScalingMode,
mTransform ^ mStickyTransform, fence, mStickyTransform,
mEnableFrameTimestamps);
...
for (auto rect : mDirtyRegion) {
...
//flippedRegion,Opengl里面采用是坐标系是左下为远点,
//而Graphic&Display子系统中采用左上为远点,所以这里需要做一下倒转。
//另外,受transform的影响,这里也需要统一一下
switch (mTransform ^ mStickyTransform) {
case NATIVE_WINDOW_TRANSFORM_ROT_90: {
// Rotate 270 degrees
Rect flippedRect{top, width - right, bottom, width - left};
flippedRegion.orSelf(flippedRect);
break;
}
...
//SurfaceDamage,受损区域,表示Surface也就是Buffer的那些个区域被更新了。支持部分更新
input.setSurfaceDamage(flippedRegion);
}
...
//进入到BufferQueueProducer的queueBuffer
status_t err = mGraphicBufferProducer->queueBuffer(i, input, &output);
}
BufferQueueProducer::queueBuffer
- requestedPresentTimestamp分两中情况,一种是自动的,另外一种是应用控制的。如果是自动的,那就是queueBuffer时是时间timestamp = systemTime(SYSTEM_TIME_MONOTONIC
- scalingmode: Video播放,或者camera预览的时候用的比较多。当显示的内容和屏幕的大小不成比例时,采用什么处理方式。SCALE_TO_WINDOW就是根据window的大小,缩放buffer,buffer的内容能被显示全;SCALE_CROP,根据窗口大小,截取buffer,部分buffer的内容就不能显示出来
- lastQueuedFence->waitForever,这里可能会比较耗时。Android在8.0及以后的版本,对fence的管理加强了,如果HAL实现的不好,这里会等很长时间。这个lastQueuedFence是上一针的acquireFence,acquirefence是绘制,一般是GPU那边signal的,表示绘制已经完成。如果上一帧的fence一直没有signal,说明上一帧一直没有绘制完成,等在这里也是有道理的。当然有些芯片商的实现不太好,可能没有完全理解Android的设计,实现的时候难免会造成不必要的block
* frameworks/native/libs/gui/BufferQueueProducer.cpp
status_t BufferQueueProducer::queueBuffer(int slot,
const QueueBufferInput &input, QueueBufferOutput *output) {
...
//requestedPresentTimestamp分两中情况,一种是自动的,另外一种是应用控制的。
//如果是自动的,那就是queueBuffer时是时间timestamp = systemTime(SYSTEM_TIME_MONOTONIC
int64_t requestedPresentTimestamp;
int scalingMode;
//用BufferItem来描述buffer
//GraphicBuffer以及描述,都封装在BuferItem中
BufferItem item;
...
//根据序号将GraphicBuffer取出来,不要怀疑,应用使用的graphicBuffer也是从mSlots中获取过去的
const sp<GraphicBuffer>& graphicBuffer(mSlots[slot].mGraphicBuffer);
...
//Occupancy,用来告诉内存统计,这里占用的内存大小
mCore->mOccupancyTracker.registerOccupancyChange(mCore->mQueue.size());
...
//frameAvailableListener,通知消费者,Buffer可以消费了
if (frameAvailableListener != nullptr) {
frameAvailableListener->onFrameAvailable(item);
} else if (frameReplacedListener != nullptr) {
frameReplacedListener->onFrameReplaced(item);
}
...
//lastQueuedFence,上一帧queue的Buffer的Fence
lastQueuedFence = std::move(mLastQueueBufferFence);
//
if (connectedApi == NATIVE_WINDOW_API_EGL) {
// Waiting here allows for two full buffers to be queued but not a
// third. In the event that frames take varying time, this makes a
// small trade-off in favor of latency rather than throughput.
