一、问题总结
Depthwise和pointwise减少了参数和计算量,为什么反而会造成计算速度变慢呢,是因为1x1的卷积太多吗?
二、代码练习
MobileNet V1
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, 2017
VGG,GoogleNet,ResNet进一步提高CNN的性能。但是到ResNet,网络已经达到152层,模型大小动辄几百300MB+。这种巨大的存储和计算开销,严重限制了CNN在某些低功耗领域的应用。在实际应用中受限于硬件运算能力与存储(比如几乎不可能在手机芯片上跑ResNet-152),所以必须有一种能在算法层面有效的压缩存储和计算量的方法。而MobileNet/ShuffleNet正为我们打开这扇窗。
Mobilenet v1是Google于2017年发布的网络架构,旨在充分利用移动设备和嵌入式应用的有限的资源,有效地最大化模型的准确性,以满足有限资源下的各种应用案例。Mobilenet v1核心是把卷积拆分为Depthwise+Pointwise两部分。
Depthwise 处理一个三通道的图像,使用3×3的卷积核,完全在二维平面上进行,卷积核的数量与输入的通道数相同,所以经过运算会生成3个feature map。卷积的参数为: 3 × 3 × 3 = 27.
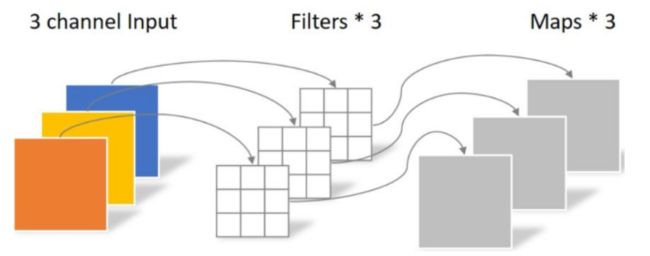
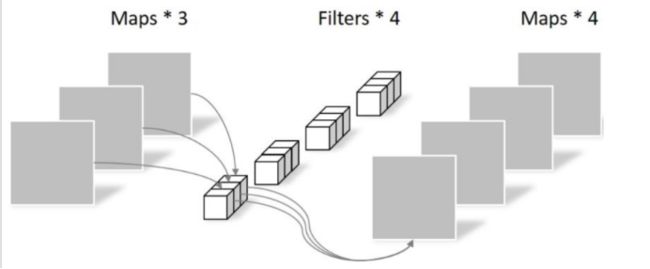
Pointwise 不同之处在于卷积核的尺寸为1×1×k,k为输入通道的数量。所以,这里的卷积运算会将上一层的feature map加权融合,有几个filter就有几个feature map,参数数量为:1 × 1 × 3 × 4 = 12,如下图所示:
创建网络
class MobileNetV1(nn.Module): # (128,2) means conv planes=128, stride=2 cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1), (1024,2), (1024,1)] def __init__(self, num_classes=10): super(MobileNetV1, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.linear = nn.Linear(1024, num_classes) def _make_layers(self, in_planes): layers = [] for x in self.cfg: out_planes = x[0] stride = x[1] layers.append(Block(in_planes, out_planes, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.avg_pool2d(out, 2) out = out.view(out.size(0), -1) out = self.linear(out) return out
实例化网络
net = MobileNetV1().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001)
MobileNet V2
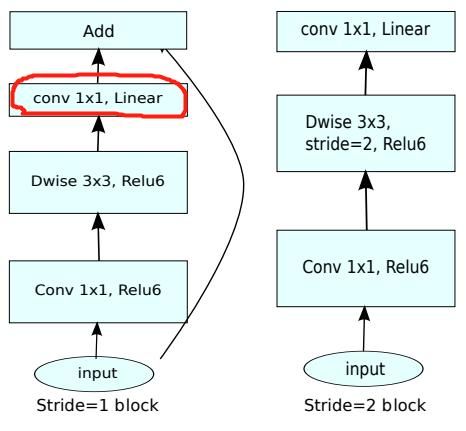
MobileNet V2 的主要改动一:设计了Inverted residual block
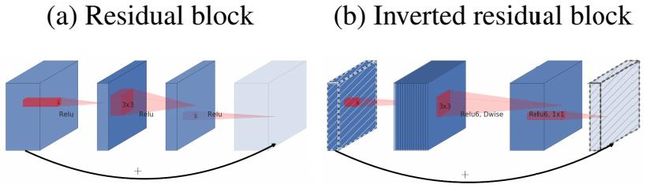
MobileNet V2 的主要改动二:去掉输出部分的ReLU6
在 MobileNet V1 里面使用 ReLU6,ReLU6 就是普通的ReLU但是限制最大输出值为 6,这是为了在移动端设备 float16/int8 的低精度的时候,也能有很好的数值分辨率。Depthwise输出比较浅,应用ReLU会带来信息损失,所以在最后把ReLU去掉了(注意下图中标红的部分没有ReLU)。
创建网络
class MobileNetV2(nn.Module): # (expansion, out_planes, num_blocks, stride) cfg = [(1, 16, 1, 1), (6, 24, 2, 1), (6, 32, 3, 2), (6, 64, 4, 2), (6, 96, 3, 1), (6, 160, 3, 2), (6, 320, 1, 1)] def __init__(self, num_classes=10): super(MobileNetV2, self).__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False) self.bn1 = nn.BatchNorm2d(32) self.layers = self._make_layers(in_planes=32) self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False) self.bn2 = nn.BatchNorm2d(1280) self.linear = nn.Linear(1280, num_classes) def _make_layers(self, in_planes): layers = [] for expansion, out_planes, num_blocks, stride in self.cfg: strides = [stride] + [1]*(num_blocks-1) for stride in strides: layers.append(Block(in_planes, out_planes, expansion, stride)) in_planes = out_planes return nn.Sequential(*layers) def forward(self, x): out = F.relu(self.bn1(self.conv1(x))) out = self.layers(out) out = F.relu(self.bn2(self.conv2(out))) out = F.avg_pool2d(out, 4) out = out.view(out.size(0), -1) out = self.linear(out) return out