lastQueuedFence->waitForever("Throttling EGL Production");
}
}
简单做个总结:
1)应用程序通过BufferQueue执行绘图,surfaceflinger会把系统中所有应用程序最终的绘图结果进行混合,然后送到物理屏幕显示。应用程序跟surfaceflinger之间的通信桥梁是IsurfaceComposrClient。
这个类被封装在SurfaceComposerClient中。
2)应用程序通过SurfaceComposerClient调用CreateSurface的过程中,除了得到IGraphicBufferProducer实例外,还创建了一个layer。把控制这个layer的handle,IGraphicBufferProducer对象,连同SurfaceComposerClient自身都保存在应用端的Surfacecontrol中。
3)Surface,应用程序通过Surfacecontrol的getSurface获取,其内部持有IGraphicBufferProducer对象,即BufferQueueProducer的实现接口。如果egl想通过Surface这个本地窗口完成某个功能,Surface实际上是利用IGraphicBufferProducer取得远程端的服务,完成egl的请求。
4)应用程序跟layer应该是一对多的关系,因为createSurface是可以被调用多次的,并且,一个应用程序申请的多个layer可以通过addClientLayer添加到一个全局变量mLayers中。应用程序申请的layer,一方面要记录都各个Client的内部变量mLayers中,另一方面还要告知SurfaceFlinger,这个操作也是在addClientLayer函数中完成的,即把layer添加到全局变量mCurrentState.layerSortByZ,Surfaceflinger会对这个列表中的所有layer排序,排序的结果直接影响了屏幕显示的画面。
5)每个layer对应一个BufferQueue,所以一个应用程序可能对应多个BufferQueue。layer并没有直接持有BufferQueue对象,而是通过其内部的IGraphicBufferProducer,mSurfaceFlingerConsumer来管理。
- Buffer状态
Buffer分别对应不同的五个状态
- DEQUEUED 状态
Producer dequeue一个Buffer后,这个Buffer就变为DEQUEUED状态,release Fence发信号后,Producer就可以修改Buffer的内容,我们称为release Fence。此时Buffer被Producer占用。DEQUEUED状态的Buffer可以迁移到 QUEUED 状态,通过queueBuffer或attachBuffer流程。也可以迁移到FREE装,通过cancelBuffer或detachBuffer流程。- QUEUED 状态
Buffer绘制完后,queue到BufferQueue中,给Consumer进行消费。此时Buffer可能还没有真正绘制完成,必现要等对应的Fence发信号出来后,才真正完成。此时Buffer是BufferQueue持有,可以迁移到ACQUIRED状态,通过acquireBuffer流程。而已可以迁移到FREE状态,如果另外一个Buffer被异步的queue进来。- ACQUIRED 状态
Buffer已经被Consumer获取,但是也必须要等对应的Fence发信号才能被Consumer读写,这个Fence是从Producer那边,queueBuffer的时候传过来的。我们将其称为acquire fence。此时,Buffer被Consumer持有。状态可以迁移到FREE状态,通过releaseBuffer或detachBuffer流程。除了从acquireBuffer流程可以迁移到ACQUIRED状态,attachBuffer流程也可以迁移到ACQUIRED状态。- FREE 状态
FREE状态,说明Buffer被BufferQueue持有,可以被Producer dequeue,它将迁移到DEQUEUED状态,通过dequeueBuffer流程。- SHARED状态
SHARED状态是一个特殊的状态,SHARED的Buffer并不参与前面所说的状态迁移。它说明Buffer被用与共享Buffer模式。除了FREE状态,它可以是其他的任何状态。它可以被多次dequeued, queued, 或者 acquired。这中共享Buffer的模式,主要用于VR等低延迟要求的场合。
Buffer的状态,都是通过各个状态的Buffer的量来表示状态
| Buffer状态 | mShared | mDequeueCount | mQueueCount | mAcquireCount |
|---|---|---|---|---|
| FREE | false | 0 | 0 | 0 |
| DEQUEUED | false | 1 | 0 | 0 |
| QUEUED | false | 0 | 1 | 0 |
| ACQUIRED | false | 0 | 0 | 1 |
| SHARED | true | any | any | any |
Buffer的状态在代码中用BufferState描述,BufferState的定义如下
* frameworks/native/libs/gui/include/gui/BufferSlot.h
struct BufferState {
// All slots are initially FREE (not dequeued, queued, acquired, or shared).
BufferState()
: mDequeueCount(0),
mQueueCount(0),
mAcquireCount(0),
mShared(false) {
}
uint32_t mDequeueCount;
uint32_t mQueueCount;
uint32_t mAcquireCount;
bool mShared;
...
}
struct BufferSlot {
BufferSlot()
: mGraphicBuffer(nullptr),
mEglDisplay(EGL_NO_DISPLAY),
mBufferState(),
mRequestBufferCalled(false),
mFrameNumber(0),
mEglFence(EGL_NO_SYNC_KHR),
mFence(Fence::NO_FENCE),
mAcquireCalled(false),
mNeedsReallocation(false) {
}
// Buffer序号对应的Buffer.
sp<GraphicBuffer> mGraphicBuffer;
// 创建EGLSyncKHR对象用
EGLDisplay mEglDisplay;
// Buffer序号当前的状态
BufferState mBufferState;
// mRequestBufferCalled 表示Producer确实已经调用requestBuffer
bool mRequestBufferCalled;
// mFrameNumber 表示该Buffer序号已经被queue的次数.
//主要用于dequeueBuffer时,遵从LRU,这很有用,
//因为buffer 变FREE时,可能release Fence还没有发信号出来。
uint64_t mFrameNumber;
EGLSyncKHR mEglFence;
//mFence 是同步的一种方式,
//上一个owner使用完Buffer后,需要发信号出来,下一个owner才可以使用
sp<Fence> mFence;
// 表示Buffer已经被Consumer取走
bool mAcquireCalled;
// 表示Buffer需要重新分配,需要设置BUFFER_NEEDS_REALLOCATION 通知Producer,
//不要用原来的缓存的Buffer
bool mNeedsReallocation;
};
- acquireBuffer流程
Buffer queue到BufferQueue中后,将通知消费者去消费。消费时通过acquireBuffer来获取Buffer
status_t BufferQueueConsumer::acquireBuffer(BufferItem* outBuffer, nsecs_t expectedPresent, uint64_t maxFrameNumber) {
...