模型训练
for epoch in range(10): # 重复多轮训练 for i, (inputs, labels) in enumerate(trainloader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 输出统计信息 if i % 100 == 0: print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item())) print('Finished Training')
HybridSN 高光谱分类
首先用 3D卷积,然后使用 2D卷积
模型的网络结构为如下图所示:

三维卷积部分:
- conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==>(8, 24, 23, 23)
- conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
- conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
为缩进问题,缩进不规范导致的出错
训练网络
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 网络放到GPU上 net = HybridSN().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001) # 开始训练 total_loss = 0 for epoch in range(100): for i, (inputs, labels) in enumerate(train_loader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() total_loss += loss.item() print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item())) print('Finished Training')
模型测试
count = 0 # 模型测试 for inputs, _ in test_loader: inputs = inputs.to(device) outputs = net(inputs) outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1) if count == 0: y_pred_test = outputs count = 1 else: y_pred_test = np.concatenate( (y_pred_test, outputs) ) # 生成分类报告 classification = classification_report(ytest, y_pred_test, digits=4) print(classification)
三、论文阅读
3.1《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》
网络结构图如下
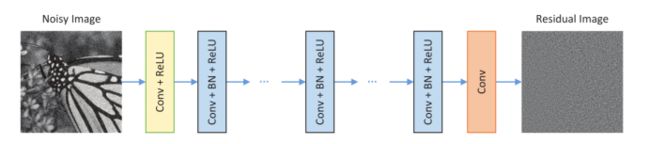
是第一在图像去噪领域使用了深度学习
图像去噪,是在一个遵循图像退化的模型y=x+v中,让网络能够从噪声中观察y中回复原始数据x
其次,引入了残差学习和批量归一化的概念
为什么需要批量归一化?(知乎)
在训练过程中,每层输入的分布不断的变化,这使得下一层需要不断的去适应新的数据分布,在深度神经网络中,这让训练变得非常复杂而且缓慢。对于这样,往往需要设置更小的学习率、更严格的参数初始化。通过使用批量归一化(Batch Normalization, BN),在模型的训练过程中利用小批量的均值和方差调整神经网络中间的输出,从而使得各层之间的输出都符合均值、方差相同高斯分布,这样的话会使得数据更加稳定,无论隐藏层的参数如何变化,可以确定的是前一层网络输出数据的均值、方差是已知的、固定的,这样就解决了数据分布不断改变带来的训练缓慢、小学习率等问题。
为什么需要残差学习(知乎)
我们知道,在CNN网络中,我们输入的是图片的矩阵,也是最基本的特征,整个CNN网络就是一个信息提取的过程,从底层的特征逐渐抽取到高度抽象的特征,网络的层数越多也就意味这能够提取到的不同级别的抽象特征更加丰富,并且越深的网络提取的特征越抽象,就越具有语义信息。
为什么不能简单的增加网络层数?
对于传统的CNN网络,简单的增加网络的深度,容易导致梯度消失和爆炸。针对梯度消失和爆炸的解决方法一般是正则初始化(normalized initialization)和中间的正则化层(intermediate normalization layers),但是这会导致另一个问题,退化问题,随着网络层数的增加,在训练集上的准确率却饱和甚至下降了。这个和过拟合不一样,因为过拟合在训练集上的表现会更加出色。
3.2《Squeeze-and-Excitation Networks》
该网络通过学习的方式,获取每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征,并一直对当前任务用处不大的特征。
简单理解就是加权重,对于有用的信息就加大权重,对于无用的信息就减少权重

是将H和W进行压缩为1x1xC,再赋予不同的权重
其中
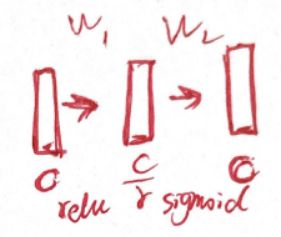
先降维再升维是为了减少参数
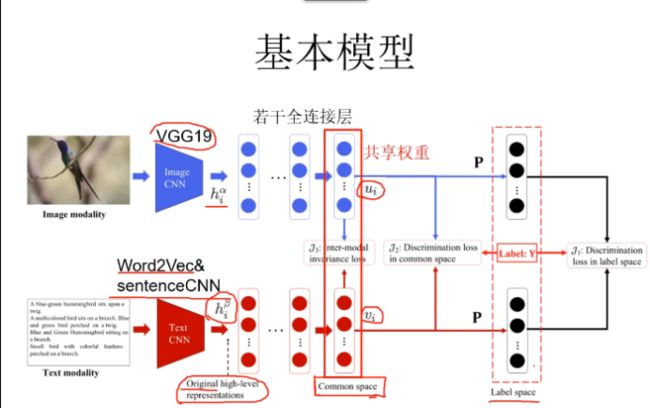
3.3《Deep Supervised Cross-modal Retrieval》
图像与文本进行互相检索,共享权重