//numAcquiredBuffers,已经acquired的Buffer
int numAcquiredBuffers = 0;
for (int s : mCore->mActiveBuffers) {
if (mSlots[s].mBufferState.isAcquired()) {
++numAcquiredBuffers;
}
}
//mMaxAcquiredBufferCount最大可以acquire的Buffer,可以溢出一个,
//以便Consumer能方便替换旧的Buffer,如果旧的Buffer还没有释放时。
if (numAcquiredBuffers >= mCore->mMaxAcquiredBufferCount + 1) {
return INVALID_OPERATION;
}
//sharedBufferAvailable:共享Buffer模式下使用,
//在这个模式下,mAutoRefresh表示,Consumer永远可以acquire到一块Buffer,即使BufferQueue还没有处于可以acquire的状态
bool sharedBufferAvailable = mCore->mSharedBufferMode &&
mCore->mAutoRefresh && mCore->mSharedBufferSlot !=
BufferQueueCore::INVALID_BUFFER_SLOT;
//mQueue,如没有Buffer被queue过来,mQueue为空,
//那么Consumer这边就acquire不到新的Buffer,Consumer这边已经acquire的会被继续使用
if (mCore->mQueue.empty() && !sharedBufferAvailable) {
return NO_BUFFER_AVAILABLE;
}
BufferQueueCore::Fifo::iterator front(mCore->mQueue.begin());
//expectedPresent 期望被显示的时间
//也就是这个Buffer希望在什么时候被显示到屏幕上。
//如果Buffer的DesiredPresent的时间早于这个时间,那么这个Buffer将被准时显示。或者稍晚才被显示,如果我们不想显示直到expectedPresent时间之后,我们返回PRESENT_LATER,不去acquire它。但是如果时间在一秒之内,就不会延迟了,直接acquire回去
if (expectedPresent != 0 && !mCore->mQueue.empty()) {
while (mCore->mQueue.size() > 1 && !mCore->mQueue[0].mIsAutoTimestamp) {
const BufferItem& bufferItem(mCore->mQueue[1]);
//检查是否需要丢弃一些帧
if (maxFrameNumber && bufferItem.mFrameNumber > maxFrameNumber) {
break;
}
nsecs_t desiredPresent = bufferItem.mTimestamp;
if (desiredPresent < expectedPresent - MAX_REASONABLE_NSEC ||
desiredPresent > expectedPresent) {
break;
}
//front->mIsStale,表示Buffer已经被释放
if (!front->mIsStale) {
...
}
mCore->mQueue.erase(front);
front = mCore->mQueue.begin();
}
...
}
int slot = BufferQueueCore::INVALID_BUFFER_SLOT;
//如果是共享Buffer模式,即使mQueue为空,也会把共享的Buffer返回去。其他情况下就返回,mQueue的第一个Buffer。
if (sharedBufferAvailable && mCore->mQueue.empty()) {
...
} else {
slot = front->mSlot;
*outBuffer = *front;
}
ATRACE_BUFFER_INDEX(slot);
if (!outBuffer->mIsStale) {
...
//acquire到Buffer后,修改mSlots中对应Buffer序号的mBufferState状态
}
...
//ATRACE_INT,这个在systrace分析时,非常有用
ATRACE_INT(mCore->mConsumerName.string(),
static_cast<int32_t>(mCore->mQueue.size()));
...
}
if (listener != nullptr) {
for (int i = 0; i < numDroppedBuffers; ++i) {
listener->onBufferReleased();
}
}
return NO_ERROR;
}
其他介绍
std::make_unique
在SurfaceFlingerFactory中,大量运用std::make_unique,make_unique是在c++14里加入标准库的
template<typename T, typename... Ts>
std::unique_ptr<T> make_unique(Ts&&... params)
{
return std::unique_ptr<T>(new T(std::forward<Ts>(params)...));
}
make_unique只是把参数完美转发给要创建对象的构造函数,再从new出来的原生指针,构造std::unique_ptr智能指针。这种形式的函数,不支持数组和自定义删除器。
如下的std::unique_ptr(new DispSyncSource(&dispSync, phaseOffsetNs, true, connectionName));
* frameworks/native/services/surfaceflinger/Scheduler/Scheduler.cpp
std::unique_ptr<EventThread> Scheduler::makeEventThread(
const char* connectionName, DispSync* dispSync, int64_t phaseOffsetNs,
impl::EventThread::InterceptVSyncsCallback interceptCallback) {
std::unique_ptr<VSyncSource> eventThreadSource =
std::make_unique<DispSyncSource>(dispSync, phaseOffsetNs, true, connectionName);
return std::make_unique<impl::EventThread>(std::move(eventThreadSource),
std::move(interceptCallback), connectionName);
}